Indexering av data från OneLake-filer och genvägar
I den här artikeln får du lära dig hur du konfigurerar en OneLake-filindexerare för att extrahera sökbara data och metadatadata från ett sjöhus ovanpå OneLake.
Använd den här indexeraren för följande uppgifter:
- Dataindexering och inkrementell indexering: Indexeraren kan indexera filer och associerade metadata från datasökvägar i ett sjöhus. Den identifierar nya och uppdaterade filer och metadata via inbyggd ändringsidentifiering. Du kan konfigurera datauppdatering enligt ett schema eller på begäran.
- Borttagningsidentifiering: Indexeraren kan identifiera borttagningar via anpassade metadata för de flesta filer och genvägar. Detta kräver att metadata läggs till i filer för att visa att de har "mjuk borttagning", vilket gör att de kan tas bort från sökindexet. För närvarande går det inte att identifiera borttagningar i Google Cloud Storage- eller Amazon S3-genvägsfiler eftersom anpassade metadata inte stöds för dessa datakällor.
- Tillämpad AI via kompetensuppsättningar: Kompetensuppsättningar stöds fullt ut av OneLake-filindexeraren. Detta omfattar viktiga funktioner som integrerad vektorisering som lägger till datasegmentering och inbäddningssteg.
- Parsningslägen: Indexeraren stöder JSON-parsningslägen om du vill parsa JSON-matriser eller rader i enskilda sökdokument.
- Kompatibilitet med andra funktioner: OneLake-indexeraren är utformad för att fungera sömlöst med andra indexerarfunktioner, till exempel felsökningssessioner, indexerarens cache för inkrementella berikanden och kunskapslager.
Använd REST API för förhandsversionen av 2024-05-01, ett Beta Azure SDK-paket eller Importera och vektorisera data i Azure-portalen för indexering från OneLake.
Den här artikeln använder REST-API:er för att illustrera varje steg.
Förutsättningar
En infrastrukturarbetsyta. Följ den här självstudien om du vill skapa en infrastrukturarbetsyta.
Ett sjöhus i en infrastrukturarbetsyta. Följ den här självstudien för att skapa ett sjöhus.
Textdata. Om du har binära data kan du använda AI-berikningsbildanalys för att extrahera text eller generera beskrivningar av bilder. Filinnehåll får inte överskrida indexeringsgränserna för söktjänstnivån.
Innehåll på platsen Filer för ditt lakehouse. Du kan lägga till data genom att:
- Ladda upp till ett sjöhus direkt
- Använda datapipelines från Microsoft Fabric
- Lägg till genvägar från externa datakällor som Amazon S3 eller Google Cloud Storage.
En AI-usluga pretrage konfigurerad för antingen en systemhanterad identitet eller användartilldelad tilldelad hanterad identitet. AI-usluga pretrage måste finnas i samma klientorganisation som Microsoft Fabric-arbetsytan.
En rolltilldelning för deltagare i Microsoft Fabric-arbetsytan där lakehouse finns. Stegen beskrivs i avsnittet Bevilja behörigheter i den här artikeln.
En REST-klient för att formulera REST-anrop som liknar de som visas i den här artikeln.
Dokumentformat som stöds
OneLake-filindexeraren kan extrahera text från följande dokumentformat:
- CSV (se Indexering av CSV-blobar)
- EML
- EPUB
- GZ
- HTML
- JSON (se Indexering av JSON-blobar)
- KML (XML för geografiska representationer)
- Microsoft kancelarija format: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (Outlook-e-post), XML (både 2003 och 2006 WORD XML)
- Öppna dokumentformat: ODT, ODS, ODP
- Oformaterade textfiler (se även Indexering av oformaterad text)
- RTF
- XML
- ZIP
Genvägar som stöds
Följande OneLake-genvägar stöds av OneLake-filindexeraren:
OneLake-genväg (en genväg till en annan OneLake-instans)
Begränsningar i den här förhandsversionen
Parquet-filtyper (inklusive deltaparquet) stöds inte för närvarande.
Filborttagning stöds inte för genvägar för Amazon S3 och Google Cloud Storage.
Den här indexeraren stöder inte innehåll för OneLake-arbetsytans tabellplats.
Den här indexeraren stöder inte SQL-frågor, men frågan som används i datakällans konfiguration är uteslutande att lägga till mappen eller genvägen för åtkomst.
Det finns inget stöd för att mata in filer från min arbetsyta i OneLake eftersom det här är en personlig lagringsplats per användare.
