Gilt für: ✔️ Linux-VMs ✔️ Windows-VMs ✔️ flexible Skalierungssätze ✔️ einheitliche Skalierungssätze
Azure VM-Größen (Virtual Machines) sind so konzipiert, dass sie eine Vielzahl von Optionen zum Hosten Ihrer Server und ihrer Workloads in der Cloud bieten. Die Größen sind in verschiedene Kategorien von Familien und Typen unterteilt, die jeweils für bestimmte Zwecke optimiert sind. Benutzer können die am besten geeignete VM-Größe entsprechend ihren Anforderungen auswählen, z. B. nach CPU, Arbeitsspeicher, Speicher und Netzwerkbandbreite.
In diesem Artikel werden die Größen beschrieben, eine Übersicht über die verfügbaren Größen und verschiedene Optionen für Azure Instanzen virtueller Computer angezeigt, die Sie zum Ausführen Ihrer Apps und Workloads verwenden können.

Benennung der VM-Größen und -Serien
Azure VM-Größen folgen bestimmten Benennungskonventionen, um unterschiedliche Features und Spezifikationen zu kennzeichnen. Jedes Zeichen im Namen stellt unterschiedliche Aspekte der VM dar. Dazu zählen die VM-Familie, die Anzahl von virtuellen CPUs (vCPUs) und zusätzliche Features wie Storage Premium oder enthaltene Beschleuniger.
Die VM-Benennung wird weiter in den Namen der „Serie“ und den Namen „Größe“ unterteilt. Die Namen von Größen enthalten zusätzliche Zeichen, die die Anzahl von vCPUs, den Speichertyp usw. darstellen.
Aufschlüsselung der Namensstruktur
Im Folgenden sehen Sie eine Aufschlüsselung der Namensstruktur für die Größenserie „Universell, DCads_v5“.
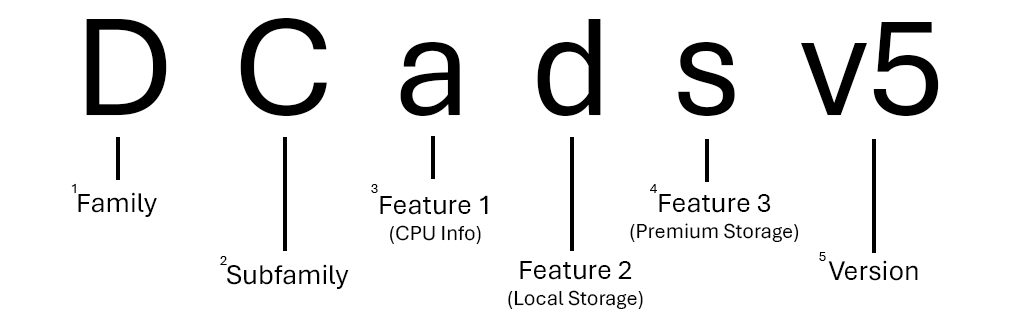 1 Die meisten Familien werden mit einem Buchstaben dargestellt, andere wie GPU-Größen (
1 Die meisten Familien werden mit einem Buchstaben dargestellt, andere wie GPU-Größen (ND-series, NV-seriesusw.) verwenden jedoch zwei.
2 Die meisten Unterfamilien werden mit einem einzigen Großbuchstaben dargestellt, andere (z Ebsv5-series. B. ) werden jedoch aufgrund von Funktionsunterschieden weiterhin als Unterfamilien ihrer Elternfamilie betrachtet.
3 Wenn kein Funktionsbuchstaben für eine CPU aufgeführt ist, verwendet die Serie Intel x86-64 CPUs. Eine AMD-CPU wird mit dem Buchstaben a angegeben. Wenn die CPU ARM basiert (Microsoft Kobalt oder Ampere Altra), wird sie als p aufgeführt.
4 In einem Größennamen kann eine beliebige Anzahl zusätzlicher Merkmale vorkommen. Es können beispielsweise keine (Dv5-series) oder drei (Dplds_v6-series) zusätzliche Features angegeben sein.
5 Versionsnummern werden nur im Größennamen angezeigt, wenn mehrere Versionen derselben Datenreihe vorhanden sind. Wenn Sie die erste Version einer Serie (HB-series, B-series usw.) verwenden, ist sie häufig nicht im Größenname enthalten.
Hinweis
Nicht alle Größen umfassen Unterfamilien, unterstützen Beschleuniger oder geben den CPU-Anbieter an. Weitere Informationen zu Benennungskonventionen für VM-Größen finden Sie unter Azure VM-Größenbenennungskonventionen.
Im Folgenden sehen Sie eine Aufschlüsselung der Größe „Standard_DC8ads_v5“ in der DCadsv5-Serie
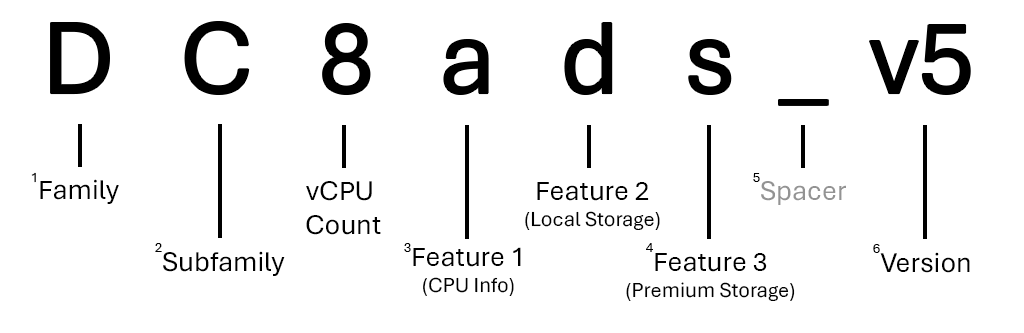 1 Die meisten Familien werden mit einem Buchstaben dargestellt, andere wie GPU-Größen (
1 Die meisten Familien werden mit einem Buchstaben dargestellt, andere wie GPU-Größen (ND-series, NV-seriesusw.) verwenden jedoch zwei.
2 Die meisten Unterfamilien werden mit einem einzigen Großbuchstaben dargestellt, andere (z Ebsv5-series. B. ) werden jedoch aufgrund von Funktionsunterschieden weiterhin als Unterfamilien ihrer Elternfamilie betrachtet.
3 Wenn kein Funktionsbuchstaben für eine CPU aufgeführt ist, verwendet die Serie Intel x86-64 CPUs. Eine AMD-CPU wird mit dem Buchstaben a angegeben. Wenn die CPU ARM basiert (Microsoft Kobalt oder Ampere Altra), wird sie als p aufgeführt.
4 In einem Größennamen kann eine beliebige Anzahl zusätzlicher Merkmale vorkommen. Es können beispielsweise keine (Dv5-series) oder drei (Dplds_v6-series) zusätzliche Features angegeben sein.
5 Größennamen können wie im Namen ND_H100_v5-series mehrere Abstandszeichen (Unterstriche) enthalten. In diesem Fall trennen sie die GPU-ID vom Rest des Größennamens.
