Azure Virtual Desktop is a comprehensive desktop and app virtualization service running on Microsoft Azure. Virtual Desktop helps enable a secure remote desktop experience that helps organizations strengthen business resilience. It delivers simplified management, Windows 10 and 11 Enterprise multi-session, and optimizations for Microsoft 365 Apps for enterprise. With Virtual Desktop, you can deploy and scale your Windows desktops and apps on Azure in minutes, providing integrated security and compliance features to help keep your apps and data secure.
As you continue to enable remote work for your organization with Virtual Desktop, it's important to understand its disaster recovery (DR) capabilities and best practices. These practices strengthen reliability across regions to help keep data safe and employees productive. This article provides you with considerations on business continuity and disaster recovery (BCDR) prerequisites, deployment steps, and best practices. You learn about options, strategies, and architecture guidance. The content in this document enables you to prepare a successful BCDR plan and can help you bring more resilience to your business during planned and unplanned downtime events.
There are several types of disasters and outages, and each can have a different impact. Resiliency and recovery are discussed in depth for both local and region-wide events, including recovery of the service in a different remote Azure region. This type of recovery is called geo disaster recovery. It's critical to build your Virtual Desktop architecture for resiliency and availability. You should provide maximum local resiliency to reduce the impact of failure events. This resiliency also reduces the requirements to execute recovery procedures. This article also provides information about high availability and best practices.
Goals and scope
The goals of this guide are to:
- Ensure maximum availability, resiliency, and geo-disaster recovery capability while minimizing data loss for important selected user data.
- Minimize recovery time.
These objectives are also known as the recovery point objective (RPO) and the Recovery Time Objective (RTO).
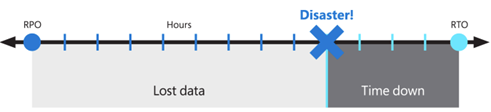
The proposed solution provides local high-availability, protection from a single availability zone failure, and protection from an entire Azure region failure. It relies on a redundant deployment in a different, or secondary, Azure region to recover the service. While it's still a good practice, Virtual Desktop and the technology used to build BCDR don't require Azure regions to be paired. Primary and secondary locations can be any Azure region combination, if the network latency permits it. Operating AVD host pools in multiple geographic regions can offer more benefits not limited to BCDR.
To reduce the impact of a single availability zone failure, use resiliency to improve high availability:
- At the compute layer, spread the Virtual Desktop session hosts across different availability zones.
- At the storage layer, use zone resiliency whenever possible.
- At the networking layer, deploy zone-resilient Azure ExpressRoute and virtual private network (VPN) gateways.
- For each dependency, review the impact of a single zone outage and plan mitigations. For example, deploy Active Directory Domain Controllers and other external resources accessed by Virtual Desktop users across multiple availability zones.
Depending on the number of availability zones you use, evaluate over-provisioning the number of session hosts to compensate for the loss of one zone. For example, even with (n-1) zones available, you can ensure user experience and performance.
Note
Azure availability zones are a high-availability feature that can improve resiliency. However, do not consider them a disaster recovery solution able to protect from region-wide disasters.

Because of the possible combinations of types, replication options, service capabilities, and availability restrictions in some regions, the Cloud Cache component from FSLogix is recommended to be used instead of storage-specific replication mechanisms.
OneDrive isn't covered in this article. For more information on redundancy and high-availability, see SharePoint and OneDrive data resiliency in Microsoft 365.
For the remainder of this article, you're going to learn about solutions for the two different Virtual Desktop host pool types. There are also observations provided so that you can compare this architecture with other solutions:
- Personal: In this type of host pool, a user has a permanently assigned session host, which should never change. Since it's personal, this VM can store user data. The assumption is to use replication and backup techniques to preserve and protect the state.
- Pooled: Users are temporarily assigned one of the available session host VMs from the pool, either directly through a desktop application group or by using remote apps. VMs are stateless and user data and profiles are stored in external storage or OneDrive.
Cost implications are discussed, but the primary goal is providing an effective geo disaster recovery deployment with minimal data loss. For more BCDR details, see the following resources:
Prerequisites
Deploy the core infrastructure and make sure it's available in the primary and the secondary Azure region. For guidance on your network topology, you can use the Azure Cloud Adoption Framework Network topology and connectivity models:
In both models, deploy the primary Virtual Desktop host pool and the secondary disaster recovery environment inside different spoke virtual networks and connect them to each hub in the same region. Place one hub in the primary location, one hub in the secondary location, and then establish connectivity between the two.
The hub eventually provides hybrid connectivity to on-premises resources, firewall services, identity resources like Active Directory Domain Controllers, and management resources like Log Analytics.
You should consider any line-of-business applications and dependent resource availability when failed over to the secondary location.
Control plane business continuity and disaster recovery
Virtual Desktop offers business continuity and disaster recovery for its control plane to preserve customer metadata during outages. The Azure platform manages this data and process, and users don't need to configure or execute anything.

Virtual Desktop is designed to be resilient to failures of individual components, and to be able to recover from failures quickly. When an outage occurs in a region, the service infrastructure components fail over to the secondary location and continue functioning as normal. You can still access service-related metadata, and users can still connect to available hosts. End-user connections stay online if the tenant environment or hosts remain accessible. Data locations for Virtual Desktop are different from the location of the host pool session host virtual machines (VMs) deployment. It's possible to locate Virtual Desktop metadata in one of the supported regions, and then deploy VMs in a different location. More details are provided in the Virtual Desktop service architecture and resilience article.
