Felsöka prestanda för kopieringsaktivitet
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du felsöker prestandaproblem med kopieringsaktivitet i Azure Data Factory.
När du har kört en kopieringsaktivitet kan du samla in körningsresultatet och prestandastatistiken i övervakningsvyn för kopieringsaktivitet. Följande är ett exempel.
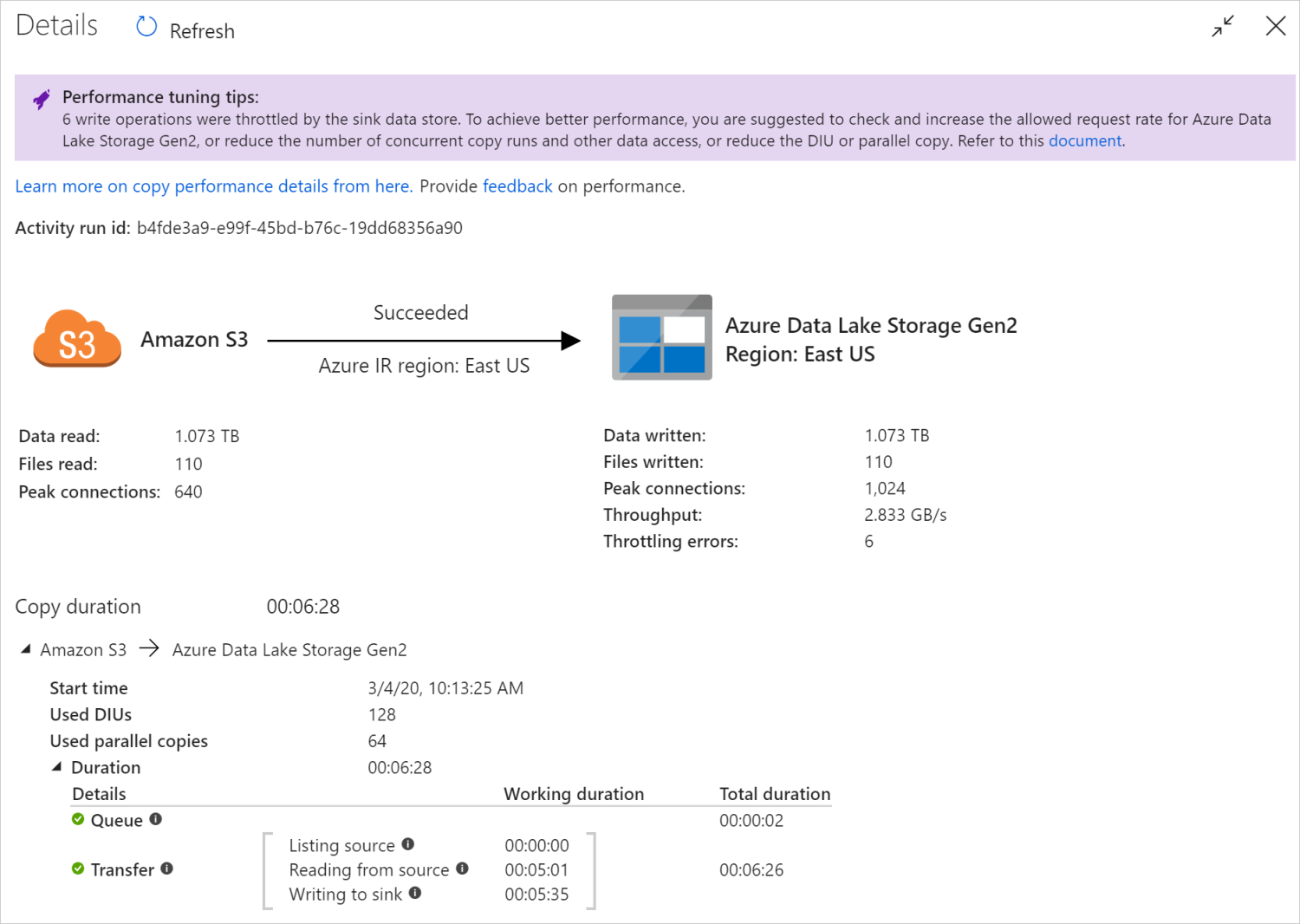
Tips vid prestandajustering
I vissa scenarier visas "Prestandajusteringstips" högst upp när du kör en kopieringsaktivitet, som du ser i exemplet ovan. Tipsen visar flaskhalsen som identifieras av tjänsten för den här kopieringskörningen, tillsammans med förslag på hur du ökar dataflödet för kopiering. Försök att göra den rekommenderade ändringen och kör sedan kopian igen.
