Vanliga frågor och svar om prognostisering i AutoML
GÄLLER FÖR:  Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
Den här artikeln besvarar vanliga frågor om prognostisering i automatisk maskininlärning (AutoML). Allmän information om prognostiseringsmetodik i AutoML finns i artikeln Översikt över prognostiseringsmetoder i AutoML .
Hur gör jag för att börja skapa prognosmodeller i AutoML?
Du kan börja med att läsa artikeln Konfigurera AutoML för att träna en tidsserieprognosmodell . Du hittar även praktiska exempel i flera Jupyter-notebook-filer:
- Exempel på cykeldelning
- Prognostisering med djupinlärning
- Lösning för många modeller
- Prognostiseringsrecept
- Avancerade prognosscenarier
Varför är AutoML långsamt för mina data?
Vi arbetar alltid med att göra AutoML snabbare och mer skalbart. För att fungera som en allmän prognostiseringsplattform utför AutoML omfattande datavalidering och komplex funktionsteknik och söker igenom ett stort modellutrymme. Den här komplexiteten kan kräva mycket tid, beroende på data och konfiguration.
En vanlig källa till långsam körning är att träna AutoML med standardinställningar för data som innehåller flera tidsserier. Kostnaden för många prognosmetoder skalas med antalet serier. Till exempel tränar metoder som Exponential Smoothing och Prophet en modell för varje tidsserie i träningsdata.
Funktionen Många modeller i AutoML skalas till dessa scenarier genom att distribuera träningsjobb över ett beräkningskluster. Den har tillämpats på data med miljontals tidsserier. Mer information finns i artikeln många modeller . Du kan också läsa om framgången för Många modeller på en högprofilerad konkurrensdatauppsättning.
Hur gör jag AutoML snabbare?
Se svaret Varför är AutoML långsamt för mina data? för att förstå varför AutoML kan vara långsamt i ditt fall.
Överväg följande konfigurationsändringar som kan påskynda ditt jobb:
- Blockera tidsseriemodeller som ARIMA och Prophet.
- Inaktivera tillbakablicksfunktioner som fördröjningar och rullande fönster.
- Minska:
- Antalet försök/iterationer.
- Tidsgräns för utvärdering/iteration.
- Tidsgräns för experiment.
- Antalet korsvalideringsveck.
- Kontrollera att tidig avslutning är aktiverat.
Vilken modelleringskonfiguration ska jag använda?
AutoML-prognostisering stöder fyra grundläggande konfigurationer:
| Konfiguration | Scenario | Fördelar | Nackdelar |
|---|---|---|---|
| Standard-AutoML | Rekommenderas om datauppsättningen har ett litet antal tidsserier som har ungefär samma historiska beteende. | – Enkelt att konfigurera från kod/SDK eller Azure Machine Learning-studio. – AutoML kan lära sig i olika tidsserier eftersom regressionsmodellerna kombinerar alla serier i träning. Mer information finns i Modellgruppering. |
– Regressionsmodeller kan vara mindre exakta om tidsserierna i träningsdata har olika beteende. – Tidsseriemodeller kan ta lång tid att träna om träningsdata har ett stort antal serier. Mer information finns i svaret Varför är AutoML långsamt för mina data? |
| AutoML med djupinlärning | Rekommenderas för datauppsättningar med mer än 1 000 observationer och potentiellt många tidsserier som uppvisar komplexa mönster. När den är aktiverad sveper AutoML över TCN-modeller (temporal convolutional neural network) under träning. Mer information finns i Aktivera djupinlärning. | – Enkelt att konfigurera från kod/SDK eller Azure Machine Learning-studio. – Möjligheter till korsinlärning eftersom TCN poolar data över alla serier. – Potentiellt högre noggrannhet på grund av den stora kapaciteten hos DNN-modeller (Deep Neural Network). Mer information finns i Prognostiseringsmodeller i AutoML. |
– Träningen kan ta mycket längre tid på grund av komplexiteten i DNN-modeller. - Serier med små mängder historik kommer sannolikt inte att dra nytta av dessa modeller. |