Active-Active vs. Active-Passive
If distinct sets of users have different BCDR requirements, Microsoft recommends that you use multiple host pools with different configurations. For example, users with a mission critical application might assign a fully redundant host pool with geo disaster recovery capabilities. However, development and test users can use a separate host pool with no disaster recovery at all.
For each single Virtual Desktop host pool, you can base your BCDR strategy on an active-active or active-passive model. This scenario assumes that the same set of users in one geographic location is served by a specific host pool.
- Active-Active
For each host pool in the primary region, you deploy a second host pool in the secondary region.
This configuration provides almost zero RTO, and RPO has an extra cost.
You don't require an administrator to intervene or fail over. During normal operations, the secondary host pool provides the user with Virtual Desktop resources.
Each host pool has its own storage accounts (at least one) for persistent user profiles.
You should evaluate latency based on the user's physical location and connectivity available. For some Azure regions, such as Western Europe and Northern Europe, the difference can be negligible when accessing either the primary or secondary regions. You can validate this scenario using the Azure Virtual Desktop Experience Estimator tool.
Users are assigned to different application groups, like Desktop Application Group (DAG) and RemoteApp Application Group (RAG), in both the primary and secondary host pools. In this case, they see duplicate entries in their Virtual Desktop client feed. To avoid confusion, use separate Virtual Desktop workspaces with clear names and labels that reflect the purpose of each resource. Inform your users about the usage of these resources.
If you need storage to manage FSLogix Profile and ODFC containers separately, use Cloud Cache to ensure almost zero RPO.
- To avoid profile conflicts, don't permit users to access both host pools at the same time.
- Due to the active-active nature of this scenario, you should educate your users on how to use these resources in the proper way.
Note
Using separate ODFC containers is an advanced scenario with higher complexity. Deploying this way is recommended only in some specific scenarios.
- Active-Passive
- Like active-active, for each host pool in the primary region, you deploy a second host pool in the secondary region.
- The amount of compute resources active in the secondary region is reduced compared to the primary region, depending on the budget available. You can use automatic scaling to provide more compute capacity, but it requires more time, and Azure capacity isn't guaranteed.
- This configuration provides higher RTO when compared to the active-active approach, but it's less expensive.
- You need administrator intervention to execute a failover procedure if there's an Azure outage. The secondary host pool doesn't normally provide the user access to Virtual Desktop resources.
- Each host pool has its own storage accounts for persistent user profiles.
- Users that consume Virtual Desktop services with optimal latency and performance are affected only if there's an Azure outage. You should validate this scenario by using the Azure Virtual Desktop Experience Estimator tool. Performance should be acceptable, even if degraded, for the secondary disaster recovery environment.
- Users are assigned to only one set of application groups, like Desktop and Remote Apps. During normal operations, these apps are in the primary host pool. During an outage, and after a failover, users are assigned to Application Groups in the secondary host pool. No duplicate entries are shown in the user's Virtual Desktop client feed, they can use the same workspace, and everything is transparent for them.
- If you need storage to manage FSLogix Profile and Office containers, use Cloud Cache to ensure almost zero RPO.
- To avoid profile conflicts, don't permit users to access both host pools at the same time. Since this scenario is active-passive, administrators can enforce this behavior at the application group level. Only after a failover procedure is the user able to access each application group in the secondary host pool. Access is revoked in the primary host pool application group and reassigned to an application group in the secondary host pool.
- Execute a failover for all application groups, otherwise users using different application groups in different host pools might cause profile conflicts if not effectively managed.
- It's possible to allow a specific subset of users to selectively fail over to the secondary host pool and provide limited active-active behavior and test failover capability. It's also possible to fail over specific application groups, but you should educate your users to not use resources from different host pools at the same time.
For specific circumstances, you can create a single host pool with a mix of session hosts located in different regions. The advantage of this solution is that if you have a single host pool, then there's no need to duplicate definitions and assignments for desktop and remote apps. Unfortunately, disaster recovery for shared host pools has several disadvantages:
- For pooled host pools, it isn't possible to force a user to a session host in the same region.
- A user might experience higher latency and suboptimal performance when connecting to a session host in a remote region.
- If you require storage for user profiles, you need a complex configuration to manage assignments for session hosts in the primary and secondary regions.
- You can use drain mode to temporarily disable access to session hosts located in the secondary region. But this method introduces more complexity, management overhead, and inefficient use of resources.
- You can maintain session hosts in an offline state in the secondary regions, but it introduces more complexity and management overhead.
Considerations and recommendations
General
In order to deploy either an active-active or active-passive configuration using multiple host pools and an FSLogix cloud cache mechanism, you can create the host pool inside the same workspace or a different one, depending on the model. This approach requires you to maintain the alignment and updates, keeping both host pools in sync and at the same configuration level. In addition to a new host pool for the secondary disaster recovery region, you need:
- To create new distinct application groups and related applications for the new host pool.
- To revoke user assignments to the primary host pool, and then manually reassign them to the new host pool during the failover.
Review the Business continuity and disaster recovery options for FSLogix.
- No profile recovery isn't covered in this document.
- Cloud cache (active/passive) is included in this document but is implemented it using the same host pool.
