İşlem yapılandırma (eski)
Not
Bunlar eski küme oluşturma kullanıcı arabirimine yönelik yönergelerdir ve yalnızca geçmiş doğruluğu için eklenmiştir. Tüm müşteriler güncelleştirilmiş küme oluşturma kullanıcı arabirimini kullanmalıdır.
Bu makalede, Azure Databricks kümelerini oluştururken ve düzenlerken kullanılabilen yapılandırma seçenekleri açıklanır. Kullanıcı arabirimini kullanarak küme oluşturmaya ve düzenlemeye odaklanır. Diğer yöntemler için bkz . Databricks CLI, Clusters API ve Databricks Terraform sağlayıcısı.
Gereksinimlerinize en uygun yapılandırma seçeneklerinin birleşimini belirleme konusunda yardım için bkz . Küme yapılandırması en iyi yöntemleri.
Küme ilkesi
Küme ilkesi , kümeleri bir dizi kurala göre yapılandırma özelliğini sınırlar. İlke kuralları, küme oluşturma için kullanılabilen öznitelikleri veya öznitelik değerlerini sınırlar. Küme ilkeleri, kullanımlarını belirli kullanıcılar ve gruplarda sınırlayan ve bu nedenle küme oluştururken seçebileceğiniz ilkeleri sınırlayan ACL'lere sahiptir.
Küme ilkesi yapılandırmak için, İlke açılan listesinden küme ilkesini seçin.
Not
Çalışma alanında hiçbir ilke oluşturulmadıysa, İlke açılan listesi görüntülenmez.
Varsa:
- Küme oluşturma izni, Kısıtlamasız ilkesini seçebilir ve tam olarak yapılandırılabilir kümeler oluşturabilirsiniz. Kısıtlanmamış ilkesi, küme özniteliklerini veya öznitelik değerlerini sınırlamaz.
- Hem küme oluşturma izni hem de küme ilkelerine erişim, Kısıtlamasız ilkesini ve erişiminiz olan ilkeleri seçebilirsiniz.
- Yalnızca küme ilkelerine erişim, erişiminiz olan ilkeleri seçebilirsiniz.
Küme modu
Not
Bu makalede eski kümeler kullanıcı arabirimi açıklanmaktadır. Yeni kümeler kullanıcı arabirimi (önizlemede) hakkında bilgi için bkz . İşlem yapılandırma başvurusu. Bu, küme erişim türleri ve modları için bazı terminoloji değişikliklerini içerir. Yeni ve eski küme türlerinin karşılaştırması için bkz . Kümeler kullanıcı arabirimi değişiklikleri ve küme erişim modları. Önizleme kullanıcı arabiriminde:
- Standart mod kümeleri artık Yalıtımsız Paylaşılan erişim modu kümeleri olarak adlandırılır.
- Tablo ACL'leriyle Yüksek Eşzamanlılık artık Paylaşılan erişim modu kümeleri olarak adlandırılır.
Azure Databricks üç küme modunu destekler: Standart, Yüksek Eşzamanlılık ve Tek Düğüm. Varsayılan küme modu Standart'tır.
Önemli
- Çalışma alanınız bir Unity Kataloğu meta deposuna atanmışsa, Yüksek Eşzamanlılık kümeleri kullanılamaz. Bunun yerine, erişim denetimlerinin bütünlüğünü sağlamak ve güçlü yalıtım garantilerini zorunlu kılmak için erişim modunu kullanırsınız. Ayrıca bkz. Erişim modları.
- Küme oluşturulduktan sonra küme modunu değiştiremezsiniz. Farklı bir küme modu istiyorsanız yeni bir küme oluşturmanız gerekir.
Küme yapılandırması, varsayılan değeri küme moduna bağlı olan bir otomatik sonlandırma ayarı içerir:
- Standart ve Tek Düğüm kümeleri varsayılan olarak 120 dakika sonra otomatik olarak sonlanır.
- Yüksek Eşzamanlılık kümeleri varsayılan olarak otomatik olarak sonlandırılmaz .
