Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Lär dig hur du använder Azure SDK för .NET för att skapa en AI-berikningspipeline under indexeringen för extrahering och omvandlingar av innehåll.
Kunskapsuppsättningar lägger till AI-bearbetning till råinnehåll, vilket gör det mer enhetligt och sökbart. När du vet hur kompetensuppsättningar fungerar kan du stödja ett brett utbud av transformeringar, från bildanalys till bearbetning av naturligt språk till anpassad bearbetning som du tillhandahåller externt.
I den här handledningen kommer du att:
- Definiera objekt i en berikningspipeline.
- Bygg en kompetens. Anropa OCR, språkidentifiering, entitetsigenkänning och extrahering av nyckelfraser.
- Utför rörledningen. Skapa och läsa in ett sökindex.
- Kontrollera resultaten med hjälp av fulltextsökning.
Overview
I den här handledningen används klientbiblioteket Azure.Search.Documents tillsammans med C# för att skapa en datakälla, ett index, en indexerare och en kunskapsuppsättning.
Indexeraren kör varje steg i pipelinen och börjar med innehållsextrahering av exempeldata (ostrukturerad text och bilder) i en blobcontainer i Azure Storage.
När innehållet har extraherats kör kompetensuppsättningen inbyggda kunskaper från Microsoft för att hitta och extrahera information. Dessa kunskaper omfattar optisk teckenigenkänning (OCR) på bilder, språkidentifiering på text, extrahering av nyckelfraser och entitetsigenkänning (organisationer). Ny information som skapas av färdigheterna skickas till fält i ett index. När indexet har fyllts i kan du använda fälten i frågor, fasetter och filter.
Prerequisites
Ett Azure-konto med en aktiv prenumeration. Skapa ett konto kostnadsfritt.
Note
Du kan använda en kostnadsfri söktjänst för den här handledningen. Den kostnadsfria nivån begränsar dig till tre index, tre indexerare och tre datakällor. I den här kursen skapar du en av varje. Innan du börjar måste du se till att du har plats för din tjänst för att acceptera de nya resurserna.
Ladda ned filer
Ladda ned en zip-fil med exempeldatalagringsplatsen och extrahera innehållet. Lär dig hur.
Ladda ned exempeldatafilerna (blandade medier)
Ladda upp exempeldata till Azure Storage
I Azure Storage skapar du en ny container och ger den namnet mixed-content-types.
Ladda upp exempeldatafilerna.
Hämta en lagringsanslutningssträng så att du kan formulera en anslutning i Azure AI Search.
Välj Åtkomstnycklar till vänster.
Kopiera anslutningssträng för antingen nyckel ett eller nyckel två. Anslutningssträng liknar följande exempel:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Gjuteriverktyg
Inbyggd AI-berikning stöds av Foundry Tools, inklusive Azure Language och Azure Vision för naturligt språk och bildbearbetning. För små uppgifter som den här självstudien kan du dra nytta av den kostnadsfria allokeringen av 20 transaktioner per indexerare. För större arbetsbelastningar kopplar du en Microsoft Foundry-resurs till en kompetensuppsättning för Standard-prissättning.
Kopiera en url för söktjänsten och API-nyckeln
I den här självstudien kräver anslutningar till Azure AI Search en slutpunkt och en API-nyckel. Du kan hämta dessa värden från Azure Portal.
Logga in på Azure-portalen och välj din söktjänst.
I den vänstra rutan väljer du Översikt och kopierar slutpunkten. Det bör vara i det här formatet:
https://my-service.search.windows.netI den vänstra rutan väljer du Inställningar>Nycklar och kopierar en administratörsnyckel för fullständiga rättigheter för tjänsten. Det finns två utbytbara administratörsnycklar som tillhandahålls för affärskontinuitet om du behöver rulla över en. Du kan använda antingen nyckel för begäranden för att lägga till, ändra eller ta bort objekt.
Konfigurera din miljö
Börja med att öppna Visual Studio och skapa ett nytt konsolappsprojekt.
Installera Azure.Search.Documents
Azure AI Search .NET SDK består av ett klientbibliotek som gör att du kan hantera dina index, datakällor, indexerare och kompetensuppsättningar, samt ladda upp och hantera dokument och köra frågor, allt utan att behöva ta itu med informationen om HTTP och JSON. Det här klientbiblioteket distribueras som ett NuGet-paket.
För det här projektet installerar du version 11 eller senare av Azure.Search.Documents och den senaste versionen av Microsoft.Extensions.Configuration.
