Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Dataflöden är tillgängliga i både Azure Data Factory pipelines och Azure Synapse Analytics pipelines. Den här artikeln gäller för mappning av dataflöden. Om du inte har använt transformeringar tidigare läser du introduktionsartikeln Transformera data med hjälp av mappning av dataflöden.
Tips
För motsvarande transformering (Hämta data) i Dataflöde Gen2, se En guide till Dataflöde Gen2 för mappning av dataflödesanvändare.
En källtransformering konfigurerar datakällan för dataflödet. När du utformar dataflöden är ditt första steg alltid att konfigurera en källtransformering. Om du vill lägga till en källa väljer du rutan Lägg till källa på dataflödesarbetsytan.
Varje dataflöde kräver minst en källtransformering, men du kan lägga till så många källor som behövs för att slutföra dina datatransformeringar. Du kan koppla dessa källor tillsammans med en koppling, uppslag eller en uniontransformering.
Varje källtransformering är associerad med exakt en datauppsättning eller länkad tjänst. Datauppsättningen definierar formen och platsen för de data som du vill skriva till eller läsa från. Om du använder en filbaserad datauppsättning kan du använda jokertecken och fillistor i källan för att arbeta med mer än en fil i taget.
Infogade datauppsättningar
Det första beslutet du fattar när du skapar en källtransformation är om källinformationen definieras i ett datauppsättningsobjekt eller inom källtransformeringen. De flesta format är bara tillgängliga i det ena eller det andra. Information om hur du använder en specifik anslutningsapp finns i lämpligt anslutningsdokument.
När ett format stöds för både infogade objekt och i ett datauppsättningsobjekt finns det fördelar med båda. Datamängdsobjekt är återanvändbara entiteter som kan användas i andra dataflöden och aktiviteter som Kopiera. Dessa återanvändbara entiteter är särskilt användbara när du använder ett härdat schema. Datauppsättningar är inte baserade i Spark. Ibland kan du behöva åsidosätta vissa inställningar eller schemaprojektion i källtransformeringen.
Infogade datauppsättningar rekommenderas när du använder flexibla scheman, enstaka källinstanser eller parametriserade källor. Om källan är kraftigt parametriserad kan infogade datauppsättningar göra att du inte kan skapa ett "dummy"-objekt. Infogade datauppsättningar baseras i Spark och deras egenskaper är inbyggda i dataflödet.
Om du vill använda en infogad datauppsättning väljer du önskat format i väljaren Källtyp . I stället för att välja en källdatauppsättning väljer du den länkade tjänst som du vill ansluta till.
Schemaalternativ
Eftersom en infogad datauppsättning definieras i dataflödet finns det inte något definierat schema som är associerat med den infogade datamängden. På fliken Projektion kan du importera källdataschemat och lagra schemat som källprojektion. På den här fliken hittar du knappen Schemaalternativ som gör att du kan definiera beteendet för ADF:s tjänst för schemaidentifiering.
- Använd beräknat schema: Det här alternativet är användbart när du har ett stort antal källfiler som ADF genomsöker som källa. ADF:s standardbeteende är att identifiera schemat för varje källfil. Men om du redan har en fördefinierad projektion lagrad i källtransformeringen kan du ställa in den på true och ADF hoppar över automatisk identifiering av varje schema. Med det här alternativet aktiverat kan källtransformeringen läsa alla filer mycket snabbare och tillämpa det fördefinierade schemat på varje fil.
- Tillåt schemaavvikelse: Aktivera schemaavvikelse så att dataflödet tillåter nya kolumner som inte redan har definierats i källschemat.
- Verifiera schema: Om du anger det här alternativet misslyckas dataflödet om någon kolumn och typ som definierats i projektionen inte matchar det identifierade schemat för källdata.
- Slutsatsdragningsstyrda kolumntyper: När nya drivande kolumner identifieras av ADF omvandlas de nya kolumnerna till lämplig datatyp med hjälp av ADF:s automatiska typinferens.