Standart kümeler
Uyarı
Standart mod kümeleri (bazen YalıtımSız Paylaşılan kümeler olarak adlandırılır), kullanıcılar arasında yalıtım olmadan birden çok kullanıcı tarafından paylaşılabilir. Tablo ACL'leri veya Kimlik Bilgisi Geçişi gibi ek güvenlik ayarları olmadan Yüksek Eşzamanlılık kümesi modunu kullanırsanız, standart mod kümeleri olarak aynı ayarlar kullanılır. Hesap yöneticileri , bu tür kümelerde Databricks çalışma alanı yöneticileri için iç kimlik bilgilerinin otomatik olarak oluşturulmasını engelleyebilir. Daha güvenli seçenekler için Databricks, Tablo ACL'leri ile yüksek eşzamanlılık kümeleri gibi alternatifler önerir.
Standart küme yalnızca tek kullanıcılar için önerilir. Standart kümeler Python, SQL, R ve Scala'da geliştirilen iş yüklerini çalıştırabilir.
Yüksek Eşzamanlılık kümeleri
Yüksek Eşzamanlılık kümesi yönetilen bir bulut kaynağıdır. Yüksek Eşzamanlılık kümelerinin temel avantajları, en fazla kaynak kullanımı ve en düşük sorgu gecikme süreleri için ayrıntılı paylaşım sağlamalarıdır.
Yüksek Eşzamanlılık kümeleri SQL, Python ve R'de geliştirilen iş yüklerini çalıştırabilir. Yüksek Eşzamanlılık kümelerinin performansı ve güvenliği, scala'da mümkün olmayan ayrı işlemlerde kullanıcı kodu çalıştırılarak sağlanır.
Ayrıca, yalnızca Yüksek Eşzamanlılık kümeleri tablo erişim denetimini destekler.
Yüksek Eşzamanlılık kümesi oluşturmak için Küme Modu'nu Yüksek Eşzamanlılık olarak ayarlayın.
Tek Düğüm kümeleri
Tek Düğümlü kümede çalışan yoktur ve sürücü düğümünde Spark işleri çalıştırır.
Buna karşılık, Standart küme, Spark işlerini yürütmek için sürücü düğümüne ek olarak en az bir Spark çalışan düğümü gerektirir.
Tek Düğüm kümesi oluşturmak için Küme Modu'nu Tek Düğüm olarak ayarlayın.
Tek Düğümlü kümelerle çalışma hakkında daha fazla bilgi edinmek için bkz . Tek düğümlü veya çok düğümlü işlem.
Havuz
Küme başlangıç süresini azaltmak için, sürücü ve çalışan düğümleri için önceden tanımlanmış bir boşta örnekleri havuzuna küme ekleyebilirsiniz. Küme, havuzlardaki örnekler kullanılarak oluşturulur. Bir havuzun istenen sürücü veya çalışan düğümlerini oluşturmak için yeterli boşta kaynakları yoksa havuz, örnek sağlayıcısından yeni örnekler ayırarak genişler. Ekli küme sonlandırıldığında, kullandığı örnekler havuzlara döndürülür ve farklı bir küme tarafından yeniden kullanılabilir.
Çalışan düğümleri için bir havuz seçerseniz ancak sürücü düğümü için seçmezseniz, sürücü düğümü havuzu çalışan düğümü yapılandırmasından devralır.
Önemli
Sürücü düğümü için bir havuz seçmeye çalışırsanız ancak çalışan düğümleri için seçmezseniz bir hata oluşur ve kümeniz oluşturulmaz. Bu gereksinim, sürücü düğümünün çalışan düğümlerinin oluşturulmasını beklemesi gereken bir durumu (veya tam tersi) önler.
Azure Databricks'te havuzlarla çalışma hakkında daha fazla bilgi edinmek için bkz . Havuz yapılandırma başvurusu .
Databricks Runtime
Databricks çalışma zamanları, kümelerinizde çalışan temel bileşenler kümesidir. Tüm Databricks çalışma zamanları Apache Spark'ı içerir ve kullanılabilirliği, performansı ve güvenliği geliştiren bileşenler ve güncelleştirmeler ekler. Ayrıntılar için bkz . Databricks Runtime sürüm notları sürümleri ve uyumluluğu.
Azure Databricks, bir küme oluşturduğunuzda veya düzenlediğinizde Databricks Runtime Sürümü açılan listesinde çeşitli çalışma zamanı türleri ve bu çalışma zamanı türlerinin çeşitli sürümlerini sunar.
