Cet article décrit le processus de conception, les principes et les choix technologiques permettant d’utiliser Azure Synapse pour créer une solution data lakehouse sécurisée. Nous nous concentrons sur les considérations de sécurité et les décisions techniques clés.
Apache®, Apache Spark® et le logo représentant une flamme sont soit des marques déposées, soit des marques commerciales d’Apache Software Foundation aux États-Unis et/ou dans d’autres pays. L’utilisation de ces marques n’implique aucune approbation de l’Apache Software Foundation.
Architecture
Le diagramme suivant représente l’architecture de la solution data lakehouse. Elle est conçue pour contrôler les interactions entre les services afin d’atténuer les menaces de sécurité. Les solutions varient en fonction des exigences fonctionnelles et de sécurité.

Téléchargez un fichier Visio de cette architecture.
Dataflow
Le flux de données de la solution est illustré dans le diagramme suivant :

- Les données sont chargées à partir de la source de données vers la zone d’atterrissage des données, soit dans le Stockage Blob Azure, soit dans un partage de fichiers fourni par Azure Files. Les données sont chargées par un programme ou un système de chargement par lots. Les données de diffusion en continu sont capturées et stockées dans Stockage Blob à l’aide de la fonctionnalité de capture d’Azure Event Hubs. Il peut y avoir plusieurs sources de données. Par exemple, plusieurs usines différentes peuvent charger leurs données d’opérations. Pour plus d’informations sur la sécurisation de l’accès à Stockage Blob, aux partages de fichiers et à d’autres ressources de stockage, consultez Recommandations de sécurité pour Stockage blob et Planification d’un déploiement Azure Files.
- L’arrivée du fichier de données déclenche Azure Data Factory qui traite les données et les stocke dans le lac de données dans la zone de données principale. Le chargement des données dans la zone de données principale dans Azure Data Lake protège contre l’exfiltration des données.
- Azure Data Lake stocke les données brutes obtenues à partir de différentes sources. Elles sont protégées par des règles de pare-feu et des réseaux virtuels. Le service bloque toutes les tentatives de connexion provenant de l’Internet public.
- L’arrivée des données dans le lac de données déclenche le pipeline Azure Synapse, ou un déclencheur régulier exécute un travail de traitement des données. Apache Spark dans Azure Synapse est activé et exécute un notebook ou un travail Spark. Il orchestre également le flux de processus des données dans le data lakehouse. Les pipelines Azure Synapse convertissent les données de la zone Bronze vers la zone Argent, puis vers la zone Or.
- Un notebook ou un travail Spark exécute le travail de traitement des données. La collecte des données ou un travail d’entraînement Machine Learning peuvent également s’exécuter dans Spark. Les données structurées dans la zone Or sont stockées au format Delta Lake.
- Un pool SQL serverless crée des tables externes qui utilisent les données stockées dans Delta Lake. Le pool SQL serverless fournit un moteur d’interrogation SQL puissant et efficace et peut prendre en charge les comptes d’utilisateur traditionnels SQL ou les comptes d’utilisateur Microsoft Entra.
- Power BI se connecte au pool SQL serverless pour visualiser les données. Le service crée des rapports ou des tableaux de bord à l’aide des données dans le data lakehouse.
- Les scientifiques ou analystes Données peuvent se connecter à Azure Synapse Studio pour :
- Améliorer davantage les données.
- Procéder à une analyse pour obtenir des insights sur l’entreprise.
- Entraîner le modèle Machine Learning.
- Les applications métier se connectent à un pool SQL serverless et utilisent les données pour prendre en charge d’autres exigences d’exploitation métier.
- Azure Pipelines exécute le processus CI/CD qui génère, teste et déploie automatiquement la solution. Ce service est conçu pour réduire l’intervention humaine pendant le processus de déploiement.
