大部分的新式 GPU 都包含多個提供特殊功能的獨立引擎。 許多人有一或多個專用的複製引擎,以及計算引擎,通常與 3D 引擎不同。 每個引擎都可以彼此平行執行命令。 Direct3D 12 使用佇列和命令清單,對 3D、計算和複製引擎提供更細緻的存取。
GPU 引擎
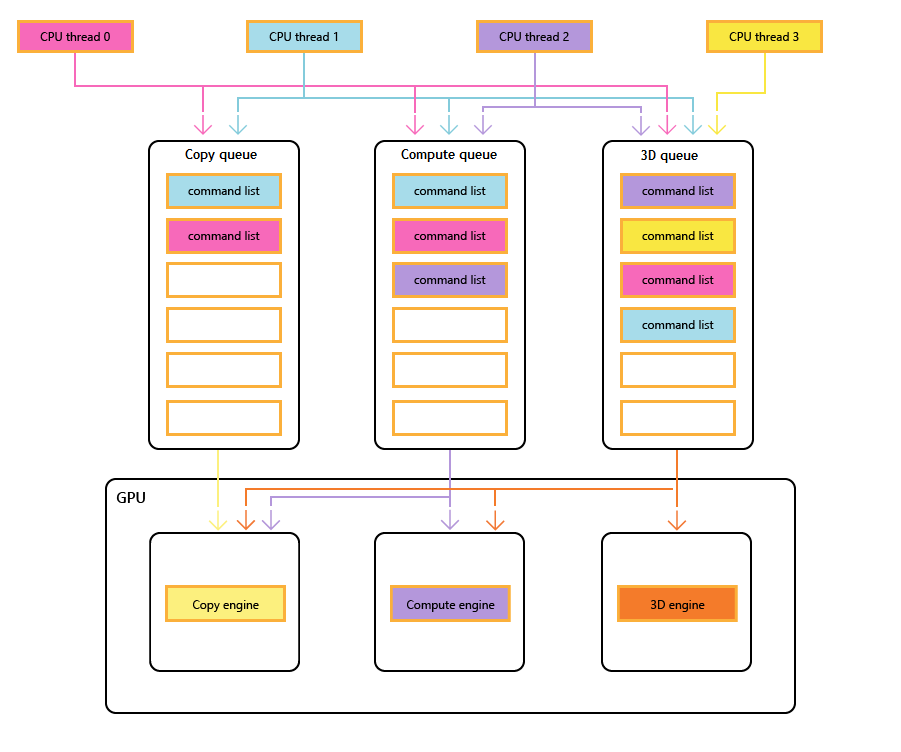
下圖顯示標題的CPU線程,每個線程都會填入一或多個複製、計算和3D佇列。 3D 佇列可以驅動這三個 GPU 引擎:計算佇列可以驅動計算和複製引擎;和複製佇列只是複製引擎。
當不同的線程填入佇列時,無法簡單保證執行順序,因此當標題需要它們時,需要同步處理機制。
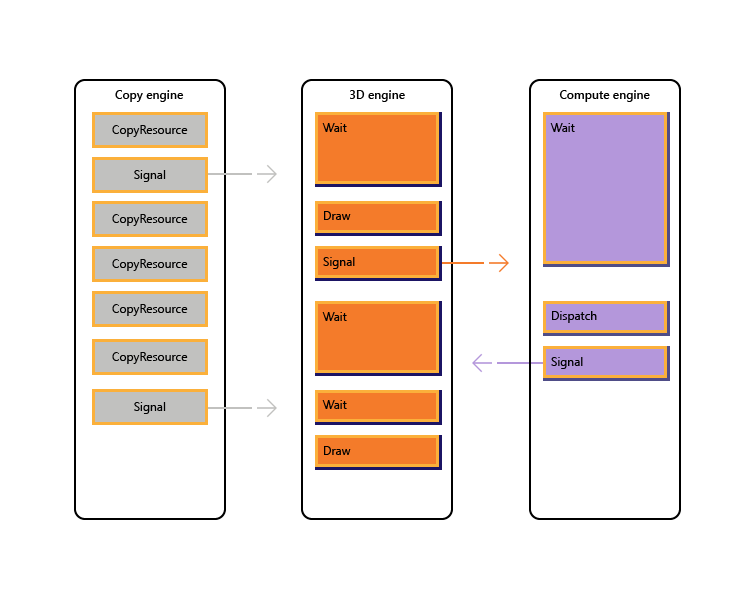
下圖說明標題如何排程跨多個 GPU 引擎運作,包括在必要時進行引擎間同步處理:它會顯示具有引擎間相依性的個別引擎工作負載。 在此範例中,複製引擎會先複製轉譯所需的一些幾何。 3D 引擎會等候這些複本完成,並轉譯幾何的預先傳遞。 計算引擎接著會取用此專案。 計算引擎 分派的結果,以及複製引擎上的數個紋理複製作業,會由 3D 引擎取用,以供最終 Draw 呼叫使用。
下列虛擬程式代碼說明標題如何提交這類工作負載。
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
下列虛擬程式代碼說明複製與 3D 引擎之間的同步處理,以透過通道緩衝區完成類似堆積的記憶體配置。 標題有彈性地在最大化平行處理原則(透過大型緩衝區)和減少記憶體耗用量和延遲(透過小型緩衝區)之間選擇正確的平衡。
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
多引擎案例
Direct3D 12 可讓您避免意外發生非預期的同步處理延遲所造成的效率不佳。 它也可讓您在較高層級引進同步處理,其中所需的同步處理可以透過更高的確定性來判斷。 多引擎解決的第二個問題是讓昂貴的作業更加明確,其中包括在 3D 與影片之間轉換,因為多個核心內容之間的同步處理,傳統上成本高昂。
特別是,您可以使用 Direct3D 12 來解決下列案例。
- 異步和低優先順序的 GPU 工作。 這可同時執行低優先順序 GPU 工作和不可部分完成的作業,讓一個 GPU 線程在不封鎖的情況下取用另一個未同步處理線程的結果。
- 高優先順序計算工作。 透過背景計算,可以中斷 3D 轉譯,以執行少量的高優先順序計算工作。 您可以提早取得這項工作的結果,以在CPU上進行額外的處理。
- 背景計算工作。 計算工作負載的個別低優先順序佇列可讓應用程式利用備用 GPU 循環來執行背景計算,而不會對主要轉譯或其他工作產生負面影響。 背景工作可能包括資源解壓縮,或更新模擬或加速結構。 背景工作應該不常在CPU上同步處理(大約每一個畫面一次),以避免擱置或使前景工作變慢。
