Déboguez des applications Apache Spark sur un cluster HDInsight avec le kit de ressources Azure pour IntelliJ via SSH
Cet article propose des instructions étape par étape sur la façon d’utiliser HDInsight Tools dans le kit de ressources Azure pour IntelliJ afin de déboguer des applications à distance sur un cluster HDInsight.
Prérequis
Un cluster Apache Spark sur HDInsight. Consultez Créer un cluster Apache Spark.
Pour les utilisateurs Windows : Quand vous exécutez l’application Spark Scala locale sur un ordinateur Windows, vous pouvez obtenir une exception, comme l’explique le document SPARK-2356. Cette exception est liée à l’absence du fichier WinUtils.exe sur Windows.
Pour résoudre cette erreur, téléchargez le fichier Winutils.exe à un emplacement tel que C:\WinUtils\bin. Ajoutez ensuite la variable d’environnement HADOOP_HOME et définissez la valeur de la variable sur C:\WinUtils.
IntelliJ IDEA (l’édition Community est gratuite.).
Un client SSH. Pour plus d’informations, consultez Se connecter à HDInsight (Apache Hadoop) à l’aide de SSH.
Créer une application Spark Scala
Démarrez IntelliJ IDEA, puis sélectionnez Create New Project (Créer un projet) pour ouvrir la fenêtre New Project (Nouveau projet).
Sélectionnez Apache Spark/HDInsight dans le volet gauche.
Sélectionnez Spark Project avec exemples (Scala) [Projet Spark (Scala)] dans la fenêtre principale.
Dans la liste déroulante Build tool (Outil de build), sélectionnez l’un des outils suivants :
- Maven pour la prise en charge de l’Assistant de création de projets Scala.
- SBT pour gérer les dépendances et la génération du projet Scala.
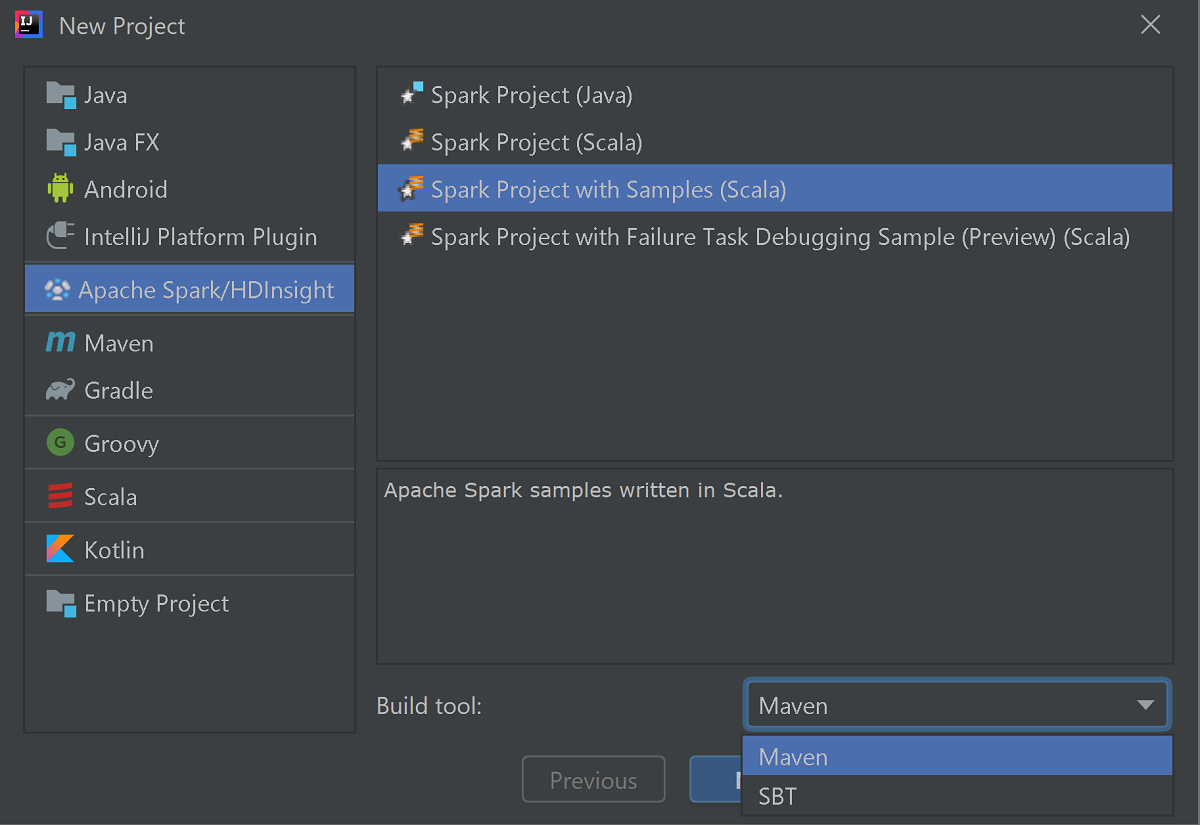
Cliquez sur Suivant.
