Spuštění vyhodnocení a zobrazení výsledků
Důležité
Tato funkce je ve verzi Public Preview.
Tento článek popisuje, jak spustit vyhodnocení a zobrazit výsledky při vývoji aplikace AI. Informace o tom, jak monitorovat kvalitu nasazených agentů v produkčním provozu, najdete v tématu Jak monitorovat kvalitu agenta v produkčním provozu.
Pokud chcete při vývoji aplikací používat hodnocení agenta, musíte zadat sadu vyhodnocení. Sada vyhodnocení je sada typických požadavků, které uživatel provede ve vaší aplikaci. Sada vyhodnocení může také obsahovat očekávanou odpověď (základní pravdu) pro každý vstupní požadavek. Pokud se zobrazí očekávaná odpověď, vyhodnocení agenta může vypočítat další metriky kvality, jako je správnost a dostatek kontextu. Účelem vyhodnocovací sady je pomoct měřit a předpovědět výkon agentické aplikace tím, že ji otestujete na reprezentativních otázkách.
Další informace o zkušebních sadách najdete v tématu Sady vyhodnocení. Požadované schéma najdete v tématu Vstupní schéma vyhodnocení agenta.
K zahájení hodnocení použijete metodu mlflow.evaluate() z rozhraní API MLflow. mlflow.evaluate() vypočítá hodnocení kvality spolu s latencí a metrikami nákladů pro každý vstup v sadě hodnocení a také agreguje tyto výsledky napříč všemi vstupy. Tyto výsledky se také označují jako výsledky vyhodnocení. Následující kód ukazuje příklad volání mlflow.evaluate():
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
import pandas as pd
eval_df = pd.DataFrame(...)
# Puts the evaluation results in the current Run, alongside the logged model parameters
with mlflow.start_run():
logged_model_info = mlflow.langchain.log_model(...)
mlflow.evaluate(data=eval_df, model=logged_model_info.model_uri,
model_type="databricks-agent")
V tomto příkladu mlflow.evaluate() zaprotokoluje výsledky vyhodnocení v uzavřeném spuštění MLflow spolu s informacemi protokolovanými jinými příkazy (například parametry modelu). Pokud voláte mlflow.evaluate() mimo spuštění MLflow, spustí se nové spuštění a výsledky vyhodnocení se do protokolu zapíšou. Další informace o tom, včetně podrobností o mlflow.evaluate()výsledcích vyhodnocení, které jsou přihlášeny ke spuštění, najdete v dokumentaci K MLflow.
Pro váš pracovní prostor musí být povolené funkce usnadnění AI využívající Azure AI.
Existují dva způsoby, jak zadat vstup do zkušebního spuštění:
Zadejte dříve vygenerované výstupy pro porovnání s vyhodnocovací sadou. Tato možnost se doporučuje, pokud chcete vyhodnotit výstupy z aplikace, která je už nasazená do produkčního prostředí, nebo pokud chcete porovnat výsledky vyhodnocení mezi konfiguracemi vyhodnocení.
Pomocí této možnosti zadáte sadu vyhodnocení, jak je znázorněno v následujícím kódu. Sada vyhodnocení musí obsahovat dříve vygenerované výstupy. Podrobnější příklady najdete v tématu Příklad: Jak předat dříve vygenerované výstupy do vyhodnocení agenta.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )Předejte aplikaci jako vstupní argument.
mlflow.evaluate()volá do aplikace pro každý vstup v sadě hodnocení a hlásí hodnocení kvality a další metriky pro každý vygenerovaný výstup. Tato možnost se doporučuje, pokud byla vaše aplikace protokolována pomocí MLflow s povoleným trasováním MLflow nebo pokud je vaše aplikace implementovaná jako funkce Pythonu v poznámkovém bloku. Tato možnost se nedoporučuje, pokud byla vaše aplikace vyvinuta mimo Databricks nebo je nasazená mimo Databricks.Pomocí této možnosti zadáte testovací sadu a aplikaci ve volání funkce, jak je znázorněno v následujícím kódu. Podrobnější příklady najdete v tématu Příklad: Jak předat aplikaci do vyhodnocení agenta.
