Indexering av data från SharePoint-dokumentbibliotek
Viktigt!
Stöd för SharePoint Online-indexerare finns i offentlig förhandsversion. Det erbjuds "som det är" under Kompletterande användningsvillkor och stöds endast för bästa insats. Förhandsversionsfunktioner rekommenderas inte för produktionsarbetsbelastningar och är inte garanterade att bli allmänt tillgängliga.
Se till att gå till avsnittet om kända begränsningar innan du börjar.
Om du vill använda den här förhandsversionen fyller du i det här formuläret. Du kommer inte att få något godkännandemeddelande direkt efter eftersom en åtkomstbegäran godkänns automatiskt efter insändningen. När åtkomsten har aktiverats använder du ett REST API för förhandsversion för att indexera ditt innehåll.
Den här artikeln beskriver hur du konfigurerar en sökindexerare för indexering av dokument som lagras i SharePoint-dokumentbibliotek för fulltextsökning i Azure AI Search. Konfigurationsstegen är först följt av beteenden och scenarier
Funktioner
En indexerare i Azure AI Search är en crawler som extraherar sökbara data och metadata från en datakälla. SharePoint Online-indexeraren ansluter till din SharePoint-webbplats och indexerar dokument från ett eller flera dokumentbibliotek. Indexeraren har följande funktioner:
- Indexering av filer och metadata från ett eller flera dokumentbibliotek.
- Index inkrementellt, plocka upp bara nya och ändrade filer och metadata.
- Borttagningsidentifiering är inbyggt. Borttagning i ett dokumentbibliotek hämtas vid nästa indexeringskörning och dokumentet tas bort från indexet.
- Text och normaliserade bilder extraheras som standard från de dokument som indexeras. Du kan också lägga till en kompetensuppsättning för djupare AI-berikande, till exempel OCR eller textöversättning.
Förutsättningar
Dokumentformat som stöds
SharePoint Online-indexeraren kan extrahera text från följande dokumentformat:
- CSV (se Indexering av CSV-blobar)
- EML
- EPUB
- GZ
- HTML
- JSON (se Indexering av JSON-blobar)
- KML (XML för geografiska representationer)
- Microsoft kancelarija format: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (Outlook-e-post), XML (både 2003 och 2006 WORD XML)
- Öppna dokumentformat: ODT, ODS, ODP
- Oformaterade textfiler (se även Indexering av oformaterad text)
- RTF
- XML
- ZIP
Begränsningar och överväganden
Här är begränsningarna för den här funktionen:
Indexering av SharePoint-listor stöds inte.
Indexera SharePoint . ASPX-webbplatsinnehåll stöds inte.
OneNote-notebook-filer stöds inte.
Privat slutpunkt stöds inte.
Att byta namn på en SharePoint-mapp utlöser inte inkrementell indexering. En omdöpt mapp behandlas som nytt innehåll.
SharePoint stöder en detaljerad auktoriseringsmodell som avgör åtkomst per användare på dokumentnivå. Indexeraren hämtar inte dessa behörigheter till indexet och Azure AI Search stöder inte auktorisering på dokumentnivå. När ett dokument indexeras från SharePoint till en söktjänst är innehållet tillgängligt för alla som har läsbehörighet till indexet. Om du behöver behörigheter på dokumentnivå bör du överväga säkerhetsfilter för att trimma resultaten och automatisera kopieringen av behörigheterna på filnivå till ett fält i indexet.
Indexering av användarkrypterade filer, IRM-skyddade filer (Information Rights Management), ZIP-filer med lösenord eller liknande krypterat innehåll stöds inte. För att krypterat innehåll ska kunna bearbetas måste användaren med rätt behörighet till den specifika filen ta bort krypteringen så att objektet kan indexeras när indexeraren kör nästa schemalagda iteration.
Indexering av underwebbplatser rekursivt från en viss webbplats stöds inte.
Här är några saker att tänka på när du använder den här funktionen:
- Om du behöver en SharePoint-innehållsindexeringslösning i en produktionsmiljö kan du skapa en anpassad anslutningsapp med SharePoint Webhooks, anropa Microsoft Graph API för att exportera data till en Azure Blob-container och sedan använda Azure Blob Indexer för inkrementell indexering.
- Om din SharePoint-konfiguration tillåter att Microsoft 365-processer uppdaterar SharePoint-filsystemmetadata bör du vara medveten om att dessa uppdateringar kan utlösa SharePoint Online-indexeraren, vilket gör att indexeraren matar in dokument flera gånger. Eftersom SharePoint Online-indexeraren är en anslutning från tredje part till Azure kan indexeraren inte läsa konfigurationen eller ändra dess beteende. Den svarar på ändringar i nytt och ändrat innehåll, oavsett hur dessa uppdateringar görs. Därför bör du testa konfigurationen och förstå antalet dokumentbearbetningar innan du använder indexeraren och eventuell AI-berikning.