Composants
Voici les composants clés de cette solution data lakehouse :
- Azure Synapse
- Azure Files
- Hubs d'événements
- Stockage Blob
- Azure Data Lake Storage
- Azure DevOps
- Power BI
- Data Factory
- Azure Bastion
- Azure Monitor
- Microsoft Defender pour le cloud
- Azure Key Vault
Autres solutions
- Si vous avez besoin d’effectuer un traitement des données en temps réel, vous pouvez utiliser le flux structuré Apache pour recevoir le flux de données à partir d’Event Hubs et le traiter, au lieu de stocker des fichiers individuels sur la zone d’atterrissage des données.
- Si les données ont une structure complexe et nécessitent des requêtes SQL complexes, envisagez de les stocker dans un pool SQL dédié au lieu d’un pool SQL serverless.
- Si les données contiennent de nombreuses structures de données hiérarchiques (par exemple, s’il y a une structure JSON volumineuse), vous pouvez les stocker dans l’Explorateur de données Azure Synapse.
Détails du scénario
Azure Synapse Analytics est une plateforme de données polyvalente qui prend en charge l’entreposage de données d’entreprise, l’analytique des données en temps réel, les pipelines, le traitement des données de série chronologique, l’apprentissage automatique et la gouvernance des données. Pour prendre en charge ces fonctionnalités, elle intègre plusieurs technologies différentes, telles que :
- Entreposage des données d’entreprise
- Pools SQL serverless
- Apache Spark
- Pipelines
- Explorateur de données
- Fonctionnalités de Machine Learning
- Gouvernance des données unifiée sur Purview
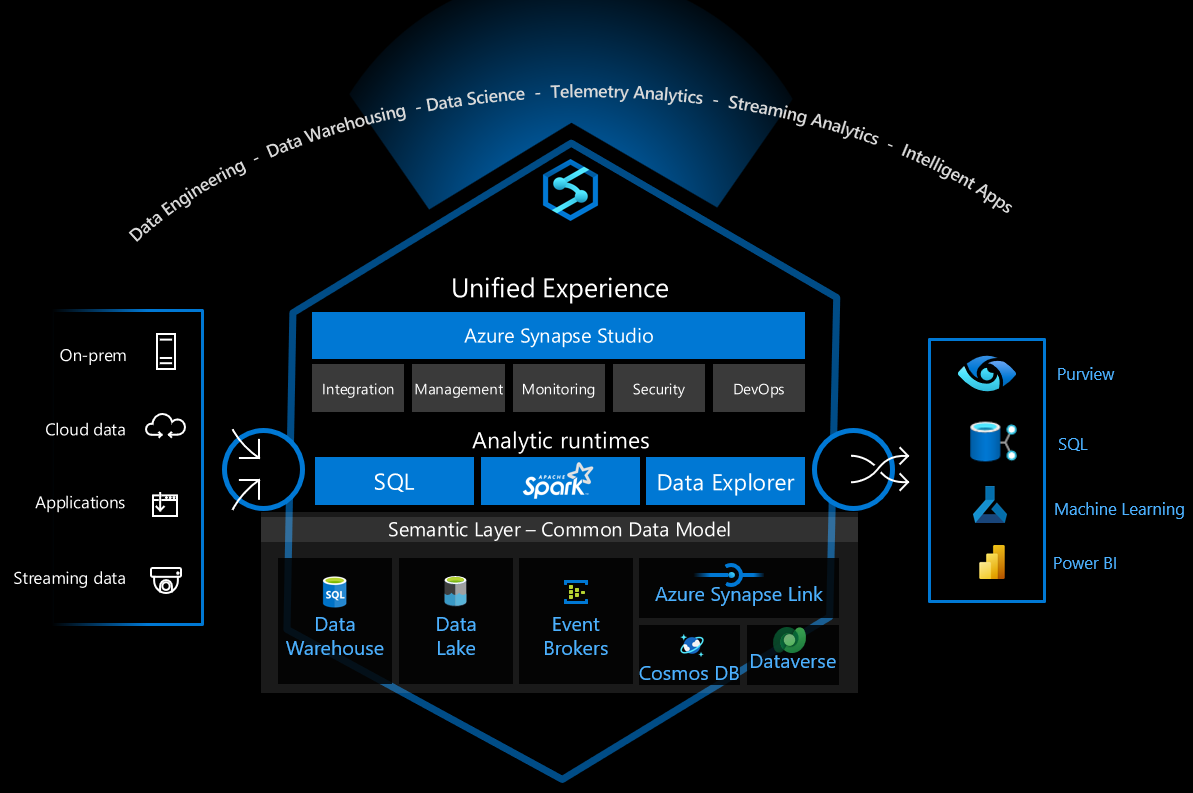
Ces fonctionnalités ouvrent de nombreuses possibilités, mais il y a de nombreux choix techniques à faire pour configurer l’infrastructure de manière sécurisée pour une utilisation sûre.