Förbereda data för indexering
Innan du konfigurerar indexering granskar du dina källdata för att avgöra om några ändringar ska göras i förväg. En indexerare kan indexeras från en container i taget. Som standard bearbetas alla filer i containern. Du har flera alternativ för mer selektiv bearbetning:
Placera filer i en virtuell mapp. En indexerares datakälldefinition innehåller en frågeparameter som kan vara antingen en lakehouse-undermapp eller genväg. Om det här värdet anges indexeras endast filerna i undermappen eller genvägen i lakehouse.
Inkludera eller exkludera filer efter filtyp. Listan med dokumentformat som stöds kan hjälpa dig att avgöra vilka filer som ska undantas. Du kanske till exempel vill exkludera bild- eller ljudfiler som inte tillhandahåller sökbar text. Den här funktionen styrs via konfigurationsinställningarna i indexeraren.
Inkludera eller exkludera godtyckliga filer. Om du vill hoppa över en specifik fil av någon anledning kan du lägga till metadataegenskaper och -värden i filer i ditt OneLake Lakehouse. När en indexerare stöter på den här egenskapen hoppar den över filen eller dess innehåll i indexeringskörningen.
Filinkludering och uteslutning beskrivs i indexerarens konfigurationssteg . Om du inte anger villkor rapporterar indexeraren en icke-berättigad fil som ett fel och går vidare. Om det uppstår tillräckligt många fel kan bearbetningen stoppas. Du kan ange feltolerans i konfigurationsinställningarna för indexeraren.
En indexerare skapar vanligtvis ett sökdokument per fil, där textinnehållet och metadata samlas in som sökbara fält i ett index. Om filer är hela filer kan du eventuellt parsa dem i flera sökdokument. Du kan till exempel parsa rader i en CSV-fil för att skapa ett sökdokument per rad. Om du behöver segmentera ett enda dokument i mindre passager för att vektorisera data bör du överväga att använda integrerad vektorisering.
Indexera filmetadata
Filmetadata kan också indexeras, och det är användbart om du tror att någon av standard- eller anpassade metadataegenskaperna är användbara i filter och frågor.
Användardefinierade metadataegenskaper extraheras ordagrant. Om du vill ta emot värdena måste du definiera fältet i sökindexet av typen Edm.String, med samma namn som metadatanyckeln för blobben. Om en blob till exempel har en metadatanyckel med Priority värdet Highbör du definiera ett fält med namnet Priority i sökindexet och fyllas med värdet High.
Standardegenskaper för filmetadata kan extraheras till fält med liknande namn och typ, enligt listan nedan. OneLake-filindexeraren skapar automatiskt interna fältmappningar för dessa metadataegenskaper och konverterar det ursprungliga bindestreckade namnet ("metadata-storage-name") till ett understruket motsvarande namn ("metadata_storage_name").
Du måste fortfarande lägga till de understreckade fälten i indexdefinitionen, men du kan utelämna indexeringsfältmappningar eftersom indexeraren gör associationen automatiskt.
metadata_storage_name (
Edm.String) – filnamnet. Om du till exempel har en fil /mydatalake/my-folder/subfolder/resume.pdf ärresume.pdfvärdet för det här fältet .metadata_storage_path (
Edm.String) – blobens fullständiga URI, inklusive lagringskontot. Till exempel:https://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String) – innehållstyp enligt den kod som du använde för att ladda upp bloben. Exempel:application/octet-streammetadata_storage_last_modified (
Edm.DateTimeOffset) – senast ändrad tidsstämpel för bloben. Azure AI Search använder den här tidsstämpeln för att identifiera ändrade blobbar för att undvika att indexera om allt efter den första indexeringen.metadata_storage_size (
Edm.Int64) – blobstorlek i byte.metadata_storage_content_md5 (
Edm.String) – MD5-hash för blobinnehållet, om det är tillgängligt.
Slutligen kan metadataegenskaper som är specifika för dokumentformatet för de filer som du indexerar också representeras i indexschemat. Mer information om innehållsspecifika metadata finns i Egenskaper för innehållsmetadata.
Det är viktigt att påpeka att du inte behöver definiera fält för alla ovanstående egenskaper i ditt sökindex – samla bara in de egenskaper du behöver för ditt program.
Bevilja behörigheter
OneLake-indexeraren använder tokenautentisering och rollbaserad åtkomst för anslutningar till OneLake. Behörigheter tilldelas i OneLake. Det finns inga behörighetskrav för de fysiska datalager som stöder genvägarna. Om du till exempel indexerar från AWS behöver du inte bevilja söktjänstbehörigheter i AWS.
Den minsta rolltilldelningen för din söktjänstidentitet är Deltagare.