Dans la fenêtre suivante New Project (Nouveau projet), entrez les informations suivantes :
Propriété Description Nom du projet Entrez un nom. Cette procédure utilise myApp.Emplacement du projet Entrez l’emplacement où vous souhaitez enregistrer votre projet. Project SDK (SDK du projet) Si vide, sélectionnez New... (Nouveau) et accédez à votre JDK. Version de Spark L’Assistant de création intègre la version correcte des SDK Spark et Scala. Si la version du cluster Spark est antérieure à la version 2.0, sélectionnez Spark 1.x. Sinon, sélectionnez Spark 2.x. . Cet exemple utilise Spark 2.3.0 (Scala 2.11.8) . 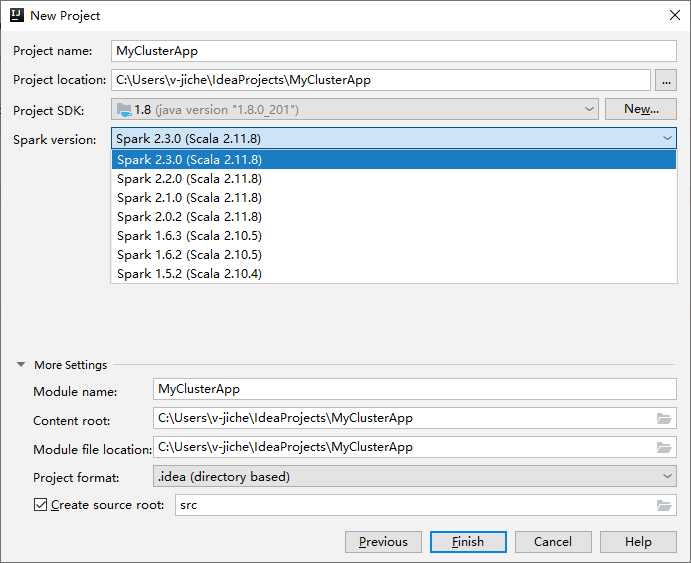
Sélectionnez Terminer. Vous devrez peut-être patienter quelques minutes avant que le projet soit disponible. La progression s’affiche dans l’angle inférieur droit.
Développez votre projet et accédez à src>main>scala>sample. Double-cliquez sur SparkCore_WasbIOTest.
Effectuer une exécution locale
Dans le script SparkCore_wasbloTest, cliquez avec le bouton droit sur l’éditeur de script, puis sélectionnez l’option SparkCore_WasbIOTest pour effectuer l’exécution locale.
Une fois l’exécution locale terminée, vous pouvez voir le fichier de sortie enregistré dans l’Explorateur de votre projet actuel data>default .