6 Versionsnummern werden nur im Größennamen angezeigt, wenn mehrere Versionen derselben Datenreihe vorhanden sind. Wenn Sie die erste Version einer Serie (HB-series, B-series usw.) verwenden, ist sie häufig nicht im Größenname enthalten.
Hinweis
Nicht alle Größen umfassen Unterfamilien, unterstützen Beschleuniger oder geben den CPU-Anbieter an. Weitere Informationen zu Benennungskonventionen für VM-Größen finden Sie unter Azure VM-Größenbenennungskonventionen.
Liste der VM-Größenfamilien nach Typ
Dieser Abschnitt enthält eine Liste aller Größenserien der aktuellen Generation mit Registerkarten für die einzelnen Größenfamilien. Jede Gruppe verfügt über eine Spalte „Liste der Serien“ mit einer verknüpften Liste aller verfügbaren Größenserien. Über diese Links gelangen Sie zur Seite der Familie der jeweiligen Serie, auf der Sie detaillierte Informationen zu jeder Größe in dieser Serie finden oder zur Seite der Serie wechseln können, um eine Liste der Größen in dieser Serie einzusehen.
Wenn Sie mehr über eine Größenfamilie erfahren möchten, wählen Sie unter jedem Typabschnitt die Registerkarte "Familie" aus. Dort finden Sie eine Zusammenfassung mit einer kurzen Beschreibung der Familie, die Workloads, für die die Familie empfohlen wird, und einen Link, über den Sie die vollständige Seite der Familie mit Spezifikationen für alle Serien in dieser Familie anzeigen können.
Allgemeiner Zweck
Universelle VM-Größen zeichnen sich durch ein ausgewogenes Verhältnis zwischen CPU und Arbeitsspeicher aus. Ideal für Tests und Entwicklung, kleine bis mittlere Datenbanken sowie Webserver mit geringer bis mittlerer Auslastung.
A-Familie
Die "A"-Familie der VM-Größenreihe sind eine der allgemeinen VM-Instanzen von Azure. Sie sind für Workloads der Einstiegsstufe, z. B. Entwicklungs- und Testumgebungen, kleine bis mittlere Datenbanken und Webserver mit geringem Datenverkehr konzipiert.
Anzeigen der vollständigen Seite "A Family"
Cost Efficiency: VMs der A-Serie sind einige der budgetfreundlichesten Optionen, die für Azure verfügbar sind, wodurch sie eine gute Wahl für Projekte mit begrenzten finanziellen Ressourcen oder für Projekte, die keine leistungsstarken Computefunktionen erfordern, geeignet sind.
Allgemeine Workloads: VMs der A-Serie eignen sich gut für die Behandlung grundlegender Anwendungen, light Webserver und kleiner Datenbanken, die keine umfangreiche CPU-, Arbeitsspeicher- oder E/A-Leistung erfordern.
Entry-Level Anwendungen: VMs der A-Serie können als guter Ausgangspunkt für die Bereitstellung von Anwendungen dienen, die nicht wesentlich skaliert werden sollen. Sie bieten eine Plattform für Anwendungen und Dienste, die weniger Verarbeitungsleistung erfordern.
B-Familie
Die "B"-Familie der VM-Größenreihe ist eine der allgemeinen VM-Instanzen von Azure. Während herkömmliche Azure virtuelle Computer eine feste CPU-Leistung bieten, sind virtuelle B-Serie-Computer der einzige VM-Typ, der Guthaben für die CPU-Leistungsbereitstellung verwendet. VMs der B-Serie verwenden ein CPU-Kreditmodell, um nachzuverfolgen, wie viel CPU verbraucht wird – der virtuelle Computer sammelt CPU-Gutschriften, wenn eine Workload unter dem Schwellenwert für die Cpu-Leistung arbeitet und Guthaben verwendet, wenn sie über dem Schwellenwert für die Basis-CPU-Leistung ausgeführt wird, bis alle Guthaben verbraucht werden. Wenn das gesamte CPU-Guthaben aufgebraucht ist, wird ein virtueller Computer der B-Serie auf seine CPU-Basisleistung gedrosselt, bis wieder Guthaben für den CPU-Burst angesammelt wurde.
Vollständige B-Familienseite anzeigen
Nutzungsflexibilität: B-Familien-VMs eignen sich am besten für Workloads, die keine konstante volle CPU-Leistung erfordern.
Ideale Anwendungen: B-Familien-VMs sind ideale Anwendungen, darunter Webserver, Machbarkeitsnachweise, kleine Datenbanken und Entwicklungsbuildumgebungen.
Leistungsanforderungen: Einige Workloads haben oft stossweise Leistungsanforderungen, was bedeutet, dass sie nur sporadisch hohe Leistung benötigen. VMs der B-Serie eignen sich perfekt für diesen Anwendungsfall.
D-Familie
Die "D"-Familie von VM-Größen ist eine von den allgemeinen VM-Größen von Azure. Sie sind für eine Vielzahl von anspruchsvollen Workloads konzipiert, wie z. B. Unternehmensanwendungen, Web- und Anwendungsserver, Entwicklungs- und Testumgebungen sowie Batchverarbeitungsaufgaben. Ausgestattet mit schnelleren Prozessoren und mehr Arbeitsspeicher pro Kern als die A-Reihe, bieten die VMs der „D“-Reihe eine ausgewogene Leistung und eignen sich daher für Anwendungen, die sowohl eine hohe Rechenleistung als auch umfangreiche Speicherressourcen benötigen. Sie eignen sich besonders für die Ausführung von Unternehmensanwendungen und unterstützen Webserver mit mittlerem bis hohem Datenverkehr sowie datenintensive Batchverarbeitung.
Vollständige D-Familienseite anzeigen
Ausgewogene Leistung: VMs der D-Serie bieten ein solides Gleichgewicht zwischen CPU-Funktionen und Arbeitsspeichergröße, wodurch sie für die meisten Produktionsworkloads geeignet sind. Sie sind im Vergleich zur A-Reihe mit schnelleren Prozessoren ausgestattet und bieten mehr Arbeitsspeicher pro Kern.
Enterprise Applications: Sie eignen sich gut für die Ausführung von Unternehmensanwendungen wie SAP, Microsoft Dynamics oder großen relationalen Datenbanken, die sowohl eine hohe Rechenleistung als auch einen erheblichen Arbeitsspeicher erfordern.
Entwicklungs- und Testumgebungen: Mit ihren ausgewogenen Ressourcen eignen sich VMs der D-Serie ideal für Entwicklungs- und Testumgebungen, in denen Entwickler Produktionsbedingungen genau simulieren müssen.
Webserver und Anwendungsserver: Sie bieten die erforderlichen Ressourcen zum Hosten von Webservern und Anwendungsservern, die einen moderaten und starken Datenverkehr aufweisen, um eine reibungslose und reaktionsfähige Benutzererfahrung sicherzustellen.
Stapelverarbeitung: VMs der D-Serie sind effizient für Stapelverarbeitungsaufgaben, die eine schnelle Verarbeitung großer Datenmengen erfordern, dank ihrer schnellen Prozessoren und dem großzügigen Arbeitsspeicher.
