Availability zones are physically separate groups of datacenters within each Azure region. When one zone fails, services can fail over to one of the remaining zones.
Fabric makes commercially reasonable efforts to support zone-redundant availability zones, where resources automatically replicate across zones, without any need for you to set up or configure.
Prerequisites
Fabric currently provides partial availability-zone support in a limited number of regions. This partial availability-zone support covers experiences (and/or certain functionalities within an experience).
Experiences such as Event Streams don't support availability zones.
Data engineering supports availability zones if you use OneLake. If you use other data sources such as ADLS Gen2, then you need to ensure that Zone-redundant storage (ZRS) is enabled.
Zone availability may or may not be available for Fabric experiences and/or features/functionalities that are in preview.
On-premises gateways and large semantic models in Power BI don't support availability zones.
Data Factory (pipelines) support availability zones in West Europe, but new or inprogress pipelines runs may fail in case of zone outage.
Supported regions
Fabric makes commercially reasonable efforts to provide availability zone support in various regions as follows:
Americas
Power BI
Datamarts
Data Warehouses
Real-Time Analytics
Data Factory (pipelines)
Data Engineering
SQL Database
Brazil South
Canada Central
Central US
East US
East US 2
South Central US
West US 2
West US 3
Europe
Power BI
Datamarts
Data Warehouses
Real-Time Analytics
Data Factory (pipelines)
Data Engineering
SQL Database
France Central
Germany West Central
Italy North
North Europe
Norway East
Poland Central
UK South
West Europe
Sweden Central
Middle East
Power BI
Datamarts
Data Warehouses
Real-Time Analytics
Data Factory (pipelines)
Data Engineering
SQL Database
Qatar Central
Israel Central
Africa
Power BI
Datamarts
Data Warehouses
Real-Time Analytics
Data Factory (pipelines)
Data Engineering
SQL Database
South Africa North
Asia Pacific
Power BI
Datamarts
Data Warehouses
Real-Time Analytics
Data Factory (pipelines)
Data Engineering
SQL Database
Australia East
Japan East
Southeast Asia
Zone down experience
During a zone-wide outage, no action is required during zone recovery. Fabric capabilities in regions listed in supported regions self-heal and rebalance automatically to take advantage of the healthy zone. Running Spark Jobs may fail if the master node is in the failed zone. In such a case, the jobs will need to be resubmitted.
Tärkeä
While Microsoft strives to provide uniform and consistent availability zone support, in some cases of availability-zone failure, Fabric capacities located in Azure regions with higher customer demand fluctuations might experience higher than normal latency.
Cross-region disaster recovery and business continuity
Disaster recovery (DR) refers to practices that organizations use to recover from high-impact events, such as natural disasters or failed deployments that result in downtime and data loss. Regardless of the cause, the best remedy for a disaster is a well-defined and tested DR plan and an application design that actively supports DR. Before you start creating your disaster recovery plan, see Recommendations for designing a disaster recovery strategy.
For DR, Microsoft uses the shared responsibility model. In this model, Microsoft ensures that the baseline infrastructure and platform services are available. However, many Azure services don't automatically replicate data or fall back from a failed region to cross-replicate to another enabled region. For those services, you're responsible for setting up a disaster recovery plan that works for your workload. Most services that run on Azure platform as a service (PaaS) offerings provide features and guidance to support DR. You can use service-specific features to support fast recovery to help develop your DR plan.
This section describes a disaster recovery plan for Fabric that's designed to help your organization keep its data safe and accessible when an unplanned regional disaster occurs. The plan covers the following topics:
Cross-region replication: Fabric offers cross-region replication for data stored in OneLake. You can opt in or out of this feature based on your requirements.
Data access after disaster: In a regional disaster scenario, Fabric guarantees data access, with certain limitations. While the creation or modification of new items is restricted after failover, the primary focus remains on ensuring that existing data remains accessible and intact.
Guidance for recovery: Fabric provides a structured set of instructions to guide you through the recovery process. The structured guidance makes it easier for you to transition back to regular operations.
Power BI, now a part of the Fabric, has a solid disaster recovery system in place and offers the following features:
BCDR as default: Power BI automatically includes disaster recovery capabilities in its default offering. You don't need to opt in or activate this feature separately.
Cross-region replication: Power BI uses Azure storage geo-redundant replication and Azure SQL geo-redundant replication to guarantee that backup instances exist in other regions and can be used. This means that data is duplicated across different regions, enhancing its availability, and reducing the risks associated with regional outages.
