Školení
Certifikace
Microsoft Certified: Datový inženýr Fabric Associate - Certifications
Jako datový inženýr infrastruktury byste měli mít zkušenosti se vzory načítání dat, architekturami dat a procesy orchestrace.
Tento prohlížeč se už nepodporuje.
Upgradujte na Microsoft Edge, abyste mohli využívat nejnovější funkce, aktualizace zabezpečení a technickou podporu.
Tento článek popisuje, jak vytvořit lakehouse, vytvořit tabulku Delta v jezeře a pak vytvořit základní sémantický model pro lakehouse v pracovním prostoru Microsoft Fabric.
Než začnete vytvářet lakehouse pro Direct Lake, nezapomeňte si přečíst přehled Direct Lake.
V pracovním prostoru Microsoft Fabric vyberte Nové>Další možnostia pak v Datovém inženýrstvívyberte dlaždici Lakehouse.
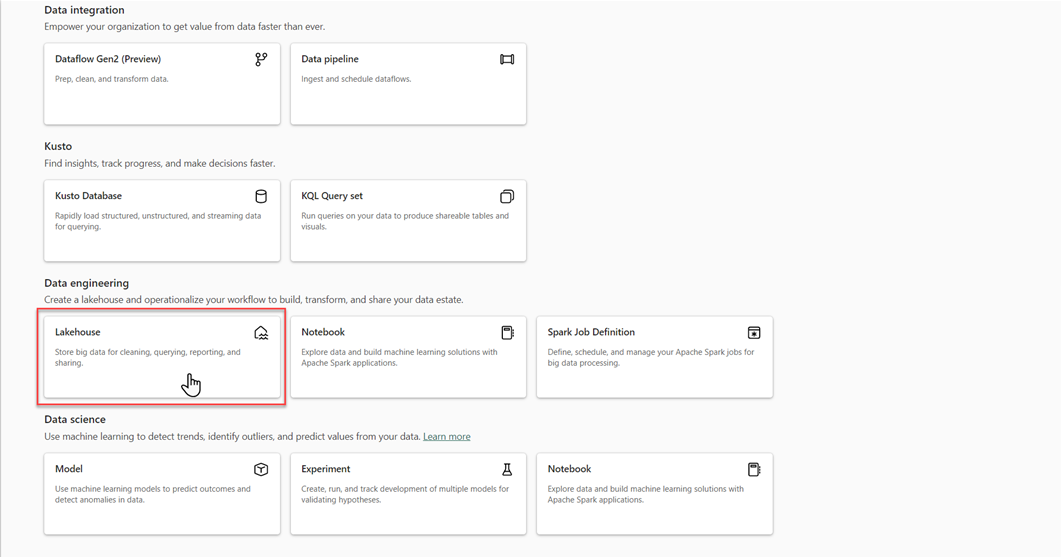
V dialogovém okně New lakehouse zadejte název a pak vyberte Vytvořit. Název může obsahovat pouze alfanumerické znaky a podtržítka.
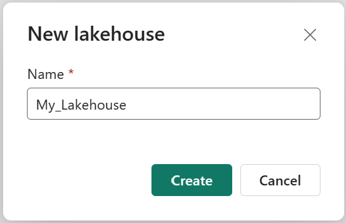
Ověřte, že se nový lakehouse vytvoří a úspěšně se otevře.
