Copier des données de Teradata Vantage à l’aide d’Azure Data Factory et Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit comment utiliser l’activité de copie dans des pipelines Azure Data Factory et Azure Synapse Analytics pour copier des données provenant de Teradata Vantage. Il s’appuie sur la vue d’ensemble de l’activité de copie.
Fonctionnalités prises en charge
Ce connecteur Teradata est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/-) | |
| Activité de recherche |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour obtenir la liste des banques de données prises en charge en tant que sources ou récepteurs par l’activité de copie, consultez le tableau Banques de données prises en charge.
Plus précisément, ce connecteur Teradata prend en charge :
- Teradata versions 14.10, 15.0, 15.10, 16.0, 16.10 et 16.20.
- Copie des données avec l’authentification De base, Windows ou LDAP.
- Copie en parallèle à partir d’une source Teradata. Pour en savoir plus, voir Copie en parallèle à partir de Teradata.
Prérequis
Si votre magasin de données se trouve dans un réseau local, un réseau virtuel Azure ou un cloud privé virtuel Amazon, vous devez configurer un runtime d’intégration auto-hébergé pour vous y connecter.
Si votre magasin de données est un service de données cloud managé, vous pouvez utiliser Azure Integration Runtime. Si l’accès est limité aux adresses IP qui sont approuvées dans les règles de pare-feu, vous pouvez ajouter les adresses IP Azure Integration Runtime dans la liste d’autorisation.
Vous pouvez également utiliser la fonctionnalité de runtime d’intégration de réseau virtuel managé dans Azure Data Factory pour accéder au réseau local sans installer et configurer un runtime d’intégration auto-hébergé.
Pour plus d’informations sur les mécanismes de sécurité réseau et les options pris en charge par Data Factory, consultez Stratégies d’accès aux données.
Si vous utilisez un runtime d’intégration auto-hébergé, notez qu’il fournit un pilote Teradata intégré depuis la version 3.18. Vous n’avez pas besoin d’installer manuellement un pilote. Le pilote requiert l’installation du package Redistribuable Visual C++ pour Visual Studio 2012 Update 4 sur l’ordinateur du runtime d’intégration auto-hébergé. S’il n’est pas déjà installé, vous pouvez le télécharger ici.
Prise en main
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié à Teradata à l’aide de l’interface utilisateur
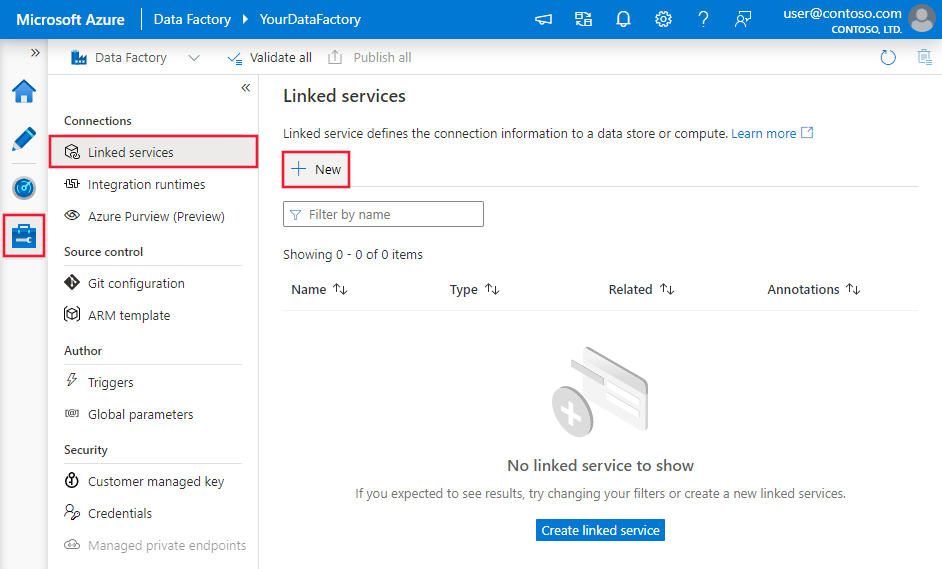
Utilisez les étapes suivantes pour créer un service lié à Teradata dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse et sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Teradata et sélectionnez le connecteur Teradata.