- Cloud cache (active/active) is covered in the remaining part of this document.
There are limits for Virtual Desktop resources that must be considered in the design of a Virtual Desktop architecture. Validate your design based on the Virtual Desktop service limits.
For diagnostics and monitoring, it's good practice to use the same Log Analytics workspace for both the primary and secondary host pool. Using this configuration, Azure Virtual Desktop Insights offers a unified view of deployment in both regions.
However, using a single log destination can cause problems if the entire primary region is unavailable. The secondary region won't be able to use the Log Analytics workspace in the unavailable region. If this situation is unacceptable, the following solutions could be adopted:
- Use a separate Log Analytics workspace for each region, and then point the Virtual Desktop components to log toward its local workspace.
- Test and review Logs Analytics workspace replication and failover capabilities.
Compute
For the deployment of both host pools in the primary and secondary disaster recovery regions, you should spread your session host VM fleet across multiple availability zones. If availability zones aren't available in the local region, you can use an availability set to make your solution more resilient than with a default deployment.
The golden image that you use for host pool deployment in the secondary disaster recovery region should be the same you use for the primary. You should store images in the Azure Compute Gallery and configure multiple image replicas in both the primary and the secondary locations. Each image replica can sustain a parallel deployment of a maximum number of VMs, and you might require more than one based on your desired deployment batch size. For more information, see Store and share images in an Azure Compute Gallery.
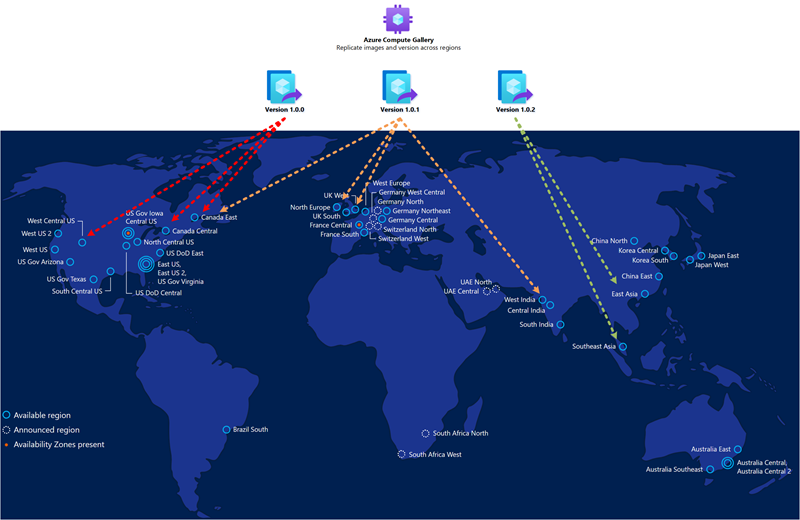
The Azure Compute Gallery isn't a global resource. It's recommended to have at least a secondary gallery in the secondary region. In your primary region, create a gallery, a VM image definition and a VM image version. Then, create the same objects also in the secondary region. When creating the VM image version, there's the possibility to copy the VM image version created in the primary region by specifying the gallery, VM image definition and VM image version used in the primary region. Azure copies the image and creates a local VM image version. It's possible to execute this operation using the Azure portal or Azure CLI command as outlined below:
Not all the session host VMs in the secondary disaster recovery locations must be active and running all the time. You must initially create a sufficient number of VMs, and after that, use an autoscale mechanism like scaling plans. With these mechanisms, it's possible to maintain most compute resources in an offline or deallocated state to reduce costs.
It's also possible to use automation to create session hosts in the secondary region only when needed. This method optimizes costs, but depending on the mechanism you use, might require a longer RTO. This approach doesn't permit failover tests without a new deployment and doesn't permit selective failover for specific groups of users.

Note
You must power on each session host VM for a few hours at least one time every 90 days to refresh the authentication token needed to connect to the Virtual Desktop control plane. You should also routinely apply security patches and application updates.
- Having session hosts in an offline, or deallocated, state in the secondary region doesn't guarantee that capacity is available in case of a primary region-wide disaster. It also applies if new session hosts are deployed on-demand when needed, and with Site Recovery usage. Compute capacity can be guaranteed only if the related resources are already allocated and active.
Important
Azure Reservations doesn't provide guaranteed capacity in the region.
For Cloud Cache usage scenarios, we recommend using the premium tier for managed disks.
Storage
In this guide, you use at least two separate storage accounts for each Virtual Desktop host pool. One is for the FSLogix Profile container, and one is for the Office container data. You also need one more storage account for MSIX packages. The following considerations apply:
- You can use Azure Files share and Azure NetApp Files as storage alternatives. To compare the options, see the FSLogix container storage options.
- Azure Files share can provide zone resiliency by using the zone-replicated storage (ZRS) resiliency option, if it's available in the region.
- You can't use the geo-redundant storage feature in the following situations:
- You require a region that doesn't have a pair. The region pairs for geo-redundant storage are fixed and can't be changed.
- You're using the premium tier.
- RPO and RTO are higher compared to FSLogix Cloud Cache mechanism.
- It isn't easy to test failover and failback in a production environment.
- Azure NetApp Files requires more considerations:
- Zone redundancy isn't yet available. If the resiliency requirement is more important than performance, use Azure Files share.
- Azure NetApp Files can be zonal, that is customers can decide in which (single) Azure Availability Zone to allocate.