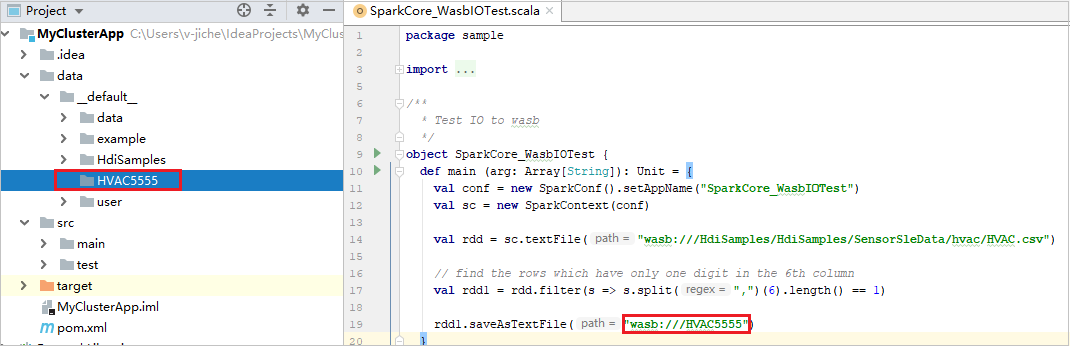
Nos outils définissent la configuration de l’exécution locale par défaut automatiquement lorsque vous effectuez l’exécution et le débogage locaux. Ouvrez la configuration [Spark on HDInsight] XXX en haut à droite. Comme vous pouvez le voir, la configuration [Spark on HDInsight]XXX est déjà créée sous Apache Spark on HDInsight. Basculez vers l’onglet Locally Run (Exécuter localement) .
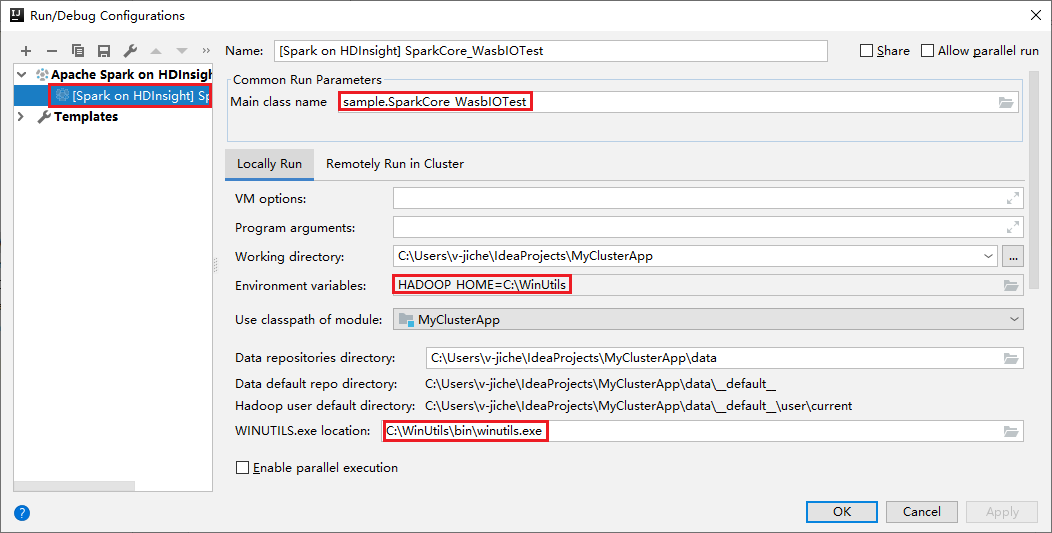
- Variables d’environnement : si vous avez déjà défini la variable d’environnement système HADOOP_HOME sur C:\WinUtils, elle peut détecter automatiquement qu’aucun ajout manuel n’est nécessaire.
- Emplacement de WinUtils.exe : si vous n’avez pas défini la variable d’environnement système, vous pouvez trouver l’emplacement en cliquant sur son bouton.
- Choisissez simplement l’une des deux options ; elles ne sont pas requises sur MacOS et Linux.
Vous pouvez également définir la configuration manuellement avant d’effectuer l’exécution et le débogage locaux. Dans la capture d’écran précédente, sélectionnez le signe plus ( + ). Sélectionnez ensuite l’option Apache Spark on HDInsight. Entrez les informations de Nom et Nom de la classe principale à enregistrer, puis cliquez sur le bouton d’exécution locale.