Konfigurera SharePoint Online-indexeraren
Om du vill konfigurera SharePoint Online-indexeraren använder du både Azure-portalen och ett REST API för förhandsversion. Du kan använda 2020-06-30-preview eller senare. Vi rekommenderar det senaste förhandsversions-API:et.
Det här avsnittet innehåller stegen. Du kan också titta på följande video.
Steg 1 (valfritt): Aktivera systemtilldelad hanterad identitet
Aktivera en systemtilldelad hanterad identitet för att automatiskt identifiera klientorganisationen som söktjänsten etableras i.
Utför det här steget om SharePoint-webbplatsen finns i samma klientorganisation som söktjänsten. Hoppa över det här steget om SharePoint-webbplatsen finns i en annan klientorganisation. Identiteten används inte för indexering, bara klientidentifiering. Du kan också hoppa över det här steget om du vill placera klientorganisations-ID:t i niska veze.
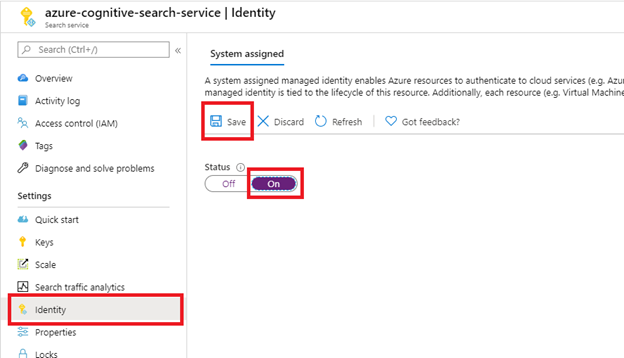
När du har valt Spara får du ett objekt-ID som har tilldelats söktjänsten.
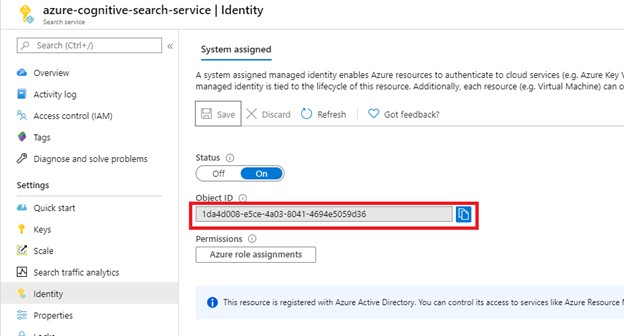
Steg 2: Bestäm vilka behörigheter indexeraren behöver
SharePoint Online-indexeraren stöder både delegerade behörigheter och programbehörigheter . Välj vilka behörigheter du vill använda baserat på ditt scenario.
Vi rekommenderar appbaserade behörigheter. Se begränsningar för kända problem som rör delegerade behörigheter.
Programbehörigheter (rekommenderas), där indexeraren körs under identiteten för SharePoint-klientorganisationen med åtkomst till alla webbplatser och filer. Indexeraren kräver en klienthemlighet. Indexeraren kräver också godkännande av klientorganisationsadministratören innan den kan indexeras.
Delegerade behörigheter, där indexeraren körs under identiteten för den användare eller app som skickar begäran. Dataåtkomst är begränsad till de webbplatser och filer som anroparen har åtkomst till. För att stödja delegerade behörigheter kräver indexeraren en uppmaning om enhetskod för att logga in för användarens räkning. Användardelegeringsbehörigheter framtvingar att token upphör att gälla var 75:e minut, enligt de senaste säkerhetsbiblioteken som används för att implementera den här autentiseringstypen. Detta är inte ett beteende som kan justeras. En token som har upphört att gälla kräver manuell indexering med Kör indexerare (förhandsversion). Därför kanske du vill ha appbaserade behörigheter i stället.
Om din Microsoft Entra-organisation har villkorlig åtkomst aktiverad och administratören inte kan bevilja någon enhetsåtkomst för delegerade behörigheter bör du överväga appbaserade behörigheter i stället. Mer information finns i Principer för villkorsstyrd åtkomst i Microsoft Entra.
Steg 3: Skapa en Microsoft Entra-programregistrering
SharePoint Online-indexeraren använder det här Microsoft Entra-programmet för autentisering.
Logga in på Azure-portalen.
Sök efter eller navigera till Microsoft Entra-ID och välj sedan Appregistreringar.
Välj + Ny registrering:
- Ange ett namn för din app.
- Välj Enskild klientorganisation.