- 串流和上傳數據。 個別的複製佇列會取代初始數據和更新資源的 D3D11 概念。 雖然應用程式負責 Direct3D 12 模型中的詳細數據,但此責任隨附電源。 應用程式可以控制用於緩衝上傳數據的系統內存量。 應用程式可以選擇何時及如何同步處理 (CPU 與 GPU、封鎖與非封鎖)同步處理,並可追蹤進度並控制已排入佇列的工作量。
- 增加平行處理原則。 當應用程式針對背景工作負載使用更深層的佇列(例如視訊譯碼)時,應用程式可以針對前景工作使用不同的佇列。
在 Direct3D 12 中,命令佇列的概念是應用程式所提交之大致序列工作的 API 表示法。 屏障和其他技術可讓這項工作以管線或順序錯亂執行,但應用程式只會看到單一完成時間軸。 這會對應至 D3D11 中的實時內容。
同步處理 API
裝置和佇列
Direct3D 12 裝置有方法來建立和擷取不同類型和優先順序的命令佇列。 大部分的應用程式都應該使用預設命令佇列,因為這些允許其他元件共用使用。 具有其他並行需求的應用程式可以建立其他佇列。 佇列是由其取用的命令清單類型所指定。
請參閱下列 ID3D12Device建立方法。
- CreateCommandQueue :根據 Direct3D 12_COMMAND_QUEUE_DESC 結構中的資訊建立命令佇列。
- CreateCommandList:建立 Direct3D 12_COMMAND_LIST_TYPE類型的命令清單。
- CreateFence:建立柵欄,指出 Direct3D 12_FENCE_FLAGS中的旗標。 柵欄可用來同步處理佇列。
所有類型的佇列(3D、計算和複製)會共用相同的介面,而且都是以命令清單為基礎的。
請參閱下列 ID3D12CommandQueue方法。
- ExecuteCommandLists :提交命令清單陣列以供執行。 ID3D12CommandList定義的每個命令清單。
- Signal :當佇列(在 GPU 上執行)到達特定點時,設定柵欄值。
- Wait:佇列會等到指定的柵欄到達指定的值為止。
請注意,任何佇列都不會取用套件組合,因此無法使用此類型來建立佇列。
圍欄
多引擎 API 提供明確的 API,以使用柵欄建立和同步處理。 柵欄是由 UINT64 值控制的同步處理建構。 應用程式會設定柵欄值。 訊號作業會修改柵欄值和等候作業區塊,直到柵欄達到要求的值或更高為止。 當柵欄達到特定值時,可以引發事件。
請參閱 ID3D12Fence 介面的方法。
- GetCompletedValue :傳回柵欄的目前值。
- SetEventOnCompletion :當柵欄達到指定值時,就會引發事件。
- Signal:將柵欄設定為指定的值。
柵欄允許 CPU 存取目前的柵欄值,以及 CPU 等候和訊號。
ID3D12Fence 介面上的 Signal 方法會更新 CPU 端的柵欄。 此更新會立即發生。 ID3D12CommandQueue 上的 Signal 方法 會更新 GPU 端的柵欄。 此更新會在命令佇列上完成所有其他作業之後發生。
多引擎設定中的所有節點都可以讀取並回應任何達到正確值的柵欄。