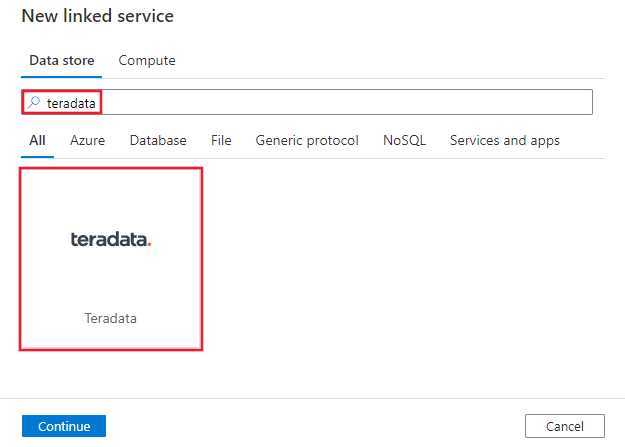
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
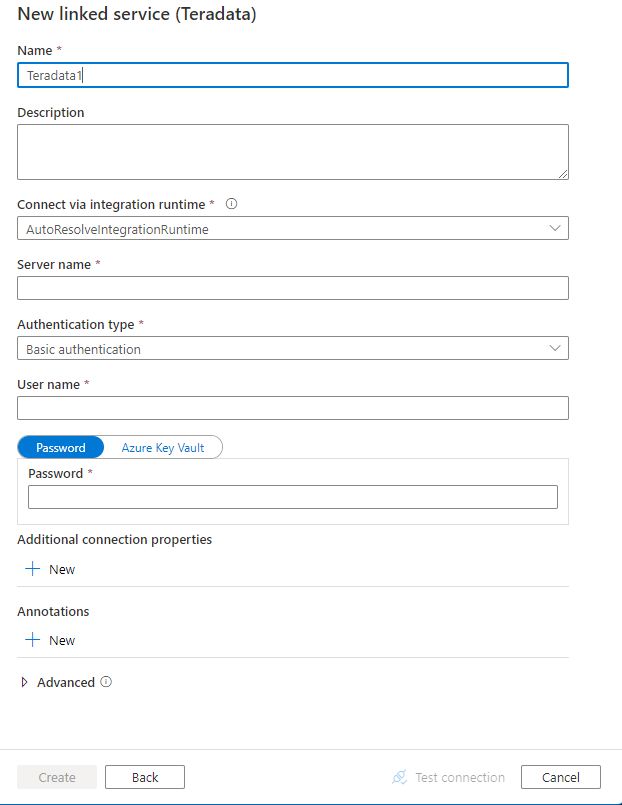
Informations de configuration des connecteurs
Les sections suivantes fournissent des informations sur les propriétés utilisées pour définir les entités Data Factory propres au connecteur Teradata.
