Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Microsoft Fabric je analytické řešení typu vše v jednom pro podniky, které pokrývá vše od přesunu dat až po datové vědy, analýzy v reálném čase a business intelligence. Nabízí komplexní sadu služeb, včetně datového jezera, přípravy dat a integrace dat na jednom místě. Další informace najdete v tématu Co je Microsoft Fabric?
Tento kurz vás provede kompletním scénářem od získávání dat po spotřebu dat. Pomůže vám vytvořit základní znalosti o prostředcích infrastruktury, včetně různých prostředí a toho, jak se integrují, a také profesionální a občanské vývojářské prostředí, která jsou součástí práce na této platformě. Tento kurz není určen jako referenční architektura, vyčerpávající seznam funkcí nebo doporučení konkrétních osvědčených postupů.
Kompletní scénář Lakehouse
Organizace tradičně vytvářejí moderní datové sklady pro potřeby transakčních a strukturovaných analýz dat. A data lakehouses pro potřeby analýzy velkých objemů dat (částečně nebo nestrukturovaných) dat. Tyto dva systémy běžely paralelně a vytvářely sila, duplikaci dat a zvýšily celkové náklady na vlastnictví.
Prostředky infrastruktury s jeho sjednocením úložiště dat a standardizací ve formátu Delta Lake umožňují eliminovat sila, odebrat duplikaci dat a výrazně snížit celkové náklady na vlastnictví.
Díky flexibilitě, kterou nabízí Fabric, můžete implementovat architektury lakehouse nebo datového skladu nebo je kombinovat, abyste získali to nejlepší z obou s jednoduchou implementací. V tomto kurzu si vezmete příklad maloobchodní organizace a od začátku do konce sestavíte své jezerohouse. Používá architekturu medailiónu, ve které má bronzová vrstva nezpracovaná data, stříbrná vrstva má ověřená a odstraněná data a zlatá vrstva má vysoce upřesňující data. Stejný přístup můžete využít k implementaci jezera pro jakoukoli organizaci z libovolného odvětví.
Tento kurz vysvětluje, jak vývojář fiktivní společnosti Wide World Importers z maloobchodní domény dokončí následující kroky:
Přihlaste se ke svému účtu Power BI a zaregistrujte si bezplatnou zkušební verzi Microsoft Fabric. Pokud nemáte licenci Power BI, zaregistrujte si bezplatnou licenci Fabric, abyste mohli spustit zkušební verzi Fabric.
Sestavte a implementujte ucelený lakehouse pro vaši organizaci:
- Vytvořte pracovní prostor Fabric.
- Vytvořte jezero.
- Ingestování dat, transformace dat a jejich načtení do jezera. Můžete také prozkoumat OneLake, jednu kopii dat v režimu Lakehouse a v režimu koncového bodu SQL Analytics.
- Připojte se ke svému jezeru pomocí koncového bodu SQL Analytics a vytvořte sestavu Power BI pomocí DirectLake k analýze prodejních dat napříč různými dimenzemi.
- Volitelně můžete orchestrovat a plánovat příjem a transformaci dat pomocí kanálu.
Vyčistěte prostředky odstraněním pracovního prostoru a dalších položek.
Architektura
Následující obrázek znázorňuje komplexní architekturu lakehouse. Zahrnuté součásti jsou popsány v následujícím seznamu.