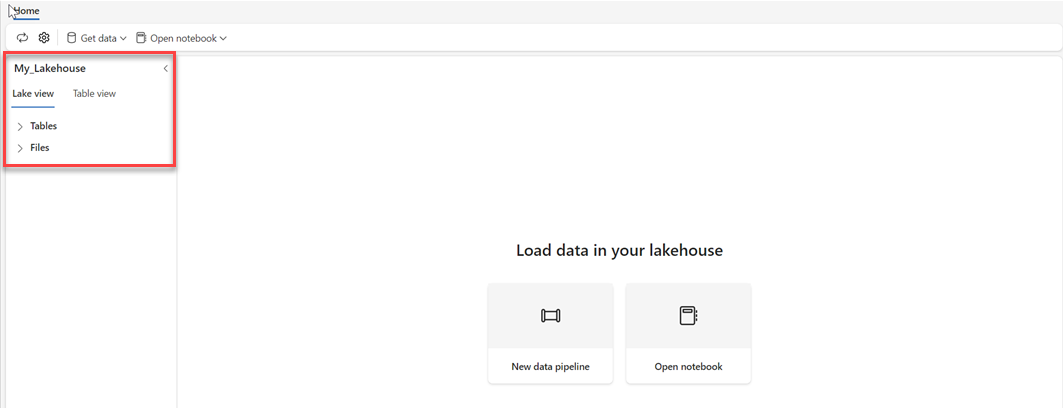
Po vytvoření nového lakehousu je nutné vytvořit alespoň jednu tabulku Delta, aby Direct Lake měl přístup k datům. Direct Lake může číst soubory ve formátu parquet, ale pro nejlepší výkon je nejlepší komprimovat data pomocí metody komprese VORDER. VORDER komprimuje data pomocí nativního algoritmu komprese modulu Power BI. Tímto způsobem může modul načíst data do paměti co nejrychleji.
Existuje několik možností, jak načíst data do jezera, včetně datových kanálů a skriptů. Následující kroky používají PySpark k přidání tabulky Delta do lakehouse založeného na Azure Open Dataset:
V nově vytvořeném lakehouse vyberte Otevřít poznámkový blok, a pak vyberte Nový poznámkový blok.
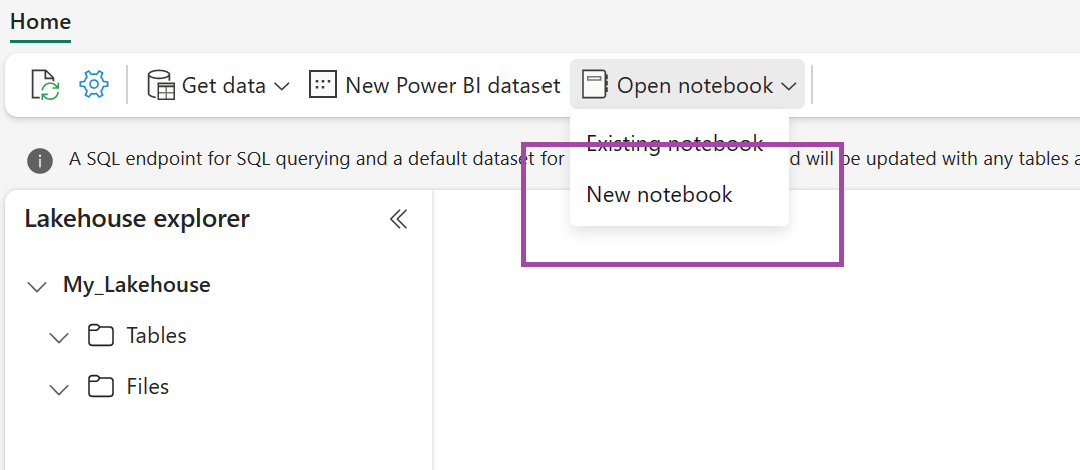
Zkopírujte a vložte následující fragment kódu do první buňky kódu, abyste sparku umožnili přístup k otevřenému modelu, a stisknutím kláves Shift + Enter kód spusťte.
# Azure storage access info
blob_account_name = "azureopendatastorage"
blob_container_name = "holidaydatacontainer"
blob_relative_path = "Processed"
blob_sas_token = r""
# Allow SPARK to read from Blob remotely
wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set(
'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name),
blob_sas_token)
print('Remote blob path: ' + wasbs_path)
Ověřte, že kód úspěšně vypíše cestu ke vzdálenému objektu blob.
