Använda Azure Data Factory för att migrera data från Amazon S3 till Azure Storage
GÄLLER FÖR:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Azure Data Factory tillhandahåller en högpresterande, robust och kostnadseffektiv mekanism för att migrera data i stor skala från Amazon S3 till Azure Blob Storage eller Azure Data Lake Storage Gen2. Den här artikeln innehåller följande information för datatekniker och utvecklare:
- Föreställning
- Kopiera motståndskraft
- Nätverkssäkerhet
- Arkitektur för högnivålösningar
- Metodtips för implementering
Prestanda
ADF erbjuder en serverlös arkitektur som möjliggör parallellitet på olika nivåer, vilket gör att utvecklare kan bygga pipelines för att fullt ut utnyttja din nätverksbandbredd och lagrings-IOPS och bandbredd för att maximera dataflyttens dataflöde för din miljö.
Kunder har migrerat petabyte med data som består av hundratals miljoner filer från Amazon S3 till Azure Blob Storage, med ett varaktigt dataflöde på 2 GBIT/s och högre.
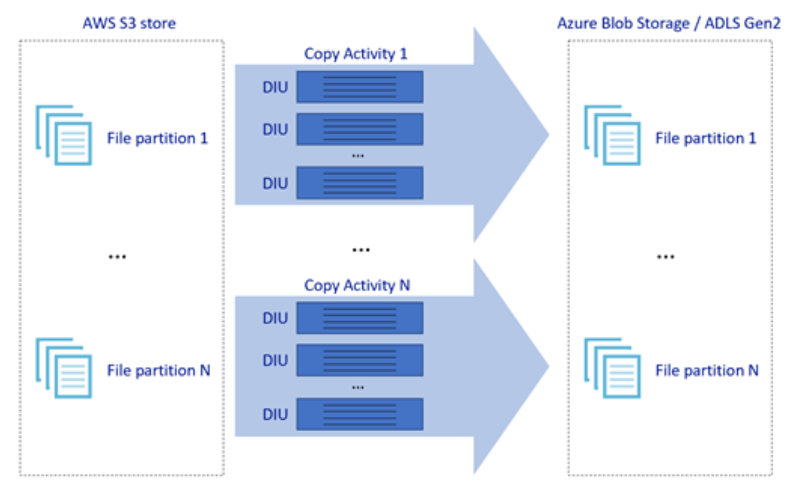
Bilden ovan visar hur du kan uppnå stora dataförflyttningshastigheter genom olika nivåer av parallellitet:
- En enskild kopieringsaktivitet kan dra nytta av skalbara beräkningsresurser: när du använder Azure Integration Runtime kan du ange upp till 256 DIU:er för varje kopieringsaktivitet på ett serverlöst sätt. När du använder lokalt installerad integrationskörning kan du skala upp datorn manuellt eller skala ut till flera datorer (upp till fyra noder) och en enskild kopieringsaktivitet partitionera dess filuppsättning över alla noder.
- En enskild kopieringsaktivitet läser från och skriver till datalagret med hjälp av flera trådar.
- ADF-kontrollflödet kan starta flera kopieringsaktiviteter parallellt, till exempel med hjälp av For Each-loopen.
Elasticitet
I en enda kopieringsaktivitetskörning har ADF inbyggd mekanism för återförsök så att den kan hantera en viss nivå av tillfälliga fel i datalager eller i det underliggande nätverket.
När du kopierar binärt från S3 till Blob och från S3 till ADLS Gen2 utför ADF automatiskt kontrollpunkter. Om en kopieringsaktivitetskörning har misslyckats eller överskridit tidsgränsen återupptas kopian från den senaste felpunkten vid ett efterföljande återförsök i stället för från början.
Nätverkssäkerhet
Som standard överför ADF data från Amazon S3 till Azure Blob Storage eller Azure Data Lake Storage Gen2 med krypterad anslutning via HTTPS-protokollet. HTTPS tillhandahåller datakryptering under överföring och förhindrar avlyssning och man-in-the-middle-attacker.
Om du inte vill att data ska överföras via offentligt Internet kan du också uppnå högre säkerhet genom att överföra data via en privat peeringlänk mellan AWS Direct Connect och Azure Express Route. Se lösningsarkitekturen i nästa avsnitt om hur detta kan uppnås.