Spieleserver: Die leistungsstarken Funktionen von VMs der D-Serie eignen sich für Gaming-Server, bei denen Latenz und Geschwindigkeit für eine gute Benutzererfahrung von entscheidender Bedeutung sind.
DC-Familie
Die "DC"-Serienfamilie ist eine der sicherheitsorientierten Allzweck-VM-Instanzen von Azure. Sie wurden für vertrauliche Computer entwickelt, die erweiterte Datenschutz- und Integritätsfunktionen mit verschiedenen hardwarebasierten vertrauenswürdigen Ausführungsumgebungen (Trusted Execution Environments, TEEs) bieten. Diese VMs eignen sich gut für viele allgemeine Computingworkloads, E-Commerce-Systeme, Web-Front-Ends, Desktopvirtualisierungslösungen, vertrauliche Datenbanken, andere Unternehmensanwendungen u. v. m.
Vollständige DC-Familienseite anzeigen
Datenschutz: VMs der DC-Serie eignen sich ideal für Anwendungen, die vertrauliche Daten verwalten, speichern und verarbeiten, z. B. personenbezogene Informationen (PII), Finanzdaten, Gesundheitsdaten und andere Arten vertraulicher Informationen. Die hardwarebasierte Verschlüsselung stellt sicher, dass Daten im Ruhezustand und während der Verarbeitung geschützt sind.
Einhaltung: Für Unternehmen, die strenge behördliche Anforderungen für Datenschutz und Sicherheit erfüllen müssen (z. B. DSGVO, HIPAA oder Finanzbranchenbestimmungen), bieten VMs der DC-Serie eine hardwaresichere Umgebung, die diese Complianceanforderungen erfüllen kann.
Computeoptimiert
Für Compute optimierte VM-Größen verfügen über ein hohes Verhältnis zwischen CPU und Arbeitsspeicher. Diese Größen sind ideal für Webserver, Netzwerkappliances, Batchvorgänge und Anwendungsserver mit mittlerer Auslastung.
Liste der für Compute optimierten VM-Größenfamilien:
Wenn Sie mehr über eine bestimmte Größenfamilie oder Serie erfahren möchten, wählen Sie die Registerkarte für diese Familie aus, und scrollen Sie, um ihre gewünschte Größenreihe zu finden.
F-Familie
Die "F"-Familie der VM-Größenserie ist eine von Azure's compute-optimierten VM-Instanzen. Sie sind für Workloads konzipiert, die eine hohe CPU-Leistung erfordern, z. B. Batchverarbeitung, Webserver, Analysen und Spiele. Mit einem hohen CPU-zu-Memory-Verhältnis sind VMs der F-Serie mit leistungsstarken Prozessoren ausgestattet, um Anwendungen zu verarbeiten, die mehr CPU-Kapazität im Verhältnis zum Arbeitsspeicher benötigen. Dies macht sie besonders effektiv für Szenarien, in denen schnelle und effiziente Verarbeitung kritisch ist, sodass Unternehmen ihre rechengebundenen Anwendungen effizient und kosteneffizient ausführen können.
Vollständige F-Familienseite anzeigen
Webserver: VMs der F-Serie eignen sich hervorragend für das Hosten von Webservern und Anwendungen, die eine erhebliche Computefunktion erfordern, um den Webdatenverkehr effizient zu verarbeiten, ohne unbedingt große Speichermengen zu benötigen.
Stapelverarbeitung: VMs der F-Serie eignen sich ideal für Batchaufträge und andere Verarbeitungsaufgaben, die das Behandeln großer Datenmengen oder Aufgaben in einer Warteschlange erfordern, aber cpuintensiver sind als arbeitsspeicherintensiv.
Anwendungsserver: Anwendungen, die eine schnelle Verarbeitung erfordern und keine hohen Speicheranforderungen haben, können von VMs der F-Serie profitieren. Dazu können mittlere Datenverkehrsanwendungsserver, Back-End-Server für Unternehmensanwendungen und andere ähnliche Aufgaben gehören.
Gaming Server: Aufgrund ihrer hohen CPU-Leistung eignen sich VMs der F-Serie auch für Gaming-Server, bei denen schnelle Verarbeitung für eine gute Spielerfahrung von entscheidender Bedeutung ist.
Analytik: VMs der F-Serie können für Datenanalyseanwendungen verwendet werden, die Verarbeitungsgeschwindigkeit zum Crunchen von Zahlen erfordern, und Berechnungen durchführen, die mehr als eine große Speichermenge erfordern.
FX-Familie
Die FX-Familie der VM-Größenserie gehört zu den speziellen computeoptimierten VM-Instanzen von Azure, die in erster Linie für Workloads entwickelt sind, die erhebliche CPU-Leistung erfordern. Diese VMs nutzen die neuesten Intel Ice Lake-Prozessoren und sind für rechenintensive Aufgaben wie Finanzmodellierung, wissenschaftliche Simulationen und aufwendige Berechnungen optimiert. Mit einer hohen Frequenz und einem großen Cache pro Kern bieten die VMs der FX-Serie eine außergewöhnliche Rechenleistung und sind damit ideal für Szenarien, die umfangreiche Verarbeitungsressourcen und eine schnelle Ausführung komplexer Vorgänge erfordern.
Die vollständige FX-Familienseite anzeigen
Electronic Design Automation (EDA):FX-Serien-VMs eignen sich gut für EDA-Workloads, die hohe CPU-Taktgeschwindigkeiten und hohe Arbeitsspeicher-zu-CPU-Verhältnisse erfordern. Diese Workloads profitieren von der hohen Einzelkernleistung und der großen Speicherkapazität der VMs der FX-Serie.
Stapelverarbeitung: VMs der FX-Serie eignen sich hervorragend für Verarbeitungsaufträge mit hohem Durchsatz, z. B. für groß angelegte Datenanalysen und Transformationen, bei denen eine schnelle Verarbeitung von entscheidender Bedeutung ist.
Datenanalyse: FX-Serien-VMs eignen sich für intensive Datenanalyseanwendungen, insbesondere für solche, die eine schnelle Iteration und Verarbeitung großer Datasets erfordern.
Arbeitsspeicheroptimiert
Arbeitsspeicheroptimierte VM-Größen bieten ein hohes Arbeitsspeicher-zu-CPU-Verhältnis und eignen sich hervorragend für relationale Datenbankserver, mittelgroße bis große Caches und In-Memory-Analysen.
Liste der arbeitsspeicheroptimierten VM-Größen mit Links zu den Abschnitten zu den einzelnen Serien auf der Seite der Familie:
Wenn Sie mehr über eine bestimmte Größenfamilie oder Serie erfahren möchten, wählen Sie die Registerkarte für diese Familie aus, und scrollen Sie, um ihre gewünschte Größenreihe zu finden.