應用程式會設定自己的柵欄值,一個良好的起點可能會為每個畫面增加一次柵欄。
圍欄 可能會重新捲土重來。 這表示柵欄值不需要只遞增。 如果 Signal 作業加入佇列兩個不同的命令佇列,或者如果兩個 CPU 線程都在圍欄上呼叫 Signal,則可能會有一個競爭來判斷哪些 Signal 最後完成,因此哪個柵欄值會保留。 如果圍欄被捲土重來,任何新的等候(包括 SetEventOnCompletion 要求)都會與新的較低柵欄值進行比較,因此可能無法滿足,即使柵欄值先前已足夠高,以滿足它們。 如果發生競爭,在滿足未完成等候的值和較低的值之間,無論之後仍保留哪些值,等候 都會 滿足。
圍欄 API 提供強大的同步處理功能,但可能會造成偵錯問題的可能性。 建議每個柵欄只用來指出一個時程表上的進度,以防止信號器之間的競爭。
複製和計算命令清單
這三種類型的命令清單都使用 ID3D12GraphicsCommandList 介面,不過複製和計算只支援方法的子集。
複製和計算命令清單可以使用下列方法。
計算命令清單也可以使用下列方法。
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- DiscardResource
- 分派
- ExecuteIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
計算命令清單必須在呼叫 setPipelineState時設定計算 PSO。
套件組合無法與計算或複製命令清單或佇列搭配使用。
管線計算和圖形範例
此範例示範如何使用柵欄同步處理,在佇列上建立計算工作的管線(pComputeQueue所參考),而圖形工作在佇列上的工作 pGraphicsQueue。 計算和圖形工作是管線處理圖形佇列,從數個畫面格取用計算工作的結果,並使用 CPU 事件來節流整體排入佇列的工作總數。
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
若要支援此管道處理,您必須有一個緩衝區,ComputeGraphicsLatency+1 從計算佇列傳遞至圖形佇列的數據複本。 命令清單必須使用 UAV 和間接存取,從緩衝區中適當「版本」的數據讀取和寫入。 計算佇列必須等到圖形佇列完成從框架 N 的數據讀取,才能寫入框架 N+ComputeGraphicsLatency。
請注意,相對於 CPU 所處理的計算佇列數量並不直接取決於所需的緩衝量,不過,將 GPU 工作排入佇列超出可用緩衝區空間的數量會較不重要。
避免間接存取的替代機制是建立多個對應至每個「重新命名」數據版本的命令清單。 下一個範例會使用這項技術,同時擴充上一個範例,以允許計算和圖形佇列以更異步的方式執行。
異步計算和圖形範例