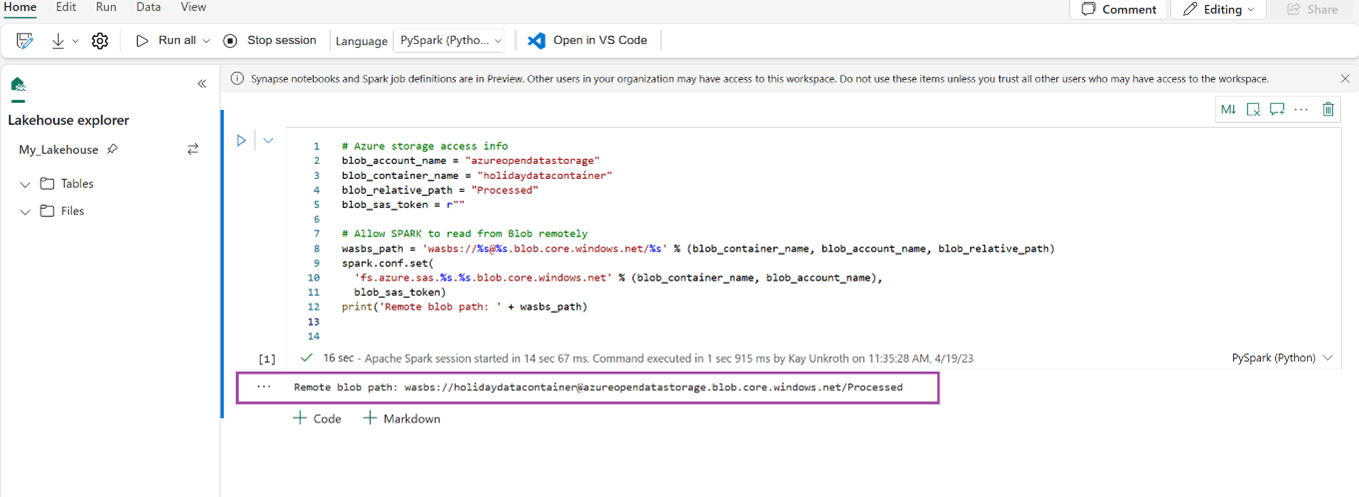
Zkopírujte a vložte následující kód do další buňky a stiskněte Shift + Enter.
# Read Parquet file into a DataFrame.
df = spark.read.parquet(wasbs_path)
print(df.printSchema())
Ověřte, že kód úspěšně vypíše schéma datového rámce.
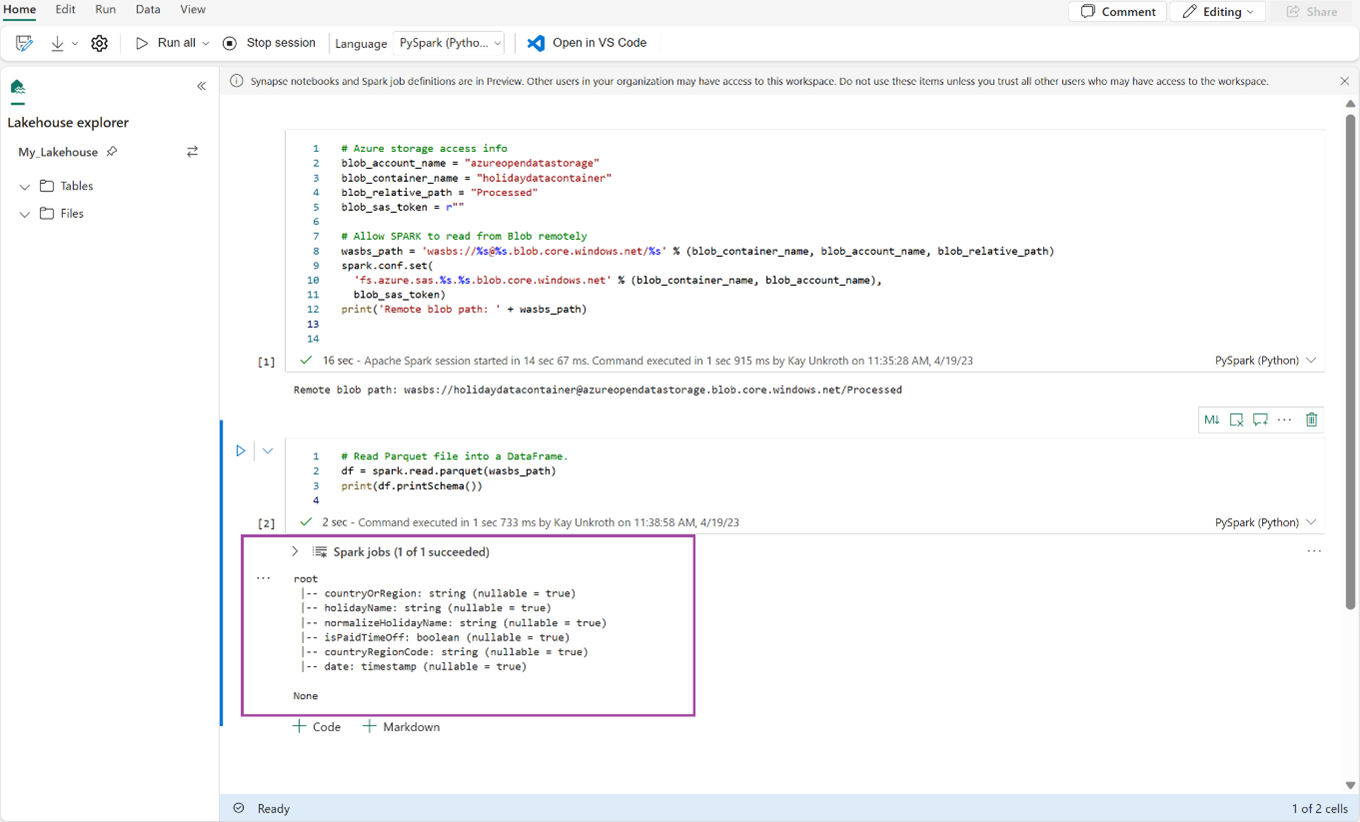
Zkopírujte a vložte následující řádky do další buňky a stiskněte Shift + Enter. První instrukce povolí metodu komprese VORDER a další instrukce uloží datový rámec jako tabulku Delta do jezera.
# Save as delta table
spark.conf.set("spark.sql.parquet.vorder.enabled", "true")
df.write.format("delta").saveAsTable("holidays")
Ověřte, že všechny úlohy SPARKu byly úspěšně dokončeny. Rozbalením seznamu úloh SPARK zobrazíte další podrobnosti.