Effectuer un débogage local
Ouvrez le script SparkCore_wasbloTest, et définissez les points d’arrêt.
Cliquez avec le bouton droit sur l’éditeur de script, puis sélectionnez l’option Debug '[Spark on HDInsight]XXX' pour effectuer le débogage local.
Effectuer une exécution à distance
Accédez à Exécuter>Modifier les configurations... . Dans ce menu, vous pouvez créer ou modifier les configurations pour le débogage à distance.
Dans la boîte de dialogue Run/Debug Configurations (Exécuter/Déboguer les configurations) sélectionnez le signe plus ( + ). Sélectionnez ensuite l’option Apache Spark on HDInsight.

Basculez vers l’onglet Remotely Run in Cluster (Exécuter à distance dans le cluster) . Entrez les informations sur le Nom, le Cluster Spark et le Nom principal de la classe. Cliquez ensuite sur Advanced configuration (Remote Debugging) [Configuration avancée (Débogage à distance)]. Nos outils prennent en charge le débogage avec Exécuteurs. Pour numExectors, la valeur par défaut est 5. Il est déconseillé de définir une valeur supérieure à 3.
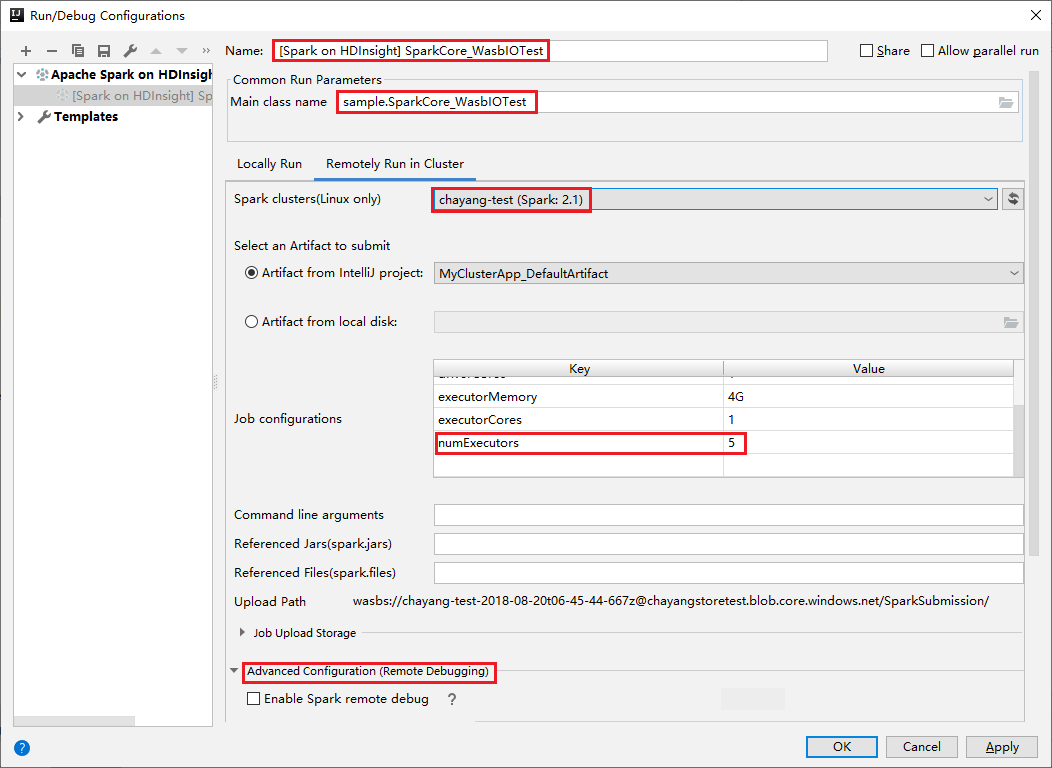
Dans la section Advanced Configuration (Remote Debugging) , sélectionnez Enable Spark remote debug. Entrez le nom d’utilisateur SSH, puis entrez un mot de passe ou utilisez un fichier de clé privée. Si vous souhaitez effectuer le débogage à distance, vous devez définir cette option. Par contre, cette action n’est pas nécessaire si vous souhaitez simplement utiliser l’exécution à distance.