- Hoppa över URI-beteckningssteget. Ingen omdirigerings-URI krävs.
- Välj Registrera.
Till vänster väljer du API-behörigheter och sedan Lägg till en behörighet och sedan Microsoft Graph.
Om indexeraren använder program-API-behörigheter väljer du Programbehörigheter och lägger till följande:
- Program – Files.Read.All
- Program – Sites.Read.All

Att använda programbehörigheter innebär att indexeraren kommer åt SharePoint-webbplatsen i en tjänstkontext. Så när du kör indexeraren kommer den att ha åtkomst till allt innehåll i SharePoint-klientorganisationen, vilket kräver administratörsgodkännande för klientorganisationen. En klienthemlighet krävs också för autentisering. Konfiguration av klienthemligheten beskrivs senare i den här artikeln.
Om indexeraren använder delegerade API-behörigheter väljer du Delegerade behörigheter och lägger till följande:
- Delegerad – Files.Read.All
- Delegerad – Sites.Read.All
- Delegerad – User.Read
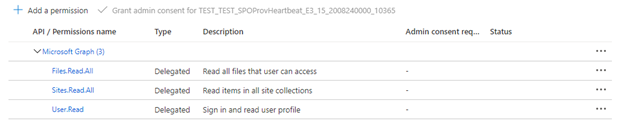
Med delegerade behörigheter kan sökklienten ansluta till SharePoint under den aktuella användarens säkerhetsidentitet.
Ge administratörsmedgivande.