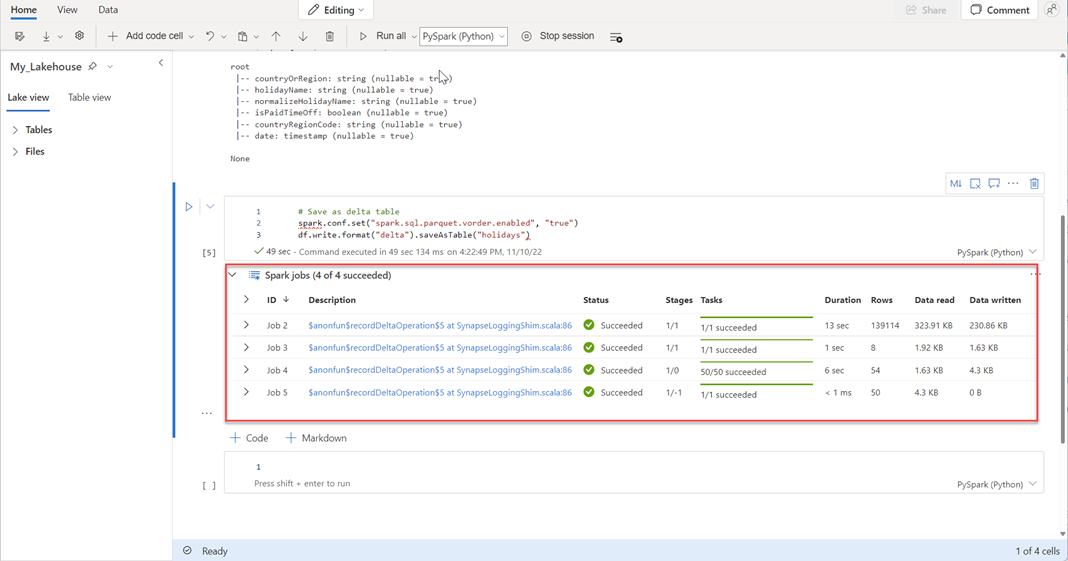
Pokud chcete ověřit úspěšné vytvoření tabulky, vyberte v levém horním rohu vedle Tabulkytři tečky (...), pak vyberte Aktualizovata rozbalte uzel Tabulky.
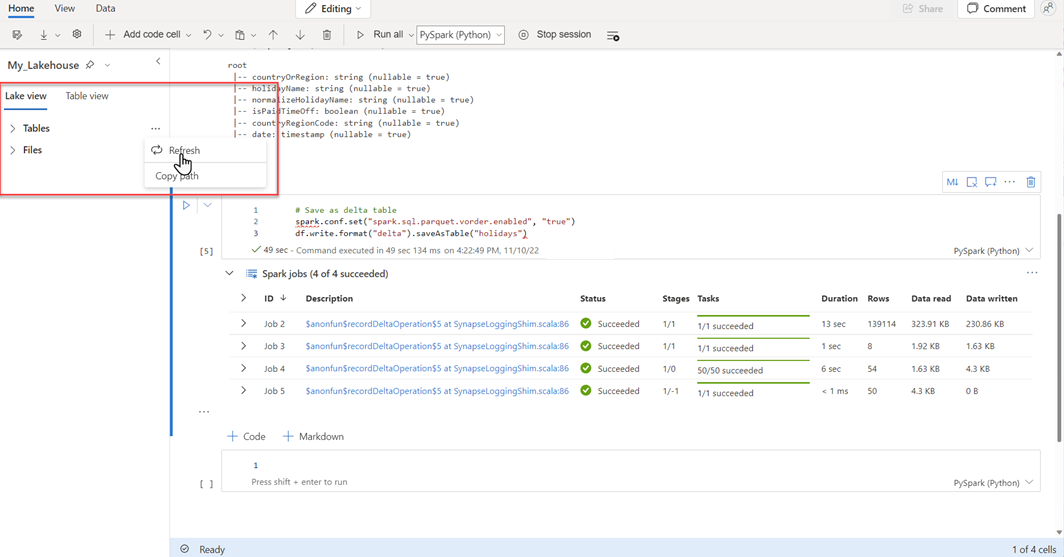
Pomocí stejné metody jako u výše uvedených nebo jiných podporovaných metod přidejte další tabulky Delta pro data, která chcete analyzovat.
Ve vašem lakehousu vyberte Nový sémantický modela potom v dialogovém okně vyberte tabulky, které zahrnout.