Som referens ger prestandajusteringstipsen för närvarande förslag på följande fall:
| Kategori | Tips vid prestandajustering |
|---|---|
| Datalagerspecifik | Läsa in data i Azure Synapse Analytics: föreslå att du använder PolyBase- eller COPY-instruktionen om den inte används. |
| Kopiera data från/till Azure SQL Database: När DTU är under hög användning rekommenderar vi att du uppgraderar till en högre nivå. | |
| Kopiera data från/till Azure Cosmos DB: När RU är under hög användning rekommenderar vi att du uppgraderar till större RU. | |
| Kopiera data från SAP-tabellen: När du kopierar stora mängder data föreslår du att du använder SAP-anslutningsappens partitionsalternativ för att aktivera parallell belastning och öka det maximala partitionsnumret. | |
| Mata in data från Amazon Redshift: föreslå att du använder UNLOAD om de inte används. | |
| Begränsning av datalager | Om ett antal läs-/skrivåtgärder begränsas av datalagret under kopiering föreslår du att du kontrollerar och ökar den tillåtna begärandefrekvensen för datalagret eller minskar den samtidiga arbetsbelastningen. |
| Integration runtime | Om du använder en lokalt installerad integrationskörning (IR) och kopieringsaktiviteten väntar länge i kön tills IR har tillgänglig resurs att köra föreslår du att du skalar ut/upp din IR. |
| Om du använder en Azure Integration Runtime som är i en inte optimal region som resulterar i långsam läsning/skrivning föreslår du att du konfigurerar att använda en IR i en annan region. | |
| Feltolerans | Om du konfigurerar feltolerans och hoppar över inkompatibla rader resulterar i långsamma prestanda rekommenderar du att du ser till att käll- och mottagardata är kompatibla. |
| Mellanlagrad kopia | Om mellanlagrad kopia har konfigurerats men inte är till hjälp för ditt käll-mottagarpar rekommenderar du att du tar bort den. |
| Återuppta | När kopieringsaktiviteten återupptas från den senaste felpunkten, men du råkar ändra DIU-inställningen efter den ursprungliga körningen, bör du notera att den nya DIU-inställningen inte börjar gälla. |
Förstå körningsinformation för kopieringsaktivitet
Körningsinformationen och varaktigheterna längst ned i övervakningsvyn för kopieringsaktiviteten beskriver de nyckelsteg som kopieringsaktiviteten går igenom (se exempel i början av den här artikeln), vilket är särskilt användbart för att felsöka kopieringsprestandan. Flaskhalsen i kopieringskörningen är den som har längst varaktighet. Se följande tabell i varje stegs definition och lär dig hur du felsöker kopieringsaktivitet i Azure IR och felsöker kopieringsaktivitet på lokalt installerad IR med sådan information.