Innehavaradministratörsmedgivande krävs när du använder program-API-behörigheter. Vissa klienter är låsta på ett sådant sätt att innehavaradministratörens medgivande krävs även för delegerade API-behörigheter. Om något av dessa villkor gäller måste du ha ett klientadministratörsmedgivande för det här Microsoft Entra-programmet innan du skapar indexeraren.
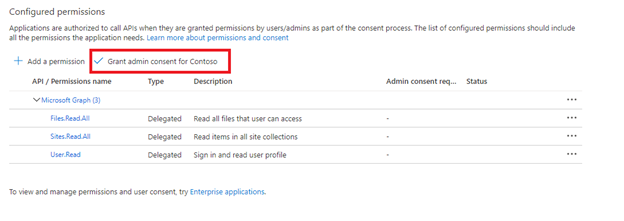
Markera fliken autentisering.
Ange Tillåt offentliga klientflöden till Ja och välj sedan Spara.
Välj + Lägg till en plattform och sedan Mobil- och skrivbordsprogram och kontrollera
https://login.microsoftonline.com/common/oauth2/nativeclientsedan och sedan Konfigurera.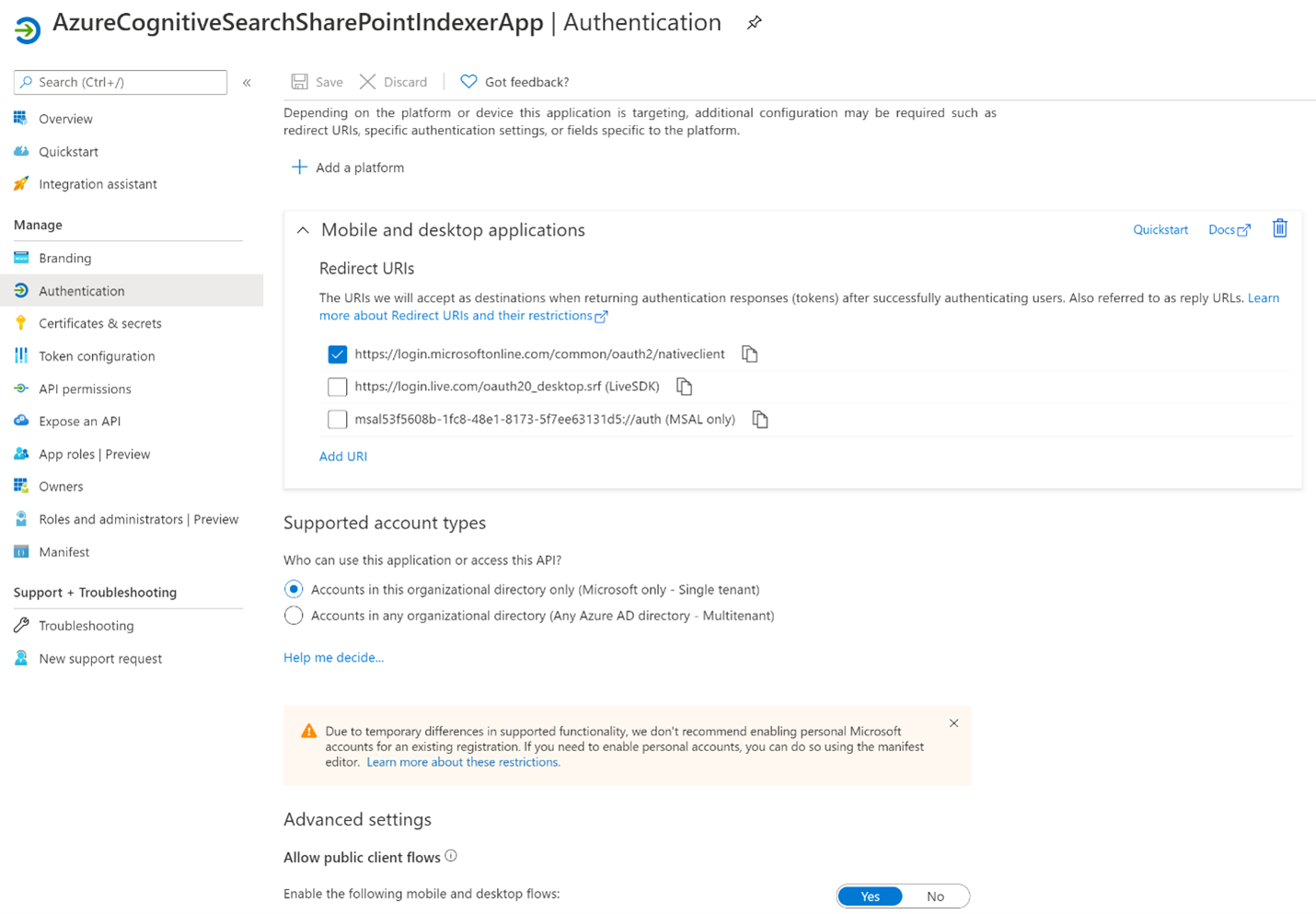
(Endast program-API-behörigheter) För att autentisera till Microsoft Entra-programmet med programbehörigheter kräver indexeraren en klienthemlighet.
Välj Certifikat och hemligheter på menyn till vänster, sedan Klienthemligheter och sedan Ny klienthemlighet.

I menyn som visas anger du en beskrivning för den nya klienthemligheten. Justera förfallodatumet om det behövs. Om hemligheten upphör att gälla måste den återskapas och indexeraren måste uppdateras med den nya hemligheten.
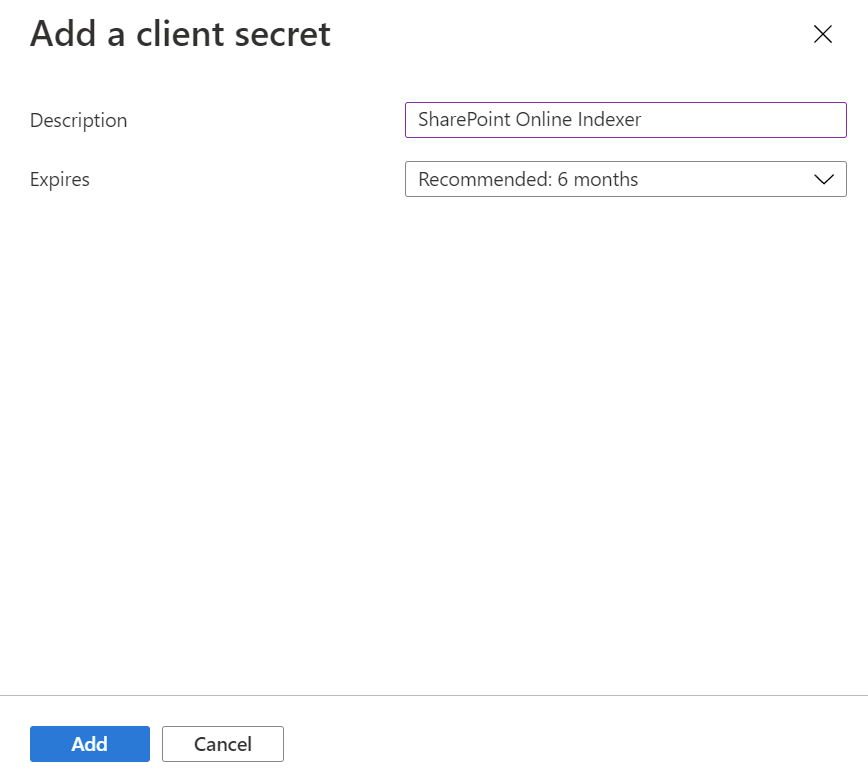
Den nya klienthemligheten visas i den hemliga listan. När du har navigerat bort från sidan är hemligheten inte längre synlig, så kopiera den med kopieringsknappen och spara den på en säker plats.