Konfigurera en system- eller användarhanterad identitet för din AI-usluga pretrage.
Följande skärmbild visar en systemhanterad identitet för en söktjänst med namnet "onelake-demo".

Den här skärmbilden visar en användarhanterad identitet för samma söktjänst.
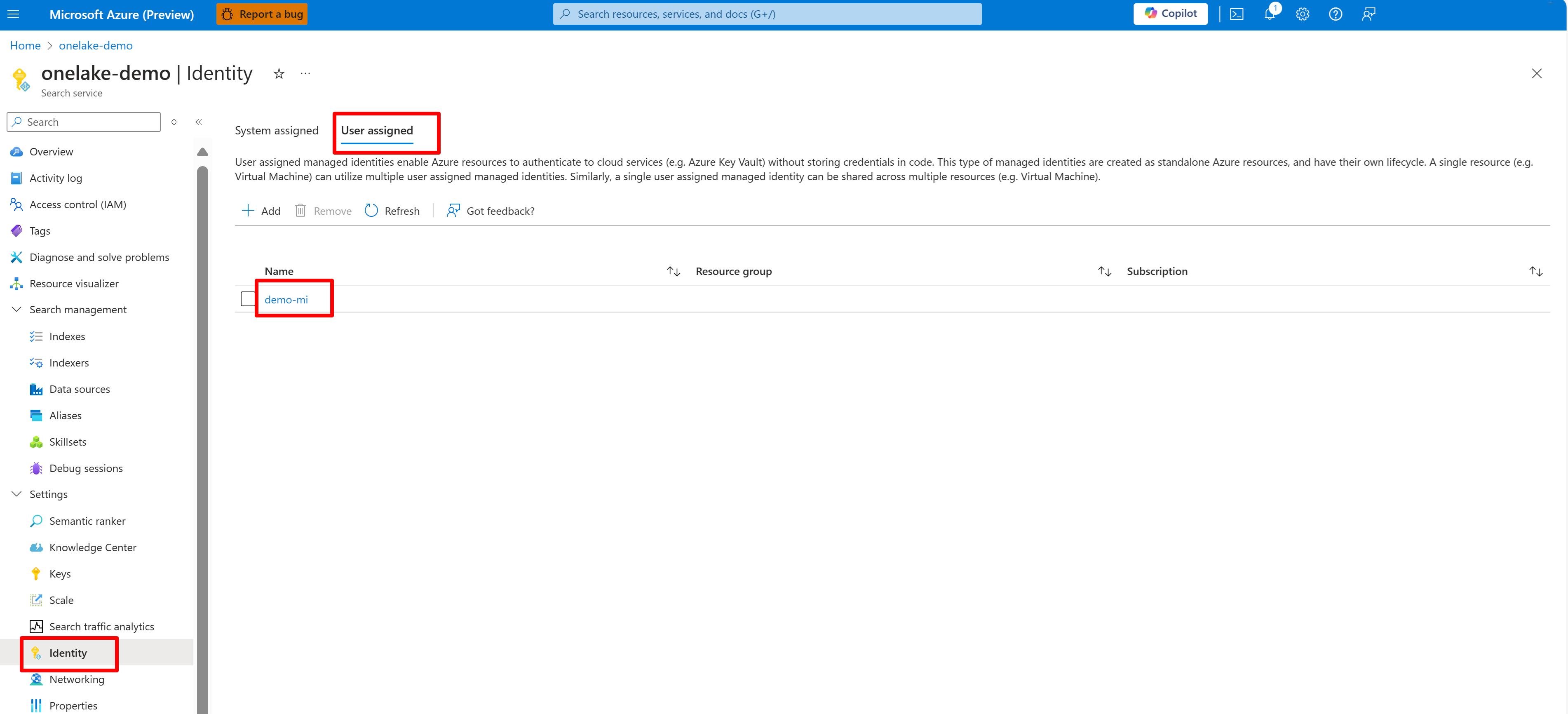
Bevilja behörighet för söktjänståtkomst till arbetsytan Infrastrukturresurser. Söktjänsten upprättar anslutningen åt indexeraren.
Om du använder en systemtilldelad hanterad identitet söker du efter namnet på AI-usluga pretrage. Om du vill ha en användartilldelad hanterad identitet söker du efter namnet på identitetsresursen.
Följande skärmbild visar en rolltilldelning för deltagare med hjälp av en systemhanterad identitet.

Den här skärmbilden visar en rolltilldelning för deltagare med hjälp av en systemhanterad identitet:





Definiera datakällan
En datakälla definieras som en oberoende resurs så att den kan användas av flera indexerare. Du måste använda REST API:et för förhandsversionen av 2024-05-01 för att skapa datakällan.