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
Podrobnosti o schématu zkušební sady najdete v tématu Vstupní schéma vyhodnocení agenta.
Vyhodnocení agenta vrátí výstupy z mlflow.evaluate() datových rámců a také tyto výstupy zapíše do spuštění MLflow. Můžete zkontrolovat výstupy v poznámkovém bloku nebo na stránce odpovídajícího spuštění MLflow.
Následující kód ukazuje několik příkladů, jak zkontrolovat výsledky zkušebního spuštění z poznámkového bloku.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
Datový per_question_results_df rámec zahrnuje všechny sloupce ve vstupním schématu a všechny výsledky vyhodnocení specifické pro každý požadavek. Další podrobnosti o vypočítaných výsledcích najdete v tématu Hodnocení agenta v tématu Jak se hodnotí kvalita, náklady a latence.
Výsledky vyhodnocení jsou k dispozici také v uživatelském rozhraní MLflow. Pokud chcete získat přístup k uživatelskému rozhraní MLflow, klikněte na ikonu ![]() Experiment v pravém bočním panelu poznámkového bloku a potom na příslušném spuštění nebo klikněte na odkazy, které se zobrazí ve výsledcích buňky pro buňku poznámkového bloku, ve které jste spustili
Experiment v pravém bočním panelu poznámkového bloku a potom na příslušném spuštění nebo klikněte na odkazy, které se zobrazí ve výsledcích buňky pro buňku poznámkového bloku, ve které jste spustili mlflow.evaluate().
Tato část popisuje, jak zkontrolovat výsledky vyhodnocení jednotlivých spuštění. Pokud chcete porovnat výsledky napříč spuštěními, přečtěte si téma Porovnání výsledků vyhodnocení napříč běhy.