Steg 4: Skapa datakälla
Från och med det här avsnittet använder du rest-API:et för förhandsversion för de återstående stegen. Vi rekommenderar det senaste förhandsversions-API:et.
En datakälla anger vilka data som ska indexeras, autentiseringsuppgifter och principer för att effektivt identifiera ändringar i data (nya, ändrade eller borttagna rader). En datakälla kan användas av flera indexerare i samma söktjänst.
För SharePoint-indexering måste datakällan ha följande obligatoriska egenskaper:
- namn är det unika namnet på datakällan i söktjänsten.
- måste vara "sharepoint". Det här värdet är skiftlägeskänsligt.
- autentiseringsuppgifterna anger SharePoint-slutpunkten och Microsoft Entra-programmets (klient)-ID. Ett exempel på En SharePoint-slutpunkt är
https://microsoft.sharepoint.com/teams/MySharePointSite. Du kan hämta slutpunkten genom att gå till startsidan för din SharePoint-webbplats och kopiera URL:en från webbläsaren. - container anger vilket dokumentbibliotek som ska indexeras. Egenskaper styr vilka dokument som indexeras.
Om du vill skapa en datakälla anropar du Skapa datakälla (förhandsversion).
POST https://[service name].search.windows.net/datasources?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-datasource",
"type" : "sharepoint",
"credentials" : { "connectionString" : "[connection-string]" },
"container" : { "name" : "defaultSiteLibrary", "query" : null }
}
Format för anslutningssträng
Formatet för niska veze ändras baserat på om indexeraren använder delegerade API-behörigheter eller program-API-behörigheter
Delegerade API-behörigheter niska veze format
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];TenantId=[SharePoint site tenant id]Program-API-behörigheter niska veze format
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];ApplicationSecret=[Azure AD App client secret];TenantId=[SharePoint site tenant id]
Kommentar
Om SharePoint-webbplatsen finns i samma klientorganisation som söktjänsten och den systemtilldelade hanterade identiteten är aktiverad behöver TenantId den inte ingå i niska veze. Om SharePoint-webbplatsen finns i en annan klientorganisation än söktjänsten TenantId måste den inkluderas.
Steg 5: Skapa ett index
Indexet anger fälten i ett dokument, attribut och andra konstruktioner som formar sökupplevelsen.
Om du vill skapa ett index anropar du Skapa index (förhandsversion):
POST https://[service name].search.windows.net/indexes?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "metadata_spo_item_name", "type": "Edm.String", "key": false, "searchable": true, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_path", "type": "Edm.String", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_content_type", "type": "Edm.String", "key": false, "searchable": false, "filterable": true, "sortable": false, "facetable": true },
{ "name": "metadata_spo_item_last_modified", "type": "Edm.DateTimeOffset", "key": false, "searchable": false, "filterable": false, "sortable": true, "facetable": false },
{ "name": "metadata_spo_item_size", "type": "Edm.Int64", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false }
]
}
Viktigt!
Endast metadata_spo_site_library_item_id får användas som nyckelfält i ett index som fylls i av SharePoint Online-indexeraren. Om det inte finns något nyckelfält i datakällan metadata_spo_site_library_item_id mappas det automatiskt till nyckelfältet.
Steg 6: Skapa en indexerare
En indexerare ansluter en datakälla till ett målsökningsindex och tillhandahåller ett schema för att automatisera datauppdateringen. När indexet och datakällan har skapats kan du skapa indexeraren.
Om du använder delegerade behörigheter uppmanas du under det här steget att logga in med organisationsautentiseringsuppgifter som har åtkomst till SharePoint-webbplatsen. Om möjligt rekommenderar vi att du skapar ett nytt organisationsanvändarkonto och ger den nya användaren de exakta behörigheter som du vill att indexeraren ska ha.
Det finns några steg för att skapa indexeraren:
Skicka en begäran om att skapa indexerare (förhandsversion ):
POST https://[service name].search.windows.net/indexers?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key] { "name" : "sharepoint-indexer", "dataSourceName" : "sharepoint-datasource", "targetIndexName" : "sharepoint-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpg", "dataToExtract": "contentAndMetadata" } }, "schedule" : { }, "fieldMappings" : [ { "sourceFieldName" : "metadata_spo_site_library_item_id", "targetFieldName" : "id", "mappingFunction" : { "name" : "base64Encode" } } ] }Om du använder programbehörigheter måste du vänta tills den första körningen är klar innan du börjar köra frågor mot ditt index. Följande instruktioner i det här steget gäller specifikt delegerade behörigheter och gäller inte för programbehörigheter.