I Visual Studio väljer du Verktyg>NuGet Package Manager>Hantera NuGet-paket för lösning...
Välj den senaste versionen och välj sedan Installera.
Upprepa föregående steg för att installera Microsoft.Extensions.Configuration och Microsoft.Extensions.Configuration.Json.
Lägga till information om tjänstanslutning
Högerklicka på projektet i Solution Explorer och välj Lägg till>nytt objekt... .
Ge filen namnet
appsettings.jsonoch välj Lägg till.Inkludera den här filen i utdatakatalogen.
- Högerklicka på
appsettings.jsonoch välj Egenskaper. - Ändra värdet för Kopiera till utdatakatalog till Kopiera om det är nyare.
- Högerklicka på
Kopiera JSON nedan till din nya JSON-fil.
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
Lägg till din söktjänst och kontoinformation för bloblagring. Kom ihåg att du kan hämta den här informationen från de tjänstetableringssteg som anges i föregående avsnitt.
För SearchServiceUri anger du den fullständiga URL:en.
Lägga till namnområden
I Program.cslägger du till följande namnområden.
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
Skapa en klient
Skapa en instans av en SearchIndexClient och en SearchIndexerClient under Main.
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
Note
Klienterna ansluter till söktjänsten. För att undvika att öppna för många anslutningar bör du försöka dela en enda instans i ditt program om det är möjligt. Metoderna är trådsäkra för att aktivera sådan delning.
Lägg till en funktion för att avsluta programmet vid fel
Den här handledningen är avsedd att hjälpa dig att förstå varje steg i indexeringsprocessen. Om det finns ett kritiskt problem som hindrar programmet från att skapa datakällan, kompetensuppsättningen, indexet eller indexeraren kommer programmet att mata ut felmeddelandet och avsluta så att problemet kan förstås och åtgärdas.
Lägg till ExitProgramMain i för att hantera scenarier som kräver att programmet avslutas.
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
Skapa pipelinen
I Azure AI Search sker AI-bearbetning under indexering (eller datainmatning). Den här delen av genomgången skapar fyra objekt: datakälla, indexdefinition, kompetensuppsättning, indexerare.
Steg 1: Skapa en datakälla
SearchIndexerClient har en DataSourceName egenskap som du kan ange till ett SearchIndexerDataSourceConnection objekt. Det här objektet innehåller alla metoder som du behöver för att skapa, lista, uppdatera eller ta bort Azure AI Search-datakällor.
Skapa en ny SearchIndexerDataSourceConnection instans genom att anropa indexerClient.CreateOrUpdateDataSourceConnection(dataSource). Följande kod skapar en datakälla av typen AzureBlob.
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("mixed-content-type"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
För en lyckad begäran returnerar metoden den datakälla som skapades. Om det uppstår ett problem med begäran, till exempel en ogiltig parameter, genererar metoden ett undantag.
Lägg nu till en rad i Main för att anropa funktionen CreateOrUpdateDataSource som du just har lagt till.
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
Skapa och kör lösningen. Eftersom det här är din första begäran kontrollerar du Azure Portal för att bekräfta att datakällan skapades i Azure AI Search. På översiktssidan för söktjänsten kontrollerar du att listan Datakällor har ett nytt objekt. Du kan behöva vänta några minuter tills sidan Azure Portal uppdateras.

Steg 2: Skapa ett förmågeset
I det här avsnittet definierar du en uppsättning berikningssteg som du vill tillämpa på dina data. Varje berikningssteg kallas för en färdighet och en uppsättning berikningssteg, en kompetensuppsättning. I den här handledningen används inbyggda färdigheter för kompetensuppsättningen:
Optisk teckenigenkänning för att identifiera tryckt och handskriven text i bildfiler.
Textsammanslagning för att konsolidera text från en samling fält till ett enda "sammanfogat innehåll"-fält.
Språkidentifiering för att identifiera innehållets språk.
Entitetsigenkänning för att extrahera namnen på organisationer från innehåll i blobcontainern.
Textdelning för att dela upp stort innehåll i mindre segment innan du anropar kunskapen om extrahering av nyckelfraser och kunskapen om entitetsigenkänning. Extrahering av nyckelfraser och entitetsigenkänning accepterar indata på högst 50 000 tecken. Några av exempelfilerna måste delas upp för att rymmas inom gränsen.
Extrahering av nyckelfraser för att hämta viktigaste nyckelfraserna.