Propriétés du service lié
Le service lié Teradata prend en charge les propriétés suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type doit être définie sur Teradata. | Oui |
| connectionString | Spécifie les informations requises pour se connecter à l’instance de Teradata. Consultez les exemples suivants. Vous pouvez également définir un mot de passe dans Azure Key Vault et extraire la configuration password de la chaîne de connexion. Pour plus d’informations, consultez la section Stocker des informations d’identification dans Azure Key Vault. |
Oui |
| username | Spécifiez le nom d’utilisateur associé à la connexion à Teradata. S’applique lors de l’utilisation de l’authentification Windows. | Non |
| mot de passe | Spécifiez un mot de passe pour le compte d’utilisateur que vous avez spécifié pour le nom d’utilisateur. Vous pouvez également choisir de référencer un secret stocké dans Azure Key Vault. S’applique lors de l’utilisation de l’authentification Windows ou du référencement du mot de passe dans Key Vault pour l’authentification de base. |
Non |
| connectVia | Runtime d’intégration à utiliser pour la connexion à la banque de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
Autres propriétés de connexion que vous pouvez définir dans la chaîne de connexion selon votre cas :
| Propriété | Description | Valeur par défaut |
|---|---|---|
| TdmstPortNumber | Numéro du port utilisé pour accéder à la base de données Teradata. Ne modifiez pas cette valeur à moins que le support technique vous demande de le faire. |
1025 |
| UseDataEncryption | Spécifie s’il faut chiffrer toutes les communications avec la base de données Teradata. Les valeurs autorisées sont 0 ou 1. - 0 (désactivé, valeur par défaut) : Chiffre uniquement les informations d’authentification. - 1 (activé) : Chiffre toutes les données transmises entre le pilote et la base de données. |
0 |
| CharacterSet | Jeu de caractères à utiliser pour la session. Par exemple, CharacterSet=UTF16.Cette valeur peut être un jeu de caractères défini par l’utilisateur ou l’un des jeux de caractères prédéfinis suivants : - ASCII - UTF8 - UTF16 - LATIN1252_0A - LATIN9_0A - LATIN1_0A - Shift-JIS (Windows, compatible DOS, KANJISJIS_0S) - EUC (compatible Unix, KANJIEC_0U) - Mainframe IBM (KANJIEBCDIC5035_0I) - KANJI932_1S0 - BIG5 (TCHBIG5_1R0) - GB (SCHGB2312_1T0) - SCHINESE936_6R0 - TCHINESE950_8R0 - NetworkKorean (HANGULKSC5601_2R4) - HANGUL949_7R0 - ARABIC1256_6A0 - CYRILLIC1251_2A0 - HEBREW1255_5A0 - LATIN1250_1A0 - LATIN1254_7A0 - LATIN1258_8A0 - THAI874_4A0 |
ASCII |
| MaxRespSize | Taille maximale de la mémoire tampon de réponse pour les requêtes SQL en Ko (kilo-octets). Par exemple, MaxRespSize=10485760.Pour la version de base de données Teradata 16.00 (ou ultérieure), la valeur maximale est 7361536. Pour les connexions qui utilisent des versions antérieures, la valeur maximale est 1048576. |
65536 |
| MechanismName | Pour utiliser le protocole LDAP afin d’authentifier la connexion, spécifiez MechanismName=LDAP. |
N/A |
Exemple : utilisation de l’authentification de base
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple : utilisation d’une authentification Windows
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>",
"username": "<username>",
"password": "<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple d’utilisation de l’authentification LDAP
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;MechanismName=LDAP;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Notes
La charge utile suivante est toujours prise en charge. Cependant, nous vous invitons à utiliser la nouvelle charge utile dorénavant.
Charge utile précédente :
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"server": "<server>",
"authenticationType": "<Basic/Windows>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Cette section fournit une liste des propriétés prises en charge par le jeu de données Teradata. Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article sur les jeux de données.
Pour copier des données à partir de Teradata, les propriétés suivantes sont prises en charge :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur TeradataTable. |
Oui |
| database | Nom de l’instance Teradata. | Non (si « query » dans la source de l’activité est spécifié) |
| table | Nom de la table dans l’instance Teradata. | Non (si « query » dans la source de l’activité est spécifié) |
Exemple :
{
"name": "TeradataDataset",
"properties": {
"type": "TeradataTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
}
}
}
Notes
Le jeu de données de type RelationalTable est toujours pris en charge. Toutefois, nous vous recommandons d’utiliser le nouveau jeu de données.
Charge utile précédente :
{
"name": "TeradataDataset",
"properties": {
"type": "RelationalTable",
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Propriétés de l’activité de copie
Cette section fournit une liste des propriétés prises en charge par la source Teradata. Pour obtenir la liste complète des sections et propriétés disponibles pour la définition des activités, consultez Pipelines.
Teradata en tant que source
Conseil
Pour charger efficacement des données à partir de Teradata à l'aide du partitionnement des données, consultez la section Copie en parallèle à partir de Teradata.