Använd REST-API:et Skapa eller uppdatera en datakälla för att ange dess definition. Det här är de viktigaste stegen i definitionen.
Ange
"type"till"onelake"(krävs).Hämta MICROSOFT Fabric-arbetsytans GUID och lakehouse GUID:
Gå till lakehouse som du vill importera data från dess URL. Det bör se ut ungefär som i det här exemplet: "https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi". Kopiera följande värden som används i datakällans definition:
Kopiera arbetsytans GUID som vi anropar
{FabricWorkspaceGuid}, som visas direkt efter "grupper" i URL:en. I det här exemplet skulle det vara 00000000-0000-0000-0000-00000000000000.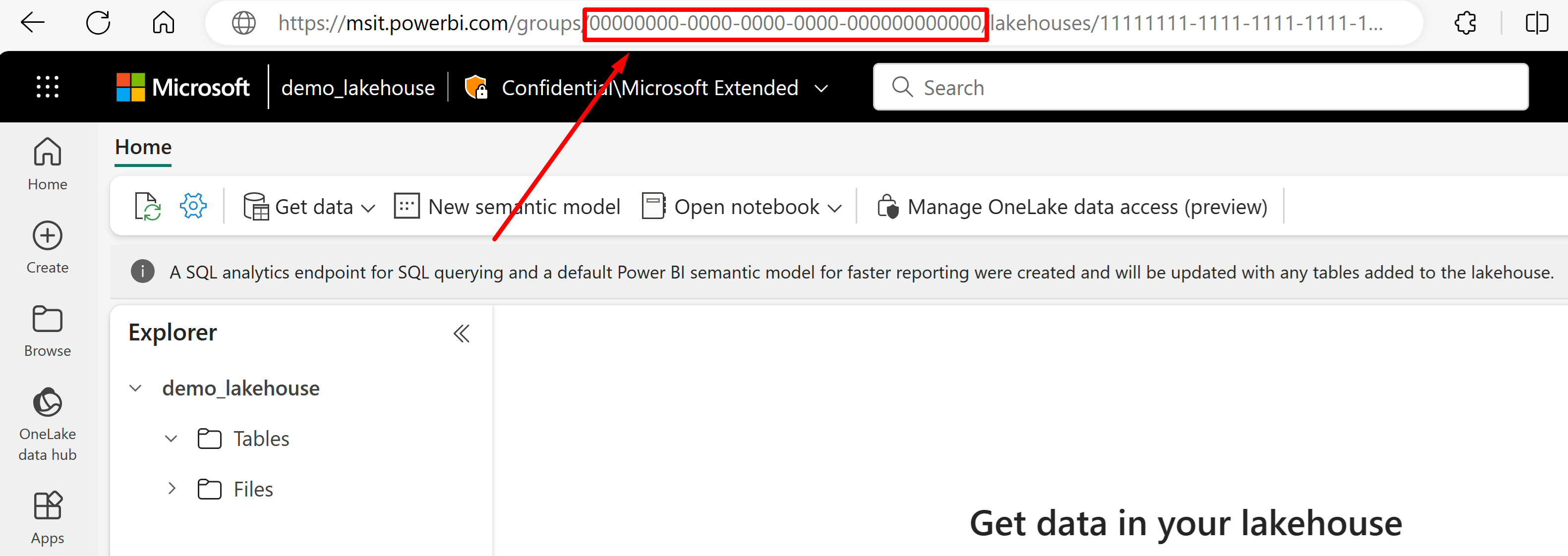
Kopiera lakehouse-GUID:et som vi anropar
{lakehouseGuid}, som visas direkt efter "lakehouses" i URL:en. I det här exemplet skulle det vara 111111111-1111-1111-1111-11111111111111111.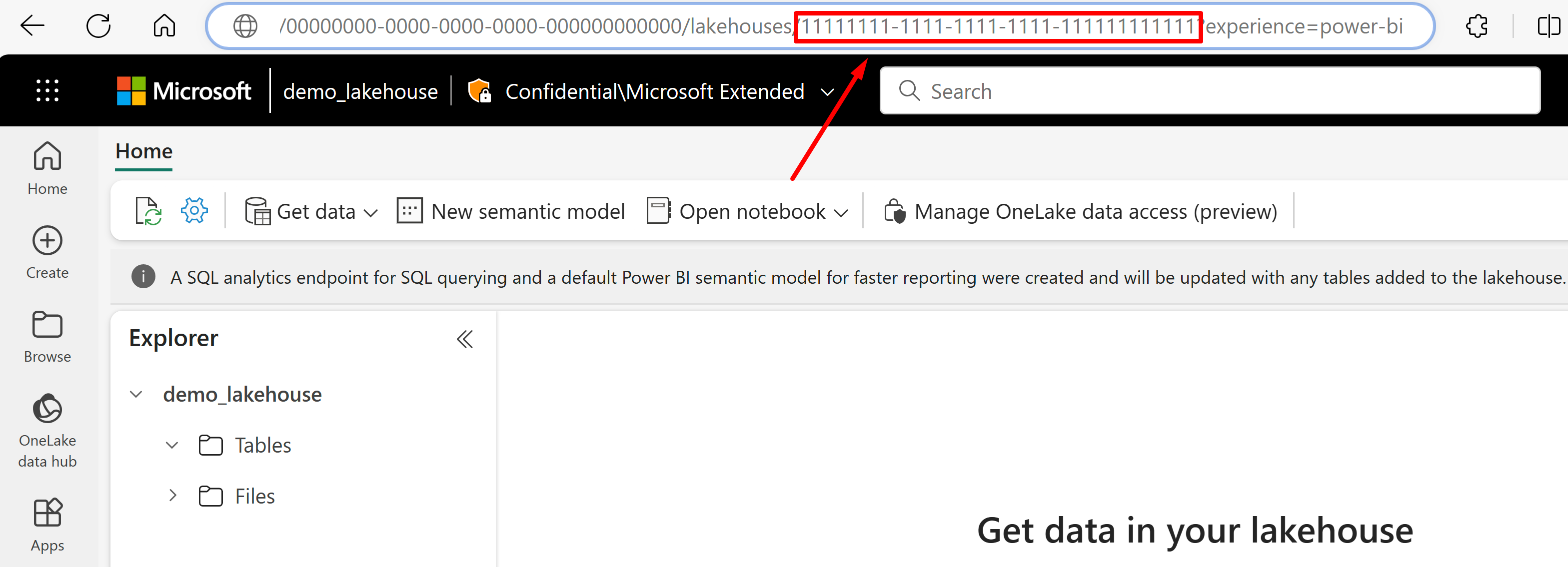
Ange
"credentials"till MICROSOFT Fabric-arbetsytans GUID genom att{FabricWorkspaceGuid}ersätta med det värde som du kopierade i föregående steg. Det här är OneLake för åtkomst med den hanterade identitet som du konfigurerar senare i den här guiden."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }Ange