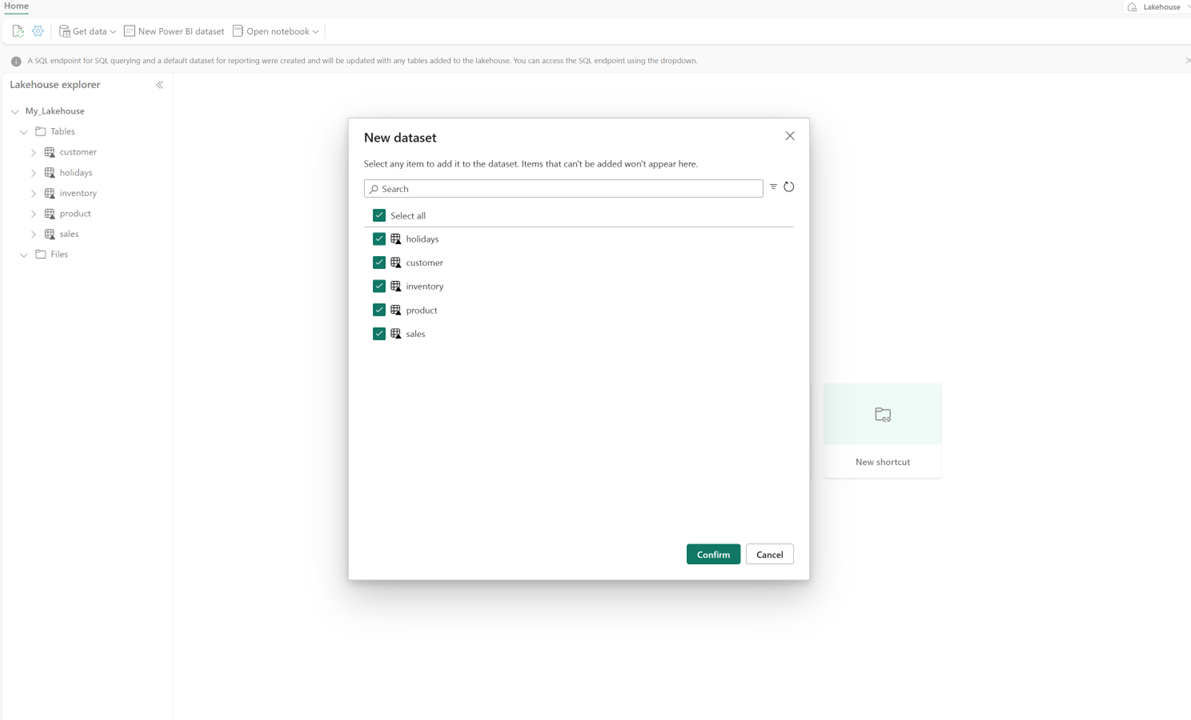
Výběrem možnosti Potvrdit vygenerujte model Direct Lake. Model se automaticky uloží do pracovního prostoru na základě názvu vašeho jezera a pak model otevře.
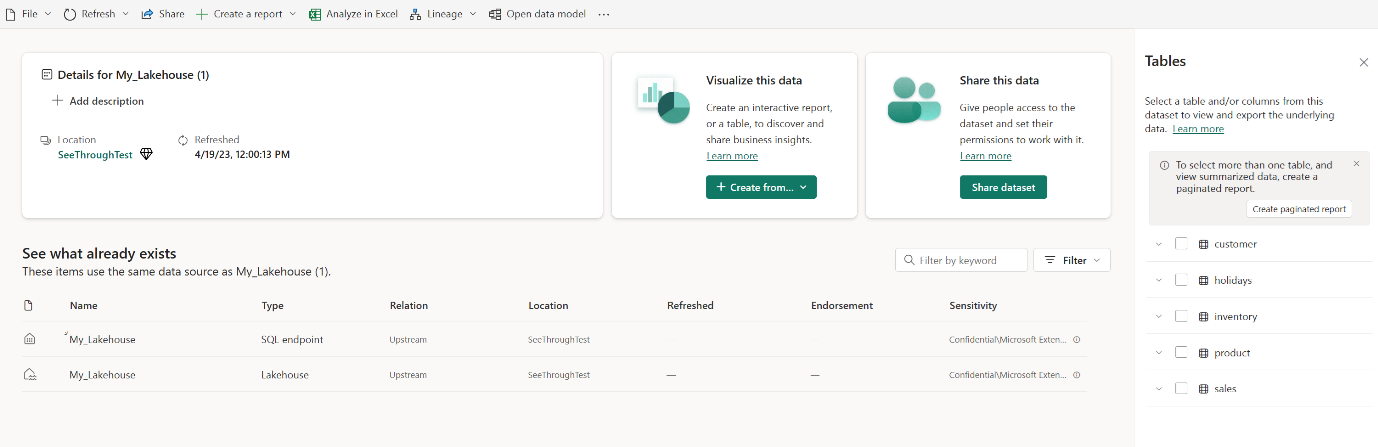
Výběrem možnosti Otevřít datový model se otevře webové prostředí pro modelování, kde můžete přidat relace mezi tabulkami a míry DAX.