E-Familie
Die "E"-Familie der VM-Größenreihe ist eine der speicheroptimierten VM-Instanzen Azure. Sie sind für arbeitsspeicherintensive Workloads konzipiert, z. B. große Datenbanken, Big Data-Analysen und Unternehmensanwendungen, die eine erhebliche RAM-Kapazität erfordern, um eine hohe Leistung zu gewährleisten. Ausgestattet mit hohen Verhältnissen von Arbeitsspeicher zu Kern unterstützen virtuelle Computer der E-Serie Anwendungen und Dienste, die von schnellerem Datenzugriff und effizienteren Datenverarbeitungsfunktionen profitieren. Dadurch eignen sie sich besonders gut für Szenarien mit In-Memory-Datenbanken und umfangreichen Datenverarbeitungsaufgaben, bei denen ausreichend Arbeitsspeicher für eine optimale Leistung von entscheidender Bedeutung ist.
Vollständige E-Familienseite anzeigen
Memory-Intensive Workloads: E-Familien-VMs sind für Workloads vorgesehen, die einen großen Speicherbedarf erfordern, um Aufgaben wie Simulationen, groß angelegte Berechnungen in der wissenschaftlichen Forschung oder finanzrelevante Risikomodellierung effizient zu verarbeiten.
Large Databases and SQL Servers: E-Family VMs eignen sich ideal zum Hosten großer relationaler Datenbanken wie SQL Server und NoSQL Datenbanken, die von hohen Speicherkapazitäten für eine verbesserte Leistung bei der Datenverarbeitung und Transaktionsverarbeitung profitieren.
Unternehmensanwendungen: E-Family-VMs eignen sich für ressourcenintensive Unternehmensanwendungen, einschließlich groß angelegter ERP- und CRM-Systeme, bei denen die Verfügbarkeit von ausreichend Arbeitsspeicher für die Verwaltung komplexer Transaktionen und Benutzerlasten von entscheidender Bedeutung ist.
Big Data-Anwendungen: E-Family-VMs sind effektiv für Big Data Analytics-Anwendungen, die große Datenmengen im Arbeitsspeicher verarbeiten müssen, um die Generierung von Analysen und Erkenntnissen zu beschleunigen.
In-Memory Computing: E-Familien-VMs eignen sich hervorragend für In-Memory-Datenbanken (z. B. SAP HANA), die große Mengen RAM erfordern, um das gesamte Dataset im Arbeitsspeicher zu halten, was eine ultraschnelle Datenverarbeitung und Abfrageantworten ermöglicht.
Data Warehouse: E-Family-VMs bieten die erforderlichen Ressourcen für Data Warehouse-Lösungen, die große Datasets verarbeiten und analysieren, die Abfrageleistung verbessern und die Reaktionszeiten reduzieren.
Eb-Familie
Die "Eb"-Familie der VM-Größenreihe ist eine der speicheroptimierten VM-Instanzen Azure. Sie sind für arbeitsspeicherintensive Workloads mit hoher Remotespeicherleistung konzipiert, z. B. große Datenbanken, Big Data-Analysen und Unternehmensanwendungen, die eine erhebliche Arbeitsspeicherkapazität (RAM) erfordern, um eine hohe Leistung zu gewährleisten. Dank hoher Arbeitsspeicher/Kern-Verhältnisse unterstützen VMs der Eb-Serie Anwendungen und Dienste, die von schnellerem Datenzugriff und effizienteren Datenverarbeitungsfunktionen profitieren. Dadurch eignen sie sich besonders gut für Szenarien mit In-Memory-Datenbanken und umfangreichen Datenverarbeitungsaufgaben, bei denen ausreichend Arbeitsspeicher für eine optimale Leistung von entscheidender Bedeutung ist.
Die vollständige Eb Family-Seite anzeigen
Memory-Intensive Workloads: Eb-Family-VMs sind für Arbeitslasten gedacht, die einen großen Speicherbedarf erfordern, um Aufgaben wie Simulationen, groß angelegte Berechnungen in der wissenschaftlichen Forschung oder finanzielle Risikomodellierung effizient zu verarbeiten.
Large Databases and SQL Servers: Eb-family VMs eignen sich ideal zum Hosten großer relationaler Datenbanken wie SQL Server und NoSQL Datenbanken, die von hohen Speicherkapazitäten für eine verbesserte Leistung bei der Datenverarbeitung und Transaktionsverarbeitung profitieren.
Unternehmensanwendungen: Eb-Family-VMs eignen sich für ressourcenintensive Unternehmensanwendungen, einschließlich groß angelegter ERP- und CRM-Systeme, bei denen die Verfügbarkeit von ausreichend Arbeitsspeicher für die Verwaltung komplexer Transaktionen und Benutzerlasten von entscheidender Bedeutung ist.
Big Data-Anwendungen: Eb-Family-VMs sind effektiv für Big Data Analytics-Anwendungen, die große Datenmengen im Arbeitsspeicher verarbeiten müssen, um die Generierung von Analysen und Erkenntnissen zu beschleunigen.
In-Memory Computing: Eb-Family-VMs eignen sich hervorragend für In-Memory-Datenbanken (z. B. SAP HANA), die große Mengen RAM erfordern, um das gesamte Dataset im Arbeitsspeicher zu halten, was eine extrem schnelle Datenverarbeitung und Abfrageantworten ermöglicht.
Data Warehouse: Eb-Family-VMs bieten die erforderlichen Ressourcen für Data Warehouse-Lösungen, die große Datasets verarbeiten und analysieren, die Abfrageleistung verbessern und die Reaktionszeiten reduzieren.
EC-Familie
Die "EC"-Unterfamilie der VM-Größenserie ist eine der auf Sicherheit fokussierten, speicheroptimierten VM-Instanzen von Azure. Sie sind für vertrauliche Computer mit verbesserter Datensicherheit und Integrität konzipiert, die verschiedene hardwarebasierte vertrauenswürdige Ausführungsumgebungen (Trusted Execution Environments, TEEs) enthält. Diese Instanzen sind ideal für arbeitsspeicherintensive Workloads geeignet, z. B. große Datenbanken, Big Data-Analysen und Unternehmensanwendungen, die eine erhebliche RAM-Kapazität erfordern, um Hochleistung zu gewährleisten.
Vollständige EC-Familienseite anzeigen
Memory-Intensive Workloads: Jede Arbeitsauslastung, die einen großen Speicherbedarf erfordert, um Aufgaben wie Simulationen, groß angelegte Berechnungen in der wissenschaftlichen Forschung oder finanzielle Risikomodellierung effizient zu verarbeiten.
Large Databases and SQL Servers: Sie eignen sich ideal für das Hosten großer relationaler Datenbanken wie SQL Server und NoSQL Datenbanken, die von hohen Speicherkapazitäten für eine verbesserte Leistung bei der Datenverarbeitung und Transaktionsverarbeitung profitieren.
Unternehmensanwendungen: Geeignet für ressourcenintensive Unternehmensanwendungen, einschließlich groß angelegter ERP- und CRM-Systeme, bei denen die Verfügbarkeit ausreichender Arbeitsspeicher für die Verwaltung komplexer Transaktionen und Benutzerlasten von entscheidender Bedeutung ist.