| Fas | beskrivning |
|---|---|
| Queue | Den förflutna tiden tills kopieringsaktiviteten faktiskt startar på integrationskörningen. |
| Förkopieringsskript | Den förflutna tiden mellan kopieringsaktiviteten som startar på IR och kopieringsaktiviteten slutför körningen av förkopieringsskriptet i datalagret för mottagare. Använd när du konfigurerar förkopieringsskriptet för databasmottagare, t.ex. när du skriver data till Azure SQL Database rensar du innan du kopierar nya data. |
| Överföring | Den förflutna tiden mellan slutet av föregående steg och IR överför alla data från källa till mottagare. Observera att understegen under överföring körs parallellt, och vissa åtgärder visas inte nu, t.ex. parsning/generering av filformat. - Tid till första byte: Tiden som förflutit mellan slutet av föregående steg och den tid då IR tar emot den första byte från källdatalagret. Gäller för icke-filbaserade källor. - Listkälla: Den tid som ägnas åt att räkna upp källfiler eller datapartitioner. Det senare gäller när du konfigurerar partitionsalternativ för databaskällor, t.ex. när du kopierar data från databaser som Oracle/SAP HANA/Teradata/Netezza/etc. -Läsning från källa: Hur lång tid det tar att hämta data från källdatalagret. - Skriva till mottagare: Den tid som ägnas åt att skriva data för att hantera datalager. Observera att vissa anslutningsappar inte har det här måttet just nu, inklusive Azure AI Search, Azure Data Explorer, Azure Table Storage, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce/Salesforce Service Cloud. |
Felsöka kopieringsaktivitet i Azure IR
Följ stegen för prestandajustering för att planera och utföra prestandatest för ditt scenario.
Om du vill felsöka enstaka kopieringsaktivitet som körs på Azure Integration Runtime om du ser prestandajusteringstips som visas i kopieringsövervakningsvyn kan du använda förslaget och försöka igen. Annars kan du förstå körningsinformation för kopieringsaktiviteter, kontrollera vilket stadium som har längst varaktighet och tillämpa vägledningen nedan för att öka kopieringsprestandan:
"Förkopieringsskriptet" hade lång varaktighet: det innebär att förkopieringsskriptet som körs på mottagardatabasen tar lång tid att slutföra. Justera den angivna logiken för förkopieringsskript för att förbättra prestandan. Kontakta databasteamet om du behöver ytterligare hjälp med att förbättra skriptet.
"Överföring – tid till första byte" upplevde lång arbetsvaraktighet: det innebär att källfrågan tar lång tid att returnera data. Kontrollera och optimera frågan eller servern. Kontakta ditt datalagerteam om du behöver ytterligare hjälp.
"Överföring – listningskälla" hade lång arbetsvaraktighet: det innebär att det går långsamt att räkna upp källfiler eller källdatabasdatapartitioner.
När du kopierar data från filbaserad källa, om du använder jokerteckenfilter på mappsökväg eller filnamn (
wildcardFolderPatheller ), ellerwildcardFileNameanvänder tidsfiltret för senast ändrad fil (modifiedDatetimeStartellermodifiedDatetimeEnd), observera att ett sådant filter skulle resultera i kopieringsaktivitet som visar alla filer under den angivna mappen på klientsidan och sedan tillämpar filtret. En sådan filuppräkning kan bli flaskhalsen, särskilt när endast en liten uppsättning filer uppfyllde filterregeln.Kontrollera om du kan kopiera filer baserat på den partitionerade filsökvägen eller namnet på datetime. På så sätt blir det inte börda för att lista källsidan.
Kontrollera om du kan använda datalagrets interna filter i stället, särskilt "prefix" för Amazon S3/Azure Blob Storage/Azure Files och "listAfter/listBefore" för ADLS Gen1. Dessa filter är datalagerfilter på serversidan och skulle ha mycket bättre prestanda.
Överväg att dela upp en enda stor datauppsättning i flera mindre datamängder och låta dessa kopieringsjobb köras samtidigt som var och en hanterar delar av data. Du kan göra detta med Lookup/GetMetadata + ForEach + Copy. Se Kopiera filer från flera containrar eller Migrera data från Amazon S3 till ADLS Gen2-lösningsmallar som allmänt exempel.
Kontrollera om tjänsten rapporterar ett begränsningsfel på källan eller om datalagret har hög användningsstatus. I så fall kan du antingen minska dina arbetsbelastningar i datalagret eller försöka kontakta datalageradministratören för att öka begränsningsgränsen eller den tillgängliga resursen.