"container.name"till lakehouse GUID och ersätt{lakehouseGuid}med det värde som du kopierade i föregående steg. Använd"query"om du vill ange en lakehouse-undermapp eller genväg."container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }Ange autentiseringsmetoden med den användartilldelade hanterade identiteten eller gå vidare till nästa steg för systemhanterad identitet.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }Du
userAssignedIdentityhittar värdet genom att komma åt resursen{userAssignedManagedIdentity}under Egenskaper och kallasIdför .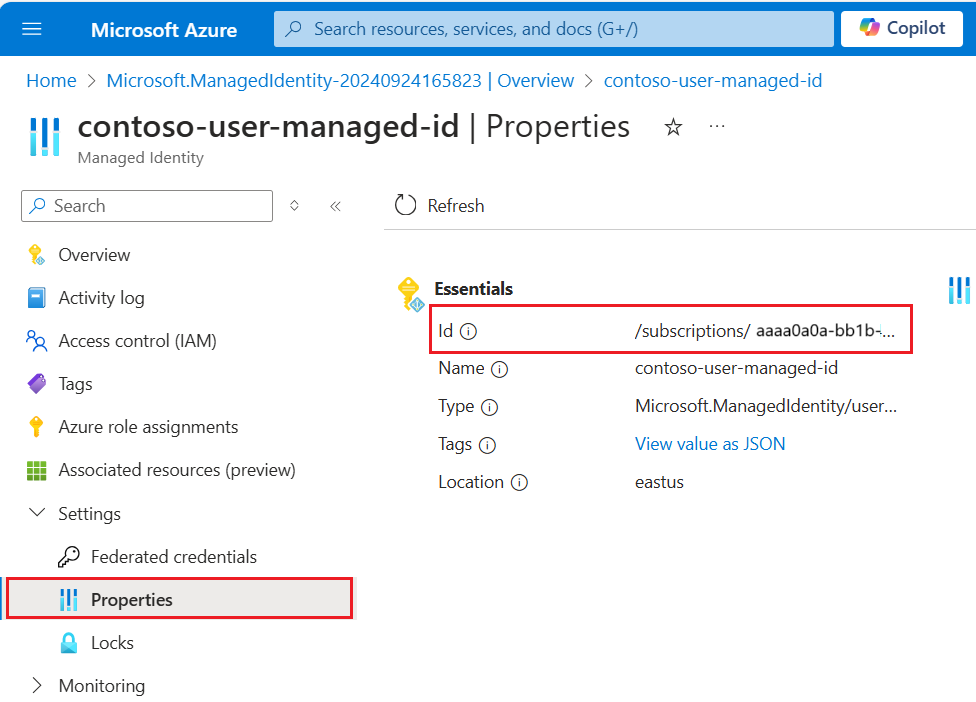
Exempel:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=00000000-0000-0000-0000-000000000000" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }Du kan också använda en systemtilldelad hanterad identitet i stället. "Identiteten" tas bort från definitionen om du använder systemtilldelad hanterad identitet.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }Exempel:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=00000000-0000-0000-0000-000000000000" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



Identifiera borttagningar via anpassade metadata
Datakälldefinitionen för OneLake-filer kan innehålla en princip för mjuk borttagning om du vill att indexeraren ska ta bort ett sökdokument när källdokumentet flaggas för borttagning.