Big Data-Anwendungen: Effektiv für Big Data Analytics-Anwendungen, die große Datenmengen im Arbeitsspeicher verarbeiten müssen, um die Generierung von Analysen und Erkenntnissen zu beschleunigen.
In-Memory Computing: Wie z. B. In-Memory-Datenbanken (z. B. SAP HANA), die große Mengen RAM erfordern, um das gesamte Dataset im Arbeitsspeicher zu halten, was eine ultraschnelle Datenverarbeitung und Abfrageantworten ermöglicht.
Data Warehouse: Stellt die erforderlichen Ressourcen für Data Warehouse-Lösungen bereit, die große Datasets verarbeiten und analysieren, die Abfrageleistung verbessern und die Reaktionszeiten reduzieren.
M-Familie
Die M-Familie der VM-Größenreihe ist eine der ultra speicheroptimierten VM-Instanzen von Azure, die für extrem arbeitsspeicherintensive Workloads entwickelt wurden, wie z. B. große In-Memory-Datenbanken, Data Warehouse und High-Performance Computing (HPC). Ausgestattet mit erheblichen RAM-Kapazitäten und hohen vCPU-Funktionen unterstützen die M-Familien-VMs Anwendungen und Dienste, die massive Speichermengen und eine erhebliche Rechenleistung erfordern. Hohe Ressourcenzuordnung macht die M-Familie besonders geeignet für die Handhabung von Aufgaben wie schwere SQL Server- und andere RDBMS-Workloads, komplexe wissenschaftliche Simulationen, Echtzeit-Datenverarbeitung und Enterprise-Resource-Planning (ERP)-Systeme, um Spitzenleistung für die anspruchsvollsten datenzentrierten Anwendungen zu gewährleisten.
Vollständige M-Familienseite anzeigen
SQL Server Workloads mit hohem Speicherbedarf: Die M-Familie ist besonders effektiv für die Ausführung SQL Server Computer mit hohen Arbeitsspeicheranforderungen, z. B. für online transaction processing (OLTP) oder datenanalyse.
In-Memory-Datenbanken: Die M-Familie ist besonders effektiv für die Ausführung von In-Memory-Datenbanken, die große Rammengen wie SQL Server oder SAP HANA erfordern.
Big Data-Anwendungen: Die M-Familie eignet sich ideal für die Behandlung von Big Data-Anwendungen , die große Datasets im Arbeitsspeicher verarbeiten und analysieren müssen, um die Leistung zu verbessern und die Zeit für Einblicke zu reduzieren.
Data Warehouse: M-Familien-VMs bieten die Leistung und den Für Data Warehouse-Anwendungen benötigten Arbeitsspeicher, wodurch schnellere Abfragen und eine bessere Handhabung großer Datenmengen erleichtert werden.
Unternehmensanwendungen: Die M-Familie unterstützt groß angelegte Unternehmensanwendungen, einschließlich ERP- und CRM-Systeme, die von mehr Arbeitsspeicher profitieren, um größere Datasets und komplexere Transaktionen effizient zu verwalten.
Schwere Workloads in virtualisierten Umgebungen: Die M-Familie ist gut ausgestattet, um schwere virtualisierte Umgebungen zu verarbeiten, die erhebliche Arbeitsspeicher für das Hosten mehrerer virtueller Computer und Anwendungen auf einem einzigen physischen Server bieten.
Speicheroptimiert
Speicheroptimierte VM-Größen (Virtual Machine) bieten hohen Datenträgerdurchsatz und E/A und eignen sich ideal für Big Data, SQL, NoSQL Datenbanken, Data Warehouse und große Transaktionsdatenbanken. Beispiele bilden Cassandra, MongoDB, Cloudera und Redis.
Liste der datenspeicheroptimierten VM-Größenfamilien:
Wenn Sie mehr über eine bestimmte Größenfamilie oder Serie erfahren möchten, wählen Sie die Registerkarte für diese Familie aus, und scrollen Sie, um ihre gewünschte Größenreihe zu finden.
Die Familie L
Die "L"-Familie der VM-Größenreihe ist eine der speicheroptimierten VM-Instanzen Azure. Sie sind für Workloads konzipiert, die hohen Datenträgerdurchsatz und E/A erfordern, z. B. Datenbanken, Big Data-Anwendungen und Data Warehousing. VMs der L-Serie weisen einen hohen Datenträgerdurchsatz und eine große Kapazität des lokalen Datenträgerspeichers auf und unterstützen Anwendungen und Dienste, die von geringer Wartezeit und hohen Geschwindigkeiten bei sequenziellen Lese- und Schreibvorgängen profitieren. Dadurch eignen sie sich besonders gut für Aufgaben wie umfangreiche Protokollverarbeitung, Big Data-Analysen in Echtzeit und Szenarien mit großen Datenbanken, die häufige Festplattenvorgänge durchführen, und gewährleisten so eine effiziente Leistung für speicherintensive Anwendungen.
Vollständige L-Familienseite anzeigen
Big Data-Anwendungen: L-Familien-VMs eignen sich perfekt für Big Data-Anwendungen, die große Datasets verarbeiten, analysieren und bearbeiten müssen, die direkt auf lokalen Datenträgern gespeichert sind, und profitieren von der hohen E/A-Leistung.
Database Servers: L-Family VMs bieten die erforderliche lokale Datenträgerleistung für SQL Server, MySQL, PostgreSQL und andere Datenbankserver, die vom schnellen Zugriff auf den Datenträgerspeicher profitieren.
Dateiserver: L-Familien-VMs können effektiv als Dateiserver in einem Netzwerk verwendet werden, große Dateien verarbeiten und mit hohem Durchsatz bereitstellen, insbesondere in Umgebungen mit großen Mediendateien.
Videobearbeitung und -rendering: Der hohe Datenträgerdurchsatz und die Kapazität von L-Familien-VMs sind von Vorteil für Videobearbeitungs- und Renderingaufgaben, bei denen große Videodateien häufig gelesen und auf den Datenträger geschrieben werden.
GPU beschleunigt
GPU-optimierte VM-Größen sind spezielle virtuelle Maschinen, die mit einzelnen, mehreren oder teilweisen GPUs verfügbar sind. Diese Größen sind für rechenintensive, grafikintensive und visualisierungsorientierte Workloads vorgesehen.
Liste der GPU-optimierten VM-Größenfamilien:
Wenn Sie mehr über eine bestimmte Größenfamilie oder Serie erfahren möchten, wählen Sie die Registerkarte für diese Familie aus, und scrollen Sie, um ihre gewünschte Größenreihe zu finden.
NC-Familie
Die Unterfamilie "NC" der VM-Größenreihe ist eine der GPU-optimierten VM-Instanzen Azure. Sie sind für rechenintensive Workloads konzipiert, z. B. KI- und Machine Learning-Modellschulungen, High Performance Computing (HPC) und grafikintensive Anwendungen. Ausgestattet mit leistungsstarken NVIDIA-Grafikprozessoren bieten die VMs der NC-Serie eine erhebliche Beschleunigung für Prozesse, die eine hohe Rechenleistung erfordern, darunter Deep Learning, wissenschaftliche Simulationen und 3D-Rendering. Dadurch eignen sie sich besonders gut für Branchen wie Technologieforschung, Unterhaltung und Technik, in denen Rendering und Verarbeitungsgeschwindigkeit entscheidend für Produktivität und Innovation sind.