- Cross-zone replication can be established at the volume level to provide zone resiliency but replication happens asynchronous and requires manual failover. This process requires a recovery point objective (RPO) and recovery time objective (RTO) that are greater than zero. Before using this feature, review the requirements and considerations for cross-zone replication.
- You can use Azure NetApp Files with zone-redundant VPN and ExpressRoute gateways, if standard networking feature is used, which you might use for networking resiliency. For more information, see Supported network topologies.
- Azure Virtual WAN is supported when used together with Azure NetApp Files standard networking. For more information, see Supported network topologies.
- Azure NetApp Files has a cross-region replication mechanism. The following considerations apply:
- It's not available in all regions.
- Cross-region replication of Azure NetApp Files volumes region pairs can be different than Azure storage region pairs.
- It can't be used at the same time with cross-zone replication
- Failover isn't transparent, and failback requires storage reconfiguration.
- Limits
- There are limits in the size, input/output operations per second (IOPS), bandwidth MBps for both Azure Files share and Azure NetApp Files storage accounts and volumes. If necessary, it's possible to use more than one for the same host pool in Virtual Desktop by using per-group settings in FSLogix. However, this configuration requires more planning and configuration.
The storage account you use for MSIX application packages should be distinct from the other accounts for Profile and Office containers. The following Geo-disaster recovery options are available:
- One storage account with geo-redundant storage enabled, in the primary region
- The secondary region is fixed. This option isn't suitable for local access if there's storage account failover.
- Two separate storage accounts, one in the primary region and one in the secondary region (recommended)
- Use zone-redundant storage for at least the primary region.
- Each host pool in each region has local storage access to MSIX packages with low latency.
- Copy MSIX packages twice in both locations and register the packages twice in both host pools. Assign users to the application groups twice.
FSLogix
Microsoft recommends that you use the following FSLogix configuration and features:
If the Profile container content needs to have separate BCDR management, and has different requirements compared to the Office container, you should split them.
- Office Container only has cached content that can be rebuilt or repopulated from the source if there's a disaster. With Office Container, you might not need to keep backups, which can reduce costs.
- When using different storage accounts, you can only enable backups on the profile container. Or, you must have different settings like retention period, storage used, frequency, and RTO/RPO.
Cloud Cache is an FSLogix component in which you can specify multiple profile storage locations and asynchronously replicate profile data, all without relying on any underlying storage replication mechanisms. If the first storage location fails or isn't reachable, Cloud Cache automatically fails over to use the secondary, and effectively adds a resiliency layer. Use Cloud Cache to replicate both Profile and Office containers between different storage accounts in the primary and secondary regions.
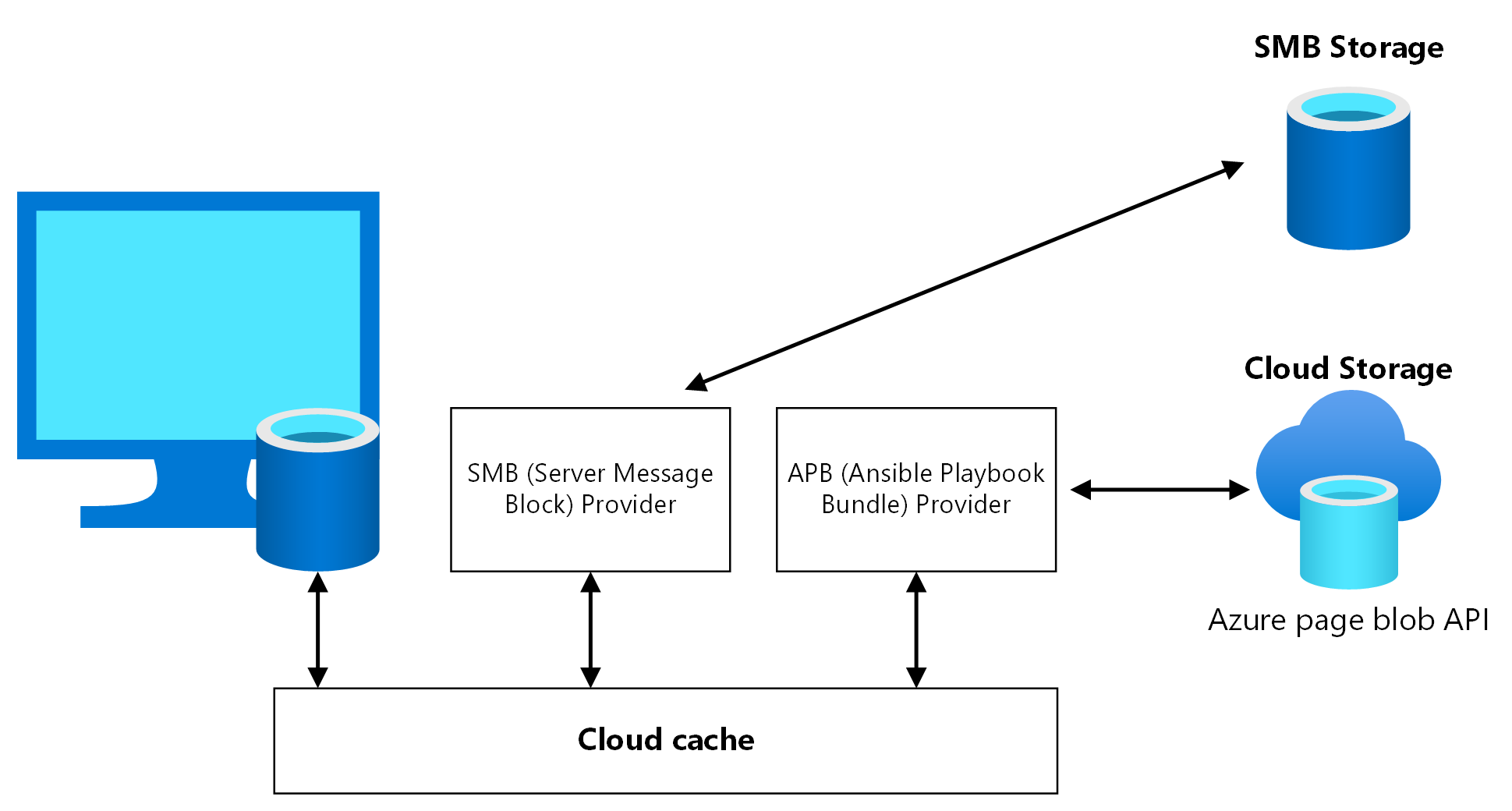
You must enable Cloud Cache twice in the session host VM registry, once for Profile Container and once for Office Container. It's possible to not enable Cloud Cache for Office Container, but not enabling it might cause a data misalignment between the primary and the secondary disaster recovery region if there's failover and failback. Test this scenario carefully before using it in production.