Cet article décrit le processus de conception, les principes et les choix technologiques permettant d’utiliser Azure Synapse pour créer une solution data lakehouse sécurisée. Nous nous concentrons sur les considérations de sécurité et les décisions techniques clés. La solution utilise les services Azure suivants :
- Azure Synapse
- Pools SQL serverless Azure Synapse
- Apache Spark dans Azure Synapse Analytics
- Pipelines Azure Synapse
- Azure Data Lake
- Azure DevOps.
L’objectif est de fournir une aide pour la création d’une plateforme de data lakehouse sécurisée et rentable pour l’entreprise et avec la façon dont les technologies fonctionnent ensemble en toute transparence et en toute sécurité.
Cas d’usage potentiels
Un data lakehouse est une architecture moderne de gestion des données qui combine les fonctionnalités d’efficacité, d’échelle et de flexibilité d’un lac de données avec les fonctionnalités de gestion des données et des transactions d’un entrepôt de données. Un data lakehouse peut gérer une grande quantité de données et prendre en charge les scénarios d’intelligence décisionnelle et de Machine Learning. Cette architecture peut également traiter les données provenant de diverses structures et sources de données. Pour plus d’informations, consultez Qu’est-ce que Databricks Lakehouse ?.
Voici quelques cas d’usage courants pour la solution décrite :
- Analyse des données de télémétrie d’Internet des objets (IoT)
- Automatisation des usines intelligentes (pour la fabrication)
- Suivi des activités et du comportement des consommateurs (pour le commerce au détail)
- Gestion des incidents et des événements de sécurité
- Surveillance des journaux d’activité et du comportement de l’application
- Traitement et analyse métier des données semi-structurées
Conception de haut niveau
Cette solution est axée sur les pratiques de conception et d’implémentation de la sécurité dans l’architecture. Pool SQL serverless, Apache Spark dans Azure Synapse, pipelines Azure Synapse, Data Lake Storage et Power BI sont les services clés utilisés pour implémenter le modèle data lakehouse.
Voici l’architecture de conception de solution de haut niveau :

Choisir les axes de sécurité
Nous avons commencé la conception de la sécurité à l’aide de l’outil de modélisation des menaces. Cet outil nous a aidés à :
- Communiquer avec les parties prenantes du système sur les risques potentiels.
- Définir la limite de confiance dans le système.
En nous basant sur les résultats de la modélisation des menaces, nous avons fait des domaines de sécurité suivants nos priorités :
- Contrôle des accès et des identités
- Protection du réseau
- Sécurité DevOps
Nous avons conçu les fonctionnalités de sécurité et les changements d’infrastructure pour protéger le système en réduisant les risques de sécurité clés identifiés par rapport à ces priorités principales.
Pour plus d’informations sur ce qui doit être vérifié et pris en compte, consultez :
- Sécurité dans le Cloud Adoption Framework Microsoft pour Azure
- Contrôle d’accès
- Protection des ressources
- Sécurité de l’innovation
Plan de protection des ressources et du réseau
L’un des principes de sécurité clés du Cloud Adoption Framework est le principe de Confiance Zéro : lors de la conception de la sécurité pour n’importe quel composant ou système, réduisez le risque que les attaquants étendent leur accès en supposant que les autres ressources de l’organisation sont compromises.