Använd Azure IR i samma eller nära källdatalagerregionen.
"Överföring – läsning från källa" upplevde lång arbetsvaraktighet:
Anta metodtips för anslutningsspecifik datainläsning om det är tillämpligt. När du till exempel kopierar data från Amazon Redshift konfigurerar du för att använda Redshift UNLOAD.
Kontrollera om tjänsten rapporterar ett begränsningsfel på källan eller om datalagret är under hög användning. I så fall kan du antingen minska dina arbetsbelastningar i datalagret eller försöka kontakta datalageradministratören för att öka begränsningsgränsen eller den tillgängliga resursen.
Kontrollera kopieringskällan och mottagarmönstret:
Om ditt kopieringsmönster stöder större än 4 dataintegreringsenheter (DIUs) – se det här avsnittet om information, vanligtvis kan du försöka öka DIUs för att få bättre prestanda.
I annat fall bör du överväga att dela upp en enskild stor datamängd i flera mindre datamängder och låta dessa kopieringsjobb köras samtidigt så att var och en av dem hanterar sin datadel. Du kan göra detta med Lookup/GetMetadata + ForEach + Copy. Se Kopiera filer från flera containrar, Migrera data från Amazon S3 till ADLS Gen2 eller Masskopiering med en kontrolltabelllösningsmallar som allmänt exempel.
Använd Azure IR i samma eller nära källdatalagerregionen.
"Transfer - writing to sink" upplevde lång arbetsvaraktighet:
Anta metodtips för anslutningsspecifik datainläsning om det är tillämpligt. När du till exempel kopierar data till Azure Synapse Analytics använder du PolyBase- eller COPY-instruktionen.
Kontrollera om tjänsten rapporterar något begränsningsfel på mottagaren eller om datalagret är under hög användning. I så fall kan du antingen minska dina arbetsbelastningar i datalagret eller försöka kontakta datalageradministratören för att öka begränsningsgränsen eller den tillgängliga resursen.
Kontrollera kopieringskällan och mottagarmönstret:
Om ditt kopieringsmönster stöder större än 4 dataintegreringsenheter (DIUs) – se det här avsnittet om information, vanligtvis kan du försöka öka DIUs för att få bättre prestanda.
Annars kan du gradvis justera de parallella kopiorna, observera att för många parallella kopior till och med kan skada prestandan.
Använd Azure IR i samma eller nära datalagerregionen för mottagare.
Felsöka kopieringsaktivitet på lokalt installerad IR
Följ stegen för prestandajustering för att planera och utföra prestandatest för ditt scenario.
När kopieringsprestandan inte uppfyller dina förväntningar kan du felsöka enstaka kopieringsaktivitet som körs på Azure Integration Runtime. Om du ser prestandajusteringstips som visas i kopieringsövervakningsvyn kan du använda förslaget och försöka igen. Annars kan du förstå körningsinformation för kopieringsaktiviteter, kontrollera vilket stadium som har längst varaktighet och tillämpa vägledningen nedan för att öka kopieringsprestandan:
"Kö" upplevde lång varaktighet: det innebär att kopieringsaktiviteten väntar länge i kön tills din lokalt installerad IR har en resurs att köra. Kontrollera IR-kapaciteten och användningen och skala upp eller ut enligt din arbetsbelastning.
"Överföring – tid till första byte" upplevde lång arbetsvaraktighet: det innebär att källfrågan tar lång tid att returnera data. Kontrollera och optimera frågan eller servern. Kontakta ditt datalagerteam om du behöver ytterligare hjälp.
"Överföring – listningskälla" hade lång arbetsvaraktighet: det innebär att det går långsamt att räkna upp källfiler eller källdatabasdatapartitioner.
Kontrollera om den lokalt installerade IR-datorn har låg svarstid vid anslutning till källdatalagret. Om källan finns i Azure kan du använda det här verktyget för att kontrollera svarstiden från den lokalt installerade IR-datorn till Azure-regionen, desto mindre desto bättre.