Foton hızlandırma
Foton, Databricks Runtime 9.1 LTS ve üzerini çalıştıran kümeler için kullanılabilir.
Foton hızlandırmayı etkinleştirmek için Foton Hızlandırma kullan onay kutusunu seçin.
İsterseniz, Çalışan Türü ve Sürücü Türü açılan listesinde örnek türünü belirtebilirsiniz.
Databricks, en uygun fiyat ve performans için aşağıdaki örnek türlerini önerir:
- Standard_E4ds_v4
- Standard_E8ds_v4
- Standard_E16ds_v4
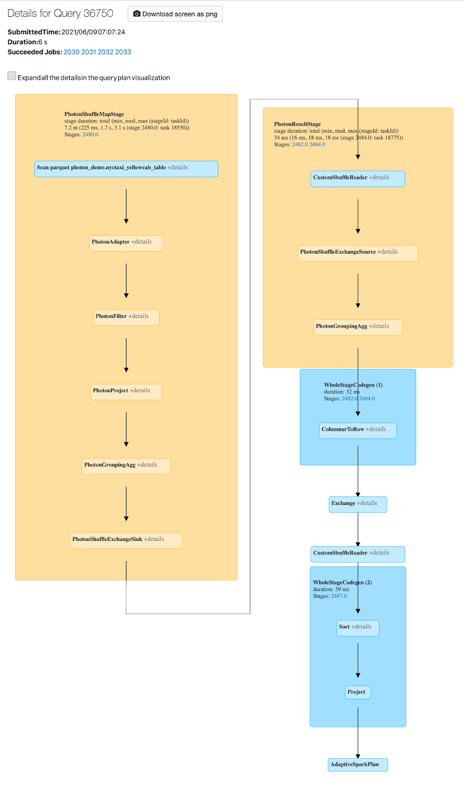
Spark kullanıcı arabiriminde Photon etkinliğini görüntüleyebilirsiniz. Aşağıdaki ekran görüntüsünde sorgu ayrıntıları DAG gösterilmektedir. DAG'de Foton'un iki göstergesi vardır. İlk olarak, Photon işleçleri "Photon" ile başlar, örneğin, PhotonGroupingAgg. İkincisi, DAG'de Foton işleçleri ve aşamaları şeftali rengindeyken, Foton olmayanlar mavidir.
Docker görüntüleri
Bazı Databricks Runtime sürümleri için, küme oluştururken bir Docker görüntüsü belirtebilirsiniz. Örnek kullanım örnekleri arasında kitaplık özelleştirmesi, değişmeyen bir altın kapsayıcı ortamı ve Docker CI/CD tümleştirmesi sayılabilir.
Gpu cihazlarına sahip kümelerde özel derin öğrenme ortamları oluşturmak için Docker görüntülerini de kullanabilirsiniz.
Yönergeler için bkz. GPU işlemde Databricks Container Service ve Databricks Container Services ile kapsayıcıları özelleştirme.
Küme düğümü türü
Küme bir sürücü düğümünden ve sıfır veya daha fazla çalışan düğümünden oluşur.
Sürücü düğümü varsayılan olarak çalışan düğümüyle aynı örnek türünü kullansa da, sürücü ve çalışan düğümleri için ayrı bulut sağlayıcısı örnek türleri seçebilirsiniz. Farklı örnek türü aileleri, yoğun bellek kullanan veya işlem yoğunluklu iş yükleri gibi farklı kullanım örneklerine uyar.
Not
Güvenlik gereksinimleriniz işlem yalıtımını içeriyorsa, çalışan türünüz olarak bir Standard_F72s_V2 örneği seçin. Bu örnek türleri, fiziksel konağın tamamını kullanan yalıtılmış sanal makineleri temsil eder ve örneğin ABD Savunma Bakanlığı Etki Düzeyi 5 (IL5) iş yüklerini desteklemek için gereken yalıtım düzeyini sağlar.