Pour copier des données à partir de Teradata, les propriétés prises en charge dans la section source de l'activité de copie sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source de l’activité de copie doit être définie sur TeradataSource. |
Oui |
| query | Utiliser la requête SQL personnalisée pour lire les données. par exemple "SELECT * FROM MyTable".Lorsque vous activez la charge partitionnée, vous devez utiliser les paramètres de partition intégrés correspondants dans votre requête. Pour consulter des exemples, voir Copie en parallèle à partir de Teradata. |
Non (si la table du jeu de données est spécifiée) |
| partitionOptions | Spécifie les options de partitionnement des données utilisées pour charger des données à partir de Teradata. Les valeurs autorisées sont : Aucun (par défaut), Hachage et DynamicRange. Lorsqu’une option de partition est activée (autrement dit, pas None), le degré de parallélisme pour charger simultanément des données à partir de Teradata est contrôlé par le paramètre parallelCopies de l’activité de copie. |
Non |
| partitionSettings | Spécifiez le groupe de paramètres pour le partitionnement des données. S’applique lorsque l’option de partitionnement n’est pas None. |
Non |
| partitionColumnName | Spécifiez le nom de la colonne source qu’utilisera le partitionnement par plages de valeurs ou hachage pour la copie en parallèle. S’il n’est pas spécifié, l’index primaire de la table sera automatiquement détecté et utilisé en tant que colonne de partition. S’applique lorsque l’option de partitionnement est Hash ou DynamicRange. Si vous utilisez une requête pour récupérer des données sources, utilisez ?AdfHashPartitionCondition ou ?AdfRangePartitionColumnName dans la clause WHERE. Consultez l’exemple de la section Copie en parallèle à partir de Teradata. |
Non |
| partitionUpperBound | Valeur maximale de la colonne de partition à partir de laquelle copier des données. S’applique lorsque de l’option de partition est DynamicRange. Si vous avez recours à une requête pour récupérer des données sources, utilisez ?AdfRangePartitionUpbound dans la clause WHERE. Pour consulter un exemple, voir Copie en parallèle à partir de Teradata. |
Non |
| partitionLowerBound | Valeur minimale de la colonne de partition à partir de laquelle copier des données. S’applique lorsque l’option de partitionnement est DynamicRange. Si vous utilisez une requête pour récupérer des données sources, utilisez ?AdfRangePartitionLowbound dans la clause WHERE. Pour consulter un exemple, voir Copie en parallèle à partir de Teradata. |
Non |
Notes
La source de copie de type RelationalSource est toujours prise en charge, mais ne gère pas la nouvelle charge en parallèle intégrée à partir de Teradata (options de partition). Toutefois, nous vous recommandons d’utiliser le nouveau jeu de données.
Exemple : copie de données à l’aide de la requête de base sans partition
"activities":[
{
"name": "CopyFromTeradata",
"type": "Copy",
"inputs": [
{
"referenceName": "<Teradata input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Copie en parallèle à partir de Teradata
Le connecteur Teradata propose un partitionnement de données intégré pour copier des données à partir de Teradata, en parallèle. Vous trouverez des options de partitionnement de données dans la table Source de l’activité de copie.

Lorsque vous activez la copie partitionnée, le service exécute des requêtes en parallèle sur votre source Teradata pour charger des données par partitions. Le degré de parallélisme est contrôlé via le paramètre parallelCopies sur l’activité de copie. Par exemple, si vous définissez parallelCopies sur la valeur quatre, le service génère et exécute simultanément quatre requêtes selon l’option de partition et les paramètres que vous avez spécifiés, chacune récupérant une partie des données de votre Teradata.