När du kopierar data från filbaserad källa, om du använder jokerteckenfilter på mappsökväg eller filnamn (
wildcardFolderPatheller ), ellerwildcardFileNameanvänder tidsfiltret för senast ändrad fil (modifiedDatetimeStartellermodifiedDatetimeEnd), observera att ett sådant filter skulle resultera i kopieringsaktivitet som visar alla filer under den angivna mappen på klientsidan och sedan tillämpar filtret. En sådan filuppräkning kan bli flaskhalsen, särskilt när endast en liten uppsättning filer uppfyllde filterregeln.Kontrollera om du kan kopiera filer baserat på den partitionerade filsökvägen eller namnet på datetime. På så sätt blir det inte börda för att lista källsidan.
Kontrollera om du kan använda datalagrets interna filter i stället, särskilt "prefix" för Amazon S3/Azure Blob Storage/Azure Files och "listAfter/listBefore" för ADLS Gen1. Dessa filter är datalagerfilter på serversidan och skulle ha mycket bättre prestanda.
Överväg att dela upp en enda stor datauppsättning i flera mindre datamängder och låta dessa kopieringsjobb köras samtidigt som var och en hanterar delar av data. Du kan göra detta med Lookup/GetMetadata + ForEach + Copy. Se Kopiera filer från flera containrar eller Migrera data från Amazon S3 till ADLS Gen2-lösningsmallar som allmänt exempel.
Kontrollera om tjänsten rapporterar ett begränsningsfel på källan eller om datalagret har hög användningsstatus. I så fall kan du antingen minska dina arbetsbelastningar i datalagret eller försöka kontakta datalageradministratören för att öka begränsningsgränsen eller den tillgängliga resursen.
"Överföring – läsning från källa" upplevde lång arbetsvaraktighet:
Kontrollera om den lokalt installerade IR-datorn har låg svarstid vid anslutning till källdatalagret. Om källan finns i Azure kan du använda det här verktyget för att kontrollera svarstiden från den lokalt installerade IR-datorn till Azure-regionerna, desto mindre desto bättre.
Kontrollera om den lokalt installerade IR-datorn har tillräckligt med inkommande bandbredd för att läsa och överföra data effektivt. Om källdatalagret finns i Azure kan du använda det här verktyget för att kontrollera nedladdningshastigheten.
Kontrollera trenden för cpu- och minnesanvändning med lokalt installerad IR i Azure-portalen –> din datafabrik eller Synapse-arbetsyta –> översiktssidan. Överväg att skala upp/ut IR om processoranvändningen är hög eller om det finns lite ledigt minne.
Anta metodtips för anslutningsspecifik datainläsning om det är tillämpligt. Till exempel:
När du kopierar data från Oracle, Netezza, Teradata, SAP HANA, SAP Table och SAP Open Hub) aktiverar du alternativ för datapartition för att kopiera data parallellt.
När du kopierar data från HDFS konfigurerar du för att använda DistCp.
När du kopierar data från Amazon Redshift konfigurerar du för att använda Redshift UNLOAD.
Kontrollera om tjänsten rapporterar ett begränsningsfel på källan eller om datalagret är under hög användning. I så fall kan du antingen minska dina arbetsbelastningar i datalagret eller försöka kontakta datalageradministratören för att öka begränsningsgränsen eller den tillgängliga resursen.
Kontrollera kopieringskällan och mottagarmönstret:
Om du kopierar data från partitionsalternativaktiverade datalager bör du överväga att gradvis justera de parallella kopiorna. Observera att för många parallella kopior till och med kan skada prestandan.
I annat fall bör du överväga att dela upp en enskild stor datamängd i flera mindre datamängder och låta dessa kopieringsjobb köras samtidigt så att var och en av dem hanterar sin datadel. Du kan göra detta med Lookup/GetMetadata + ForEach + Copy. Se Kopiera filer från flera containrar, Migrera data från Amazon S3 till ADLS Gen2 eller Masskopiering med en kontrolltabelllösningsmallar som allmänt exempel.