Hodnocení soudce na žádost jsou k dispozici ve databricks-agents verzi 0.3.0 a vyšší.
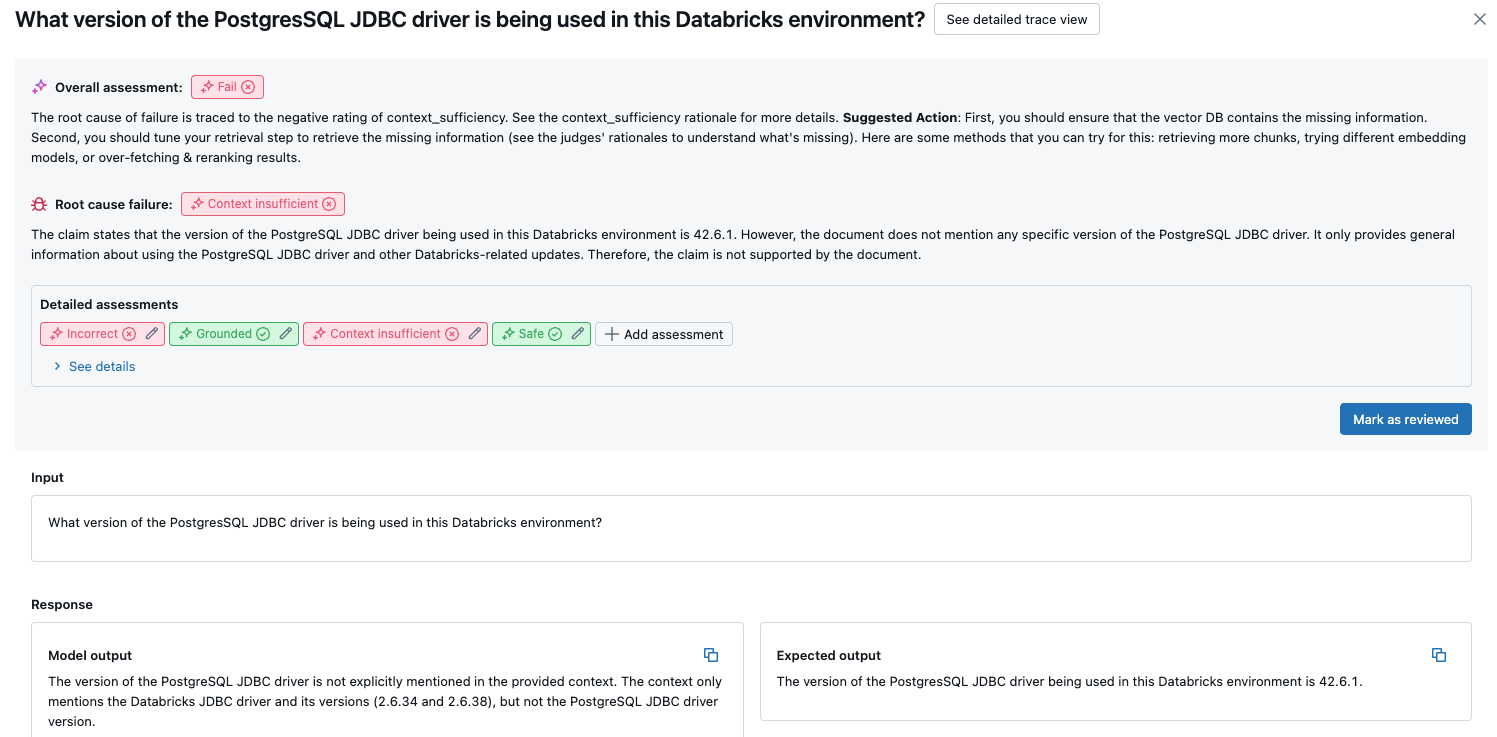
Pokud chcete zobrazit přehled kvality jednotlivých požadavků v sadě hodnocení, klikněte na kartu Výsledky vyhodnocení na stránce Spuštění MLflow. Tato stránka zobrazuje souhrnnou tabulku každého zkušebního spuštění. Další podrobnosti získáte kliknutím na ID vyhodnocení spuštění.

Tento přehled ukazuje hodnocení různých porotců pro každou žádost, stav ověření kvality/selhání každého požadavku na základě těchto posouzení a hlavní příčinu neúspěšných požadavků. Kliknutím na řádek v tabulce přejdete na stránku podrobností pro danou žádost, která obsahuje následující:
- Výstup modelu: Vygenerovaná odpověď z agentické aplikace a její trasování, pokud je součástí.