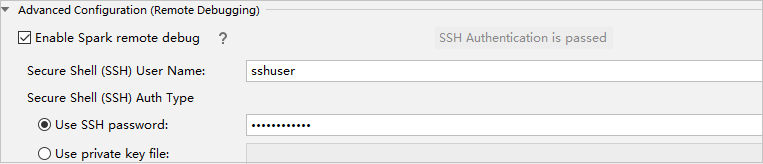
La configuration est maintenant enregistrée avec le nom fourni. Pour afficher les détails de configuration, sélectionnez le nom de configuration. Pour apporter des modifications, sélectionnez Modifier les configurations.
Une fois le paramétrage des configurations terminé, vous pouvez exécuter le projet sur le cluster à distance ou effectuer un débogage à distance.

Cliquez sur le bouton Déconnecter si les journaux d’activité d’envoi n’apparaissent pas dans le panneau gauche. Toutefois, une exécution a toujours lieu sur le serveur principal.
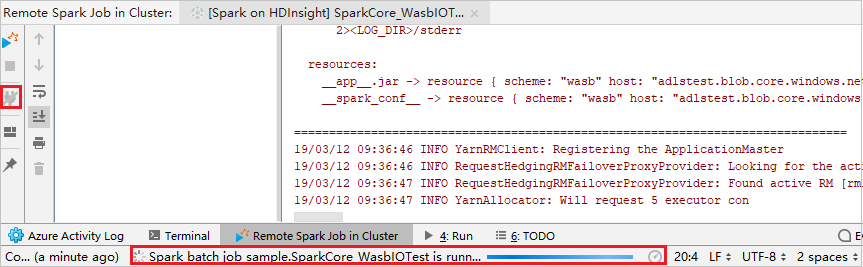
Effectuer un débogage à distance
Configurez des points de rupture, puis sélectionnez l’icône Débogage distant. La différence avec la soumission à distance est que le nom d’utilisateur/mot de passe SSH doit être configuré.

Quand l’exécution du programme atteint le point de rupture, un onglet Pilote et deux onglets Exécuteur s’affichent dans le volet Débogueur. Sélectionnez l’icône Reprendre le programme pour continuer à exécuter le code ; le point de rupture suivant est alors atteint. Vous devez basculer vers l’onglet Exécuteur correct pour trouver l’exécuteur cible à déboguer. Vous pouvez consulter les journaux d’activité d’exécution sous l’onglet Console correspondant.
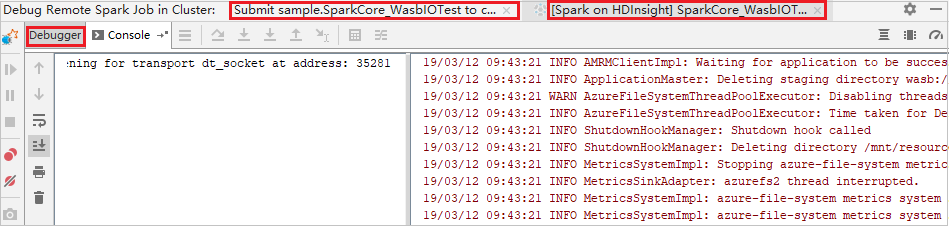
Effectuer un débogage et une résolution des bogues à distance
Configurez deux points de rupture, puis sélectionnez l’icône Déboguer pour démarrer le processus de débogage à distance.
Le code s’arrête au premier point de rupture et les informations sur les paramètres et les variables s’affichent dans le volet Variable.