Lösningsarkitekturen
Migrera data via offentligt Internet:
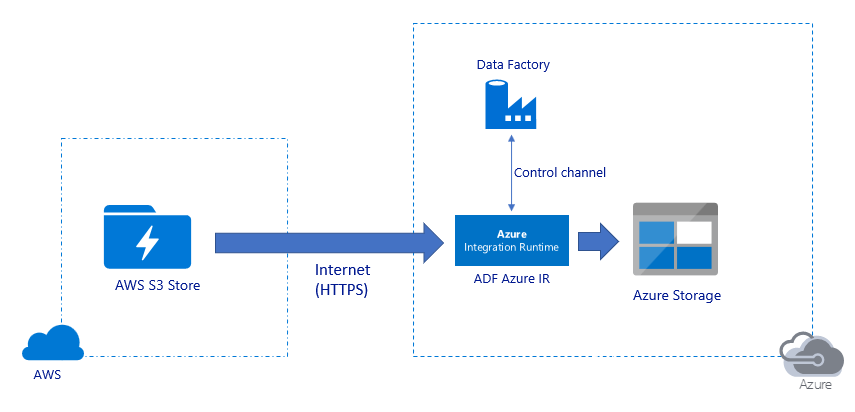
- I den här arkitekturen överförs data på ett säkert sätt med hjälp av HTTPS via offentligt Internet.
- Både Amazon S3-källan och målet Azure Blob Storage eller Azure Data Lake Storage Gen2 har konfigurerats för att tillåta trafik från alla nätverks-IP-adresser. Se den andra arkitekturen som refereras senare på den här sidan om hur du kan begränsa nätverksåtkomsten till ett specifikt IP-intervall.
- Du kan enkelt skala upp mängden hästkrafter på ett serverlöst sätt för att fullt ut utnyttja nätverks- och lagringsbandbredden så att du kan få det bästa dataflödet för din miljö.
- Både inledande migrering av ögonblicksbilder och migrering av deltadata kan uppnås med hjälp av den här arkitekturen.
Migrera data via privat länk:
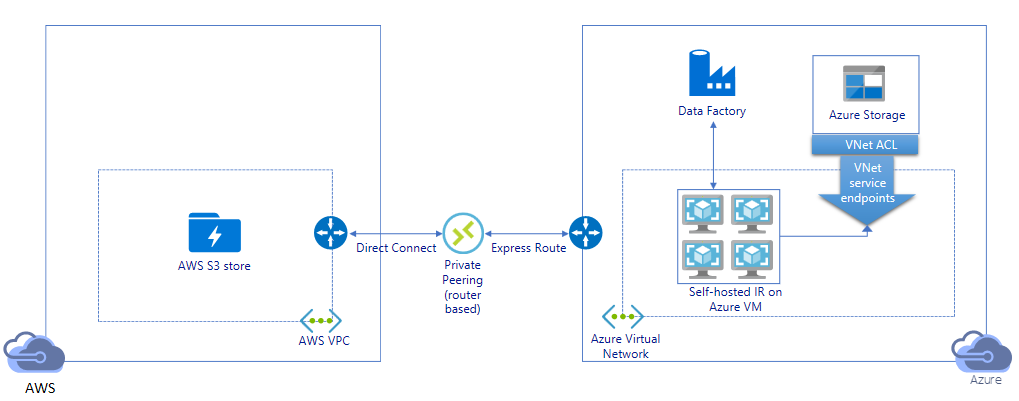
- I den här arkitekturen utförs datamigrering via en privat peeringlänk mellan AWS Direct Connect och Azure Express Route så att data aldrig passerar via offentligt Internet. Det kräver användning av AWS VPC och Azure Virtual Network.
- Du måste installera en lokalt installerad ADF-integreringskörning på en virtuell Windows-dator i ditt virtuella Azure-nätverk för att uppnå den här arkitekturen. Du kan skala upp dina lokala virtuella IR-datorer manuellt eller skala ut till flera virtuella datorer (upp till fyra noder) för att fullt ut utnyttja ditt nätverks- och lagrings-IOPS/bandbredd.
- Både inledande migrering av ögonblicksbildsdata och deltadatamigrering kan uppnås med hjälp av den här arkitekturen.
Metodtips för implementering
Hantering av autentiserings- och autentiseringsuppgifter
- Om du vill autentisera till Amazon S3-kontot måste du använda åtkomstnyckeln för IAM-kontot.