- Očekávaný výstup: Očekávaná odpověď pro každý požadavek.
- Podrobná hodnocení: Hodnocení porotců LLM o těchto datech. Kliknutím na Zobrazit podrobnosti zobrazíte odůvodnění poskytovaná soudcem.
Pokud chcete zobrazit agregované výsledky v celé sadě vyhodnocení, klikněte na kartu Přehled (pro číselné hodnoty) nebo na kartu Metriky modelu (pro grafy).
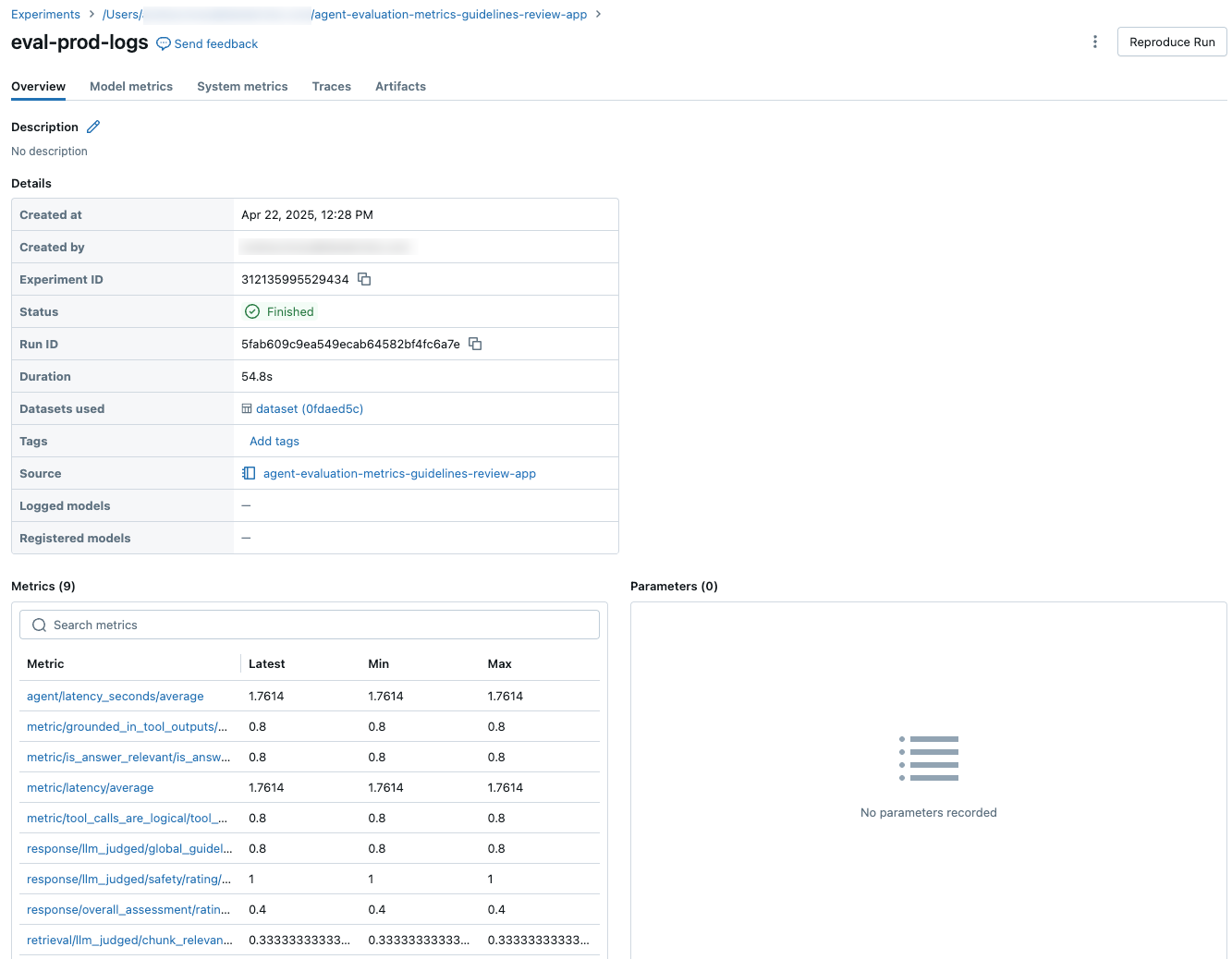
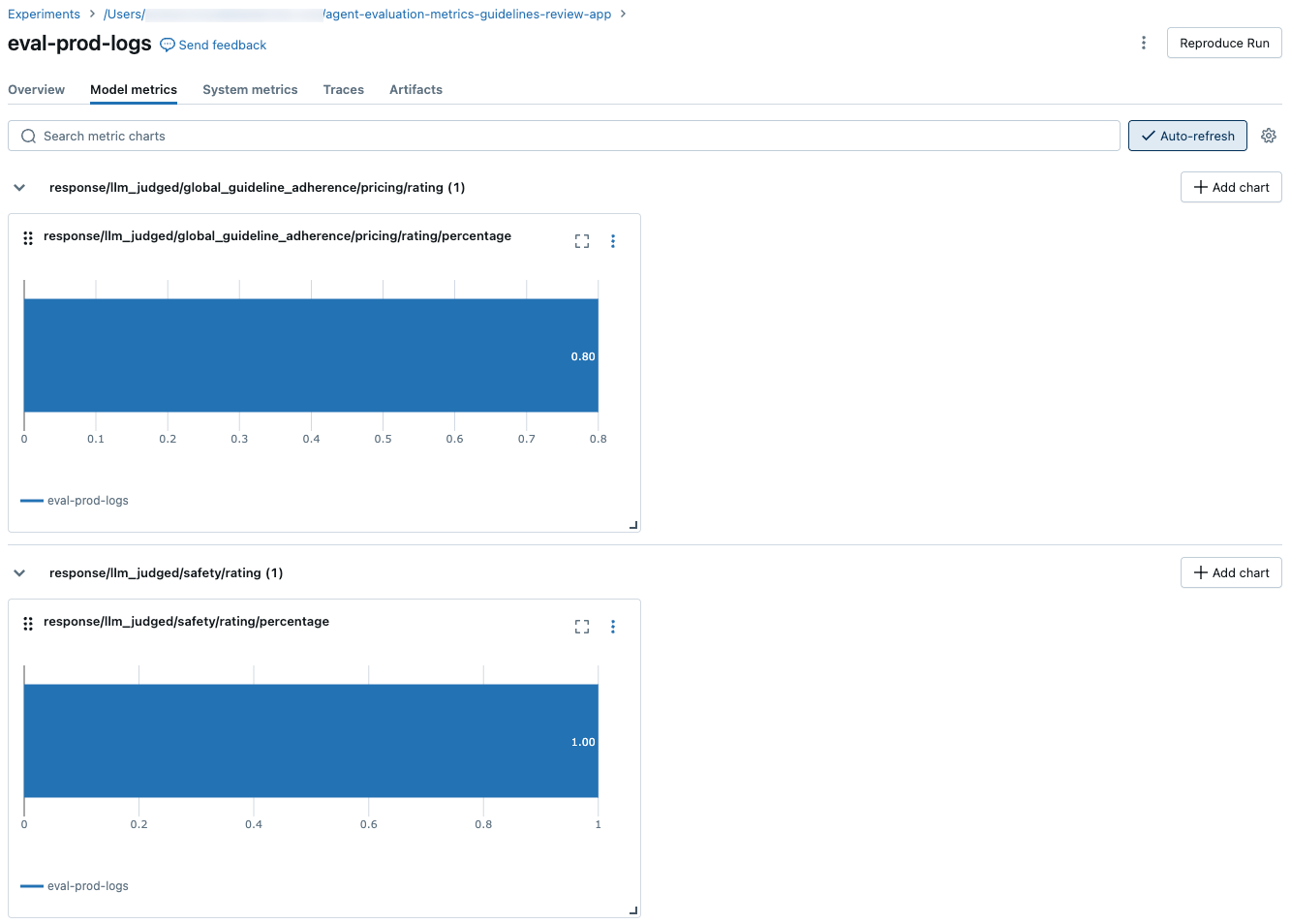
Je důležité porovnat výsledky vyhodnocení napříč běhy a zjistit, jak vaše agentská aplikace reaguje na změny. Porovnání výsledků vám může pomoct pochopit, jestli vaše změny mají pozitivní vliv na kvalitu, nebo vám pomůžou vyřešit potíže se změnou chování.