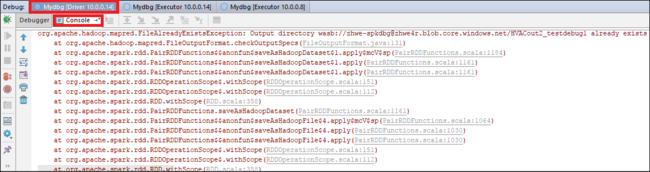
Sélectionnez l’icône Reprendre le programme pour continuer. Le code s’arrête au deuxième point. L’exception est interceptée comme prévu.
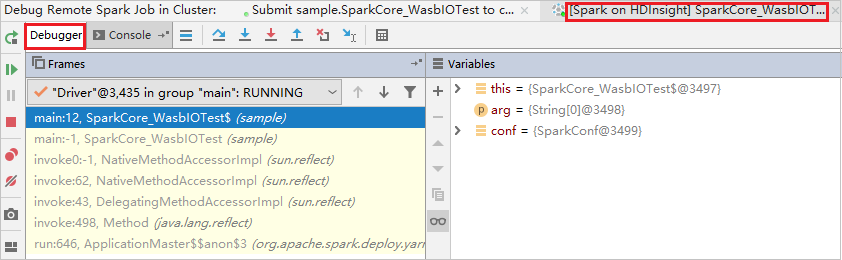
Resélectionnez l’icône Reprendre le programme. La fenêtre Soumission HDInsight Spark affiche une erreur d’exécution de tâche.
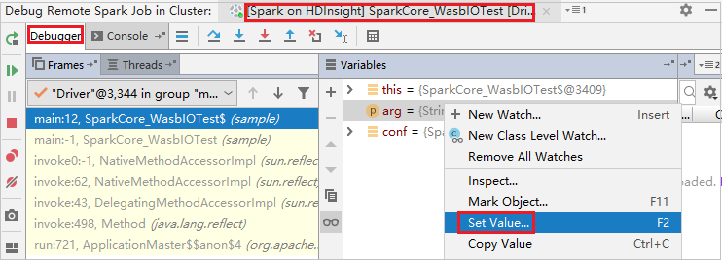
Pour mettre à jour dynamiquement la valeur de la variable à l’aide de la fonctionnalité de débogage IntelliJ, resélectionnez Déboguer. Le volet Variables réapparaît.
Cliquez avec le bouton droit de la cible de l’onglet Déboguer, puis sélectionnez Définir la valeur. Ensuite, entrez une nouvelle valeur pour la variable. Puis sélectionnez Entrer pour enregistrer la valeur.
Sélectionnez l’icône Reprendre le programme pour continuer à exécuter le programme. Cette fois-ci, aucune exception n’est interceptée. Vous pouvez voir que le projet s’exécute correctement sans aucune exception.

Étapes suivantes
Scénarios
- Apache Spark avec BI : Effectuer une analyse interactive des données à l’aide de Spark dans HDInsight avec les outils décisionnels
- Apache Spark avec Machine Learning : utiliser Spark dans HDInsight pour analyser la température de bâtiments à l’aide des données des systèmes HVAC
- Apache Spark avec Machine Learning : utiliser Spark dans HDInsight pour prédire les résultats de l’inspection d’aliments
- Analyse des journaux de site web à l’aide d’Apache Spark dans HDInsight
Création et exécution d’applications
- Créer une application autonome avec Scala
- Exécuter des tâches à distance avec Apache Livy sur un cluster Apache Spark
Outils et extensions
- Utiliser Azure Toolkit for IntelliJ afin de créer des applications Apache Spark pour un cluster HDInsight
- Utiliser Azure Toolkit for IntelliJ pour déboguer des applications Apache Spark à distance par VPN
- Utiliser HDInsight Tools dans Azure Toolkit for Eclipse pour créer des applications Apache Spark
- Utiliser des blocs-notes Apache Zeppelin avec un cluster Apache Spark sur HDInsight
- Noyaux disponibles pour Jupyter Notebook dans le cluster Apache Spark pour HDInsight
- Utiliser des packages externes avec des blocs-notes Jupyter
- Install Jupyter on your computer and connect to an HDInsight Spark cluster (Installer Jupyter sur un ordinateur et se connecter au cluster Spark sur HDInsight)