Sürücü düğümü
Sürücü düğümü sürücüye bağlı tüm not defterlerinin durum bilgilerini saklar. Sürücü düğümü ayrıca SparkContext bilgisini de saklar; kümedeki bir not defterinden veya kitaplıktan çalıştırdığınız tüm komutları yorumlar; Spark yürütücüleriyle eşgüdüm sağlayan Apache Spark ana öğesini çalıştırır.
Sürücü düğümü türünün varsayılan değeri çalışan düğümü türününkiyle aynıdır. Spark çalışanlarından çok fazla veri almayı ve bunları not defterinde analiz etmeyi collect() planlıyorsanız daha fazla belleğe sahip daha büyük bir sürücü düğümü türü seçebilirsiniz.
İpucu
Sürücü düğümü ekli not defterlerinin tüm durum bilgilerini koruduğundan, kullanılmayan not defterlerini sürücü düğümünden ayırdığından emin olun.
Çalışan düğümü
Azure Databricks çalışan düğümleri, kümelerin düzgün çalışması için gereken Spark yürütücülerini ve diğer hizmetleri çalıştırır. İş yükünüzü Spark ile dağıttığınızda dağıtılan işlemlerin tümü çalışan düğümlerinde gerçekleştirilir. Azure Databricks çalışan düğümü başına bir yürütücü çalıştırır; bu nedenle yürütücü ve çalışan terimleri, Azure Databricks mimarisi bağlamında birbirinin yerine kullanılır.
İpucu
Spark işini çalıştırmak için en az bir çalışan düğümüne ihtiyacınız vardır. Kümede sıfır çalışan varsa sürücü düğümünde Spark harici komutları yürütebilirsiniz ancak Spark komutları başarısız olur.
GPU örneği türleri
Azure Databricks, derin öğrenmeyle ilişkili olanlar gibi yüksek performans gerektiren hesaplama açısından zorlu görevler için grafik işleme birimleri (GPU) ile hızlandırılmış kümeleri destekler. Daha fazla bilgi için bkz . GPU özellikli işlem.
Spot örnekleri
Maliyetten tasarruf etmek için Spot örnekleri onay kutusunu işaretleyerek Azure Spot VM'leri olarak da bilinen spot örnekleri kullanmayı seçebilirsiniz.

İlk örnek her zaman isteğe bağlı olacaktır (sürücü düğümü her zaman isteğe bağlıdır) ve sonraki örnekler spot örnekler olacaktır. Spot örnekler kullanılamama nedeniyle çıkarılırsa, çıkarılan örneklerin yerine isteğe bağlı örnekler dağıtılır.
Küme boyutu ve otomatik ölçeklendirme
Azure Databricks kümesi oluşturduğunuzda, küme için sabit sayıda çalışan sağlayabilir veya küme için en az ve en fazla çalışan sayısını sağlayabilirsiniz.
Sabit boyutlu bir küme sağladığınızda Azure Databricks, kümenizin belirtilen sayıda çalışana sahip olmasını sağlar. Çalışan sayısı için bir aralık sağladığınızda Databricks, işinizi çalıştırmak için gereken uygun çalışan sayısını seçer. Bu, otomatik ölçeklendirme olarak adlandırılır.
Otomatik ölçeklendirme sayesinde Azure Databricks, çalışanlarınızı işinizin özelliklerini hesaba eklemek için dinamik olarak yeniden ayırır. İşlem hattınızın bazı bölümleri diğerlerinden daha hesaplama açısından daha zorlu olabilir ve Databricks işinizin bu aşamalarında otomatik olarak ek çalışanlar ekler (ve artık gerekli olmadığında bunları kaldırır).
Bir iş yüküyle eşleşecek şekilde kümeyi hazırlamanız gerekmeyen otomatik ölçeklendirme, yüksek küme kullanımını sağlamayı kolaylaştırır. Bu, özellikle gereksinimleri zaman içinde değişen iş yükleri için geçerlidir (örneğin, bir gün boyunca bir veri kümesini keşfetmek gibi), ancak sağlama gereksinimleri bilinmeyen bir kerelik daha kısa bir iş yükü için de geçerli olabilir. Bu nedenle otomatik ölçeklendirme iki avantaj sunar:
- İş yükleri, sabit boyutlu, az sağlanan kümeye kıyasla daha hızlı çalışabilir.