"Transfer - writing to sink" upplevde lång arbetsvaraktighet:
Anta metodtips för anslutningsspecifik datainläsning om det är tillämpligt. När du till exempel kopierar data till Azure Synapse Analytics använder du PolyBase- eller COPY-instruktionen.
Kontrollera om den lokalt installerade IR-datorn har låg svarstid vid anslutning till datalagret för mottagare. Om din mottagare finns i Azure kan du använda det här verktyget för att kontrollera svarstiden från den lokalt installerade IR-datorn till Azure-regionen, desto mindre desto bättre.
Kontrollera om den lokalt installerade IR-datorn har tillräckligt med utgående bandbredd för att överföra och skriva data effektivt. Om ditt datalager för mottagare finns i Azure kan du använda det här verktyget för att kontrollera uppladdningshastigheten.
Kontrollera om IR:s cpu- och minnesanvändningstrend i Azure-portalen –> din datafabrik eller Synapse-arbetsyta –> är en översiktssida. Överväg att skala upp/ut IR om processoranvändningen är hög eller om det finns lite ledigt minne.
Kontrollera om tjänsten rapporterar något begränsningsfel på mottagaren eller om datalagret är under hög användning. I så fall kan du antingen minska dina arbetsbelastningar i datalagret eller försöka kontakta datalageradministratören för att öka begränsningsgränsen eller den tillgängliga resursen.
Överväg att gradvis justera de parallella kopiorna, observera att för många parallella kopior till och med kan skada prestandan.
Anslutningsprogram och IR-prestanda
I det här avsnittet beskrivs några felsökningsguider för prestanda för viss anslutningstyp eller integrationskörning.
Körningstiden för aktiviteter varierar med Azure IR jämfört med Azure VNet IR
Körningstiden för aktiviteter varierar när datamängden baseras på olika integrationskörningar.
Symptom: Att bara växla listrutan Länkad tjänst i datauppsättningen utför samma pipelineaktiviteter, men har drastiskt olika körningstider. När datauppsättningen baseras på Managed Virtual Network Integration Runtime tar det mer tid i genomsnitt än körningen när den baseras på standardintegreringskörningen.
Orsak: Om du kontrollerar information om pipelinekörningar kan du se att den långsamma pipelinen körs på IR för hanterat virtuellt nätverk (virtuellt nätverk) medan den normala körs på Azure IR. Avsiktligt tar managed VNet IR längre kötid än Azure IR eftersom vi inte reserverar en beräkningsnod per tjänstinstans, så det finns en uppvärmning för varje kopieringsaktivitet att starta, och den sker främst på VNet-anslutning i stället för Azure IR.
Låga prestanda vid inläsning av data i Azure SQL Database
Symptom: Det går långsamt att kopiera data till Azure SQL Database.
Orsak: Rotorsaken till problemet utlöses främst av flaskhalsen på Azure SQL Database-sidan. Följande är några möjliga orsaker:
Azure SQL Database-nivån är inte tillräckligt hög.
Azure SQL Database DTU-användning är nära 100 %. Du kan övervaka prestanda och överväga att uppgradera Azure SQL Database-nivån.
Index har inte angetts korrekt. Ta bort alla index innan data läses in och återskapa dem när inläsningen är klar.
WriteBatchSize är inte tillräckligt stort för att passa schemaradens storlek. Försök att förstora egenskapen för problemet.
I stället för massinfogning används lagrad procedur, vilket förväntas ha sämre prestanda.
Timeout eller långsamma prestanda vid parsning av stor Excel-fil
Symptom:
När du skapar Excel-datamängd och importerar schema från anslutning/lagring, förhandsgranska data, lista eller uppdatera kalkylblad kan det uppstå timeout-fel om Excel-filen är stor.
När du använder kopieringsaktivitet för att kopiera data från stora Excel-filer (>= 100 MB) till andra datalager kan det uppstå problem med långsamma prestanda eller OOM.