Under den inledande bearbetningen bearbetar Azure AI Search varje dokument för att extrahera innehåll från olika filformat. Text som kommer från källfilen placeras i ett genererat content fält, ett för varje dokument. Ställ in indata som "/document/content" för att använda den här texten. Bildinnehåll placeras i ett genererat normalized_images-fält, som specificeras i en färdighetsuppsättning som /document/normalized_images/*.
Utdata kan mappas till ett index som används som indata till en underordnad kunskap, eller både, vilket är fallet med språkkod. I indexet kan en språkkod användas för filtrering. Som indata används språkkoden av textanalyskunskaper för att informera om de språkliga reglerna kring ordnedbrytning.
Mer information om grunderna i kunskapsuppsättningar finns i Definiera en kunskapsuppsättning.
OCR-kompetens
Extraherar OcrSkill text från bilder. Den här färdigheten förutsätter att det finns ett normalized_images fält. För att generera det här fältet anger vi senare i självstudien konfigurationen "imageAction" i indexerardefinitionen till "generateNormalizedImages".
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
Sammanslagningsfärdighet
I det här avsnittet skapar du en MergeSkill som sammanfogar dokumentinnehållsfältet med texten som skapades av OCR-färdigheten.
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
Språkidentifieringsfärdighet
Identifierar LanguageDetectionSkill språket i indatatexten och rapporterar en enda språkkod för varje dokument som skickas på begäran. Vi använder utdata från språkidentifieringsfärdigheten som en del av inmatningen till färdigheten Textdelning .
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
Kunskap om textdelning
Nedanstående SplitSkill delar upp text efter sidor och begränsar sidlängden till 4 000 tecken mätt med String.Length. Algoritmen försöker dela upp texten i segment som är som mest maximumPageLength stora. I det här fallet gör algoritmen sitt bästa för att bryta meningen på en meningsgräns, så storleken på segmentet kan vara något mindre än maximumPageLength.
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
Kunskap om entitetsigenkänning
Den här EntityRecognitionSkill instansen är inställd på att identifiera kategoritypen organization.
EntityRecognitionSkill Kan också identifiera kategorityper person och location.
Observera att fältet "context" är inställt på med en asterisk, vilket innebär att "/document/pages/*" berikningssteget anropas för varje sida under "/document/pages".
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
// Specify the V3 version of the EntityRecognitionSkill
var skillVersion = EntityRecognitionSkill.SkillVersion.V3;
var entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings, skillVersion)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
Extraheringsfärdighet för nyckelfraser
Precis som den EntityRecognitionSkill instans som just skapades KeyPhraseExtractionSkill anropas för varje sida i dokumentet.
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
Bygg och utveckla dina färdigheter
Bygg SearchIndexerSkillset med de färdigheter du har skapat.
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Foundry Tools was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
Lägg till följande rader i Main.
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
Steg 3: Skapa ett index
I det här avsnittet definierar du indexschemat genom att ange vilka fält som ska ingå i det sökbara indexet och sökattributen för varje fält. Fält har en typ och kan ta attribut som bestämmer hur fältet ska användas (sökbart, sorteringsbart och så vidare). Fältnamn i ett index krävs inte för att identiskt matcha fältnamnen i källan. I ett senare steg lägger du till fältmappningar i en indexerare för att ansluta källa-mål-fält. För det här steget definiera indexet med fältnamnkonventioner som är relevanta för ditt sökprogram.
Den här övningen använder följande fält och fälttyp:
| Fält-namn: | Fälttyper |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
Lista<Edm.String> |
organizations |
Lista<Edm.String> |
Skapa DemoIndex-klass
Fälten för det här indexet definieras med hjälp av en modellklass. Varje egenskap för modellklassen har attribut som avgör sökrelaterade beteenden för motsvarande indexfält.
Vi lägger till modellklassen i en ny C#-fil. Högerklicka på projektet och välj Lägg till>nytt objekt..., välj "Klass" och ge filen DemoIndex.csnamnet och välj sedan Lägg till.
Se till att ange att du vill använda typer från namnrymderna Azure.Search.Documents.Indexes och System.Text.Json.Serialization .
Lägg till modellklassdefinitionen nedan i DemoIndex.cs och inkludera den i samma namnområde där du skapar indexet.
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
Nu när du har definierat en modellklass Program.cs kan du skapa en indexdefinition ganska enkelt. Namnet på det här indexet blir demoindex. Om det redan finns ett index med det namnet tas det bort.