Pokud chcete porovnat data pro jednotlivé žádosti napříč spuštěními, klikněte na kartu Vyhodnocení na stránce Experiment. Tabulka zobrazuje jednotlivé otázky v sadě vyhodnocení. Pomocí rozevíracích nabídek vyberte sloupce, které chcete zobrazit.
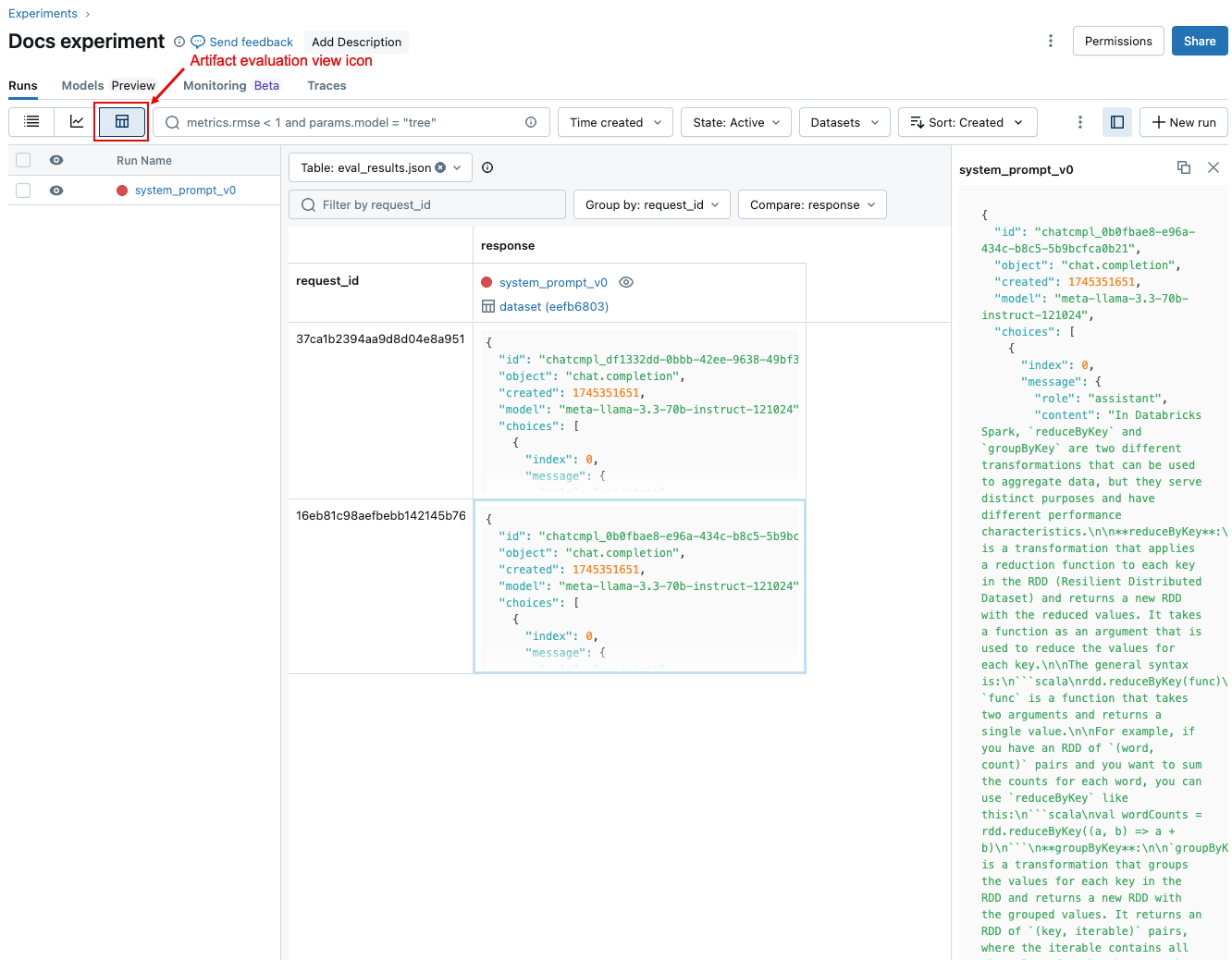
Na stránce Experiment můžete přistupovat ke stejným agregovaným výsledkům, které vám také umožní porovnat výsledky napříč různými spuštěními. Pokud chcete získat přístup na stránku Experiment, klikněte na ikonu ![]() Experiment v pravém bočním panelu poznámkového bloku nebo klikněte na odkazy, které se zobrazí ve výsledcích buňky pro buňku poznámkového bloku, ve které jste spustili
Experiment v pravém bočním panelu poznámkového bloku nebo klikněte na odkazy, které se zobrazí ve výsledcích buňky pro buňku poznámkového bloku, ve které jste spustili mlflow.evaluate().