- Flera autentiseringstyper stöds för att ansluta till Azure Blob Storage. Användning av hanterade identiteter för Azure-resurser rekommenderas starkt: med hjälp av en automatiskt hanterad ADF-identifiering i Microsoft Entra-ID kan du konfigurera pipelines utan att ange autentiseringsuppgifter i definitionen för länkad tjänst. Du kan också autentisera till Azure Blob Storage med tjänstens huvudnamn, signatur för delad åtkomst eller lagringskontonyckel.
- Flera autentiseringstyper stöds också för att ansluta till Azure Data Lake Storage Gen2. Användning av hanterade identiteter för Azure-resurser rekommenderas starkt, även om tjänstens huvudnamn eller lagringskontonyckel också kan användas.
- När du inte använder hanterade identiteter för Azure-resurser rekommenderar vi starkt att du lagrar autentiseringsuppgifterna i Azure Key Vault för att göra det enklare att centralt hantera och rotera nycklar utan att ändra ADF-länkade tjänster. Detta är också en av metodtipsen för CI/CD.
Initial datamigrering av ögonblicksbilder
Datapartition rekommenderas särskilt när du migrerar mer än 100 TB data. Om du vill partitionering av data använder du prefixinställningen för att filtrera mapparna och filerna i Amazon S3 efter namn, och sedan kan varje ADF-kopieringsjobb kopiera en partition i taget. Du kan köra flera ADF-kopieringsjobb samtidigt för bättre dataflöde.
Om något av kopieringsjobben misslyckas på grund av ett tillfälligt problem med nätverket eller datalagret kan du köra det misslyckade kopieringsjobbet igen för att läsa in den specifika partitionen igen från AWS S3. Alla andra kopieringsjobb som läser in andra partitioner påverkas inte.
Deltadatamigrering
Det mest högpresterande sättet att identifiera nya eller ändrade filer från AWS S3 är att använda tidspartitionerad namngivningskonvention – när dina data i AWS S3 har partitionerats med tidssektorinformation i fil- eller mappnamnet (till exempel /åååå/mm/dd/file.csv) kan pipelinen enkelt identifiera vilka filer/mappar som ska kopieras stegvis.
Om dina data i AWS S3 inte är tidspartitionerade kan ADF identifiera nya eller ändrade filer med lastModifiedDate. ADF genomsöker alla filer från AWS S3 och kopierar bara den nya och uppdaterade filen vars senast ändrade tidsstämpel är större än ett visst värde. Om du har ett stort antal filer i S3 kan den inledande filgenomsökningen ta lång tid oavsett hur många filer som matchar filtervillkoret. I det här fallet rekommenderas du att partitionering av data först, med samma prefixinställning för inledande ögonblicksbildsmigrering, så att filgenomsökningen kan ske parallellt.
För scenarier som kräver lokalt installerad integrationskörning på en virtuell Azure-dator
Oavsett om du migrerar data via privat länk eller om du vill tillåta specifika IP-intervall i Amazon S3-brandväggen måste du installera integrationskörning med egen värd på en virtuell Azure Windows-dator.
- Den rekommenderade konfigurationen som ska börja med för varje virtuell Azure-dator är Standard_D32s_v3 med 32 vCPU och 128 GB minne. Du kan fortsätta övervaka processor- och minnesanvändningen för den virtuella IR-datorn under datamigreringen för att se om du behöver skala upp den virtuella datorn ytterligare för bättre prestanda eller skala ned den virtuella datorn för att spara kostnader.
- Du kan också skala ut genom att associera upp till fyra VM-noder med en enda lokalt installerad IR. Ett enda kopieringsjobb som körs mot en lokalt installerad IR partitionerar automatiskt filuppsättningen och använder alla VM-noder för att kopiera filerna parallellt. För hög tillgänglighet rekommenderar vi att du börjar med två VM-noder för att undvika en felpunkt under datamigreringen.
Frekvensbegränsning
Vi rekommenderar att du utför en poc-prestanda med en representativ exempeldatauppsättning så att du kan fastställa en lämplig partitionsstorlek.
Börja med en enskild partition och en enskild kopieringsaktivitet med standardinställningen DIU. Öka diu-inställningen gradvis tills du når bandbreddsgränsen för nätverket eller IOPS/bandbreddsgränsen för datalager, eller så har du nått max 256 DIU som tillåts för en enda kopieringsaktivitet.
Öka sedan gradvis antalet samtidiga kopieringsaktiviteter tills du når gränserna för din miljö.