Vollständige NC-Familienseite anzeigen
AI und Maschinelles Lernen: VMs der NC-Serie eignen sich ideal für das Trainieren komplexer Modelle des Maschinellen Lernens und die Ausführung von KI-Anwendungen. Die NVIDIA-GPUs bieten eine erhebliche Beschleunigung für Berechnungen, die typischerweise bei Deep Learning und anderen intensiven Trainingsaufgaben anfallen.
High-Performance Computing (HPC): Diese VMs eignen sich für wissenschaftliche Simulationen, Rendering und andere HPC-Workloads, die von GPUs beschleunigt werden können. In Bereichen wie dem Ingenieurwesen, der medizinischen Forschung und der Finanzmodellierung werden häufig VMs der NC-Serie eingesetzt, um ihre Rechenanforderungen effizient zu erfüllen.
Grafikrendering: VMs der NC-Serie werden auch für grafikintensive Anwendungen verwendet, einschließlich Videobearbeitung, 3D-Rendering und Echtzeitgrafikverarbeitung. Sie sind besonders nützlich in Branchen wie der Spieleentwicklung und Filmproduktion.
Remotevisualisierung: Für Anwendungen, die High-End-Visualisierungsfunktionen erfordern, z. B. CAD und visuelle Effekte, können VMs der NC-Serie remote die erforderliche GPU-Leistung bereitstellen, sodass Benutzer an komplexen grafischen Aufgaben arbeiten können, ohne leistungsstarke lokale Hardware benötigen zu müssen.
Simulation und Analyse: Diese VMs eignen sich auch für detaillierte Simulationen und Analysen in Bereichen wie Automobilabsturztests, Rechenflüssigkeitsdynamik und Wettermodellierung, wo GPU-Funktionen die Verarbeitungszeiten erheblich beschleunigen können.
ND-Familie
Die "ND"-Familie der VM-Größenreihe ist eine GPU-beschleunigte VM-Instanz von Azure. Sie sind für Deep Learning, KI-Forschung und High Performance Computing-Aufgaben konzipiert, die von einer leistungsstarken GPU-Beschleunigung profitieren. Ausgestattet mit NVIDIA-GPUs bieten die VMs der ND-Reihe spezielle Funktionen für das Training und die Inferenz komplexer Machine Learning-Modelle, die schnellere Berechnungen und den effizienten Umgang mit großen Datensätzen ermöglichen. Dadurch eignen sie sich besonders gut für akademische und kommerzielle Anwendungen in der KI-Entwicklung und Simulation, wo modernste GPU-Technologie entscheidend ist, um schnelle und genaue Ergebnisse bei der Verarbeitung neuronaler Netzwerke und anderen rechenintensiven Aufgaben zu erzielen.
Anzeigen der vollständigen ND-Familienseite
KI und Deep Learning: VMs der ND-Familie eignen sich ideal für Schulungen und Die Bereitstellung komplexer Deep Learning-Modelle. Ausgestattet mit leistungsstarken NVIDIA-GPUs bieten sie die nötige Rechenleistung für das Training umfangreicher neuronaler Netze mit großen Datensätzen und verkürzen die Trainingszeiten erheblich.
High-Performance Computing (HPC): VMs der ND-Familie eignen sich für HPC-Anwendungen, die GPU-Beschleunigung erfordern. Bereiche wie wissenschaftliche Forschung, technische Simulationen (z. B. Computational Fluid Dynamics) und genomische Verarbeitung können von den Hochdurchsatz-Rechenkapazitäten der VMs der ND-Reihe profitieren.
NG-Familie
Die "NG"-Familie der VM-Größenserie ist eine der GPU-optimierten VM-Instanzen von Azure, die speziell für Cloudspiele und Remotedesktopanwendungen entwickelt wurden. Sie nutzen leistungsstarke AMD Radeon™ PRO GPUs, um hochwertige, interaktive Gaming-Erlebnisse in der Cloud bereitzustellen, die für das Rendern komplexer Grafiken und Streaming von High-Definition-Videos optimiert sind. Dadurch wird sichergestellt, dass Spieler eine nahtlose, reaktionsfähige Spielumgebung genießen, auf die von jedem Gerät aus zugegriffen werden kann. Darüber hinaus bieten VMs der NG-Serie eine qualitativ hochwertige, reaktionsfähige Remotedesktopumgebung, sodass sie ideal für Benutzer geeignet sind, die einen zuverlässigen, leistungsstarken Zugriff auf Desktopanwendungen von überall auf der Welt benötigen.
Vollständige NG-Familienseite anzeigen
Cloud Gaming: NG-Familien-VMs nutzen leistungsstarke AMD Radeon™ PRO GPUs, um hochwertige, interaktive Gaming-Erlebnisse in der Cloud zu bieten.
Remote Destkop: VMs der NG-Familie können für Remotedesktopanwendungen verwendet werden und bieten Benutzern eine qualitativ hochwertige, reaktionsfähige Benutzeroberfläche.
NV-Familie
Die "NV"-Familie der VM-Größenreihe ist eine der GPU-beschleunigten VM-Instanzen von Azure, die speziell für grafikintensive Anwendungen wie Grafikrendering, Simulation und virtuelle Desktops entwickelt wurden. Ausgestattet mit NVIDIA- oder AMD-Grafikprozessoren bieten die VMs der NV-Serie eine robuste Plattform für das Rendering und die Verarbeitung grafikintensiver Aufgaben und sind damit ideal für Unternehmen, die virtuelle Workstations mit leistungsstarken grafischen Funktionen benötigen. Diese virtuellen Computer unterstützen Szenarien, in denen Remotevisualisierung, Echtzeitzusammenarbeit und 3D-Visualisierung erforderlich sind, sodass Benutzer grafikintensive Anwendungen effizient direkt aus der Cloudumgebung Azure ausführen können.
Vollständige NV-Familienseite anzeigen
Virtual Desktop Infrastructure (VDI): NV-Familien-VMs eignen sich gut für virtuelle Desktops, die GPU-Funktionen für Aufgaben wie Grafikdesign, Videobearbeitung und CAD-Anwendungen erfordern. Sie bieten die erforderliche grafische Leistung für einen reibungslosen Betrieb in Remote-Desktop-Szenarien.
3D-Visualisierung: VMs der NV-Familie eignen sich ideal für die Ausführung von 3D-Anwendungen, die hochleistungsfähiges Rendering erfordern, z. B. Architekturvisualisierungen, medizinische Bildverarbeitung und andere aufgaben auf professioneller Qualität.
Remote-Grafik-Arbeiten: VMs der NV-Serie sind von Vorteil für Branchen, die auf grafikintensive Software angewiesen sind, sodass Fachleute auf Anwendungen wie Adobe Photoshop, Autodesk AutoCAD oder Dassault SOLIDWORKS remote mit nahezu nativer Leistung zugreifen und diese verwenden können.