En fonction du résultat de la modélisation des menaces, la solution adopte la recommandation de déploiement de microsegmentation de la Confiance Zéro et définit plusieurs limites de sécurité. Le réseau virtuel Azure et la protection contre l’exfiltration de données d’Azure Synapse sont les technologies clés utilisées pour implémenter la limite de sécurité afin de protéger les ressources de données et les composants critiques.
Étant donné qu’Azure Synapse est composé de plusieurs technologies différentes, nous devons :
Identifier les composants de Synapse et les services associés utilisés dans le projet.
Azure Synapse est une plateforme de données polyvalente qui peut gérer de nombreux besoins de traitement des données différents. Tout d’abord, nous devons décider quels composants d’Azure Synapse sont utilisés dans le projet afin de pouvoir planifier la façon de les protéger. Nous devons également déterminer quels autres services communiquent avec ces composants Azure Synapse.
Dans l’architecture data lakehouse, les composants clés sont les suivants :
- SQL serverless Azure Synapse
- Apache Spark dans Azure Synapse
- Pipelines Azure Synapse
- Data Lake Storage
- Azure DevOps
Définir les comportements de communication légaux entre les composants.
Nous devons définir les comportements de communication autorisés entre les composants. Par exemple, voulons-nous que le moteur Spark communique directement avec l’instance SQL dédiée ou qu’il communique via un proxy tel que le pipeline d’intégration de données Azure Synapse ou Data Lake Storage ?
Selon le principe de Confiance Zéro, nous bloquons la communication si l’interaction ne rentre pas dans le cadre d’un besoin d’entreprise. Par exemple, nous empêchons un moteur Spark se trouvant dans un locataire inconnu de communiquer directement avec Data Lake Storage.
Choisir la solution de sécurité appropriée pour appliquer les comportements de communication définis.
Dans Azure, plusieurs technologies de sécurité peuvent appliquer les comportements de communication de service définis. Par exemple, dans Data Lake Storage, vous pouvez utiliser une liste d’autorisation d’adresses IP pour contrôler l’accès à un lac de données, mais vous pouvez également choisir quels réseaux virtuels, services Azure et instances de ressources sont autorisés. Chaque méthode de protection fournit une protection de sécurité différente. Choisissez en fonction des besoins d’entreprise et des limitations environnementales. La configuration utilisée dans cette solution est décrite dans la section suivante.
Implémentez la détection des menaces et les défenses avancées pour les ressources critiques.
Pour les ressources critiques, il est préférable d’implémenter la détection des menaces et les défenses avancées. Les services aident à identifier les menaces et à déclencher des alertes, afin que le système puisse informer les utilisateurs en cas de violations de sécurité.
Pensez à utiliser les techniques suivantes pour mieux protéger les réseaux et les ressources :
Déployer des réseaux de périmètre afin de fournir des zones de sécurité aux pipelines de données
Lorsqu’une charge de travail de pipeline de données nécessite l’accès aux données externes et à la zone d’atterrissage des données, il est préférable d’implémenter un réseau de périmètre et de le séparer d’un pipeline d’extraction, de transformation et de chargement (ETL).
Activer Defender pour le cloud pour tous les comptes de stockage
Le service Defender pour le cloud déclenche des alertes de sécurité lorsqu’il détecte des tentatives inhabituelles et potentiellement dangereuses d’accès ou d’exploitation de comptes de stockage. Pour plus d’informations, consultez Configurer Microsoft Defender pour le stockage.
Verrouiller un compte de stockage pour empêcher toute suppression ou modification malveillante de la configuration
Pour plus d’informations, consultez Appliquer un verrou Azure Resource Manager sur un compte de stockage.