- Kümeleri otomatik ölçeklendirme, statik olarak boyutlandırılmış bir kümeye kıyasla genel maliyetleri azaltabilir.
Kümenin ve iş yükünün sabit boyutuna bağlı olarak, otomatik ölçeklendirme size bu avantajlardan birini veya ikisini aynı anda sağlar. Bulut sağlayıcısı örnekleri sonlandırdığında küme boyutu seçilen en düşük çalışan sayısının altına inebilir. Bu durumda Azure Databricks, en az çalışan sayısını korumak için örnekleri yeniden sağlamayı sürekli olarak yeniden denenir.
Not
spark-submit işleri için otomatik ölçeklendirme kullanılamıyor.
Otomatik ölçeklendirmenin davranışı
- 2 adımda en düşükten maks.'ye ölçeklendirilir.
- Karışık dosya durumuna bakarak küme boşta olmasa bile ölçeği küçültebilir.
- Geçerli düğümlerin yüzdesine göre ölçeği küçültür.
- İş kümelerinde, küme son 40 saniye içinde az kullanılıyorsa ölçeği azaltılır.
- Tüm amaçlı kümelerde, küme son 150 saniye içinde az kullanılıyorsa ölçeği azaltılır.
spark.databricks.aggressiveWindowDownSSpark yapılandırma özelliği, bir kümenin ölçeği azaltma kararları alma sıklıklarını saniyeler içinde belirtir. Değerin artırılması, kümenin ölçeğinin daha yavaş küçültülmesine neden olur. En yüksek değer 600'dür.
Otomatik ölçeklendirmeyi etkinleştirme ve yapılandırma
Azure Databricks'in kümenizi otomatik olarak yeniden boyutlandırmasına izin vermek için küme için otomatik ölçeklendirmeyi etkinleştirir ve en az ve en fazla çalışan aralığını sağlarsınız.
Otomatik ölçeklendirmeyi etkinleştirin.
Çok Amaçlı küme - Küme Oluştur sayfasında, Autopilot Seçenekleri kutusunda Otomatik ölçeklendirmeyi etkinleştir onay kutusunu seçin:

İş kümesi - Kümeyi Yapılandır sayfasında Autopilot Seçenekleri kutusunda Otomatik ölçeklendirmeyi etkinleştir onay kutusunu seçin:

Min ve max çalışanlarını yapılandırın.

Küme çalışırken, küme ayrıntı sayfası ayrılan çalışanların sayısını görüntüler. Ayrılan çalışan sayısını çalışan yapılandırmasıyla karşılaştırabilir ve gerektiğinde ayarlamalar yapabilirsiniz.
Önemli
Örnek havuzu kullanıyorsanız:
- İstenen küme boyutunun havuzdaki en az boştaki örnek sayısından küçük veya buna eşit olduğundan emin olun. Bu sayıdan çoksa, küme başlatma zamanı havuzu kullanmayan bir kümeyle eşdeğer olur.
- En büyük küme boyutunun havuzun maksimum kapasitesinden küçük veya buna eşit olduğundan emin olun. Kapasiteden büyükse küme oluşturma başarısız olur.
Otomatik ölçeklendirme örneği
Statik bir kümeyi otomatik ölçeklendirme kümesi olacak şekilde yeniden yapılandırırsanız, Azure Databricks kümeyi en düşük ve en yüksek sınırlar içinde hemen yeniden boyutlandırır ve ardından otomatik ölçeklendirmeyi başlatır. Örneğin, bir kümeyi 5 ile 10 düğüm arasında otomatik ölçeklendirme için yeniden yapılandırırsanız, aşağıdaki tabloda belirli bir başlangıç boyutuna sahip kümelere ne olduğu gösterilmektedir.
| İlk boyut | Yeniden yapılandırmadan sonra boyut |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Yerel depolamayı otomatik ölçeklendirme
Genellikle belirli bir işin ne kadar disk alanı alacağını tahmin etmek zor olabilir. Azure Databricks, oluşturma sırasında kümenize kaç gigabaytlık yönetilen disk iliştirmek zorunda olmadığınızı tahmin etmek zorunda kalmaktan kurtarmak için tüm Azure Databricks kümelerinde yerel depolamayı otomatik olarak ölçeklendirmeyi etkinleştirir.