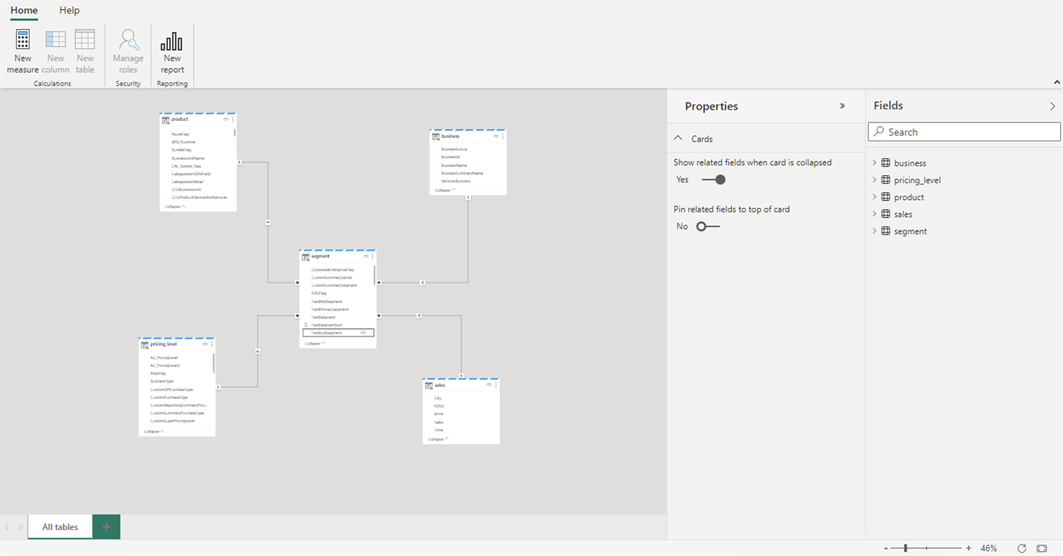
Jakmile dokončíte přidávání relací a měr DAX, můžete pak vytvářet sestavy, sestavovat složený model a dotazovat se na model prostřednictvím koncových bodů XMLA stejným způsobem jako u jakéhokoli jiného modelu.
Školení
Certifikace
Microsoft Certified: Datový inženýr Fabric Associate - Certifications
Jako datový inženýr infrastruktury byste měli mít zkušenosti se vzory načítání dat, architekturami dat a procesy orchestrace.
Dokumentace
Režim Direct Lake a generování sestav Power BI - Microsoft Fabric
Naučte se vytvářet sestavy Power BI s využitím dat lakehouse v Microsoft Fabric.
Pochopení úložiště pro sémantické modely Direct Lake - Microsoft Fabric
Přečtěte si o konceptech úložiště pro sémantické modely Direct Lake a o tom, jak optimalizovat spolehlivý a rychlý výkon dotazů.
Vývoj sémantických modelů Direct Lake - Microsoft Fabric
Přečtěte si, jak vyvíjet sémantické modely Direct Lake.