Architecture avec la protection du réseau et des ressources
Le tableau suivant décrit les comportements de communication définis et les technologies de sécurité choisies pour cette solution. Les choix étaient basés sur les méthodes abordées dans la section Plan de protection des ressources et du réseau.
| De (Client) | À (Service) | Comportement | Configuration | Notes | |
|---|---|---|---|---|---|
| Internet | Data Lake Storage | Tout refuser | Règle de pare-feu - Refuser par défaut | Valeur par défaut : « Refuser » | Règle de pare-feu - Refuser par défaut |
| Pipeline Azure Synapse/Spark | Data Lake Storage | Autoriser (instance) | Réseau virtuel - Point de terminaison privé managé (Data Lake Storage) | ||
| SQL Synapse | Data Lake Storage | Autoriser (instance) | Règle de pare-feu - Instances de ressources (Synapse SQL) | Synapse SQL doit accéder à Data Lake Storage à l’aide d’identités managées | |
| Agent Azure Pipelines | Data Lake Storage | Autoriser (instance) | Règle de pare-feu - Réseaux virtuels sélectionnés Point de terminaison de service - Stockage |
Pour le test d’intégration contournement : « AzureServices » (règle de pare-feu) |
|
| Internet | Espace de travail Synapse | Tout refuser | Règle de pare-feu | ||
| Agent Azure Pipelines | Espace de travail Synapse | Autoriser (instance) | Réseau virtuel - point de terminaison privé | Nécessite trois points de terminaison privés (Dev, SQL serverless et SQL dédié) | |
| Réseau virtuel managé Synapse | Locataire Azure Internet ou non autorisé | Tout refuser | Réseau virtuel - Protection contre l’exfiltration de données Synapse | ||
| Pipeline Synapse/Spark | Key Vault | Autoriser (instance) | Réseau virtuel - Point de terminaison privé managé (Key Vault) | Valeur par défaut : « Refuser » | |
| Agent Azure Pipelines | Key Vault | Autoriser (instance) | Règle de pare-feu - Réseaux virtuels sélectionnés * Point de terminaison de service - Key Vault |
contournement : « AzureServices » (règle de pare-feu) | |
| Azure Functions | SQL serverless Synapse | Autoriser (instance) | Réseau virtuel - Point de terminaison privé (SQL serverless Synapse) | ||
| Pipeline Synapse/Spark | Azure Monitor | Autoriser (instance) | Réseau virtuel - Point de terminaison privé (Azure Monitor) |
Par exemple, dans le plan, nous voulons :
- Créer un espace de travail Azure Synapse avec un réseau virtuel d’espace de travail managé.
- Sécurisez la sortie de données d’espaces de travail Azure Synapse à l’aide de la protection contre l’exfiltration de données Azure Synapse.
- Gérez la liste des tenants Microsoft Entra approuvés pour l’espace de travail Azure Synapse.
- Configurez des règles de réseau pour autoriser le trafic sur le compte de stockage à partir de réseaux virtuels sélectionnés (accès uniquement) et désactivez l’accès au réseau public.
- Utilisez des points de terminaison privés managés pour connecter le réseau virtuel géré par Azure Synapse au lac de données.
- Utilisez l’instance de ressource pour connecter en toute sécurité Azure Synapse SQL au lac de données.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework, un ensemble de principes directeurs que vous pouvez utiliser pour améliorer la qualité d’une charge de travail. Pour plus d'informations, consultez Microsoft Azure Well-Architected Framework.
Sécurité
Pour plus d’informations sur le pilier de sécurité du Well-Architected Framework, consultez Sécurité.
Contrôle des accès et des identités
Il existe plusieurs composants dans le système. Chacun d’eux nécessite une configuration de gestion des identités et des accès (IAM) différente. Ces configurations doivent collaborer pour offrir une expérience utilisateur simplifiée. Par conséquent, nous utilisons les instructions de conception suivantes lorsque nous implémentons le contrôle d’identité et d’accès.
Choisir une solution d’identité pour différentes couches de contrôle d’accès
- Il existe quatre solutions d’identité différentes dans le système.
- Compte SQL (SQL Server)
- Principal de service (Microsoft Entra ID)
- Identité managée (Microsoft Entra ID)
- Compte d’utilisateur (Microsoft Entra ID)
- Il existe quatre couches de contrôle d’accès différentes dans le système.
- Couche d’accès aux applications : choisissez la solution d’identité pour les rôles AP.
- Couche d’accès à la base de données/table Azure Synapse : choisissez la solution d’identité pour les rôles dans les bases de données.
- Couche de ressources externes d’accès à Azure Synapse : choisissez la solution d’identité pour accéder aux ressources externes.
- Couche d’accès à Data Lake Storage : choisissez la solution d’identité pour contrôler l’accès aux fichiers dans le stockage.

Une partie cruciale du contrôle d’identité et d’accès consiste à choisir la solution d’identité appropriée pour chaque couche de contrôle d’accès. Les principes de conception de la sécurité d’Azure Well-Architected Framework suggèrent d’utiliser les contrôles natifs et de faire le plus simple possible. Par conséquent, cette solution utilise le compte d’utilisateur Microsoft Entra de l’utilisateur final dans l’application et les couches d’accès de base de données Azure Synapse. Elle tire parti des solutions IAM internes natives et fournit un contrôle d’accès de granularité fine. La couche de ressources externes d’accès à Azure Synapse et la couche d’accès à Data Lake utilisent l’identité managée dans Azure Synapse pour simplifier le processus d’autorisation.
- Il existe quatre solutions d’identité différentes dans le système.
Utiliser le privilège avec accès minimal
Un principe Confiance Zéro suggère de fournir un accès juste-à-temps et juste suffisant aux ressources critiques. Consultez Microsoft Entra Privileged Identity Management (PIM) pour améliorer la sécurité à l’avenir.
Protéger le service lié
Les services liés définissent les informations de connexion nécessaires à un service pour se connecter à des ressources externes. Il est important de sécuriser les configurations des services liés.
- Créez un service lié Azure Data Lake avec Private Link.
- Utilisez l’identité managée comme méthode d’authentification dans les services liés.
- Utilisez Azure Key Vault pour sécuriser les informations d’identification pour accéder au service lié.

Évaluation du score de sécurité et détection des menaces
Pour comprendre l’état de sécurité du système, la solution utilise Microsoft Defender pour le cloud afin d’évaluer la sécurité de l’infrastructure et de détecter les problèmes de sécurité. Microsoft Defender pour le cloud est un outil destiné à la gestion de posture de sécurité et à la protection contre les menaces. Il peut protéger les charges de travail s’exécutant dans Azure, un environnement hybride et d’autres plateformes cloud.

Lorsque vous visitez pour la première fois les pages Defender pour le cloud dans le portail Azure, vous activez automatiquement le plan gratuit de Defender pour le cloud sur tous vos abonnements Azure. Nous vous recommandons vivement de l’activer pour obtenir une évaluation et des suggestions relatives à votre stratégie de sécurité cloud. Microsoft Defender pour le cloud fournit votre score de sécurité et des conseils pour renforcer la sécurité sur vos abonnements.
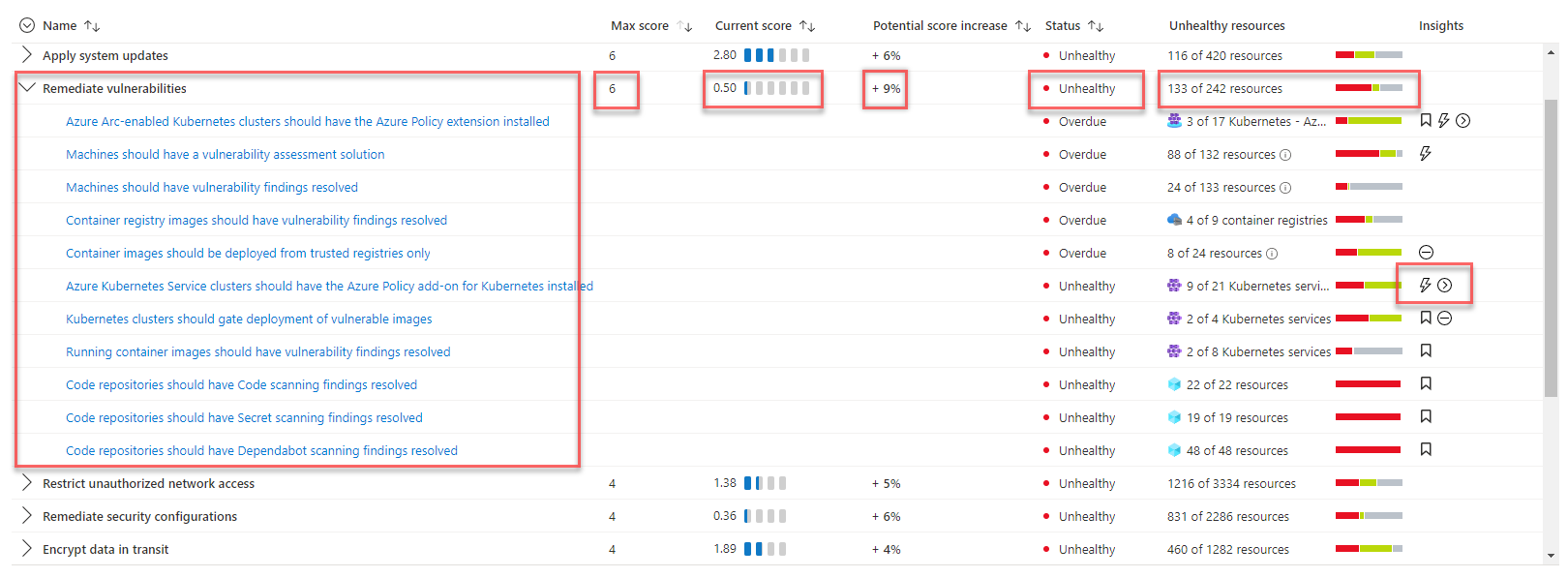
Si la solution a besoin de fonctionnalités avancées de gestion de la sécurité et de détection des menaces, telles que la détection des activités suspectes et les alertes, vous pouvez activer la protection des charges de travail cloud individuellement pour différentes ressources.