Om du vill aktivera automatisk borttagning av filer använder du anpassade metadata för att ange om ett sökdokument ska tas bort från indexet.
Arbetsflödet kräver tre separata åtgärder:
- "Soft-delete" filen i OneLake
- Indexeraren tar bort sökdokumentet i indexet
- "Hård borttagning" av filen i OneLake
"Mjuk borttagning" talar om för indexeraren vad du ska göra (ta bort sökdokumentet). Om du tar bort den fysiska filen i OneLake först finns det inget som indexeraren kan läsa och motsvarande sökdokument i indexet är överblivet.
Det finns steg att följa i både OneLake och Azure AI Search, men det finns inga andra funktionsberoenden.
I lakehouse-filen lägger du till ett nyckel/värde-par för anpassade metadata i filen för att ange att filen har flaggats för borttagning. Du kan till exempel ge egenskapen namnet "IsDeleted", inställt på false. När du vill ta bort filen ändrar du den till true.
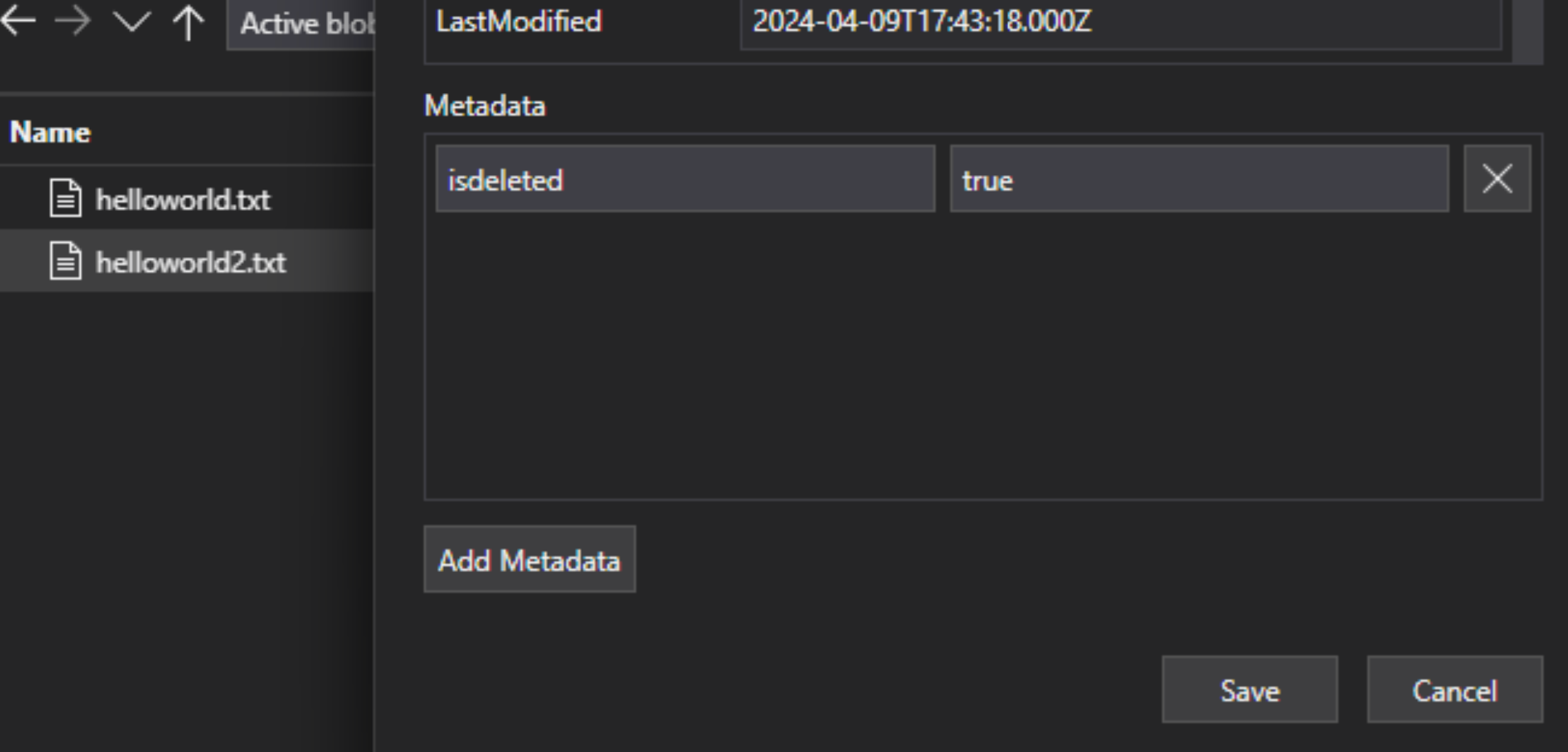
I Azure AI Search redigerar du datakälldefinitionen så att den innehåller egenskapen "dataDeletionDetectionPolicy". Följande princip anser till exempel att en fil tas bort om den har metadataegenskapen "IsDeleted" med värdet true:
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

När indexeraren har kört och tagit bort dokumentet från sökindexet kan du sedan ta bort den fysiska filen i datasjön.
Några viktiga punkter är:
Genom att schemalägga en indexerare kan du automatisera den här processen. Vi rekommenderar scheman för alla inkrementella indexeringsscenarier.
Om borttagningsidentifieringsprincipen inte angavs vid den första indexeringskörningen måste du återställa indexeraren så att den läser den uppdaterade konfigurationen.
Kom ihåg att borttagningsidentifiering inte stöds för Amazon S3- och Google Cloud Storage-genvägar på grund av beroendet av anpassade metadata.
Lägga till sökfält i ett index
I ett sökindex lägger du till fält för att acceptera innehållet och metadata för dina OneLake-data lake-filer.
Skapa eller uppdatera ett index för att definiera sökfält som lagrar filinnehåll och metadata:
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }Skapa ett dokumentnyckelfält ("nyckel": sant). För filinnehåll är de bästa kandidaterna metadataegenskaper.