| Många modeller | Rekommenderas om du behöver träna och hantera ett stort antal prognosmodeller på ett skalbart sätt. Mer information finns i artikeln många modeller . | -Skalbar. - Potentiellt högre noggrannhet när tidsserier har olika beteende från varandra. |
- Ingen inlärning över tidsserier. – Du kan inte konfigurera eller köra många modelljobb från Azure Machine Learning-studio. Endast koden/SDK-upplevelsen är för närvarande tillgänglig. |
| Hierarkisk tidsserie (HTS) | Rekommenderas om serien i dina data har en kapslad, hierarkisk struktur och du behöver träna eller göra prognoser på aggregerade nivåer i hierarkin. Mer information finns i artikeln om hierarkisk tidsserieprognoser . | – Träning på aggregerade nivåer kan minska bruset i tidsserien för lövnoder och potentiellt leda till modeller med högre noggrannhet. – Du kan hämta prognoser för valfri nivå i hierarkin genom att aggregera eller disaggregera prognoser från träningsnivån. |
– Du måste ange aggregeringsnivån för träning. AutoML har för närvarande ingen algoritm för att hitta en optimal nivå. |
Anteckning
Vi rekommenderar att du använder beräkningsnoder med GPU:er när djupinlärning är aktiverat för att på bästa sätt dra nytta av hög DNN-kapacitet. Träningstiden kan vara mycket snabbare jämfört med noder med endast processorer. Mer information finns i artikeln GPU-optimerade storlekar för virtuella datorer .
Anteckning
HTS är utformat för uppgifter där träning eller förutsägelse krävs på aggregerade nivåer i hierarkin. För hierarkiska data som endast kräver träning och förutsägelse av lövnoder använder du många modeller i stället.
Hur kan jag förhindra överanpassning och dataläckage?
AutoML använder metodtips för maskininlärning, till exempel korsval av verifierade modeller, som minimerar många överanpassningsproblem. Det finns dock andra potentiella källor till överanpassning:
Indata innehåller funktionskolumner som härleds från målet med en enkel formel. En funktion som är en exakt multipel av målet kan till exempel resultera i en nästan perfekt träningspoäng. Modellen kommer dock sannolikt inte att generaliseras till out-of-sample-data. Vi rekommenderar att du utforskar data före modellträningen och släpper kolumner som "läcker" målinformationen.
Träningsdata använder funktioner som inte är kända i framtiden, fram till prognoshorisonten. AutoML:s regressionsmodeller förutsätter för närvarande att alla funktioner är kända för prognoshorisonten. Vi rekommenderar att du utforskar dina data före träningen och tar bort alla funktionskolumner som bara är kända historiskt.
Det finns betydande strukturella skillnader (regimförändringar) mellan tränings-, validerings- eller testdelen av data. Tänk till exempel på effekten av COVID-19-pandemin på efterfrågan på nästan alla bra under 2020 och 2021. Detta är ett klassiskt exempel på ett regimskifte. Överanpassning på grund av regimskifte är det mest utmanande problemet att ta itu med eftersom det är mycket scenarioberoende och kan kräva djup kunskap för att identifiera.
Som en första försvarslinje försöker du reservera 10 till 20 procent av den totala historiken för valideringsdata eller korsvalideringsdata. Det är inte alltid möjligt att reservera den här mängden valideringsdata om träningshistoriken är kort, men det är bästa praxis. Mer information finns i Tränings- och valideringsdata.
Vad betyder det om mitt träningsjobb uppnår perfekta valideringspoäng?
Du kan se perfekta poäng när du visar valideringsmått från ett träningsjobb. En perfekt poäng innebär att prognosen och det faktiska värdet i valideringsuppsättningen är desamma eller nästan desamma. Du har till exempel ett kvadratfel med rotvärdet 0,0 eller R2 på 1,0.
En perfekt valideringspoäng indikerar vanligtvis att modellen är kraftigt överanpassad, troligen på grund av dataläckage. Det bästa sättet är att inspektera data för läckage och släppa de kolumner som orsakar läckan.