Optimisation des coûts
Pour plus d’informations sur le pilier d’optimisation des coûts du Well-Architected Framework, consultez Optimisation des coûts.
L’un des principaux avantages de la solution data lakehouse est son architecture économique et évolutive. La plupart des composants de la solution utilisent la facturation basée sur la consommation et ont des fonctionnalités de mise à l’échelle automatique. Dans cette solution, toutes les données sont stockées dans Data Lake Storage. Vous payez uniquement pour le stockage des données si vous n’exécutez aucune requête ou ne traitez pas de données.
La tarification de cette solution dépend de l’utilisation des ressources clés suivantes :
- SQL serverless Azure Synapse : utilisez la facturation basée sur la consommation, payez uniquement pour ce que vous utilisez.
- Apache Spark dans Azure Synapse : utilisez la facturation basée sur la consommation, payez uniquement pour ce que vous utilisez.
- Pipelines Azure Synapse : utilisez la facturation basée sur la consommation, payez uniquement pour ce que vous utilisez.
- Lacs de données Azure : utilisez la facturation basée sur la consommation, payez uniquement pour ce que vous utilisez.
- Power BI : le coût dépend de la licence que vous achetez.
- Private Link : utilisez la facturation basée sur la consommation, payez uniquement pour ce que vous utilisez.
Les différentes solutions de protection de la sécurité ont des modes de coût différents. Vous devez choisir la solution de sécurité en fonction des besoins de votre entreprise et du coût des solutions.
Utilisez la Calculatrice de prix Azure pour estimer le coût d’une solution.
Excellence opérationnelle
Pour plus d’informations sur le pilier de l’excellence opérationnelle du Well-Architected Framework, consultez Excellence opérationnelle.
Utiliser un agent de pipeline auto-hébergé avec un réseau virtuel pour les services CI/CD
L’agent de pipeline par défaut Azure DevOps ne prend pas en charge la communication de réseau virtuel, car il utilise une plage d’adresses IP très large. Cette solution implémente un agent auto-hébergé Azure DevOps dans le réseau virtuel afin que les processus DevOps puissent communiquer de manière fluide avec les autres services de la solution. Les chaînes de connexion et les secrets pour l’exécution des services CI/CD sont stockés dans un coffre de clés indépendant. Pendant le processus de déploiement, l’agent auto-hébergé accède au coffre de clés dans la zone de données principale pour mettre à jour les configurations de ressources et les secrets. Pour plus d’informations, consultez le document Utiliser des coffres de clés distincts. Cette solution utilise également des groupes identiques de machines virtuelles pour s’assurer que le moteur de DevOps peut effectuer automatiquement un scale-up et un scale-down en fonction de la charge de travail.