metadata_storage_path(standard) fullständig sökväg till objektet eller filen. Nyckelfältet ("ID" i det här exemplet) fylls i med värden från metadata_storage_path eftersom det är standardvärdet.metadata_storage_name, endast användbart om namnen är unika. Om du vill att det här fältet ska vara nyckeln går du"key": truetill den här fältdefinitionen.En anpassad metadataegenskap som du lägger till i dina filer. Det här alternativet kräver att filuppladdningsprocessen lägger till metadataegenskapen till alla blobar. Eftersom nyckeln är en obligatorisk egenskap kan alla filer som saknar ett värde inte indexeras. Om du använder en anpassad metadataegenskap som en nyckel bör du undvika att göra ändringar i den egenskapen. Indexerare lägger till duplicerade dokument för samma fil om nyckelegenskapen ändras.
Metadataegenskaper innehåller ofta tecken, till exempel och
-, som/är ogiltiga för dokumentnycklar. Eftersom indexeraren har egenskapen "base64EncodeKeys" (sant som standard) kodas metadataegenskapen automatiskt utan att det krävs någon konfiguration eller fältmappning.Lägg till ett "innehållsfält" för att lagra extraherad text från varje fil via filens "innehållsegenskap". Du behöver inte använda det här namnet, men om du gör det kan du dra nytta av implicita fältmappningar.
Lägg till fält för standardmetadataegenskaper. Indexeraren kan läsa anpassade metadataegenskaper, standardmetadataegenskaper och innehållsspecifika metadataegenskaper .
Konfigurera och köra OneLake-filindexeraren
När indexet och datakällan har skapats är du redo att skapa indexeraren. Indexerarens konfiguration anger indata, parametrar och egenskaper som styr körningstidsbeteenden. Du kan också ange vilka delar av en blob som ska indexeras.
Skapa eller uppdatera en indexerare genom att ge den ett namn och referera till datakällan och målindexet:
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }Ange "batchSize" om standardvärdet (10 dokument) antingen används eller överbelastar tillgängliga resurser. Standard batchstorlekar är specifika för datakällan. Filindexering anger batchstorleken till 10 dokument som en igenkänning av den större genomsnittliga dokumentstorleken.