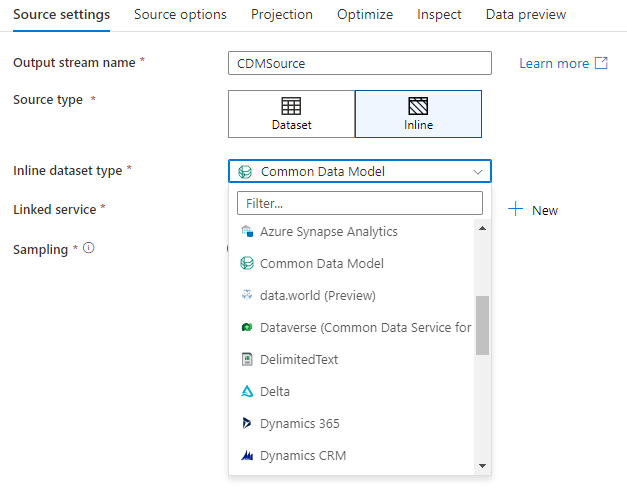
Arbetsyta DB (endast Synapse-arbetsytor)
I Azure Synapse arbetsytor finns ytterligare ett alternativ i dataflödeskälltransformeringar som kallas Workspace DB. På så sätt kan du direkt välja en arbetsytedatabas av valfri tillgänglig typ som källdata utan att behöva ytterligare länkade tjänster eller datauppsättningar. Databaserna som skapas via Azure Synapse databasmallar är också tillgängliga när du väljer Arbetsyta DB.
Källtyper som stöds
Mappning av dataflöde följer en ELT-metod (extract, load, and transform) och fungerar med staging datauppsättningar som alla finns i Azure. För närvarande kan följande datauppsättningar användas i en källtransformering.
Inställningar som är specifika för dessa anslutningsappar finns på fliken Källalternativ . Exempel på informations- och dataflödesskript för de här inställningarna finns i anslutningsdokumentationen.
Azure Data Factory och Synapse-pipelines har åtkomst till mer än 90 inbyggda anslutningar. Om du vill inkludera data från de andra källorna i dataflödet använder du kopieringsaktiviteten för att läsa in dessa data i något av de mellanlagringsområden som stöds.
Källinställningar
När du har lagt till en källa konfigurerar du via fliken Källinställningar . Här kan du välja eller skapa datauppsättningen som källpunkterna finns på. Du kan också välja schema- och samplingsalternativ för dina data.
Utvecklingsvärden för datauppsättningsparametrar kan konfigureras i felsökningsinställningarna. (Felsökningsläget måste vara aktiverat.)
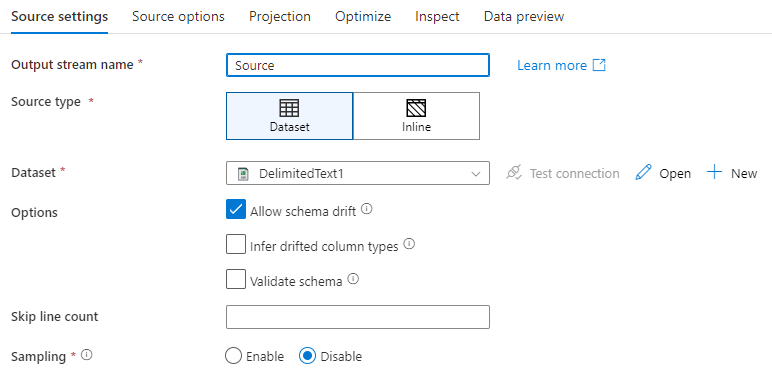
Namn på utdataström: Namnet på källtransformeringen.
Källtyp: Välj om du vill använda en infogad datauppsättning eller ett befintligt datauppsättningsobjekt.
Testanslutning: Testa om dataflödets Spark-tjänst kan ansluta till den länkade tjänst som används i källdatauppsättningen. Felsökningsläget måste vara aktiverat för att den här funktionen ska vara aktiverad.
Schemaavvikelse: Schemaavvikelse är tjänstens förmåga att internt hantera flexibla scheman i dina dataflöden utan att uttryckligen behöva definiera kolumnändringar.
Markera kryssrutan Tillåt schemaavvikelse om källkolumnerna ändras ofta. Med den här inställningen kan alla inkommande källfält flöda genom transformeringar till mottagaren.