High-Resolution Bildverarbeitung: VMs der NV-Serie eignen sich ideal für die Verarbeitung extrem großer vRAM-Anwendungen wie hochauflösende Bildverarbeitung und Analyse. Dazu gehören Aufgaben in Bereichen wie der geografischen Analyse, der Verarbeitung von Satellitenbildern und der professionellen Fotobearbeitung, bei denen die Handhabung großer Bilddateien und die Durchführung komplexer Manipulationen in Echtzeit entscheidend für Produktivität und Leistung sind.
Videostreaming: NV-Familien-VMs eignen sich für das Streamen von hochauflösenden Videoinhalten, einschließlich Schulungsvideos und virtuellen Ereignissen, um eine qualitativ hochwertige Bereitstellung ohne lokale Hardwareeinschränkungen sicherzustellen.
FPGA-beschleunigt
FPGA-optimierte VM-Größen sind spezialisierte virtuelle Maschinen, die mit einzelnen oder mehreren FPGAs verfügbar sind. Diese Größen sind für rechenintensive Workloads ausgelegt. Dieser Artikel enthält Informationen über die Anzahlen und Typen von FPGAs, vCPUs, Datenträgern und NICs. Der Speicherdurchsatz und die Netzwerkbandbreite sind für die jeweiligen Größen in dieser Gruppe ebenfalls enthalten.
Liste der FPGA (Field Programmable Gate Array)-beschleunigten VM-Größenfamilien:
| Familie |
Arbeitslasten |
Liste der Serien |
|
NP-Familie |
Machine Learning-Rückschluss
Videotranscodierung
Datenbanksuche und -analyse |
NP-Serie |
Wenn Sie mehr über eine bestimmte Größenfamilie oder Serie erfahren möchten, wählen Sie die Registerkarte für diese Familie aus, und scrollen Sie, um ihre gewünschte Größenreihe zu finden.
NP-Familie
Die NP-Unterfamilie der VM-Größenserie umfasst FPGA-beschleunigte VM-Instanzen von Azure. Sie sind für benutzerdefinierte Hardwarebeschleunigungsszenarien konzipiert, einschließlich Machine Learning-Ableitung, Videotranscodierung und Datenbanksuche & Analysen. NP-series VMs werden von AMD Xilinx Alveo U250 FPGAs und Intel Xeon 8171M (Skylake) CPUs unterstützt.
Anzeigen der vollständigen NP-Familienseite
Real-Time Datenverarbeitung: VMs der NP-Familie zeichnen sich in Umgebungen aus, in denen Daten in Echtzeit mit minimaler Latenz verarbeitet werden müssen, z. B. im Finanzhandel, in Echtzeitanalysen und in der Netzwerkdatenverarbeitung.
Custom AI und Machine Learning: NP-Familien-VMs eignen sich zum Beschleunigen von KI- und machine learning Rückschlussaufgaben, bei denen das FPGA programmiert werden kann, um bestimmte Algorithmen manchmal schneller auszuführen als typische CPU- oder GPU-basierte Lösungen.
Genomik und Lebenswissenschaften: NP-Familien-VMs können genomische Sequenzierungsaufgaben und andere Life Sciences-Anwendungen erheblich beschleunigen, die von der benutzerdefinierten Hardwarebeschleunigung profitieren.
Videotranscodierung und Streaming: FPGAs können verwendet werden, um Videoverarbeitungsaufgaben wie Transcodierung und Echtzeit-Videostreaming zu beschleunigen, leistung zu optimieren und Verarbeitungszeiten zu reduzieren.
Signalverarbeitung: NP-Familien-VMs eignen sich ideal für Anwendungen in der Telekommunikations- und Signalverarbeitung, bei denen schnelle Manipulation und Analyse von Signalen erforderlich sind.
Datenbankbeschleunigung: VMs der NP-Familie können Datenbankvorgänge verbessern, insbesondere für benutzerdefinierte Suchvorgänge und umfangreiche Datenbankabfragen, indem sie diese Aufgaben in das FPGA entladen.
Azure High Performance Compute VMs sind für verschiedene HPC-Workloads optimiert, z. B. Rechenflüssigkeitsdynamik, Finite Elementanalyse, Frontend- und Back-End-EDA, Rendering, Molekulare Dynamik, computergestützte Geowissenschaften, Wettersimulation und Finanzrisikoanalyse.
Liste der für High Performance Computing optimierten VM-Größenfamilien:
Wenn Sie mehr über eine bestimmte Größenfamilie oder Serie erfahren möchten, wählen Sie die Registerkarte für diese Familie aus, und scrollen Sie, um ihre gewünschte Größenreihe zu finden.
Hinweis
Hc-Serie (Standard_HC44rs, Standard_HC44-16rs, Standard_HC44-32rs) wird am 31. Mai 2027 eingestellt. Nach diesem Datum wird die Zuweisung aller noch vorhandener VMs der HC-Serie aufgehoben, ihre Ausführung gestoppt und jegliche SLA oder Unterstützung eingestellt. Der Verkauf von Reservierten Instanzen (1 Jahr und 3 Jahre) für die HC-Serie wurde am 2. April 2026 eingestellt. Berücksichtigen Sie für neue Bereitstellungen HBv5-Serie für höhere Leistung und Preisleistung oder HX-Serie für HPC-Workloads mit hohem Arbeitsspeicher.
Die Unterfamilie "HB" der VM-Größenreihe ist eine der Azure high-performance computing (HPC) optimierten H-Familien-VM-Instanzen. Sie sind für rechenintensive Aufgaben wie Strömungsmechanik, Finite-Elemente-Analyse und umfangreiche wissenschaftliche Simulationen konzipiert. Die leistungsstarken AMD EPYC Prozessoren und der schnelle Arbeitsspeicher der VMs der HB-Serie bieten eine außergewöhnliche CPU- und Speicherbandbreite und eignen sich daher ideal für Anwendungen, die umfangreiche Rechenressourcen zur Durchführung umfangreicher Berechnungen und Datenverarbeitung benötigen. Diese Funktion eignet sich gut für Branchen wie Technik, wissenschaftliche Forschung und Datenanalyse. In diesen Bereichen ist schnelle und genaue Verarbeitung für Produktivität und neue Ideen unerlässlich.
Die vollständige Familienseite "HB" anzeigen
Computational Fluid Dynamics (CFD): HB-Familie VMs sind ideal geeignet für Simulationen in Bereichen wie Luft- und Raumfahrt, Automobildesign und Fertigung, bei denen dynamische Berechnungen intensiv sind.
Finite Element Analysis (FEA): HB-Familien-VMs eignen sich für technische Analysen, die physikalische Phänomene simulieren und eine intensive Rechenleistung erfordern, um komplexe Systeme und Materialien zu modellieren.
Wetterprognose: HB-Familien-VMs können die massiven Datasets und komplexe Simulationen verarbeiten, die für die hochauflösende Wettermodellierung und Prognose erforderlich sind.