Implémenter l’analyse de la sécurité de l’infrastructure et les tests de vérification de sécurité dans le pipeline CI/CD
Un outil d’analyse statique pour l’analyse des fichiers IaC (infrastructure as code) peut aider à détecter et à prévenir les configurations incorrectes pouvant entraîner des problèmes de sécurité ou de conformité. Les tests de vérification de sécurité garantissent que les mesures de sécurité du système vitales sont correctement activées, ce qui protège contre les défaillances de déploiement.
- Utilisez un outil d’analyse statique pour l’analyse des modèles IaC (infrastructure as code) pour détecter et prévenir les configurations incorrectes pouvant entraîner des problèmes de sécurité ou de conformité. Utilisez des outils tels que Checkov ou Terrascan pour détecter et prévenir les risques de sécurité.
- Assurez-vous que le pipeline CD gère correctement les échecs de déploiement. Toute défaillance de déploiement liée aux fonctionnalités de sécurité doit être traitée comme une défaillance critique. Le pipeline doit réessayer l’action ayant échoué ou mettre le déploiement en pause.
- Validez les mesures de sécurité dans le pipeline de déploiement en exécutant des tests de vérification de sécurité. Les tests de vérification de sécurité, tels que la validation de l’état de configuration des ressources déployées ou les tests de cas qui examinent les scénarios de sécurité critiques, peuvent garantir que la conception de la sécurité fonctionne comme prévu.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Herman Wu | Ingénieur logiciel senior
Autres contributeurs :
- Ian Chen | Ingénieur logiciel responsable principal
- Jose Contreras | Responsable ingénierie logicielle
- Roy Chan | Ingénieur logiciel manager principal
Étapes suivantes
- Documentation de produit Azure
- Autres articles
- Présentation d’Azure Synapse Analytics
- Pool SQL serverless dans Azure Synapse Analytics
- Apache Spark dans Azure Synapse Analytics
- Pipelines et activités dans Azure Data Factory et Azure Synapse Analytics
- Qu’est-ce que l’explorateur de données Azure Synapse ? (Préversion)
- Fonctionnalités de Machine Learning dans Azure Synapse Analytics
- Qu’est-ce que Microsoft Purview ?
- Azure Synapse Analytics et Azure Purview fonctionnent mieux ensemble
- Introduction à Azure Data Lake Storage Gen2
- Présentation d’Azure Data Factory
- Série de blog sur les modèles de données actuels : Data Lakehouse
- Qu’est-ce que Microsoft Defender pour le cloud ?
- L’architecture Data Lakehouse, l’entrepôt de données et l’architecture de plateforme de données moderne
- Les meilleures pratiques pour organiser les espaces de travail et les lakehouses Azure Synapse
- Présentation des points de terminaison privés Azure Synapse
- Azure Synapse Analytics – Nouveaux insights sur la sécurité des données
- Base de référence de la sécurité Azure pour le pool SQL dédié Azure Synapse (anciennement SQL DW)
- Bases de la sécurité du réseau cloud : points de terminaison de service Azure et points de terminaison privés
- Guide pratique pour configurer le contrôle d’accès pour votre espace de travail Azure Synapse
- Se connecter à Azure Synapse Studio à l’aide de hubs Azure Private Link
- Guide pratique pour déployer votre espace de travail Azure Synapse Artifacts sur un espace de travail de RÉSEAU VIRTUEL managé Azure Synapse
- Intégration et livraison continues pour un espace de travail Azure Synapse Analytics
- Degré de sécurisation dans Microsoft Defender pour le cloud
- Meilleures pratiques pour l'utilisation d’Azure Key Vault
- Scénario Adatum Corporation de gestion et d’analyse des données dans Azure