下一個範例可讓圖形以異步方式從計算佇列轉譯。 這兩個階段之間仍有固定的緩衝數據量,不過現在圖形工作會獨立進行,並在圖形工作排入佇列時,使用計算階段最 up-to日期結果,稱為 CPU。 如果圖形工作是由另一個來源更新,例如使用者輸入,這會很有用。 必須有多個命令清單,才能讓圖形工作的 ComputeGraphicsLatency 框架一次在飛行中,而函式 UpdateGraphicsCommandList 代表更新命令清單以包含最新的輸入數據,並從適當的緩衝區讀取計算數據。
計算佇列仍必須等候圖形佇列完成管道緩衝區,但引進第三個柵欄(pGraphicsComputeFence),以便能夠追蹤圖形讀取計算工作與圖形進度。 這反映了現在連續圖形畫面格可以從相同的計算結果讀取或略過計算結果的事實。 更有效率但稍微複雜的設計只會使用單一圖形柵欄,並將對應儲存至每個圖形框架所使用的計算畫面格。
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + CommandListIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
多佇列資源存取
若要存取多個佇列上的資源,應用程式必須遵循下列規則。
資源存取權(請參閱 Direct3D 12_RESOURCE_STATES)是由佇列類型類別而非佇列物件所決定。 佇列有兩種類型類別:計算/3D 佇列是一個類型類別,Copy 是第二個類型類別。 因此,在一個 3D 佇列上具有NON_PIXEL_SHADER_RESOURCE狀態障礙的資源,可以在任何 3D 或計算佇列上使用該狀態,但受限於需要串行化大部分寫入的同步處理需求。 在兩個類型類別之間共用的資源狀態(COPY_SOURCE和COPY_DEST)會被視為每個類型類別的不同狀態。 因此,如果資源轉換至複製佇列上的COPY_DEST,則無法從 3D 或計算佇列存取複製目的地,反之亦然。
總結。
- 佇列 「object」 是任何單一佇列。
- 佇列「類型」是下列三者之一:計算、3D 和複製。
- 佇列「類型類別」是這兩者之一:計算/3D 和複製。
COPY 旗標(COPY_DEST和COPY_SOURCE)用來做為初始狀態,代表 3D/Compute 類型類別中的狀態。 若要一開始在複製佇列上使用資源,它應該以 COMMON 狀態啟動。 COMMON 狀態可用於使用隱含狀態轉換在複製佇列上的所有使用方式。
雖然資源狀態會跨所有計算和 3D 佇列共用,但不允許在不同的佇列上同時寫入資源。 此處的「同時」表示在某些硬體上無法進行未同步處理,指出無法同步執行。 適用下列規則。
- 一次只能有一個佇列寫入資源。
- 只要寫入器未讀取正在修改的位元組,多個佇列就可以從資源讀取(正在同時寫入的位元組會產生未定義的結果)。
- 在寫入之後,必須先使用柵欄進行同步處理,然後另一個佇列才能讀取寫入的位元組或進行任何寫入存取。
所呈現的後端緩衝區必須處於 Direct3D 12_RESOURCE_STATE_COMMON 狀態。
相關主題
使用資源屏障同步處理 Direct3D 12 中的資源狀態
Direct3D 12 中的 記憶體管理