Orsak:
För åtgärder som att importera schema, förhandsgranska data och visa kalkylblad i Excel-datauppsättningen är tidsgränsen 100 s och statisk. För stora Excel-filer kanske dessa åtgärder inte slutförs inom tidsgränsvärdet.
Kopieringsaktiviteten läser hela Excel-filen i minnet och letar sedan upp det angivna kalkylbladet och cellerna för att läsa data. Det här beteendet beror på den underliggande SDK som tjänsten använder.
Lösning:
För att importera schema kan du generera en mindre exempelfil, som är en delmängd av den ursprungliga filen, och välja "importera schema från exempelfil" i stället för "importera schema från anslutning/arkiv".
I listrutan i kalkylbladet kan du klicka på "Redigera" och ange bladnamnet/indexet i stället.
Om du vill kopiera en stor Excel-fil (>100 MB) till ett annat lager kan du använda Data Flow Excel-källa som sportströmning läser och presterar bättre.
OOM-problemet med att läsa stora JSON/Excel/XML-filer
Symptom: När du läser stora JSON/Excel/XML-filer uppstår problemet med slut på minne (OOM) under aktivitetskörningen.
Orsak:
- För stora XML-filer: OOM-problemet med att läsa stora XML-filer är avsiktligt. Orsaken är att hela XML-filen måste läsas in i minnet eftersom den är ett enda objekt, sedan härleds schemat och data hämtas.
- För stora Excel-filer: OOM-problemet med att läsa stora Excel-filer är avsiktligt. Orsaken är att den SDK (POI/NPOI) som används måste läsa hela Excel-filen i minnet och sedan härleda schemat och hämta data.
- För stora JSON-filer: OOM-problemet med att läsa stora JSON-filer är avsiktligt när JSON-filen är ett enda objekt.
Rekommendation: Använd något av följande alternativ för att lösa problemet.
- Alternativ 1: Registrera en onlinebaserad integrationskörning med kraftfull dator (hög CPU/minne) för att läsa data från din stora fil via kopieringsaktiviteten.
- Alternativ 2: Använd optimerat minne och kluster med stor storlek (till exempel 48 kärnor) för att läsa data från din stora fil genom att mappa dataflödesaktiviteten.
- Alternativ 3: Dela upp den stora filen i små filer och använd sedan aktiviteten kopiera eller mappa dataflöde för att läsa mappen.
- Alternativ 4: Om du har fastnat eller uppfyller OOM-problemet under kopieringen av mappen XML/Excel/JSON använder du aktiviteten foreach aktivitet + kopiera/mappa dataflöde i pipelinen för att hantera varje fil eller undermapp.
- Alternativ 5: Andra:
- För XML använder du Notebook-aktivitet med minnesoptimerade kluster för att läsa data från filer om varje fil har samma schema. Spark har för närvarande olika implementeringar för att hantera XML.
- För JSON använder du olika dokumentformulär (till exempel Enskilt dokument, Dokument per rad och Matris med dokument) i JSON-inställningar under mappning av dataflödeskälla. Om JSON-filinnehållet är Dokument per rad förbrukar det mycket lite minne.
Andra referenser
Här är prestandaövervaknings- och justeringsreferenser för några av de datalager som stöds:
- Azure Blob Storage: Skalbarhets- och prestandamål för bloblagring och checklista för prestanda och skalbarhet för Blob Storage.
- Azure Table Storage: Skalbarhets- och prestandamål för tabelllagring och checklista för prestanda och skalbarhet för Table Storage.
- Azure SQL Database: Du kan övervaka prestanda och kontrollera procentandelen databastransaktionsenhet (DTU).
- Azure Synapse Analytics: Dess kapacitet mäts i DWU:er (Data Warehouse Units). Se Hantera beräkningskraft i Azure Synapse Analytics (översikt).
- Azure Cosmos DB: Prestandanivåer i Azure Cosmos DB.
- SQL Server: Övervaka och finjustera prestanda.
- Lokal filserver: Prestandajustering för filservrar.
Relaterat innehåll
Se de andra artiklarna om kopieringsaktivitet:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för