Yerel depolamayı otomatik ölçeklendirme ile Azure Databricks, kümenizin Spark çalışanlarında kullanılabilir boş disk alanı miktarını izler. Bir çalışan diskte çok az çalışmaya başlarsa Databricks, disk alanı dolmadan önce çalışana otomatik olarak yeni bir yönetilen disk ekler. Diskler, sanal makine başına toplam 5 TB disk alanı sınırına (sanal makinenin ilk yerel depolama alanı dahil) bağlanır.
Bir sanal makineye bağlı yönetilen diskler yalnızca sanal makine Azure'a döndürülürken ayrılır. Yani, yönetilen diskler çalışan bir kümenin parçası olduğu sürece hiçbir zaman bir sanal makineden ayrılmaz. Azure Databricks, yönetilen disk kullanımının ölçeğini küçültmek için bu özelliğin Küme boyutu ve otomatik ölçeklendirme veya Beklenmeyen sonlandırma ile yapılandırılmış bir kümede kullanılmasını önerir.
Yerel disk şifrelemesi
Önemli
Bu özellik Genel Önizlemededir.
Kümeleri çalıştırmak için kullandığınız bazı örnek türlerinde yerel olarak bağlı diskler olabilir. Azure Databricks, karışık verileri veya kısa ömürlü verileri bu yerel olarak eklenmiş disklerde depolar. Bekleyen tüm verilerin kümenizin yerel disklerinde geçici olarak depolanan karıştırma verileri de dahil olmak üzere tüm depolama türleri için şifrelendiğinden emin olmak için yerel disk şifrelemesini etkinleştirebilirsiniz.
Önemli
Yerel birimlere şifrelenmiş verileri okuma ve yazmanın performans üzerindeki etkisi nedeniyle iş yükleriniz daha yavaş çalışabilir.
Yerel disk şifrelemesi etkinleştirildiğinde, Azure Databricks yerel olarak her küme düğümü için benzersiz olan ve yerel disklerde depolanan tüm verileri şifrelemek için kullanılan bir şifreleme anahtarı oluşturur. Anahtarın kapsamı her küme düğümü için yereldir ve küme düğümünün kendisiyle birlikte yok edilir. Anahtar, kullanım ömrü boyunca şifreleme ve şifre çözme için bellekte bulunur ve diskte şifrelenmiş olarak depolanır.
Yerel disk şifrelemesini etkinleştirmek için Kümeler API'sini kullanmanız gerekir. Küme oluşturma veya düzenleme sırasında şunları ayarlayın:
{
"enable_local_disk_encryption": true
}
Bu API'leri çağırma örnekleri için bkz. Kümeler API'sine bakın.
Aşağıda, yerel disk şifrelemesini etkinleştiren bir küme oluşturma çağrısı örneği verilmiştir:
{
"cluster_name": "my-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_D3_v2",
"enable_local_disk_encryption": true,
"spark_conf": {
"spark.speculation": true
},
"num_workers": 25
}
Güvenlik modu
Çalışma alanınız bir Unity Kataloğu meta deposuna atanmışsa, erişim denetimlerinin bütünlüğünü sağlamak ve güçlü yalıtım garantilerini zorunlu kılmak için Yüksek Eşzamanlılık kümesi modu yerine güvenlik modunu kullanırsınız. Unity Kataloğu ile Yüksek Eşzamanlılık kümesi modu kullanılamaz.
Gelişmiş seçenekler'in altında aşağıdaki küme güvenlik modlarından birini seçin:
- Yok: Yalıtım yok. Çalışma alanı-yerel tablo erişim denetimini veya kimlik bilgisi geçişini zorunlu kılmaz. Unity Kataloğu verilerine erişilemiyor.
- Tek Kullanıcı: Yalnızca tek bir kullanıcı (varsayılan olarak kümeyi oluşturan kullanıcı) tarafından kullanılabilir. Diğer kullanıcılar kümeye ekleyemez. Tek Kullanıcı güvenlik moduyla bir kümeden görünüme erişirken, görünüm kullanıcının izinleriyle yürütülür. Tek kullanıcılı kümeler Python, Scala ve R kullanan iş yüklerini destekler. Başlatma betikleri, kitaplık yüklemesi ve DBFS bağlamaları tek kullanıcılı kümelerde desteklenir. Otomatik işler tek kullanıcılı kümeleri kullanmalıdır.