När du skapar indexeraren för första gången väntar begäran skapa indexerare (förhandsversion) tills du har slutfört nästa steg. Du måste anropa Hämta indexerarstatus för att hämta länken och ange din nya enhetskod.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Om du inte kör Hämta indexerarens status inom 10 minuter upphör koden att gälla och du måste återskapa datakällan.
Kopiera enhetsinloggningskoden från svaret Hämta indexerarestatus . Enhetsinloggningen finns i "errorMessage".
{ "lastResult": { "status": "transientFailure", "errorMessage": "To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code <CODE> to authenticate." } }Ange den kod som ingick i felmeddelandet.
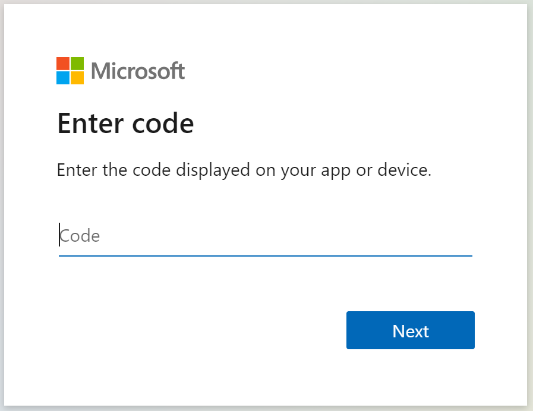
SharePoint Online-indexeraren får åtkomst till SharePoint-innehållet som den inloggade användaren. Den användare som loggar in under det här steget är den inloggade användaren. Så om du loggar in med ett användarkonto som inte har åtkomst till ett dokument i dokumentbiblioteket som du vill indexeras, har indexeraren inte åtkomst till dokumentet.
Om möjligt rekommenderar vi att du skapar ett nytt användarkonto och ger den nya användaren de exakta behörigheter som du vill att indexeraren ska ha.
Godkänn de behörigheter som begärs.
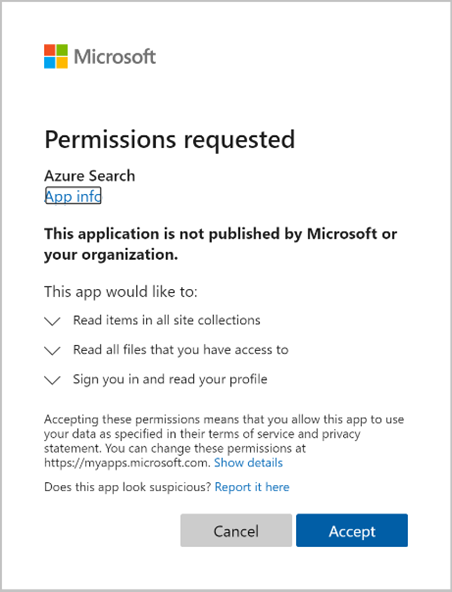
Den första begäran om att skapa indexerare (förhandsversion) slutförs om alla behörigheter som anges ovan är korrekta och inom tidsramen på 10 minuter.
Kommentar
Om Microsoft Entra-programmet kräver administratörsgodkännande och inte godkändes innan du loggar in kan följande skärm visas. Administratörsgodkännande krävs för att fortsätta.
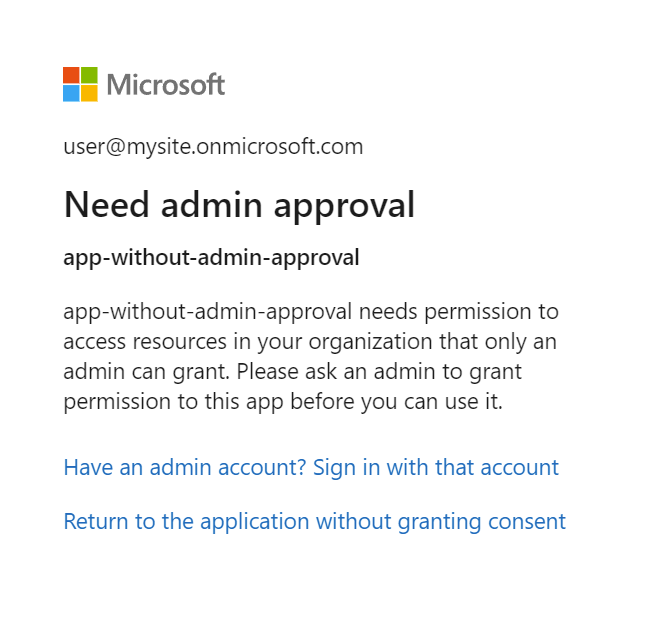
Steg 7: Kontrollera indexerarens status
När indexeraren har skapats kan du anropa Hämta indexerarstatus:
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
Uppdatera datakällan
Om det inte finns några uppdateringar av datakällans objekt körs indexeraren enligt ett schema utan någon användarinteraktion.