Under "konfiguration" kontrollerar du vilka filer som indexeras baserat på filtyp eller lämnar ospecificerat för att hämta alla filer.
För
"indexedFileNameExtensions"anger du en kommaavgränsad lista över filnamnstillägg (med en inledande punkt). Gör samma sak för"excludedFileNameExtensions"att ange vilka tillägg som ska hoppas över. Om samma tillägg finns i båda listorna undantas det från indexering.Under "konfiguration" anger du "dataToExtract" för att styra vilka delar av filerna som indexeras:
"contentAndMetadata" är standardvärdet. Den anger att alla metadata och textinnehåll som extraheras från filen indexeras.
"storageMetadata" anger att endast standardfilegenskaperna och användardefinierade metadata indexeras. Även om egenskaperna dokumenteras för Azure-blobar är filegenskaperna samma för OneLkae, förutom SAS-relaterade metadata.
"allMetadata" anger att standardfilegenskaper och metadata för hittade innehållstyper extraheras från filinnehållet och indexeras.
Under "konfiguration" anger du "parsingMode" om filer ska mappas till flera sökdokument, eller om de består av oformaterad text, JSON-dokument eller CSV-filer.
Ange fältmappningar om det finns skillnader i fältnamn eller typ, eller om du behöver flera versioner av ett källfält i sökindexet.
I filindexering kan du ofta utelämna fältmappningar eftersom indexeraren har inbyggt stöd för att mappa egenskaperna "innehåll" och metadata till fält med liknande namn och typ i ett index. För metadataegenskaper ersätter indexeraren automatiskt bindestreck
-med understreck i sökindexet.
Mer information om andra egenskaper finns i Skapa en indexerare. Den fullständiga listan över parameterbeskrivningar finns i Blob-konfigurationsparametrar i REST-API:et. Parametrarna är desamma för OneLake.
Som standard körs en indexerare automatiskt när du skapar den. Du kan ändra det här beteendet genom att ange "inaktiverad" till true. Om du vill kontrollera indexerarens körning kör du en indexerare på begäran eller sätter den enligt ett schema.
Kontrollera status för indexerare
Lär dig flera metoder för att övervaka indexerarens status och körningshistorik här.
Hantera fel
Fel som ofta inträffar under indexering är innehållstyper som inte stöds, innehåll som saknas eller överdimensionerade filer. Som standard stoppas OneLake-filindexeraren så fort den stöter på en fil med en innehållstyp som inte stöds. Du kanske dock vill att indexeringen ska fortsätta även om fel inträffar och sedan felsöka enskilda dokument senare.
Tillfälliga fel är vanliga för lösningar som involverar flera plattformar och produkter. Men om du håller indexeraren enligt ett schema (till exempel var 5:e minut) bör indexeraren kunna återställa från dessa fel i följande körning.
Det finns fem indexeraregenskaper som styr indexerarens svar när fel inträffar.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| Parameter | Giltiga värden | beskrivning |
|---|---|---|
| "maxFailedItems" | -1, null eller 0, positivt heltal | Fortsätt indexering om fel inträffar när som helst under bearbetningen, antingen när du parsar blobar eller när du lägger till dokument i ett index. Ange dessa egenskaper till antalet godkända fel. Värdet -1 tillåter bearbetning oavsett hur många fel som inträffar. Annars är värdet ett positivt heltal. |
| "maxFailedItemsPerBatch" | -1, null eller 0, positivt heltal | Samma som ovan, men används för batchindexering. |
| "failOnUnsupportedContentType" | sant eller falskt | Om indexeraren inte kan fastställa innehållstypen anger du om jobbet ska fortsätta eller inte. |
| "failOnUnprocessableDocument" | sant eller falskt | Om indexeraren inte kan bearbeta ett dokument av en innehållstyp som stöds på annat sätt anger du om jobbet ska fortsätta eller inte. |
| "indexStorageMetadataOnlyForOversizedDocuments" | sant eller falskt | Överdimensionerade blobar behandlas som fel som standard. Om du anger den här parametern till true försöker indexeraren indexeras med metadata även om innehållet inte kan indexeras. Begränsningar för blobstorlek finns i Tjänstgränser. |
Nästa steg
Granska hur guiden Importera och vektorisera data fungerar och prova för den här indexeraren. Du kan använda integrerad vektorisering för att segmentera och skapa inbäddningar för vektor- eller hybridsökning med hjälp av ett standardschema.