Zdroje dat: Prostředky infrastruktury umožňují rychlé a snadné připojení ke službám Azure Data Services a dalším cloudovým platformám a místním zdrojům dat pro efektivnější příjem dat.
Příjem dat: Přehledy pro vaši organizaci můžete rychle vytvářet pomocí více než 200 nativních konektorů. Tyto konektory jsou integrované do kanálu Fabric a využívají uživatelsky přívětivou transformaci dat pomocí toku dat. Kromě toho se pomocí funkce Zástupce v prostředcích infrastruktury můžete připojit k existujícím datům, aniž byste je museli kopírovat nebo přesouvat.
Transformace a ukládání: Standardizuje prostředky infrastruktury ve formátu Delta Lake. To znamená, že všechny moduly Fabric mají přístup ke stejné datové sadě uložené ve OneLake a manipulovat s nimi bez duplikování dat. Tento systém úložiště poskytuje flexibilitu při sestavování jezer s využitím architektury medailonu nebo datové sítě v závislosti na požadavcích vaší organizace. Pro transformaci dat si můžete vybrat prostředí s nízkým kódem nebo bez kódu, které využívá kanály, toky dat nebo poznámkové bloky nebo Spark pro první prostředí s kódem.
Využívání: Power BI může využívat data z Lakehouse pro vytváření sestav a vizualizaci. Každý Lakehouse má integrovaný koncový bod TDS, který se označuje jako koncový bod analýzy SQL, který umožňuje snadné připojení a dotazování dat v tabulkách Lakehouse z jiných nástrojů pro vytváření sestav. Koncový bod analýzy SQL poskytuje uživatelům funkce připojení SQL.
Ukázková datová sada
V tomto kurzu se používá ukázková databáze WWI (Wide World Importers), kterou naimportujete do jezera v dalším kurzu. V případě kompletního scénáře lakehouse jsme vygenerovali dostatečná data pro prozkoumání možností škálování a výkonu platformy Fabric.
Wide World Importers (WWI) je velkoobchodní dovozce nového zboží a distributor provozující z oblasti San Francisco Bay. Zákazníci WWI jako velkoobchodník většinou zahrnují společnosti, které přeprodeji jednotlivcům. WWI prodává maloobchodním zákazníkům v celém USA včetně speciálních obchodů, supermarketů, výpočetních obchodů, turistických atrakcí a některých jednotlivců. WWI také prodává jiným velkoobchodníkům prostřednictvím sítě agentů, kteří podporují produkty jménem WWI. Další informace o profilu a provozu společnosti najdete v ukázkových databázích Wide World Importers pro Microsoft SQL.
Obecně platí, že data se přenesou z transakčních systémů nebo obchodních aplikací do jezera. Pro zjednodušení v tomto kurzu však jako počáteční zdroj dat používáme dimenzionální model, který poskytuje WWI. Používáme ho jako zdroj k ingestování dat do jezera a transformujeme je prostřednictvím různých fází (bronzová, stříbrná a zlatá) architektury medailiónu.
Datový model
I když dimenzionální model WWI obsahuje mnoho tabulek faktů, v tomto kurzu používáme tabulku faktů Sale a její korelované dimenze. Následující příklad znázorňuje datový model WWI:

Tok dat a transformace
Jak jsme popsali dříve, k vytvoření tohoto uceleného jezera používáme ukázková data z WWI (Wide World Importers). V této implementaci jsou ukázková data uložená v účtu úložiště Dat Azure ve formátu souboru Parquet pro všechny tabulky. V reálných scénářích ale data obvykle pocházejí z různých zdrojů a v různých formátech.
Následující obrázek ukazuje zdroj, cíl a transformaci dat:

Zdroj dat: Zdrojová data jsou ve formátu souboru Parquet a v nedílné struktuře. Je uložená ve složce pro každou tabulku. V tomto kurzu nastavíme kanál pro příjem kompletních historických nebo jednorázových dat do jezera.
V tomto kurzu použijeme tabulku faktů Prodej , která obsahuje jednu nadřazenou složku s historickými daty po dobu 11 měsíců (s jednou podsložkou pro každý měsíc) a jinou složku obsahující přírůstková data po dobu tří měsíců (jedna podsložka pro každý měsíc). Během počátečního příjmu dat se do tabulky lakehouse ingestují 11 měsíců dat. Když však přírůstková data dorazí, zahrnují aktualizovaná data pro říjen a listopad a nová data pro prosinec a nov se sloučí s existujícími daty a nová data Dec se zapíšou do tabulky Lakehouse, jak je znázorněno na následujícím obrázku:
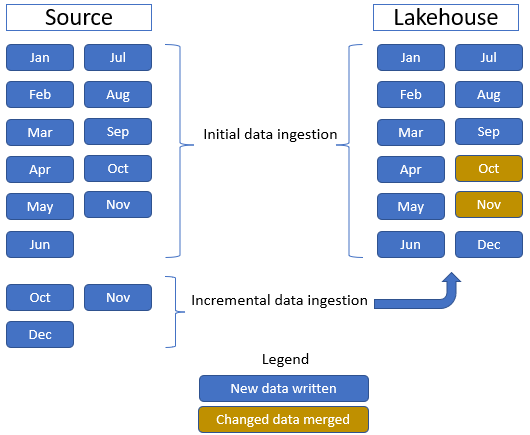
Lakehouse: V tomto kurzu vytvoříte jezerní dům, ingestujete data do oddílu souborů jezera a pak vytvoříte tabulky delta lake v části Tabulky jezera.
Transformace: Pro přípravu a transformaci dat se zobrazují dva různé přístupy. Předvedeme použití poznámkových bloků/Sparku pro uživatele, kteří dávají přednost prostředí s kódem a používají kanály/tok dat pro uživatele, kteří dávají přednost prostředí s nízkým kódem nebo bez kódu.
Využití: Abyste si ukázali spotřebu dat, uvidíte, jak můžete pomocí funkce DirectLake v Power BI vytvářet sestavy, řídicí panely a přímo dotazovat data z jezera. Kromě toho si ukážeme, jak můžete data zpřístupnit nástrojům pro vytváření sestav třetích stran pomocí koncového bodu TDS/SQL Analytics. Tento koncový bod umožňuje připojit se k skladu a spouštět dotazy SQL pro analýzy.