Continued services and access after disaster: Even during disruptive events, Power BI items remain accessible in read-only mode. Items include semantic models, reports, and dashboards, ensuring that businesses can continue their analysis and decision-making processes without significant hindrance.
For customers whose home regions don't have an Azure pair region and are affected by a disaster, the ability to utilize Fabric capacities may be compromised—even if the data within those capacities is replicated. This limitation is tied to the home region’s infrastructure, essential for the capacities' operation.
Home region and capacity functionality
For effective disaster recovery planning, it's critical that you understand the relationship between your home region and capacity locations. Understanding home region and capacity locations helps you make strategic selections of capacity regions, as well as the corresponding replication and recovery processes.
The home region for your organization's tenancy and data storage is set to the billing address location of the first user that signs up. For further details on tenancy setup, go to Power BI implementation planning: Tenant setup. When you create new capacities, your data storage is set to the home region by default. If you wish to change your data storage region to another region, you'll need to enable Multi-Geo, a Fabric Premium feature.
Tärkeä
Choosing a different region for your capacity doesn't entirely relocate all of your data to that region. Some data elements still remain stored in the home region. To see which data remains in the home region and which data is stored in the Multi-Geo enabled region, see Configure Multi-Geo support for Fabric Premium.
In the case of a home region that doesn't have a paired region, capacities in any Multi-Geo enabled region may face operational issues if the home region encounters a disaster, as the core service functionality is tethered to the home region.
If you select a Multi-Geo enabled region within the EU, it's guaranteed that your data is stored within the EU data boundary.
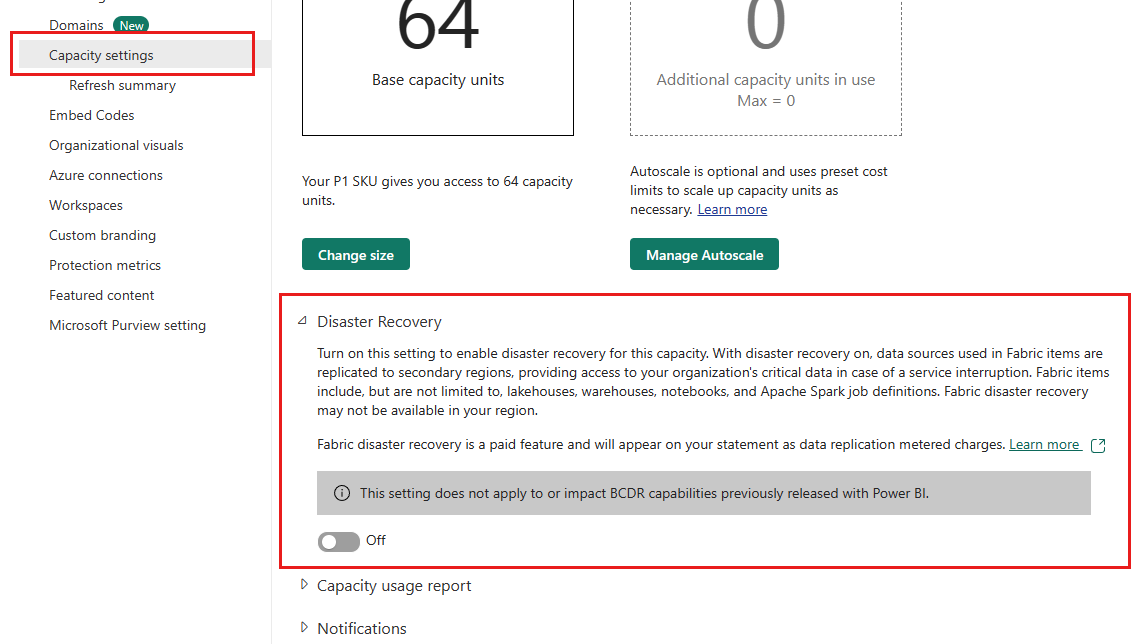
Fabric provides a disaster recovery switch on the capacity settings page. It's available where Azure regional pairings align with Fabric's service presence. Here are the specifics of this switch:
Role access: Only users with the capacity admin role or higher can use this switch.
Granularity: The granularity of the switch is the capacity level. It's available for both Premium and Fabric capacities.