Vad händer om mina tidsseriedata inte har observationer med jämna mellanrum?
AutoML:s prognosmodeller kräver alla att träningsdata regelbundet har rymdobservationer med avseende på kalendern. Detta krav omfattar fall som månatliga eller årliga observationer där antalet dagar mellan observationer kan variera. Tidsberoende data kanske inte uppfyller detta krav i två fall:
Data har en väldefinierad frekvens, men observationer som saknas skapar luckor i serien. I det här fallet försöker AutoML identifiera frekvensen, fylla i nya observationer för luckorna och imputera saknade mål- och funktionsvärden. Alternativt kan användaren konfigurera imputeringsmetoderna via SDK-inställningar eller via webbgränssnittet. Mer information finns i Anpassad funktionalisering.
Data har ingen väldefinierad frekvens. Det innebär att varaktigheten mellan observationer inte har något märkbart mönster. Transaktionsdata, som det från ett säljpunktssystem, är ett exempel. I det här fallet kan du ställa in AutoML för att aggregera dina data till en vald frekvens. Du kan välja en regelbunden frekvens som bäst passar data och modelleringsmålen. Mer information finns i Dataaggregering.
Hur gör jag för att välja det primära måttet?
Det primära måttet är viktigt eftersom dess värde på valideringsdata avgör den bästa modellen under svepning och val. Normalized root mean squared error (NRMSE) och normalized mean absolute error (NMAE) är vanligtvis de bästa alternativen för det primära måttet i prognostiseringsuppgifter.
Observera att NRMSE straffar avvikande värden i träningsdata mer än NMAE eftersom det använder kvadraten för felet för att välja mellan dem. NMAE kan vara ett bättre alternativ om du vill att modellen ska vara mindre känslig för extremvärden. Mer information finns i Regression och prognostiseringsmått.
Anteckning
Vi rekommenderar inte att du använder R2-poängen, eller R2, som ett primärt mått för prognostisering.
Anteckning
AutoML stöder inte anpassade funktioner eller funktioner som tillhandahålls av användaren för det primära måttet. Du måste välja ett av de fördefinierade primära måtten som AutoML stöder.
Hur kan jag förbättra min modells noggrannhet?
- Se till att du konfigurerar AutoML på bästa sätt för dina data. Mer information finns i svaret Vilken modelleringskonfiguration ska jag använda?
- Läs notebook-filen med prognosrecept för stegvisa guider om hur du skapar och förbättrar prognosmodeller.
- Utvärdera modellen med hjälp av bakåttester under flera prognoscykler. Den här proceduren ger en mer robust uppskattning av prognosfel och ger dig en baslinje att mäta förbättringar mot. Ett exempel finns i notebook-filen för back-testing.
- Om data är bullriga kan du överväga att aggregera dem till en grämare frekvens för att öka signal-till-brus-förhållandet. Mer information finns i Frekvens och måldataaggregering.
- Lägg till nya funktioner som kan hjälpa dig att förutsäga målet. Ämnesexpertis kan vara till stor hjälp när du väljer träningsdata.
- Jämför validerings- och testmåttvärden och kontrollera om den valda modellen underanpassar eller överanpassar data. Den här kunskapen kan vägleda dig till en bättre träningskonfiguration. Du kan till exempel fastställa att du behöver använda fler korsvalideringsveck som svar på överanpassning.
Kommer AutoML alltid att välja samma bästa modell från samma träningsdata och konfiguration?
AutoML:s modellsökningsprocess är inte deterministisk, så den väljer inte alltid samma modell från samma data och konfiguration.
Hur gör jag för att åtgärda ett out-of-memory-fel?
Det finns två typer av minnesfel:
- RAM-minne utan minne
- Disken har slut på minne
Kontrollera först att du konfigurerar AutoML på bästa sätt för dina data. Mer information finns i svaret Vilken modelleringskonfiguration ska jag använda?