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
Under testningen kanske du försöker skapa indexet mer än en gång. Därför kontrollerar du om det index som du ska skapa redan finns innan du försöker skapa det.
Lägg till följande rader i Main.
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
Lägg till följande instruktion för att lösa den tvetydiga referensen.
using Index = Azure.Search.Documents.Indexes.Models;
Mer information om indexbegrepp finns i Skapa index (REST API).
Steg 4: Skapa och köra en indexerare
Hittills har du skapat en datakälla, en kunskapsuppsättning och ett index. De här tre komponenterna blir en del av en indexerare som sammanför varje del till en enda åtgärd i flera faser. Om du vill sammanfoga dem i en indexerare måste du definiera fältmappningar.
FieldMappings bearbetas före kompetensuppsättningen och mappar källfält från datakällan till målfält i ett index. Om fältnamn och typer är samma i båda ändar krävs ingen mappning.
OutputFieldMappings bearbetas efter skillset och refererar till sourceFieldNames som inte existerar förrän dokumentbearbetning eller berikning skapar dem. targetFieldName är ett fält i ett index.
Förutom att koppla indata till utdata kan du även använda fältmappningar för att platta ut datastrukturer. Mer information finns i Mappa berikade fält till ett sökbart index.
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
Lägg till följande rader i Main.
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
Förvänta dig att indexerarens bearbetning tar lite tid att slutföra. Trots att datauppsättningen är liten är analytiska kunskaper beräkningsintensiva. Vissa kunskaper, som bildanalys, är tidskrävande.
Tip
När en indexerare skapas anropas pipelinen. Om det uppstår problem med att nå datan, mappning av indata och utdata eller operationernas ordning, visas de i det här stadiet.
Utforska hur du skapar indexeraren
Koden sätter "maxFailedItems" till -1, vilket instruerar indexeringsmotorn att ignorera fel under importen av data. Detta är användbart eftersom det finns det så få dokument i demo-datakällan. För en större datakälla skulle du ställa in värdet på större än 0.
Observera också att "dataToExtract" är inställt på "contentAndMetadata". Den här instruktionen anger att indexeraren automatiskt ska extrahera innehållet från olika filformat samt metadata som är relaterade till varje fil.
När innehållet har extraherats kan du ställa in imageAction på att extrahera text från avbildningar som hittades i datakällan. Konfigurationsuppsättningen "imageAction""generateNormalizedImages" , kombinerad med OCR Skill and Text Merge Skill, instruerar indexeraren att extrahera text från bilderna (till exempel ordet "stopp" från en trafikstoppsskylt) och bädda in den som en del av innehållsfältet. Det här beteendet gäller både avbildningarna som är inbäddade i dokumenten (tänk på en avbildning i en PDF) samt avbildningar som hittas i datakällan, till exempel en JPG-fil.
Övervaka indexering
När du har definierat indexeraren körs den automatiskt när du skickar din begäran. Beroende på vilka kunskaper du har definierat kan indexeringen ta längre tid än förväntat. Använd GetStatus-metoden för att ta reda på om indexeraren fortfarande körs.
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo representerar den aktuella status- och körningshistoriken för en indexerare.
Varningar är vanliga med vissa kombinationer av källfiler och kunskaper och indikerar inte alltid ett problem. I den här självstudien är varningarna ofarliga (till exempel inga textindata från JPEG-filerna).
Lägg till följande rader i Main.
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
Search
I azure AI Search-självstudiekonsolappar lägger vi vanligtvis till en fördröjning på 2 sekunder innan vi kör frågor som returnerar resultat, men eftersom berikning tar flera minuter att slutföra stänger vi konsolappen och använder en annan metod i stället.
Det enklaste alternativet är Sökutforskaren i Azure-portalen. Du kan först köra en tom fråga som returnerar alla dokument eller en mer riktad sökning som returnerar nytt fältinnehåll som skapats av pipelinen.
I Azure-portalen går du till söktjänstsidorna och expanderarSökhanteringsindex>.
Sök
demoindexi listan. Den bör ha 14 dokument. Om antalet dokument är noll körs indexeraren fortfarande eller så har sidan inte uppdaterats ännu.Välj
demoindex. Sökutforskaren är den första fliken.Innehållet kan sökas efter så snart det första dokumentet har lästs in. Kontrollera att innehållet finns genom att köra en ospecificerad fråga genom att klicka på Sök. Den här frågan returnerar alla för närvarande indexerade dokument, vilket ger dig en uppfattning om vad indexet innehåller.