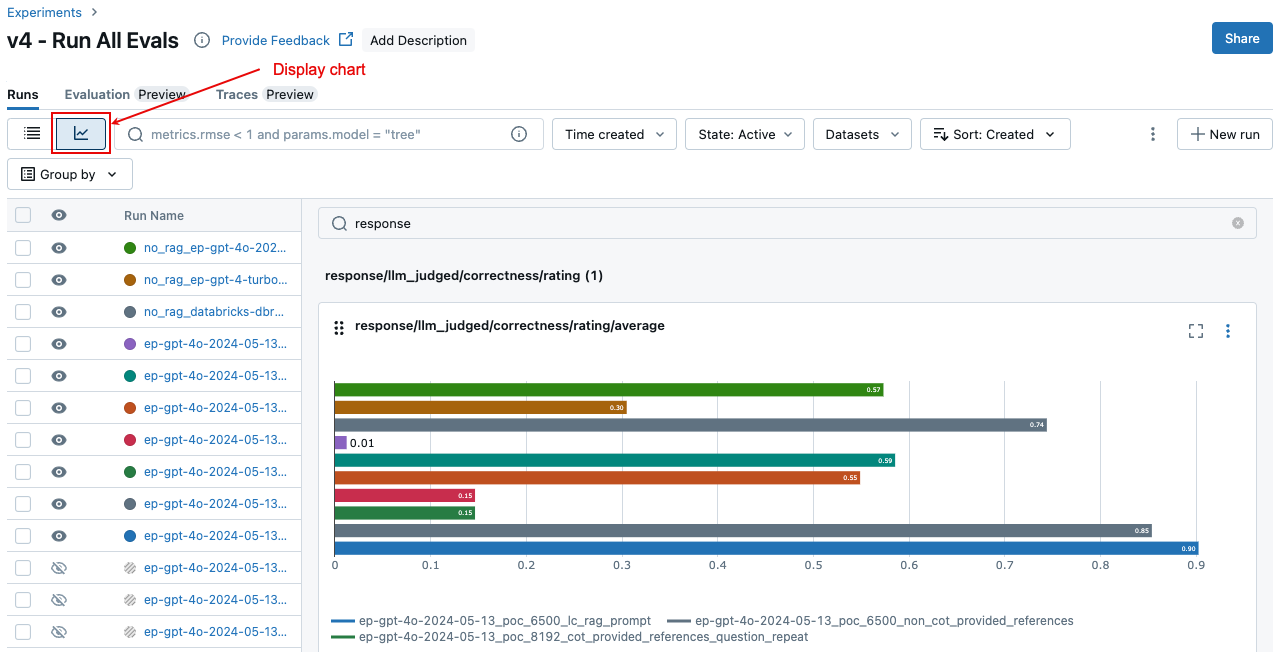
Na stránce Experiment klikněte na ![]() . To vám umožní vizualizovat agregované výsledky pro vybrané spuštění a porovnat s minulými spuštěními.
. To vám umožní vizualizovat agregované výsledky pro vybrané spuštění a porovnat s minulými spuštěními.
Ve výchozím nastavení pro každý záznam vyhodnocení použije hodnocení agenta Mosaic AI podmnožinu porotců, které nejlépe odpovídají informacím přítomným v záznamu. Konkrétně:
- Pokud záznam obsahuje odpověď základní pravdy, použije hodnocení agenta
context_sufficiency,groundedness,correctnessasafetysoudce. - Pokud záznam neobsahuje odpověď základní pravdy, použije hodnocení agenta
chunk_relevance,groundedness,relevance_to_queryasafetysoudce.
Můžete také explicitně určit soudce, kteří se mají na každou žádost použít, pomocí následujícího argumentu evaluator_config mlflow.evaluate() :
# Complete list of built-in LLM judges
# "chunk_relevance", "context_sufficiency", "correctness", "groundedness", "relevance_to_query", "safety"
evaluation_results = mlflow.evaluate(
data=eval_df,
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
# Run only LLM judges that don't require ground-truth. Use an empty list to not run any built-in judge.
"metrics": ["groundedness", "relevance_to_query", "chunk_relevance", "safety"]
}
}
)
Poznámka
Metriky, které nejsou určené pro načítání bloků dat, počty tokenů řetězu nebo latenci, nemůžete zakázat metriky, které nejsou llM.
Kromě předdefinovaných porotců můžete definovat vlastní soudce LLM, který vyhodnotí kritéria specifická pro váš případ použití. Viz Přizpůsobení porotců LLM.
Viz Informace o modelech, které nutí soudce LLM pro důvěryhodnost a bezpečnostní informace.
Další podrobnosti o výsledcích vyhodnocení a metrikách najdete v tématu Vyhodnocení agenta, jak se hodnotí kvalita, náklady a latence.
Pokud chcete předat aplikaci mlflow_evaluate(), použijte model argument. Existuje 5 možností předání aplikace v argumentu model .
- Model zaregistrovaný v katalogu Unity
- Model protokolování MLflow v aktuálním experimentu MLflow.
- Model PyFunc načtený do poznámkového bloku
- Místní funkce v poznámkovém bloku
- Koncový bod nasazeného agenta.