Seismische Verarbeitung: In der Öl- und Gasindustrie können HB-Familien-VMs seismische Daten verarbeiten, um Unterbaustrukturen zuzuordnen und zu verstehen.
Wissenschaftliche Forschung: HB-Familien-VMs unterstützen eine breite Palette von wissenschaftlichen Forschungen, die umfangreiche mathematische Modellierung erfordern, einschließlich Physik- und Berechnungschemiesimulationen.
Genomik und Bioinformatik: HB-Familien-VMs werden auch in Life Sciences für genomische Analysen verwendet, wo große Datenmengen schnell verarbeitet werden müssen, um genetische Informationen zu decodieren.
Die "HC"-Familie der VM-Größenreihe gehört zu den hochleistungsfähigen (HPC) optimierten VM-Instanzen von Azure. Sie sind für rechenintensive Workloads konzipiert, die eine erhebliche CPU-Leistung erfordern, z. B. genomische Sequenzierung, technische Simulationen und Finanzmodellierung. Die leistungsstarken Intel Xeon Scalable Prozessoren und der schnelle Arbeitsspeicher der VMs der HC-Reihe bieten außergewöhnliche Rechenkapazitäten und eine hohe Speicherbandbreite. Damit sind sie ideal für Anwendungen geeignet, die eine hohe Rechenleistung benötigen, um komplexe Berechnungen und umfangreiche Datensätze effizient zu verarbeiten. Diese VMs wurden für Sektoren wie das Gesundheitswesen, das Finanzwesen und das Ingenieurwesen entwickelt, in denen schnelle Datenverarbeitung und Simulationsgenauigkeit für fortschrittliche Forschung und Entwicklung entscheidend sind.
Vollständige HC-Familienseite anzeigen
Genomische Sequenzierung: VMs der HC-Serie bieten die für die genomische Sequenzierung benötigte Rechenleistung, sodass Forscher große genetische Datasets schnell verarbeiten und analysieren können.
Technische Simulationen: Ideal für die Ausführung komplexer Simulationen in Bereichen wie Automobil, Luft- und Raumfahrt und Maschinenbau. Diese Simulationen umfassen häufig Finite-Elemente-Analysen (FEA) und Computational Fluid Dynamics (CFD).
Finanzmodellierung: Diese virtuellen Computer können die hohen Anforderungen von Finanzanwendungen verarbeiten, einschließlich Risikoanalyse und quantitativen Simulationen, die massive Rechenressourcen erfordern, um viele Berechnungen schnell auszuführen.
Wissenschaftliche Forschung: VMs der HC-Serie unterstützen ein breites Spektrum an wissenschaftlichen Computing-Anforderungen, insbesondere in Physik und Chemie, wo groß angelegte Berechnungen und Datenanalysen von entscheidender Bedeutung sind.
Wettervorhersage und Klimasimulation: Sie werden in der Meteorologie für hochauflösende Wettermodellierung und Klimasimulationen verwendet, die große Datasets verarbeiten und komplexe Simulationen durchführen müssen.
Hinweis
Der Verkauf von Reservierten Instanzen (1 Jahr und 3 Jahre) für die HC-Serie wurde am 2. April 2026 eingestellt. Die HC-Serie soll am 31. Mai 2027 auslaufen. Planen Sie die Kapazität entsprechend.
Die "HX"-Familie der VM-Größenreihe sind eine von Azure für High-Memory- und High-Performance-Computing (HPC) optimierte VM-Instanzen. Sie wurden für arbeitsspeicherintensive Workloads entwickelt, die sowohl große Mengen an Arbeitsspeicher als auch eine hohe CPU-Leistung erfordern, wie z. B. In-Memory-Datenbanken, Big Data Analytics und komplexe wissenschaftliche Simulationen. Der große Arbeitsspeicher und die leistungsstarken CPUs der VMs der HX-Reihe bieten die notwendigen Ressourcen, um große Datensätze effizient zu verarbeiten und eine schnelle Datenverarbeitung durchzuführen. Diese VMs sind für Branchen wie Finanzdienstleistungen, wissenschaftliche Forschung und Unternehmensressourcenplanung konzipiert, in denen die Verwaltung und Analyse großer Datenmengen in Echtzeit für den betrieblichen Erfolg und die Innovation entscheidend ist.
Vollständige HX-Familienseite anzeigen
In-Memory Datenbanken: HX-Serien-VMs eignen sich hervorragend zum Hosten von In-Memory-Datenbanken, die umfangreiche Arbeitsspeicher erfordern, um große Datasets im RAM für ultraschnelle Verarbeitung und Zugriff zu verwalten.
Big Data Analytics: Sie können Big Data Analytics-Anwendungen verarbeiten, die große Datenmengen im Arbeitsspeicher verarbeiten müssen, um die Analyse zu beschleunigen, was für die Entscheidungsfindung in Echtzeit von entscheidender Bedeutung ist.
Genomische Forschung: Genomforschung umfasst häufig umfangreiche Datenanalysen, bei denen hohe Arbeitsspeicherkapazität die Leistung erheblich verbessern kann, indem mehr Datasets im Arbeitsspeicher gehalten werden können, wodurch die Analyse beschleunigt wird.
Finanzsimulationen: Finanzinstitute verwenden HX-Serien-VMs für Hochfrequenz-Handelsplattformen und Risikomanagementsimulationen, die eine schnelle Verarbeitung großer Datenmengen erfordern, um Aktientrends vorherzusagen oder Kreditrisiken in Echtzeit zu berechnen.
ERP-Systeme: Große Erp-Systeme (Enterprise Resource Planning) profitieren von der hohen Speicher- und Verarbeitungsleistung von VMs der HX-Serie, um umfangreiche Unternehmensdaten zu verwalten und zu verarbeiten und eine große Anzahl gleichzeitiger Benutzer effektiv zu unterstützen.
Auflisten der verfügbaren Computergrößen nach Region.
Die Azure CLI können verwendet werden, um zu ermitteln, welche Maschinengrößen für eine bestimmte Region mit dem Befehl verfügbar sind:
az vm list-skus --location <region> --output table
Artikel mit Informationen zu Plattformgrößen
REST-API
Informationen zur Verwendung der REST-API, um VM-Größen abzufragen, finden Sie nachstehend:
Benchmarkergebnisse
Erfahren Sie mehr über die Computeleistung für Linux-VMs mit den CoreMark-Benchmarkbewertungen.
Erfahren Sie mehr über die Computeleistung für Windows VMs mithilfe der SPECInt-Benchmarkergebnisse.
Liste aller verfügbaren Größen: Größen
Preisrechner: Preisrechner
Informationen zu Datenträgertypen: Datenträgertypen
Nächste Schritte
Für Ihre Workloads nutzen Sie die neuesten verfügbaren Leistungen und Features, indem Sie die Größe einer virtuellen Maschine ändern.
Nutzen Sie die internen ARM-Prozessoren von Microsoft mit Azure Kobalt-VMs.
Erfahren Sie, wie Sie Azure-virtuelle Computer überwachen.