Om du vill ha mer hanterbara resultat växlar du till JSON-vyn och anger parametrar för att välja fälten:
{ "search": "*", "count": true, "select": "id, languageCode, organizations" }
Återställa och köra igen
I de tidiga experimentella utvecklingsfaserna är det mest praktiska sättet att utforma iteration att ta bort objekten från Azure AI Search och låta koden återskapa dem. Resursnamn är unika. Om du tar bort ett objekt kan du återskapa det med samma namn.
Exempelkoden för den här självstudien söker efter befintliga objekt och tar bort dem så att du kan köra koden igen. Du kan också använda Azure Portal för att ta bort index, indexerare, datakällor och kompetensuppsättningar.
Takeaways
Den här självstudien visade de grundläggande stegen för att skapa en berikad indexeringspipeline genom att skapa komponentdelar: en datakälla, kompetensuppsättning, index och indexerare.
Inbyggda färdigheter introducerades, tillsammans med kompetensuppsättningsdefinition och mekaniken för sammanlänkning av färdigheter genom indata och utdata. Du har också lärt dig att outputFieldMappings i indexerarens definition krävs för att dirigera berikade värden från pipeline till ett sökbart index på Azure AI Search-tjänsten.
Slutligen lärde du dig att testa resultat och återställa systemet för ytterligare iterationer. Du har lärt dig att när du ställer frågor mot indexet returneras det utdata som skapades av den berikade indexeringspipeline. Du har också lärt dig att kontrollera indexerarstatus, och vilka objekt du ska ta bort innan du kör en pipeline igen.
Rensa resurser
När du arbetar i din egen prenumeration i slutet av ett projekt är det en bra idé att ta bort de resurser som du inte längre behöver. Resurser som körs i onödan kan kosta dig pengar. Du kan ta bort enstaka resurser eller hela resursgruppen om du vill ta bort alla resurser.
Du kan hitta och hantera resurser i Azure Portal med hjälp av länken Alla resurser eller Resursgrupper i det vänstra navigeringsfönstret.
Nästa steg
Nu när du är bekant med alla objekt i en AI-berikningspipeline ska vi titta närmare på definitioner för kompetensuppsättningar och individuella färdigheter.
Lär dig hur du anropar REST-API:er som skapar en AI-berikningspipeline för extrahering och omvandling av innehåll vid indexering.
Kunskapsuppsättningar lägger till AI-bearbetning till råinnehåll, vilket gör det mer enhetligt och sökbart. När du vet hur kompetensuppsättningar fungerar kan du stödja ett brett utbud av transformeringar, från bildanalys till bearbetning av naturligt språk till anpassad bearbetning som du tillhandahåller externt.
I den här handledningen kommer du att:
- Definiera objekt i en berikningspipeline.
- Bygg en kompetens. Anropa OCR, språkidentifiering, entitetsigenkänning och extrahering av nyckelfraser.
- Utför rörledningen. Skapa och läsa in ett sökindex.
- Kontrollera resultaten med hjälp av fulltextsökning.
Overview
I den här handledningen används en REST-klient och REST API:er för Azure AI Search för att skapa en datakälla, ett index, en indexerare och en kunskapsuppsättning.
Indexeraren kör varje steg i pipelinen och börjar med innehållsextrahering av exempeldata (ostrukturerad text och bilder) i en blobcontainer i Azure Storage.
När innehållet har extraherats kör kompetensuppsättningen inbyggda kunskaper från Microsoft för att hitta och extrahera information. Dessa kunskaper omfattar optisk teckenigenkänning (OCR) på bilder, språkidentifiering på text, extrahering av nyckelfraser och entitetsigenkänning (organisationer). Ny information som skapas av färdigheterna skickas till fält i ett index. När indexet har fyllts i kan du använda fälten i frågor, fasetter och filter.
Prerequisites
Ett Azure-konto med en aktiv prenumeration. Skapa ett konto kostnadsfritt.
Visual Studio Code med en REST-klient
Note
Du kan använda en kostnadsfri söktjänst för den här handledningen. Den kostnadsfria nivån begränsar dig till tre index, tre indexerare och tre datakällor. I den här kursen skapar du en av varje. Innan du börjar måste du se till att du har plats för din tjänst för att acceptera de nya resurserna.
Ladda ned filer
Ladda ned en zip-fil med exempeldatalagringsplatsen och extrahera innehållet. Lär dig hur.