Cloud Cache is compatible with both profile split and per-group settings. per-group requires careful design and planning of active directory groups and membership. You must ensure that every user is part of exactly one group, and that group is used to grant access to host pools.
The CCDLocations parameter specified in the registry for the host pool in the secondary disaster recovery region is reverted in order, compared to the settings in the primary region. For more information, see Tutorial: Configure Cloud Cache to redirect profile containers or office container to multiple Providers.
Tip
This article focuses on a specific scenario. Additional scenarios are described in High availability options for FSLogix and Business continuity and disaster recovery options for FSLogix.

The following example shows a Cloud Cache configuration and related registry keys:
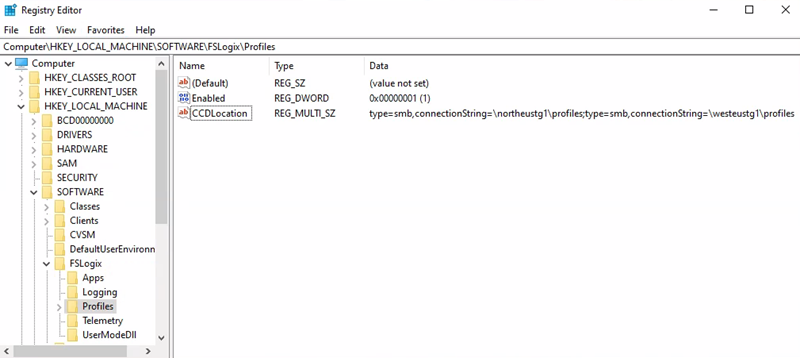
Primary Region = North Europe
Profile container storage account URI = \northeustg1\profiles
- Registry Key path = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix > Profiles
- CCDLocations value = type=smb,connectionString=\northeustg1\profiles;type=smb,connectionString=\westeustg1\profiles
Note
If you previously downloaded the FSLogix Templates, you can accomplish the same configurations through the Active Directory Group Policy Management Console. For more details on how to set up the Group Policy Object for FSLogix, refer to the guide, Use FSLogix Group Policy Template Files.
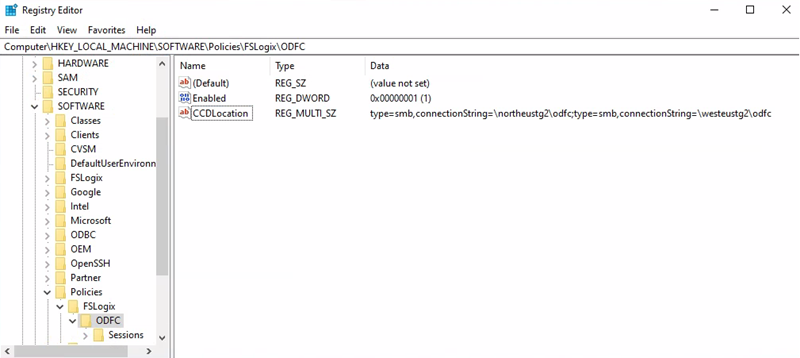
Office container storage account URI = \northeustg2\odcf
Registry Key path = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
CCDLocations value = type=smb,connectionString=\northeustg2\odfc;type=smb,connectionString=\westeustg2\odfc


Note
In the screenshots above, not all the recommended registry keys for FSLogix and Cloud Cache are reported, for brevity and simplicity. For more information, see FSLogix configuration examples.