För standardinställningar för AutoML kan du åtgärda minnesfel med RAM-minne med hjälp av beräkningsnoder med mer RAM-minne. En allmän regel är att mängden ledigt RAM-minne ska vara minst 10 gånger större än rådatastorleken för att köra AutoML med standardinställningar.
Du kan lösa fel med slut minne på diskar genom att ta bort beräkningsklustret och skapa ett nytt.
Vilka avancerade prognosscenarier stöder AutoML?
AutoML stöder följande avancerade förutsägelsescenarier:
- Kvantilprognoser
- Robust modellutvärdering via löpande prognoser
- Prognoser utanför prognoshorisonten
- Prognostisering när det finns en tidsskillnad mellan tränings- och prognosperioder
Exempel och information finns i notebook-filen för avancerade prognostiseringsscenarier.
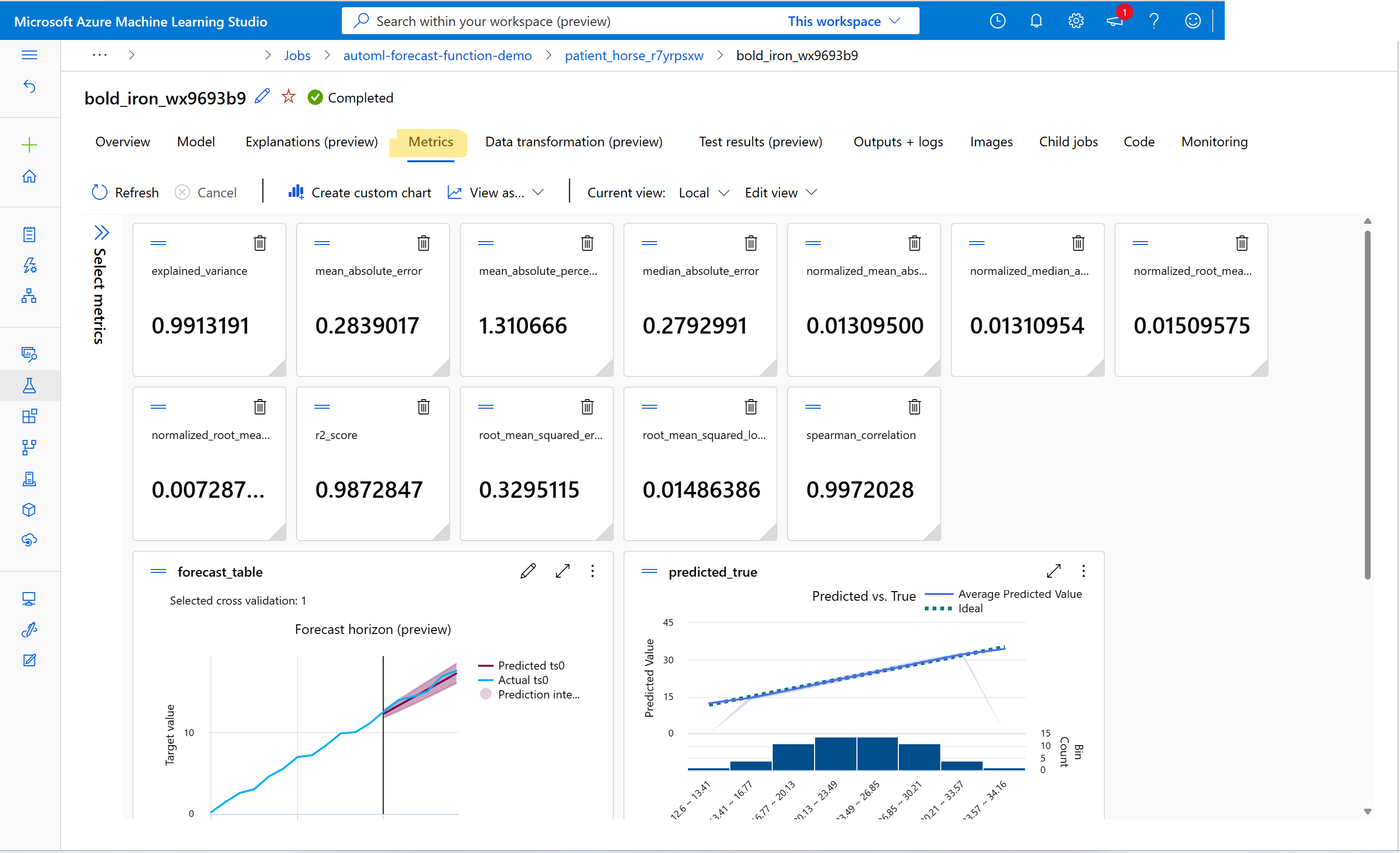
Hur gör jag för att visa mått från prognostisering av träningsjobb?