Ladda upp exempeldata till Azure Storage
I Azure Storage skapar du en ny container och ger den namnet cog-search-demo.
Hämta en lagringsanslutningssträng så att du kan formulera en anslutning i Azure AI Search.
Välj Åtkomstnycklar till vänster.
Kopiera anslutningssträng för antingen nyckel ett eller nyckel två. Anslutningssträng liknar följande exempel:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Gjuteriverktyg
Inbyggd AI-berikning stöds av Foundry Tools, inklusive Azure Language och Azure Vision för naturligt språk och bildbearbetning. För små arbetsuppgifter som den här självstudien kan du använda den kostnadsfria tilldelningen av tjugo transaktioner per indexerare. För större arbetsbelastningar kopplar du en Microsoft Foundry-resurs till en kompetensuppsättning för Standard-prissättning.
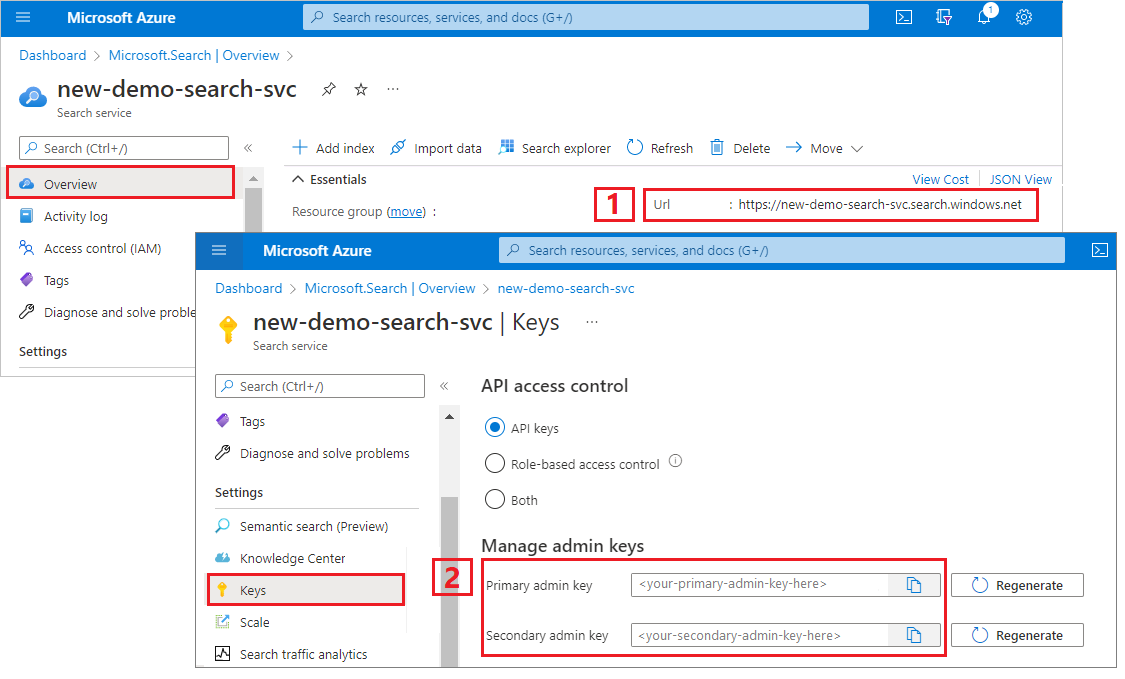
Kopiera en url för söktjänsten och API-nyckeln
I den här självstudien kräver anslutningar till Azure AI Search en slutpunkt och en API-nyckel. Du kan hämta dessa värden från Azure Portal.
Logga in på Azure-portalen och välj din söktjänst.
I den vänstra rutan väljer du Översikt och kopierar slutpunkten. Det bör vara i det här formatet:
https://my-service.search.windows.netI den vänstra rutan väljer du Inställningar>Nycklar och kopierar en administratörsnyckel för fullständiga rättigheter för tjänsten. Det finns två utbytbara administratörsnycklar som tillhandahålls för affärskontinuitet om du behöver rulla över en. Du kan använda antingen nyckel för begäranden för att lägga till, ändra eller ta bort objekt.
Konfigurera REST-filen
Starta Visual Studio Code och öppna filen skillset-tutorial.rest . Se Snabbstart: Fulltextsökning om du behöver hjälp med REST-klienten.