Secondary Region = West Europe
- Profile container storage account URI = \westeustg1\profiles
- Registry Key path = HKEY_LOCAL_MACHINE > SOFTWARE > FSLogix > Profiles
- CCDLocations value = type=smb,connectionString=\westeustg1\profiles;type=smb,connectionString=\northeustg1\profiles
- Office container storage account URI = \westeustg2\odcf
- Registry Key path = HKEY_LOCAL_MACHINE > SOFTWARE >Policy > FSLogix > ODFC
- CCDLocations value = type=smb,connectionString=\westeustg2\odfc;type=smb,connectionString=\northeustg2\odfc
Cloud Cache replication
The Cloud Cache configuration and replication mechanisms guarantee profile data replication between different regions with minimal data loss. Since the same user profile file can be opened in ReadWrite mode by only one process, concurrent access should be avoided, thus users shouldn't open a connection to both host pools at the same time.

Download a Visio file of this architecture.
Dataflow
A Virtual Desktop user launches Virtual Desktop client, and then opens a published Desktop or Remote App application assigned to the primary region host pool.
FSLogix retrieves the user Profile and Office containers, and then mounts the underlying storage VHD/X from the storage account located in the primary region.
At the same time, the Cloud Cache component initializes replication between the files in the primary region and the files in the secondary region. For this process, Cloud Cache in the primary region acquires an exclusive read-write lock on these files.
The same Virtual Desktop user now wants to launch another published application assigned on the secondary region host pool.
The FSLogix component running on the Virtual Desktop session host in the secondary region tries to mount the user profile VHD/X files from the local storage account. But the mounting fails since these files are locked by the Cloud Cache component running on the Virtual Desktop session host in the primary region.
In the default FSLogix and Cloud Cache configuration, the user can't sign in and an error is tracked in the FSLogix diagnostic logs, ERROR_LOCK_VIOLATION 33 (0x21).


Identity
One of the most important dependencies for Virtual Desktop is the availability of user identity. To access full remote virtual desktops and remote apps from your session hosts, your users need to be able to authenticate. Microsoft Entra ID is Microsoft's centralized cloud identity service that enables this capability. Microsoft Entra ID is always used to authenticate users for Virtual Desktop. Session hosts can be joined to the same Microsoft Entra tenant, or to an Active Directory domain using Active Directory Domain Services or Microsoft Entra Domain Services, providing you with a choice of flexible configuration options.
Microsoft Entra ID
- It's a global multi-region and resilient service with high-availability. No other action is required in this context as part of a Virtual Desktop BCDR plan.
Active Directory Domain Services
- For Active Directory Domain Services to be resilient and highly available, even if there's a region-wide disaster, you should deploy at least two domain controllers (DCs) in the primary Azure region. These domain controllers should be in different availability zones if possible, and you should ensure proper replication with the infrastructure in the secondary region and eventually on-premises. You should create at least one more domain controller in the secondary region with global catalog and DNS roles. For more information, see Deploy AD DS in an Azure virtual network.
Microsoft Entra Connect
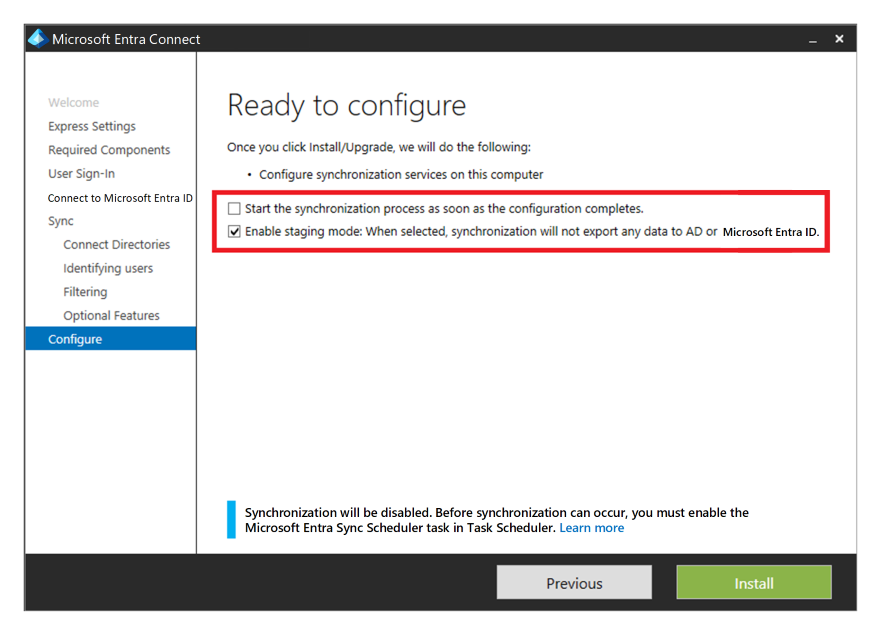
If you're using Microsoft Entra ID with Active Directory Domain Services, and then Microsoft Entra Connect to synchronize user identity data between Active Directory Domain Services and Microsoft Entra ID, you should consider the resiliency and recovery of this service for protection from a permanent disaster.
You can provide high availability and disaster recovery by installing a second instance of the service in the secondary region and enable staging mode.
If there's a recovery, the administrator is required to promote the secondary instance by taking it out of staging mode. They must follow the same procedure as placing a server into staging mode. Microsoft Entra Global Administrator credentials are required to perform this configuration.
Microsoft Entra Domain Services
- You can use Microsoft Entra Domain Services in some scenarios as an alternative to Active Directory Domain Services.
- It offers high-availability.
- If geo-disaster recovery is in scope for your scenario, you should deploy another replica in the secondary Azure region by using a replica set. You can also use this feature to increase high availability in the primary region.