Data scope: The disaster recovery toggle specifically addresses OneLake data, which includes Lakehouse and Warehouse data. The switch does not influence your data stored outside OneLake.
BCDR continuity for Power BI: While disaster recovery for OneLake data can be toggled on and off, BCDR for Power BI is always supported, regardless of whether the switch is on or off.
Frequency: Once you change the disaster recovery capacity setting, you must wait 30 days before being able to alter it again. The wait period is set in place to maintain stability and prevent constant toggling,
Huomautus
After turning on the disaster recovery capacity setting, it can take up to one week for the data to start replicating.
Data replication
When you turn on the disaster recovery capacity setting, cross-region replication is enabled as a disaster recovery capability for OneLake data. The Fabric platform aligns with Azure regions to provision the geo-redundancy pairs. However, some regions don't have an Azure pair region, or the pair region doesn't support Fabric. For these regions, data replication isn't available. For more information, see Regions with availability zones and no region pair and Fabric region availability.
Huomautus
While Fabric offers a data replication solution in OneLake to support disaster recovery, there are notable limitations. For instance, the data of KQL databases and query sets is stored externally to OneLake, which means that a separate disaster recovery approach is needed. Refer to the rest of this document for details of the disaster recovery approach for each Fabric item.
Billing
The disaster recovery feature in Fabric enables geo-replication of your data for enhanced security and reliability. This feature consumes more storage and transactions, which are billed as BCDR Storage and BCDR Operations respectively. You can monitor and manage these costs in the Microsoft Fabric Capacity Metrics app, where they appear as separate line items.
While Fabric provides disaster recovery features to support data resiliency, you must follow certain manual steps to restore service during disruptions. This section details the actions you should take to prepare for potential disruptions.
Phase 1: Prepare
Activate the disaster recovery capacity settings: Regularly review and set the disaster recovery capacity settings to make sure they meet your protection and performance needs.
Create data backups: Copy critical data stored outside of OneLake to another region in a way that aligns to your disaster recovery plan.
Phase 2: Disaster failover
When a major disaster renders the primary region unrecoverable, Microsoft Fabric initiates a regional failover. Access to the Fabric portal is unavailable until the failover is complete and a notification is posted on the Microsoft Fabric support page.
The time it takes for failover to complete can vary, although it typically takes less than one hour. Once failover is complete, here's what you can expect:
Fabric portal: You can access the portal, and read operations such as browsing existing workspaces and items continue to work. All write operations, such as creating or modifying a workspace, are paused.
Power BI: You can perform read operations, such as displaying dashboards and reports. Refreshes, report publish operations, dashboard and report modifications, and other operations that require changes to metadata aren't supported.
Lakehouse/Warehouse: You can't open these items, but files can be accessed via OneLake APIs or tools.
Spark Job Definition: You can't open Spark job definitions, but code files can be accessed via OneLake APIs or tools. Any metadata or configuration will be saved after failover.
Notebook: You can't open notebooks, and code content won't be saved after the disaster.
ML Model/Experiment: You can't open ML models or experiments. Code content and metadata such as run metrics and configurations won't be saved after the disaster.
Dataflow Gen2/Pipeline/Eventstream: You can't open these items, but you can use supported disaster recovery destinations (lakehouses or warehouses) to protect data.
KQL Database/Queryset: You won't be able to access KQL databases and query sets after failover. More prerequisite steps are required to protect the data in KQL databases and query sets.
In a disaster scenario, the Fabric portal and Power BI are in read-only mode, and other Fabric items are unavailable, you can access their data stored in OneLake using APIs or third-party tools. Both portal and Power BI retain the ability to perform read-write operations on that data. This ability ensures that critical data remains accessible and modifiable, and mitigates potential disruption of your business operations.
OneLake data remains accessible through multiple channels:
While Fabric ensures that data remains accessible after a disaster, you can also act to fully restore their services to the state before the incident. This section provides a step-by-step guide to help you through the recovery process.
Recovery steps
Create a new Fabric capacity in any region after a disaster. Given the high demand during such events, we recommend selecting a region outside your primary geo to increase likelihood of compute service availability. For information about creating a capacity, see Buy a Microsoft Fabric subscription.
Create workspaces in the newly created capacity. If necessary, use the same names as the old workspaces.
Create items with the same names as the ones you want to recover. This step is important if you use the custom script to recover lakehouses and warehouses.