Information om hur du hittar måttvärden för träning och validering finns i Visa jobb/kör information i studion. Du kan visa mått för alla prognosmodeller som tränats i AutoML genom att gå till en modell från AutoML-jobbgränssnittet i studion och välja fliken Mått .
Hur gör jag för att felsöka fel med prognostisering av träningsjobb?
Om autoML-prognosjobbet misslyckas kan ett felmeddelande i studiogränssnittet hjälpa dig att diagnostisera och åtgärda problemet. Den bästa källan till information om felet utöver felmeddelandet är drivrutinsloggen för jobbet. Anvisningar om hur du hittar drivrutinsloggar finns i Visa jobb/kör information med MLflow.
Anteckning
För ett många modeller eller HTS-jobb är träning vanligtvis på beräkningskluster med flera noder. Loggar för de här jobben finns för varje nod-IP-adress. I det här fallet måste du söka efter felloggar i varje nod. Felloggarna, tillsammans med drivrutinsloggarna, finns i mappen user_logs för varje nod-IP.
Hur gör jag för att distribuera en modell från prognostisering av träningsjobb?
Du kan distribuera en modell från prognostisering av träningsjobb på något av följande sätt:
- Onlineslutpunkt: Kontrollera bedömningsfilen som används i distributionen eller välj fliken Test på slutpunktssidan i studion för att förstå strukturen för indata som distributionen förväntar sig. Se den här anteckningsboken för ett exempel. Mer information om onlinedistribution finns i Distribuera en AutoML-modell till en onlineslutpunkt.
- Batch-slutpunkt: Den här distributionsmetoden kräver att du utvecklar ett anpassat bedömningsskript. Ett exempel finns i den här notebook-filen . Mer information om batchdistribution finns i Använda batchslutpunkter för batchbedömning.
För UI-distributioner rekommenderar vi att du använder något av följande alternativ:
- Realtidsslutpunkt
- Batch-slutpunkt
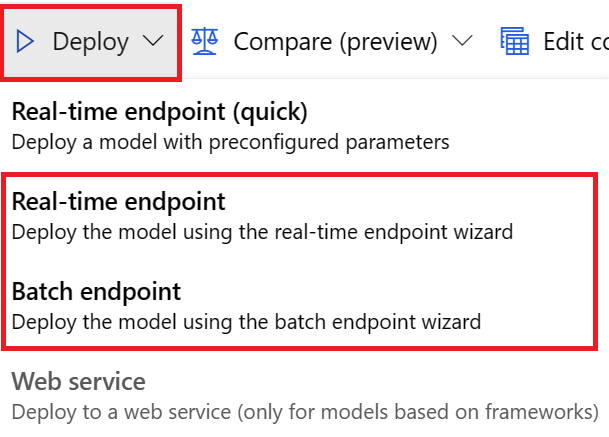
Använd inte det första alternativet Realtidsslutpunkt (snabb).
Anteckning
Från och med nu stöder vi inte distribution av MLflow-modellen från prognostisering av träningsjobb via SDK, CLI eller användargränssnitt. Du får fel om du provar det.
Vad är en arbetsyta, miljö, experiment, beräkningsinstans eller beräkningsmål?
Om du inte är bekant med Azure Machine Learning-begrepp börjar du med artiklarna Vad är Azure Machine Learning? och Vad är en Azure Machine Learning-arbetsyta?