Men om du ändrar datakällobjektet medan enhetskoden har upphört att gälla måste du logga in igen för att indexeraren ska kunna köras. Om du till exempel ändrar datakällans fråga loggar du in igen med hjälp av https://microsoft.com/devicelogin och hämtar den nya enhetskoden.
Här följer stegen för att uppdatera en datakälla, förutsatt att enhetskoden har upphört att gälla:
Anropa Kör indexerare (förhandsversion) för att starta indexerarens körning manuellt.
POST https://[service name].search.windows.net/indexers/sharepoint-indexer/run?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Kontrollera indexerarens status.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Om du får ett felmeddelande om att du ska besöka
https://microsoft.com/deviceloginöppnar du sidan och kopierar den nya koden.Klistra in koden i dialogrutan.
Kör indexeraren manuellt igen och kontrollera indexerarens status. Den här gången bör indexerarkörningen startas.
Indexera dokumentmetadata
Om du indexerar dokumentmetadata ("dataToExtract": "contentAndMetadata") kommer följande metadata att vara tillgängliga för indexering.
| Identifierare | Typ | Beskrivning |
|---|---|---|
| metadata_spo_site_library_item_id | Edm.String | Kombinationsnyckeln för webbplats-ID, biblioteks-ID och objekt-ID, som unikt identifierar ett objekt i ett dokumentbibliotek för en webbplats. |
| metadata_spo_site_id | Edm.String | ID:t för SharePoint-webbplatsen. |
| metadata_spo_library_id | Edm.String | ID för dokumentbiblioteket. |
| metadata_spo_item_id | Edm.String | ID:t för objektet (dokumentet) i biblioteket. |
| metadata_spo_item_last_modified | Edm.DateTimeOffset | Objektets senast ändrade datum/tid (UTC). |
| metadata_spo_item_name | Edm.String | Namnet på objektet. |
| metadata_spo_item_size | Edm.Int64 | Objektets storlek (i byte). |
| metadata_spo_item_content_type | Edm.String | Objektets innehållstyp. |
| metadata_spo_item_extension | Edm.String | Objektets tillägg. |
| metadata_spo_item_weburi | Edm.String | Objektets URI. |
| metadata_spo_item_path | Edm.String | Kombinationen av den överordnade sökvägen och objektnamnet. |
SharePoint Online-indexeraren stöder även metadata som är specifika för varje dokumenttyp. Mer information finns i Egenskaper för innehållsmetadata som används i Azure AI Search.
Kommentar
Om du vill indexera anpassade metadata måste "additionalColumns" anges i frågeparametern för datakällan.
Inkludera eller exkludera efter filtyp
Du kan styra vilka filer som indexeras genom att ange inkluderings- och exkluderingsvillkor i avsnittet "parametrar" i indexerarens definition.
Inkludera specifika filnamnstillägg genom att ange "indexedFileNameExtensions" en kommaavgränsad lista med filnamnstillägg (med en inledande punkt). Exkludera specifika filnamnstillägg genom att ange "excludedFileNameExtensions" de tillägg som ska hoppas över. Om samma tillägg finns i båda listorna undantas det från indexering.
PUT /indexers/[indexer name]?api-version=2024-05-01-preview
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Kontrollera vilka dokument som indexeras
En enskild SharePoint Online-indexerare kan indexeras från ett eller flera dokumentbibliotek. Använd parametern "container" i datakällans definition för att ange vilka platser och dokumentbibliotek som ska indexeras från.
Avsnittet "container" för datakällan har två egenskaper för den här uppgiften: "name" och "query".
Name
Egenskapen "name" krävs och måste vara ett av tre värden:
| Värde | beskrivning |
|---|---|
| defaultSiteLibrary | Indexeras allt innehåll från webbplatsens standarddokumentbibliotek. |
| allSiteLibraries | Indexerar allt innehåll från alla dokumentbibliotek på en webbplats. Dokumentbibliotek från en underwebbplats ligger utanför omfånget/ Om du behöver innehåll från underwebbplatser väljer du "useQuery" och anger "includeLibrariesInSite". |
| useQuery | Indexeras endast innehållet som definierats i "frågan". |
Fråga
Parametern "query" för datakällan består av nyckelord/värde-par. Nedan visas de nyckelord som kan användas. Värdena är antingen webbplats-URL:er eller url:er för dokumentbibliotek.