Ange värden för variablerna: söktjänstens slutpunkt, api-nyckeln för söktjänstens administratör, ett indexnamn, en anslutningssträng till ditt Azure Storage-konto och namnet på blobcontainern.
Skapa pipelinen
AI-berikning är indexerdriven. Den här delen av genomgången skapar fyra objekt: datakälla, indexdefinition, kompetensuppsättning, indexerare.
Steg 1: Skapa en datakälla
Anropa Skapa datakälla för att ange anslutningssträng till blobcontainern som innehåller exempeldatafilerna.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Steg 2: Skapa ett förmågeset
Anropa Skapa kompetensuppsättning för att ange vilka berikningssteg som ska tillämpas på ditt innehåll. Färdigheter exekveras parallellt såvida det inte finns ett beroende.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Viktiga punkter:
Brödtexten i begäran anger följande inbyggda kunskaper:
Skill Description Optisk teckenigenkänning Identifierar text och siffror i bildfiler. Sammanslagning av text Skapar "sammanfogat innehåll" som kombinerar om tidigare avgränsat innehåll, användbart för dokument med inbäddade bilder (PDF, DOCX och så vidare). Bilder och text separeras under dokumentets sprickfas. Sammanslagningsfärdigheten kombinerar om dem genom att infoga eventuell igenkänd text, bildtexter eller taggar som skapades under berikningen till samma plats där bilden extraherades från i dokumentet. När du arbetar med sammanfogat innehåll i en kompetensuppsättning omfattar den här noden all text i dokumentet, inklusive endast textdokument som aldrig genomgår OCR eller bildanalys. Språkidentifiering Identifierar språket och utdata antingen ett språknamn eller en kod. I flerspråkiga datamängder kan ett språkfält vara användbart för filter. Entitetsigenkänning Extraherar namnen på personer, organisationer och platser från sammanslaget innehåll. Textdelning Delar upp stort sammanfogat innehåll i mindre segment innan du anropar extraheringsfärdigheten för nyckelfraser. Extrahering av nyckelfraser accepterar indata på 50 000 tecken eller mindre. Några av exempelfilerna måste delas upp för att rymmas inom gränsen. Extrahering av nyckelfraser Hämtar de viktigaste nyckelfraserna. Varje färdighet utförs på innehållet i dokumentet. Under bearbetningen analyserar Azure AI Search varje dokument för att läsa innehåll från olika filformat. Text som hittas från källfilen placeras i ett genererat
content-fält, ett för varje dokument. Därför blir"/document/content"indata .För extrahering av nyckelfraser, eftersom vi använder färdigheten textdelare för att dela upp större filer i sidor, är kontexten för extraheringsfärdigheten för nyckelfraser
"document/pages/*"(för varje sida i dokumentet) i stället för"/document/content".
Note
Utdata kan mappas till ett index som används som indata till en underordnad kunskap, eller både, vilket är fallet med språkkod. I indexet kan en språkkod användas för filtrering. Mer information om grunderna i kunskapsuppsättningar finns i Definiera en kunskapsuppsättning.
Steg 3: Skapa ett index
Anropa Skapa index för att ange det schema som används för att skapa inverterade index och andra konstruktioner i Azure AI Search.
Den största komponenten i ett index är fältsamlingen, där datatyp och attribut avgör innehåll och beteende i Azure AI Search. Kontrollera att du har fält för dina nyligen genererade utdata.
### Create an index
POST {{baseUrl}}/indexes?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Steg 4: Skapa och köra en indexerare
Anropa Skapa indexerare för att köra pipelinen. De tre komponenter som du har skapat hittills (datakälla, kompetensuppsättning, index) är indata till en indexerare. Att skapa indexeraren i Azure AI Search är den händelse som sätter hela pipelinen i rörelse.
Förvänta dig att steget kan ta flera minuter att slutföra. Trots att datauppsättningen är liten är analytiska kunskaper beräkningsintensiva.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Viktiga punkter:
Brödtexten i begäran innehåller referenser till tidigare objekt, konfigurationsegenskaper som krävs för bildbearbetning och två typer av fältmappningar.