När du stöter på begränsningsfel som rapporteras av ADF-kopieringsaktiviteten kan du antingen minska samtidigheten eller DIU-inställningen i ADF eller överväga att öka bandbredds-/IOPS-gränserna för nätverket och datalager.
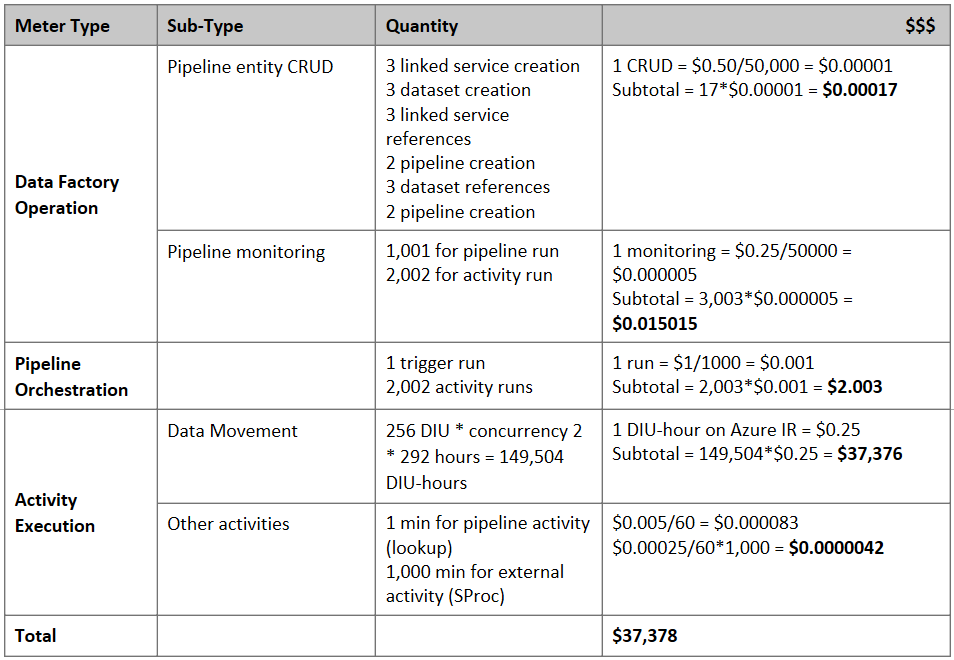
Beräkna pris
Kommentar
Det här är ett hypotetiskt prisexempel. Din faktiska prissättning beror på det faktiska dataflödet i din miljö.
Överväg följande pipeline som skapats för migrering av data från S3 till Azure Blob Storage:
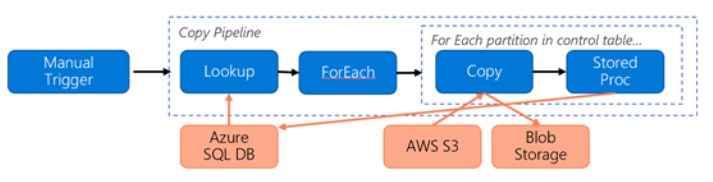
Låt oss anta följande:
- Den totala datavolymen är 2 PB
- Migrera data via HTTPS med hjälp av den första lösningsarkitekturen
- 2 PB är indelat i 1 KB-partitioner och varje kopia flyttar en partition
- Varje kopia konfigureras med DIU=256 och uppnår 1 GBIT/s-dataflöde
- ForEach-samtidighet är inställt på 2 och aggregerat dataflöde är 2 GBIT/s
- Totalt tar det 292 timmar att slutföra migreringen
Här är det uppskattade priset baserat på ovanstående antaganden:
Ytterligare referenser
- Amazon Simple Storage Service-anslutningsprogram
- Azure Blob Storage-anslutningsprogram
- Azure Data Lake Storage Gen2-anslutningsprogram
- Prestandajusteringsguide för kopieringsaktivitet
- Skapa och konfigurera lokalt installerad Integration Runtime
- Ha och skalbarhet för lokalt installerad integrationskörning
- Säkerhetsöverväganden för dataflytt
- Lagra autentiseringsuppgifter i Azure Key Vault
- Kopiera filen stegvis baserat på tidspartitionerat filnamn
- Kopiera nya och ändrade filer baserat på LastModifiedDate
- Prissättningssida för ADF
Template
Här är mallen att börja med för att migrera petabyte med data som består av hundratals miljoner filer från Amazon S3 till Azure Data Lake Storage Gen2.