- Kullanıcı Yalıtımı: Birden çok kullanıcı tarafından paylaşılabilir. Yalnızca SQL iş yükleri desteklenir. Kitaplık yüklemesi, başlatma betikleri ve DBFS bağlamaları, küme kullanıcıları arasında katı yalıtım uygulamak için devre dışı bırakılır.
- Yalnızca Tablo ACL'si (Eski): Çalışma alanı-yerel tablo erişim denetimini zorlar, ancak Unity Kataloğu verilerine erişemez.
- Yalnızca geçiş (Eski): Çalışma alanı yerel kimlik bilgisi geçişini zorlar, ancak Unity Kataloğu verilerine erişemez.
Unity Kataloğu iş yükleri için desteklenen tek güvenlik modları Tek Kullanıcı ve Kullanıcı Yalıtımı'dır.
Daha fazla bilgi için bkz . Erişim modları.
Spark yapılandırması
Spark işlerinde ince ayar yapmak için, küme yapılandırmasında özel Spark yapılandırma özellikleri sağlayabilirsiniz.
Küme yapılandırması sayfasında Gelişmiş Seçenekler iki durumlu düğmesine tıklayın.
Spark sekmesine tıklayın.
Spark yapılandırmasında yapılandırma özelliklerini satır başına bir anahtar-değer çifti olarak girin.
Küme API'sini kullanarak bir küme yapılandırdığınızda, Yeni küme oluşturma API'sindeki veya Küme yapılandırma API'sini spark_conf güncelleştir alanındaki Spark özelliklerini ayarlayın.
Databricks genel başlatma betiklerinin kullanılmasını önermez.
Tüm kümeler için Spark özelliklerini ayarlamak için genel bir başlatma betiği oluşturun:
dbutils.fs.put("dbfs:/databricks/init/set_spark_params.sh","""
|#!/bin/bash
|
|cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf
|[driver] {
| "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC"
|}
|EOF
""".stripMargin, true)
Gizli diziden Spark yapılandırma özelliği alma
Databricks, parolalar gibi hassas bilgilerin düz metin yerine gizli dizide depolanmasını önerir. Spark yapılandırmasında gizli diziye başvurmak için aşağıdaki söz dizimini kullanın:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Örneğin, içinde depolanan secrets/acme_app/passwordgizli dizi değerine çağrılan password bir Spark yapılandırma özelliği ayarlamak için:
spark.password {{secrets/acme-app/password}}
Daha fazla bilgi için bkz . Spark yapılandırma özelliğinde veya ortam değişkeninde gizli dizilere başvurmak için söz dizimi.
Ortam değişkenleri
Bir kümede çalışan init betiklerinden erişebileceğiniz özel ortam değişkenlerini yapılandırabilirsiniz. Databricks, başlatma betiklerinde kullanabileceğiniz önceden tanımlanmış ortam değişkenleri de sağlar. Önceden tanımlanmış bu ortam değişkenlerini geçersiz kılamazsınız.
Küme yapılandırması sayfasında Gelişmiş Seçenekler iki durumlu düğmesine tıklayın.
Spark sekmesine tıklayın.
Ortam Değişkenleri alanında ortam değişkenlerini ayarlayın.
Yeni küme API'sini oluşturma veya Küme yapılandırma API'sini spark_env_vars güncelleştirme alanındaki alanı kullanarak ortam değişkenlerini de ayarlayabilirsiniz.
Küme etiketleri
Küme etiketleri, kuruluşunuzdaki çeşitli gruplar tarafından kullanılan bulut kaynaklarının maliyetini kolayca izlemenizi sağlar. Bir küme oluştururken etiketleri anahtar-değer çiftleri olarak belirtebilirsiniz ve Azure Databricks bu etiketleri VM'ler ve disk birimleri gibi bulut kaynaklarına ve DBU kullanım raporlarına uygular.
Havuzlardan başlatılan kümeler için özel küme etiketleri yalnızca DBU kullanım raporlarına uygulanır ve bulut kaynaklarına yayılmaz.