Architecture diagrams
Personal host pool

Download a Visio file of this architecture.
Pooled host pool

Download a Visio file of this architecture.
Failover and failback
Personal host pool scenario
Note
Only the active-passive model is covered in this section—an active-active doesn't require any failover or administrator intervention.
Failover and failback for a personal host pool is different, as there's no Cloud Cache and external storage used for Profile and Office containers. You can still use FSLogix technology to save the data in a container from the session host. There's no secondary host pool in the disaster recovery region, so there's no need to create more workspaces and Virtual Desktop resources to replicate and align. You can use Site Recovery to replicate session host VMs.
You can use Site Recovery in several different scenarios. For Virtual Desktop, use the Azure to Azure disaster recovery architecture in Azure Site Recovery.
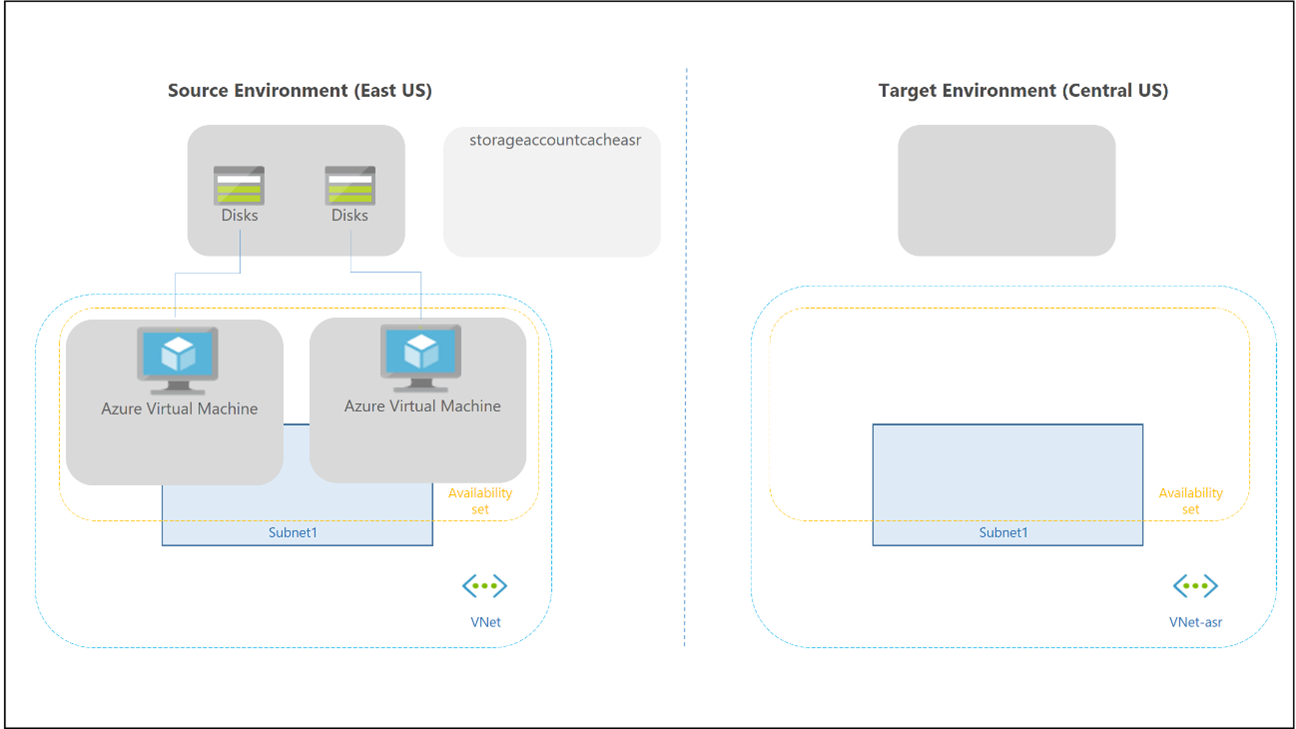
The following considerations and recommendations apply:
- Site Recovery failover isn't automatic—an administrator must trigger it by using the Azure portal or Powershell/API.
- You can script and automate the entire Site Recovery configuration and operations by using PowerShell.
- Site Recovery has a declared RTO inside its service-level agreement (SLA). Most of the time, Site Recovery can fail over VMs within minutes.
- You can use Site Recovery with Azure Backup. For more information, see Support for using Site Recovery with Azure Backup.
- You must enable Site Recovery at the VM level, as there's no direct integration in the Virtual Desktop portal experience. You must also trigger failover and failback at the single VM level.
- Site Recovery provides test failover capability in a separate subnet for general Azure VMs. Don't use this feature for Virtual Desktop VMs, since you would have two identical Virtual Desktop session hosts calling the service control plane at the same time.
- Site Recovery doesn't maintain Virtual Machine extensions during replication. If you enable any custom extensions for Virtual Desktop session host VMs, you must re-enable the extensions after failover or failback. The Virtual Desktop built-in extensions joindomain and Microsoft.PowerShell.DSC are only used when a session host VM is created. It's safe to lose them after a first failover.
- Be sure to review Support matrix for Azure VM disaster recovery between Azure regions and check requirements, limitations, and the compatibility matrix for the Site Recovery Azure-to-Azure disaster recovery scenario, especially the supported OS versions.