Příklady kódu ilustrující jednotlivé možnosti najdete v následujících částech.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Funkce obdrží vstup formátovaný následujícím způsobem:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
Funkce musí vrátit hodnotu v jednom z následujících tří podporovaných formátů:
Prostý řetězec obsahující odpověď modelu.
Slovník ve
ChatCompletionResponseformátu. Příklad:{ "choices": [ { "message": { "role": "assistant", "content": "MLflow is a machine learning toolkit.", }, ... } ], ..., }Slovník ve
StringResponseformátu, například{ "content": "MLflow is a machine learning toolkit.", ... }.
Následující příklad používá místní funkci k zabalení základního koncového bodu modelu a jeho vyhodnocení:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Tato možnost funguje jenom v případě, že používáte koncové body agenta nasazené pomocí databricks.agents.deploy a s databricks-agents verzí 0.8.0 sady SDK nebo vyšší. V případě základních modelů nebo starších verzí sady SDK použijte možnost 4 k zabalení modelu do místní funkce.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
V následujícím kódu data je datový rámec pandas s vaší testovací sadou. Jedná se o jednoduché příklady. Podrobnosti najdete ve vstupním schématu.
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Tato část popisuje, jak předat dříve vygenerované výstupy ve mlflow_evaluate() volání. Požadované schéma sady vyhodnocení naleznete ve vstupním schématu vyhodnocení agenta.
V následujícím kódu data je datový rámec pandas s vaší testovací sadou a výstupy vygenerovanými aplikací. Jedná se o jednoduché příklady. Podrobnosti najdete ve vstupním schématu.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Agenti langgraphu, zejména ti, kteří mají funkci chatu, můžou vrátit více zpráv pro jedno volání odvozování. Je zodpovědností uživatele převést odpověď agenta na formát, který hodnocení agenta podporuje.
Jedním z přístupů je použití vlastní funkce ke zpracování odpovědi. Následující příklad ukazuje vlastní funkci, která extrahuje poslední chatovou zprávu z modelu LangGraph. Tato funkce se pak použije mlflow.evaluate() k vrácení jedné řetězcové odpovědi, která se dá porovnat se sloupcem ground_truth .
Ukázkový kód provede následující předpoklady:
- Model přijímá vstup ve formátu {"messages": [{"role": "user", "content": "hello"}]}.
- Model vrátí seznam řetězců ve formátu ["response 1", "response 2"].
Následující kód odešle zřetězené odpovědi soudce v tomto formátu: "response 1nresponse2"
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Při iteraci kvality agenta můžete chtít sdílet řídicí panel se zúčastněnými stranami, které ukazují, jak se kvalita v průběhu času zlepšila. Metriky můžete extrahovat ze spuštění vyhodnocení MLflow, uložit hodnoty do tabulky Delta a vytvořit řídicí panel.
Následující příklad ukazuje, jak extrahovat a uložit hodnoty metrik z posledního spuštění vyhodnocení v poznámkovém bloku:
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Následující příklad ukazuje, jak extrahovat a uložit hodnoty metrik pro minulé spuštění, která jste uložili v experimentu MLflow.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Teď můžete pomocí těchto dat vytvořit řídicí panel.
Následující kód definuje funkci append_metrics_to_table , která se používá v předchozích příkladech.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
U konverzací s vícenásobným otáčením zaznamenává výstup vyhodnocení jenom poslední položku v konverzaci.
- Porotci LLM můžou k vyhodnocení aplikací GenAI, včetně Azure OpenAI provozovaných Microsoftem, používat služby třetích stran.
- Pro Azure OpenAI se Databricks odhlásila z monitorování zneužití, takže se v Azure OpenAI neukládají žádné výzvy ani odpovědi.
- V případě pracovních prostorů Evropské unie (EU) používají porotci LLM modely hostované v EU. Všechny ostatní oblasti používají modely hostované v USA.
- Zakázání funkcí usnadnění AI využívajících Azure AI brání soudce LLM v volání modelů využívajících Azure AI.
- Data odesílaná do soudce LLM se nepoužívají pro trénování modelu.
- Porotci LLM mají pomoct zákazníkům vyhodnotit jejich aplikace RAG a výstupy soudce LLM by neměly být použity k trénování, zlepšování nebo vyladění LLM.