Om du väljer Härledda kolumntyper instrueras tjänsten att identifiera och definiera datatyper för varje ny kolumn som identifieras. Med den här funktionen inaktiverad är alla driftade kolumner av typen sträng.
Verifiera schema: Om Verifiera schema har valts kan dataflödet inte köras om inkommande källdata inte matchar datamängdens definierade schema.
Hoppa över radantal: Fältet Hoppa över antal rader anger hur många rader som ska ignoreras i början av datamängden.
Sampling: Aktivera sampling för att begränsa antalet rader från källan. Använd den här inställningen när du testar eller provar data från källan i felsökningssyfte. Detta är mycket användbart när du kör dataflöden i felsökningsläge från en pipeline.
Om du vill verifiera att källan är korrekt konfigurerad aktiverar du felsökningsläget och hämtar en förhandsgranskning av data. Mer information finns i Felsökningsläge.
Kommentar
När felsökningsläget är aktiverat skriver radgränsens konfiguration i felsökningsinställningarna över samplingsinställningen i källan under dataförhandsgranskningen.
Källalternativ
Fliken Källalternativ innehåller inställningar som är specifika för anslutningsappen och formatet som valts. Mer information och exempel finns i relevant anslutningsdokumentation. Detta omfattar information som isoleringsnivå för de datakällor som stöder den (till exempel lokala SQL-servrar, Azure SQL databaser och Azure SQL hanterade instanser) och andra inställningar för datakällan.
Projektion
Precis som scheman i datauppsättningar definierar projektionen i en källa datakolumnerna, typerna och formaten från källdata. För de flesta datauppsättningstyper, till exempel SQL och Parquet, är projektionen i en källa fast för att återspegla schemat som definierats i en datauppsättning, vilket varierar beroende på källan. När källfilerna inte är starkt inskrivna (till exempel platta .csv filer i stället för Parquet-filer) kan du definiera datatyperna för varje fält i källomvandlingen. Följande bild visar en exempelprojektion:
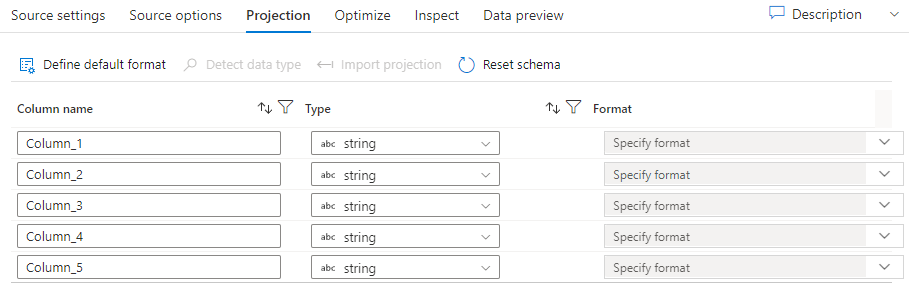
Om textfilen inte har något definierat schema väljer du Identifiera datatyp så att tjänsten kan prova och härleda datatyperna. Välj Definiera standardformat för att identifiera standarddataformat automatiskt.
Återställningsschema återställer projektionen till det som definieras i den refererade datauppsättningen.
Med överskrivningsschemat kan du ändra de beräknade datatyperna här källan och skriva över de schemadefinierade datatyperna. Du kan också ändra kolumndatatyperna i en härledd kolumntransformation nedströms. Använd en select-transformering för att ändra kolumnnamnen.
Importera schema
Välj knappen Importera schema på fliken Projektion för att använda ett aktivt felsökningskluster för att skapa en schemaprojektion. Den är tillgänglig i alla källtyper. Om du importerar schemat här åsidosätts projektionen som definierats i datauppsättningen. Datamängdsobjektet ändras inte.
Att importera schema är användbart i datauppsättningar som Avro och Azure Cosmos DB som stöder komplexa datastrukturer som inte kräver att schemadefinitioner finns i datauppsättningen. För infogade datauppsättningar är import av schema det enda sättet att referera till kolumnmetadata utan schemaavvikelse.