Kommentar
För att hämta värdet för ett visst nyckelord rekommenderar vi att du navigerar till dokumentbiblioteket som du försöker inkludera/exkludera och kopiera URI:n från webbläsaren. Det här är det enklaste sättet att få värdet att använda med ett nyckelord i frågan.
| Nyckelord | Värdebeskrivning och exempel |
|---|---|
| NULL | Om värdet är null eller tomt indexerar du antingen standarddokumentbiblioteket eller alla dokumentbibliotek beroende på containernamnet. Exempel: "container" : { "name" : "defaultSiteLibrary", "query" : null } |
| includeLibrariesInSite | Indexerar innehåll från alla bibliotek under den angivna webbplatsen i niska veze. Värdet ska vara URI för webbplatsen eller underwebbplatsen. Exempel 1: "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/mysite" } Exempel 2 (inkludera endast några underwebbplatser): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite1;includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite2" } |
| includeLibrary | Indexeras allt innehåll från det här biblioteket. Värdet är den fullständigt kvalificerade sökvägen till biblioteket, som kan kopieras från webbläsaren: Exempel 1 (fullständigt kvalificerad sökväg): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary" } Exempel 2 (URI kopieras från webbläsaren): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| excludeLibrary | Indexeras inte innehåll från det här biblioteket. Värdet är den fullständigt kvalificerade sökvägen till biblioteket, som kan kopieras från webbläsaren: Exempel 1 (fullständigt kvalificerad sökväg): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mysite.sharepoint.com/subsite1; excludeLibrary=https://mysite.sharepoint.com/subsite1/MyDocumentLibrary" } Exempel 2 (URI kopieras från webbläsaren): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/teams/mysite; excludeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| additionalColumns | Indexkolumner från dokumentbiblioteket. Värdet är en kommaavgränsad lista med kolumnnamn som du vill indexera. Använd ett dubbelt omvänt snedstreck för att undkomma semikolon och kommatecken i kolumnnamn: Exempel 1 (additionalColumns=MyCustomColumn,MyCustomColumn2): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary;additionalColumns=MyCustomColumn,MyCustomColumn2" } Exempel 2 (escape-tecken med dubbla omvänt snedstreck): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx;additionalColumns=MyCustomColumnWith\\,,MyCustomColumnWith\\;" } |
Hantera fel
Som standard stoppas SharePoint Online-indexeraren så snart ett dokument med en innehållstyp som inte stöds (till exempel en bild) stoppas. Du kan använda parametern excludedFileNameExtensions för att hoppa över vissa innehållstyper. Du kan dock behöva indexeras dokument utan att känna till alla möjliga innehållstyper i förväg. Om du vill fortsätta indexeringen när en innehållstyp som inte stöds påträffas anger du failOnUnsupportedContentType konfigurationsparametern till false:
PUT https://[service name].search.windows.net/indexers/[indexer name]?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
... other parts of indexer definition
"parameters" : { "configuration" : { "failOnUnsupportedContentType" : false } }
}
För vissa dokument kan Azure AI Search inte fastställa innehållstypen eller kan inte bearbeta ett dokument av innehållstyp som stöds på annat sätt. Om du vill ignorera det här felläget anger du konfigurationsparametern failOnUnprocessableDocument till false:
"parameters" : { "configuration" : { "failOnUnprocessableDocument" : false } }
Azure AI Search begränsar storleken på dokument som indexeras. Dessa gränser dokumenteras i Tjänstgränser i Azure AI Search. Överdimensionerade dokument behandlas som fel som standard. Du kan dock fortfarande indexeras lagringsmetadata för överdimensionerade dokument om du ställer in indexStorageMetadataOnlyForOversizedDocuments konfigurationsparametern på sant:
"parameters" : { "configuration" : { "indexStorageMetadataOnlyForOversizedDocuments" : true } }
Du kan också fortsätta indexeringen om fel inträffar när som helst under bearbetningen, antingen när du parsar dokument eller när du lägger till dokument i ett index. Om du vill ignorera ett visst antal fel anger du maxFailedItems konfigurationsparametrarna och maxFailedItemsPerBatch till önskade värden. Till exempel:
{
... other parts of indexer definition
"parameters" : { "maxFailedItems" : 10, "maxFailedItemsPerBatch" : 10 }
}
Om en fil på SharePoint-webbplatsen har kryptering aktiverat kan ett felmeddelande som liknar följande uppstå:
Code: resourceModified Message: The resource has changed since the caller last read it; usually an eTag mismatch Inner error: Code: irmEncryptFailedToFindProtector
Felmeddelandet innehåller även SharePoint-webbplats-ID, enhets-ID och enhetsobjekt-ID i följande mönster: <sharepoint site id> :: <drive id> :: <drive item id>. Den här informationen kan användas för att identifiera vilket objekt som misslyckas i SharePoint-änden. Användaren kan sedan ta bort krypteringen från objektet för att lösa problemet.
Se även
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för