Havuz ve küme etiketi türlerinin birlikte nasıl çalıştığı hakkında ayrıntılı bilgi için bkz . Etiketleri kullanarak kullanımı izleme.
Kolaylık olması için Azure Databricks her kümeye dört varsayılan etiket uygular: Vendor, Creator, ClusterNameve ClusterId.
Ayrıca, iş kümelerinde Azure Databricks iki varsayılan etiket uygular: RunName ve JobId.
Databricks SQL tarafından kullanılan kaynaklarda, Azure Databricks varsayılan etiketini SqlWarehouseIdde uygular.
Uyarı
Kümeye anahtarıyla Name özel bir etiket atamayın. Her kümenin değeri Azure Databricks tarafından ayarlanan bir etiketi Name vardır. anahtarıyla Nameilişkili değeri değiştirirseniz, küme artık Azure Databricks tarafından izlenemez. Sonuç olarak, küme boşta olduktan sonra sonlandırılamayabilir ve kullanım maliyetlerine neden olmaya devam eder.
Küme oluştururken özel etiketler ekleyebilirsiniz. Küme etiketlerini yapılandırmak için:
Küme yapılandırması sayfasında Gelişmiş Seçenekler iki durumlu düğmesine tıklayın.
Sayfanın en altında Etiketler sekmesine tıklayın.
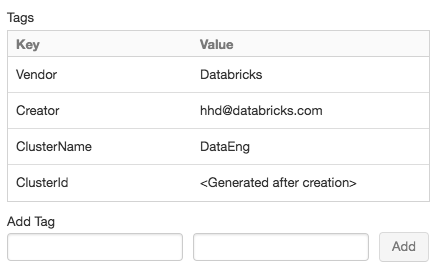
Her özel etiket için bir anahtar-değer çifti ekleyin. En fazla 43 özel etiket ekleyebilirsiniz.
Kümelere SSH erişimi
Güvenlik nedeniyle, Azure Databricks'te SSH bağlantı noktası varsayılan olarak kapatılır. Spark kümelerinize SSH erişimini etkinleştirmek istiyorsanız Azure Databricks desteğine başvurun.
Not
SSH yalnızca çalışma alanınız kendi Azure sanal ağınızda dağıtıldığında etkinleştirilebilir.
Küme günlüğü teslimi
Küme oluştururken Spark sürücü düğümü, çalışan düğümleri ve olaylar için günlüklerin teslim edileceği konumu belirtebilirsiniz. Günlükler, her beş dakikada bir seçtiğiniz hedefe teslim edilir. Bir küme sonlandırıldığında Azure Databricks, küme sonlandırılana kadar oluşturulan tüm günlüklerin teslimini garanti eder.
Günlüklerin hedefi küme kimliğine bağlıdır. Belirtilen hedef ise dbfs:/cluster-log-delivery, için 0630-191345-leap375 küme günlükleri adresine dbfs:/cluster-log-delivery/0630-191345-leap375teslim edilir.
Günlük teslim konumunu yapılandırmak için:
Küme yapılandırması sayfasında Gelişmiş Seçenekler iki durumlu düğmesine tıklayın.
Günlük sekmesine tıklayın.
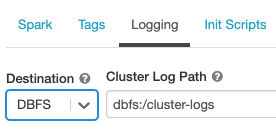
Bir hedef türü seçin.
Küme günlük yolunu girin.
Başlangıç betikleri
Küme düğümü başlatma (veya başlatma) betiği, Spark sürücüsü veya çalışan JVM başlamadan önce her küme düğümü için başlatma sırasında çalışan bir kabuk betiğidir. Databricks çalışma zamanına dahil olmayan paketleri ve kitaplıkları yüklemek, JVM sistem sınıfyolunu değiştirmek, JVM tarafından kullanılan sistem özelliklerini ve ortam değişkenlerini ayarlamak veya Spark yapılandırma parametrelerini diğer yapılandırma görevlerinin yanı sıra değiştirmek için init betiklerini kullanabilirsiniz.
Gelişmiş Seçenekler bölümünü genişletip Başlatma Betikleri sekmesine tıklayarak bir kümeye init betikleri ekleyebilirsiniz.
Ayrıntılı yönergeler için bkz . Init betikleri nedir?.