- When you fail over a VM from one region to another, the VM starts up in the target disaster recovery region in an unprotected state. Failback is possible, but the user must reprotect VMs in the secondary region, and then enable replication back to the primary region.
- Execute periodic testing of failover and failback procedures. Then document an exact list of steps and recovery actions based on your specific Virtual Desktop environment.
Pooled host pool scenario
One of the desired characteristics of an active-active disaster recovery model is that administrator intervention isn't required to recover the service if there's an outage. Failover procedures should only be necessary in an active-passive architecture.
In an active-passive model, the secondary disaster recovery region should be idle, with minimal resources configured, and active. Configuration should be kept aligned with the primary region. If there's a failover, reassignments for all users to all desktop and application groups for remote apps in the secondary disaster recovery host pool happen at the same time.
It's possible to have an active-active model and partial failover. If the host pool is only used to provide desktop and application groups, then you can partition the users in multiple nonoverlapping Active Directory groups and reassign the group to desktop and application groups in the primary or secondary disaster recovery host pools. A user shouldn't have access to both host pools at the same time. If there's multiple application groups and applications, the user groups you use to assign users might overlap. In this case, it's difficult to implement an active-active strategy. Whenever a user starts a remote app in the primary host pool, the user profile is loaded by FSLogix on a session host VM. Trying to do the same on the secondary host pool might cause a conflict on the underlying profile disk.
Warning
By default, FSLogix registry settings prohibit concurrent access to the same user profile from multiple sessions. In this BCDR scenario, you shouldn't change this behavior and leave a value of 0 for registry key ProfileType.
Here's the initial situation and configuration assumptions:
- The host pools in the primary region and secondary disaster recovery regions are aligned during configuration, including Cloud Cache.
- In the host pools, both DAG1 desktop and APPG2 and APPG3 remote app application groups are offered to users.
- In the host pool in the primary region, Active Directory user groups GRP1, GRP2, and GRP3 are used to assign users to DAG1, APPG2, and APPG3. These groups might have overlapping user memberships, but since the model here uses active-passive with full failover, it's not a problem.
The following steps describe when a failover happens, after either a planned or unplanned disaster recovery.
- In the primary host pool, remove user assignments by the groups GRP1, GRP2, and GRP3 for application groups DAG1, APPG2, and APPG3.
- There's a forced disconnection for all connected users from the primary host pool.
- In the secondary host pool, where the same application groups are configured, you must grant user access to DAG1, APPG2, and APPG3 using groups GRP1, GRP2, and GRP3.
- Review and adjust the capacity of the host pool in the secondary region. Here, you might want to rely on an autoscale plan to automatically power on session hosts. You can also manually start the necessary resources.
The Failback steps and flow are similar, and you can execute the entire process multiple times. Cloud Cache and configuring the storage accounts ensures that Profile and Office container data is replicated. Before failback, ensure that the host pool configuration and compute resources are recovered. For the storage part, if there's data loss in the primary region, Cloud Cache replicates Profile and Office container data from the secondary region storage.
It's also possible to implement a test failover plan with a few configuration changes, without affecting the production environment.
- Create a few new user accounts in Active Directory for production.
- Create a new Active Directory group named GRP-TEST and assign users.
- Assign access to DAG1, APPG2, and APPG3 by using the GRP-TEST group.
- Give instructions to users in the GRP-TEST group to test applications.
- Test the failover procedure by using the GRP-TEST group to remove access from the primary host pool and grant access to the secondary disaster recovery pool.
Important recommendations:
- Automate the failover process by using PowerShell, Azure CLI, or another available API or tool.
- Periodically test the entire failover and failback procedure.
- Conduct a regular configuration alignment check to ensure host pools in the primary and secondary disaster region are in sync.
Backup
An assumption in this guide is that there's profile split and data separation between Profile containers and Office containers. FSLogix permits this configuration and the usage of separate storage accounts. Once in separate storage accounts, you can use different backup policies.
For ODFC Container, if the content represents only cached data that can be rebuilt from on-line data store like Office 365, it isn't necessary to back up data.
If it's necessary to back up Office container data, you can use a less expensive storage or a different backup frequency and retention period.
For a personal host pool type, you should execute the backup at the session host VM level. This method only applies if the data is stored locally.
If you use OneDrive and known folder redirection, the requirement to save data inside the container might disappear.
Note
OneDrive backup is not considered in this article and scenario.
Unless there's another requirement, backup for the storage in the primary region should be enough. Backup of the disaster recovery environment isn't normally used.
For Azure Files share, use Azure Backup.
- For the vault resiliency type, use zone-redundant storage if off-site or region backup storage isn't required. If those backups are required, use geo-redundant storage.
Azure NetApp Files provides its own built-in backup solution.
- Make sure you check the region feature availability, along with requirements and limitations.
The separate storage accounts used for MSIX should also be covered by a backup if the application packages repositories can't be easily rebuilt.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal authors:
- Ben Martin Baur | Cloud Solution Architect
- Igor Pagliai | FastTrack for Azure (FTA) Principal Engineer
Other contributors:
- Nelson Del Villar | Cloud Solution Architect, Azure Core Infrastructure
- Jason Martinez | Technical Writer
Next steps
- Virtual Desktop disaster recovery plan
- BCDR for Virtual Desktop - Cloud Adoption Framework
- Cloud Cache to create resiliency and availability