"fieldMappings"bearbetas före kompetensuppsättningen och skickar innehåll från datakällan till målfält i ett index. Du använder fältmappningar för att skicka befintligt, oförändrade innehåll till indexet. Om fältnamn och typer är samma i båda ändar krävs ingen mappning."outputFieldMappings"är för fält som skapats av färdigheter, efter färdighetsuppsättningens genomförande. Referenserna tillsourceFieldNameioutputFieldMappingsfinns inte förrän dokumentsprickor eller berikning skapar dem.targetFieldNameär ett fält i ett index som definieras i indexschemat.Parametern
"maxFailedItems"är inställd på -1, vilket instruerar indexeringsmotorn att ignorera fel under dataimporten. Detta är acceptabelt eftersom det finns så få dokument i demodatakällan. För en större datakälla skulle du ställa in värdet på större än 0.Instruktionen
"dataToExtract":"contentAndMetadata"instruerar indexeraren att automatiskt extrahera värdena från blobens innehållsegenskap och metadata för varje objekt.Parametern
imageActioninstruerar indexeraren att extrahera text från bilder som finns i datakällan. Konfigurationen av"imageAction":"generateNormalizedImages", tillsammans med OCR-färdigheten och färdigheten för textsammanslagning, talar om för indexeraren att den ska extrahera text från bilderna (exempelvis ordet ”stopp” från en trafikstoppskylt) och bädda in den som en del av innehållsfältet. Det här beteendet gäller både inbäddade bilder (tänk på en bild i en PDF) och fristående bildfiler, till exempel en JPG-fil.
Note
När en indexerare skapas anropas pipelinen. Om det uppstår problem med att nå datan, mappning av indata och utdata eller operationernas ordning, visas de i det här stadiet. För att köra om pipeline med kod- eller skriptändringar kan du behöva ta bort objekt först. Mer information finns i Reset and re-run (Återställa och köra om).
Övervaka indexering
Indexering och berikning påbörjas så snart du skickar begäran om att skapa indexerare. Beroende på kompetensuppsättningens komplexitet och åtgärder kan indexering ta en stund.
Om du vill ta reda på om indexeraren fortfarande körs anropar du Hämta indexerarstatus för att kontrollera indexerarens status.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Viktiga punkter:
Varningar är vanliga i vissa scenarier och indikerar inte alltid ett problem. Om en blobcontainer till exempel innehåller avbildningsfiler och pipelinen inte hanterar avbildningar får du en varning om att avbildningarna inte bearbetats.
I det här exemplet finns det en PNG-fil som inte innehåller någon text. Alla fem av de textbaserade färdigheterna (språkidentifiering, entitetsigenkänning av platser, organisationer, personer och extrahering av nyckelfraser) kan inte köras på den här filen. Det resulterande meddelandet visas i körningshistoriken.
Kontrollera resultat
Nu när du har skapat ett index som innehåller AI-genererat innehåll anropar du Sökdokument för att köra några frågor för att se resultatet.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Filter kan hjälpa dig att begränsa resultatet till intressanta objekt:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Dessa frågor illustrerar några av de sätt som du kan arbeta med frågesyntax och filter på nya fält som skapats av Azure AI Search. Fler frågeexempel finns i Exempel i REST API för sökdokument, Enkla syntaxfrågeexempel och Fullständiga Lucene-frågeexempel.
Återställa och köra igen
Under tidiga utvecklingsstadier är iteration över designen vanlig. Återställning och omkörning hjälper till med iteration.
Takeaways
Den här självstudien visar de grundläggande stegen för att använda REST-API:er för att skapa en AI-berikningspipeline: en datakälla, färdighetsuppsättning, index och indexerare.
Inbyggda färdigheter introducerades, tillsammans med kompetensuppsättningsdefinitioner som visar mekaniken för att länka samman färdigheter genom indata och utdata. Du har också lärt dig att outputFieldMappings i indexerarens definition krävs för att dirigera berikade värden från pipeline till ett sökbart index på Azure AI Search-tjänsten.
Slutligen lärde du dig att testa resultat och återställa systemet för ytterligare iterationer. Du har lärt dig att när du ställer frågor mot indexet returneras det utdata som skapades av den berikade indexeringspipeline.
Rensa resurser
När du arbetar i din egen prenumeration i slutet av ett projekt är det en bra idé att ta bort de resurser som du inte längre behöver. Resurser som körs i onödan kan kosta dig pengar. Du kan ta bort enstaka resurser eller hela resursgruppen om du vill ta bort alla resurser.
Du kan hitta och hantera resurser i Azure Portal med hjälp av länken Alla resurser eller Resursgrupper i det vänstra navigeringsfönstret.
Nästa steg
Nu när du är bekant med alla objekt i en AI-berikningspipeline kan du ta en närmare titt på definitioner av kompetensuppsättningar och individuella färdigheter.