Optimera källtransformeringen
På fliken Optimera kan du redigera partitionsinformation i varje transformeringssteg. I de flesta fall optimerar att använda aktuell partitionering för den idealiska partitioneringsstrukturen för en källa.
Om du läser från en källa i Azure SQL Database är anpassad Source-partitionering sannolikt det snabbaste sättet att läsa data. Tjänsten läser stora sökfrågor genom att göra parallella anslutningar till din databas. Den här källpartitioneringen kan göras i en kolumn eller med hjälp av en fråga.
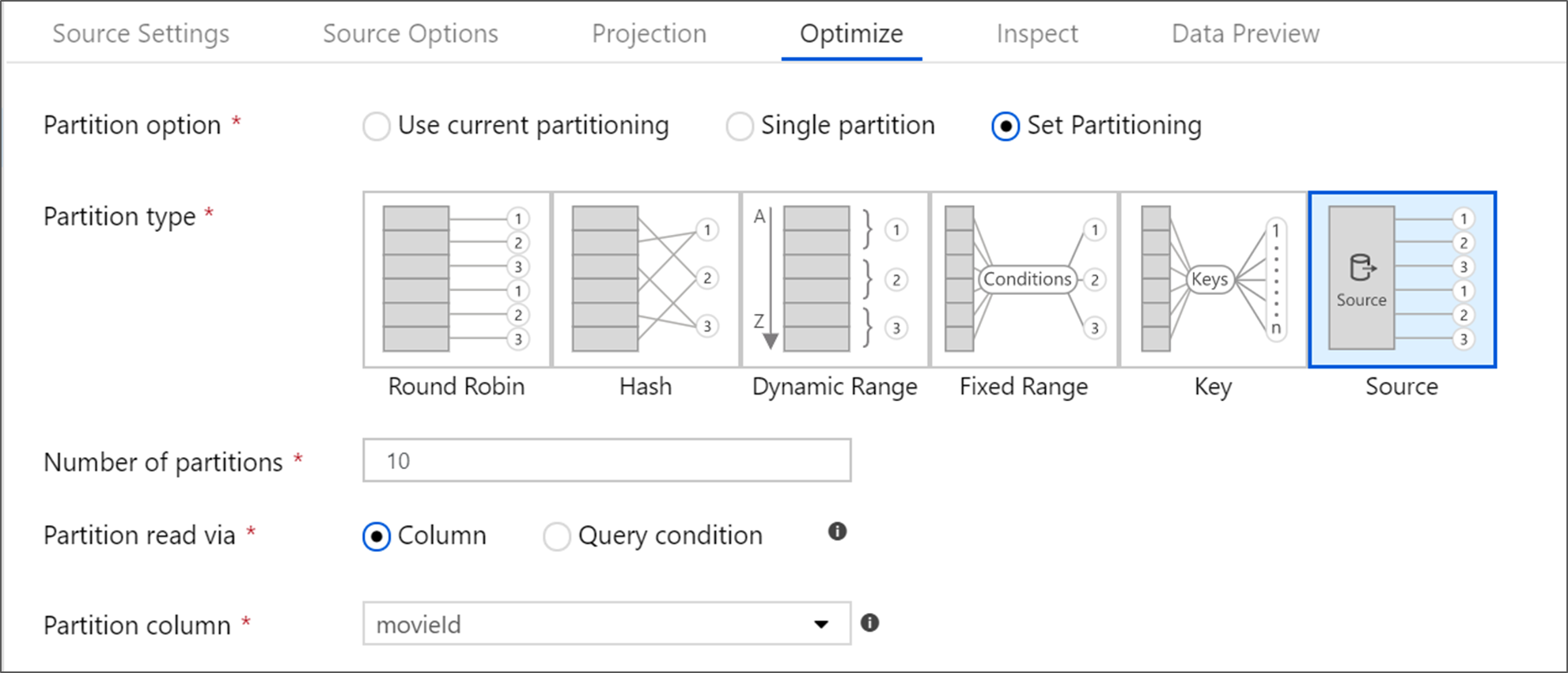
Mer information om optimering inom dataflödesmappning finns på fliken Optimera.
Relaterat innehåll
Börja skapa ditt dataflöde med en transformering av härledda kolumner och en select-transformering.