Il vous est recommandé d’activer la copie en parallèle avec partitionnement des données notamment lorsque vous chargez une grande quantité de données à partir de Teradata. Voici quelques suggestions de configurations pour différents scénarios. Lors de la copie de données dans un magasin de données basé sur un fichier, il est recommandé d’écrire les données dans un dossier sous la forme de plusieurs fichiers (spécifiez uniquement le nom du dossier). Les performances seront meilleures qu’avec l’écriture de données dans un seul fichier.
| Scénario | Paramètres suggérés |
|---|---|
| Chargement complet à partir d’une table volumineuse. | Option de partition : Hachage. Lors de l’exécution, le service détecte automatiquement la colonne d’index principale, y applique un hachage et copie les données par partitions. |
| Chargez une grande quantité de données à l’aide d’une requête personnalisée. | Option de partition : Hachage. Requête: SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>.Colonne de partition : Spécifiez la colonne utilisée pour appliquer la partition par hachage. Si cette colonne n’est pas spécifiée, le service détecte automatiquement la colonne PK de la table que vous avez spécifiée dans le jeu de données Teradata. Lors de l’exécution, le service remplace ?AdfHashPartitionCondition par la logique de partition de hachage et l’envoie à Teradata. |
| Chargez une grande quantité de données à l’aide d’une requête personnalisée, qui dispose d’une colonne d’entiers avec valeur uniformément distribuée pour le partitionnement par plages de valeurs. | Options de partition : Partition dynamique par spécification de plages de valeurs. Requête: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Colonne de partition : Spécifiez la colonne utilisée pour partitionner les données. Vous pouvez procéder au partitionnement par rapport à la colonne avec le type de données entier. Limite supérieure de partition et limite inférieure de partition : Indiquez si vous souhaitez filtrer le contenu par rapport à la colonne de partition pour récupérer uniquement les données entre les plages inférieure et supérieure. Lors de l’exécution, le service remplace ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound et ?AdfRangePartitionLowbound par le nom réel de la colonne et les plages de valeurs de chaque partition et les envoie à Teradata. Par exemple, si votre colonne de partition « ID » est définie sur une limite inférieure de 1 et une limite supérieure de 80, avec une copie en parallèle définie sur 4, le service récupère les données via 4 partitions. Les ID sont inclus entre [1,20], [21, 40], [41, 60] et [61, 80], respectivement. |
Exemple : requête avec partition par hachage
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>",
"partitionOption": "Hash",
"partitionSettings": {
"partitionColumnName": "<hash_partition_column_name>"
}
}
Exemple : requête avec partition dynamique par spécification de plages de valeurs
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Mappage de type de données pour Teradata
Lorsque vous copiez des données à partir de Teradata, les mappages suivants s’appliquent à partir des types de données de Teradata aux types de données internes utilisés par le service. Pour découvrir comment l’activité de copie mappe le schéma et le type de données la source au récepteur, consultez Mappage de schéma dans l’activité de copie.
| Type de données Teradata | Type de données de service intermédiaire |
|---|---|
| BigInt | Int64 |
| Objet blob | Byte[] |
| Byte | Byte[] |
| ByteInt | Int16 |
| Char | String |
| Clob | String |
| Date | DateTime |
| Decimal | Decimal |
| Double | Double |
| Graphic | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Integer | Int32 |
| Interval Day | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Day To Hour | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Day To Minute | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Day To Second | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Hour | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Hour To Minute | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Hour To Second | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Minute | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Minute To Second | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Month | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Second | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Year | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Interval Year To Month | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Number | Double |
| Période (date) | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Période (heure) | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Période (heure avec fuseau horaire) | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Période (timestamp) | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Période (timestamp avec fuseau horaire) | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| SmallInt | Int16 |
| Temps | TimeSpan |
| Time With Time Zone | TimeSpan |
| Timestamp | DateTime |
| Timestamp With Time Zone | DateTime |
| VarByte | Byte[] |
| VarChar | String |
| VarGraphic | Non pris en charge. Appliquer un cast explicite dans la requête source. |
| Xml | Non pris en charge. Appliquer un cast explicite dans la requête source. |
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Contenu connexe
Consultez les magasins de données pris en charge pour obtenir la liste des sources et magasins de données pris en charge en tant que récepteurs par l’activité de copie.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour