Interaktív adatkonvergálás az Apache Sparkkal az Azure Machine-Tanulás
Az adatmeghatolás a gépi tanulási projektek egyik legfontosabb lépésévé válik. Az Azure Machine Tanulás integrációja az Azure Synapse Analyticsszel hozzáférést biztosít az Azure Synapse által támogatott Apache Spark-készlethez az Azure Machine Tanulás Notebooks használatával történő interaktív adatátszervezéshez.
Ebből a cikkből megtudhatja, hogyan végezhet adat-rendezést az
- Kiszolgáló nélküli Spark-számítás
- Csatolt Synapse Spark-készlet
Előfeltételek
- Azure-előfizetés; ha nem rendelkezik Azure-előfizetéssel, a kezdés előtt hozzon létre egy ingyenes fiókot .
- Egy Azure Machine Learning-munkaterület. Lásd: Munkaterület-erőforrások létrehozása.
- Egy Azure Data Lake Storage (ADLS) Gen 2-tárfiók. Lásd: Azure Data Lake Storage (ADLS) Gen 2- tárfiók létrehozása.
- (Nem kötelező): Azure Key Vault. Lásd: Azure Key Vault létrehozása.
- (Nem kötelező): Szolgáltatásnév. Lásd: Szolgáltatásnév létrehozása.
- (Nem kötelező): Csatolt Synapse Spark-készlet az Azure Machine Tanulás-munkaterületen.
Mielőtt elkezdené az adatátszervezési feladatokat, ismerkedjen meg a titkos kulcsok tárolásának folyamatával
- Azure Blob Storage-fiók hozzáférési kulcsa
- Közös hozzáférésű jogosultságkód (SAS) jogkivonat
- Az Azure Data Lake Storage (ADLS) Gen 2 szolgáltatásnévre vonatkozó információi
az Azure Key Vaultban. Azt is tudnia kell, hogyan kezelheti a szerepkör-hozzárendeléseket az Azure Storage-fiókokban. A következő szakaszok ezeket a fogalmakat tekintik át. Ezután az Azure Machine Tanulás Notebooks Spark-készleteinek használatával megismerheti az interaktív adatmegrendezés részleteit.
Tipp.
Az Azure Storage-fiók szerepkör-hozzárendelési konfigurációjáról, vagy ha felhasználói identitásátadással fér hozzá a tárfiókjaiban lévő adatokhoz, olvassa el a szerepkör-hozzárendelések hozzáadása az Azure Storage-fiókokban című témakört.
Interaktív adatkonvergálás az Apache Sparkkal
Az Azure Machine Tanulás kiszolgáló nélküli Spark-számítást és csatlakoztatott Synapse Spark-készletet kínál az Azure Machine-Tanulás Notebookokban található Apache Spark interaktív adatkonvergálásához. A kiszolgáló nélküli Spark-számításhoz nem szükséges erőforrások létrehozása az Azure Synapse-munkaterületen. Ehelyett egy teljes mértékben felügyelt kiszolgáló nélküli Spark-számítás közvetlenül elérhetővé válik az Azure Machine Tanulás notebookokban. A kiszolgáló nélküli Spark-számítás használata a legegyszerűbb módszer a Spark-fürtök Azure Machine-Tanulás való elérésére.
Kiszolgáló nélküli Spark-számítás az Azure Machine Tanulás Notebookokban
Alapértelmezés szerint egy kiszolgáló nélküli Spark-számítás érhető el az Azure Machine Tanulás Notebooksban. Ha egy jegyzetfüzetben szeretné elérni, válassza a Kiszolgáló nélküli Spark Compute lehetőséget az Azure Machine Tanulás Kiszolgáló nélküli Spark alatt a Számítási kijelölés menüből.
A Jegyzetfüzetek felhasználói felülete a Spark-munkamenet konfigurálásának lehetőségeit is biztosítja a kiszolgáló nélküli Spark-számításhoz. Spark-munkamenet konfigurálása:
- Válassza a munkamenet konfigurálása lehetőséget a képernyő tetején.
- Válassza ki az Apache Spark-verziót a legördülő menüből.
Fontos
Azure Synapse Runtime for Apache Spark: Announcements
- Azure Synapse Runtime for Apache Spark 3.2:
- EOLA közlemény dátuma: 2023. július 8.
- Támogatási dátum vége: 2024. július 8. A dátum után a futtatókörnyezet le lesz tiltva.
- A folyamatos támogatás és az optimális teljesítmény érdekében javasoljuk, hogy migráljon az Apache Spark 3.3-ra.
- Azure Synapse Runtime for Apache Spark 3.2:
- Válassza a Példánytípus lehetőséget a legördülő menüben. Jelenleg a következő példánytípusok támogatottak:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Adjon meg egy Spark-munkamenet időtúllépési értékét percben.
- Válassza ki, hogy dinamikusan lefoglalja-e a végrehajtókat
- Válassza ki a Spark-munkamenet végrehajtóinak számát.
- Válassza a Végrehajtó mérete lehetőséget a legördülő menüben.
- Válassza az Illesztőprogram mérete lehetőséget a legördülő menüben.
- Ha Conda-fájlt szeretne használni a Spark-munkamenet konfigurálásához, jelölje be a Conda-fájl feltöltése jelölőnégyzetet. Ezután válassza a Tallózás lehetőséget, és válassza ki a Kívánt Spark-munkamenet-konfigurációval rendelkező Conda-fájlt.
- Adja hozzá a konfigurációs beállítások tulajdonságait, a bemeneti értékeket a Tulajdonság és az Érték szövegmezőkben, és válassza a Hozzáadás lehetőséget.
- Válassza az Alkalmazás lehetőséget.
- Válassza a Munkamenet leállítása lehetőséget az Új munkamenet konfigurálása előugró ablakban.
A munkamenetkonfiguráció módosításai megmaradnak, és elérhetővé válnak egy másik jegyzetfüzet-munkamenet számára, amely a kiszolgáló nélküli Spark-számítással kezdődött.
Tipp.
Ha munkamenetszintű Conda-csomagokat használ, javíthatja a Spark-munkamenet hideg kezdési idejét, ha igazra állítja a konfigurációs változótspark.hadoop.aml.enable_cache. A munkamenet hideg kezdése a munkamenetszintű Conda-csomagokkal általában 10–15 percet vesz igénybe, amikor a munkamenet első alkalommal elindul. Az ezt követő munkamenet hidegben azonban a konfigurációs változó igaz értékre állításával kezdődik, amely általában 3-5 percet vesz igénybe.
Adatok importálása és leküldése az Azure Data Lake Storage-ból (ADLS) Gen 2
Az Azure Data Lake Storage (ADLS) Gen 2 storage-fiókokban tárolt adatokat a két adatelérési mechanizmus egyikét követve érheti el és helyezheti el az adat URL-címeivel abfss:// :
- Felhasználói identitás átadása
- Szolgáltatásnév-alapú adathozzáférés
Tipp.
A kiszolgáló nélküli Spark-számítással való adatátengedés és a felhasználói identitás átadása az Azure Data Lake Storage (ADLS) Gen 2 storage-fiók adatainak eléréséhez a legkisebb számú konfigurációs lépést igényli.
Az interaktív adatátengedés elindítása a felhasználói identitás átadásával:
Ellenőrizze, hogy a felhasználói identitás rendelkezik-e közreműködői és tárolási blobadat-közreműködőiszerepkör-hozzárendelésekkel az Azure Data Lake Storage (ADLS) Gen 2 storage-fiókban.
A kiszolgáló nélküli Spark-számítás használatához válassza a Kiszolgáló nélküli Spark Computelehetőséget az Azure Machine Tanulás Kiszolgáló nélküli Spark alatt a Számítási kijelölés menüből.
Csatolt Synapse Spark-készlet használatához válasszon ki egy csatolt Synapse Spark-készletet a Synapse Spark-készletek alatt a Számítási kijelölés menüből.
Ez a Titanic-adatküldő kódminta egy adat URI használatát mutatja be a következő
pyspark.pandasformátumbanabfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>: éspyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Feljegyzés
Ez a Python-kódminta a következőt használja
pyspark.pandas: . Ezt csak a Spark 3.2-es vagy újabb verziója támogatja.
Adatok leküldése szolgáltatásnéven keresztüli hozzáféréssel:
Ellenőrizze, hogy a szolgáltatásnév rendelkezik-e közreműködői és tárolási blobadat-közreműködőiszerepkör-hozzárendelésekkel az Azure Data Lake Storage (ADLS) Gen 2 storage-fiókban.
Azure Key Vault-titkos kulcsokat hozhat létre a szolgáltatásnév bérlőazonosítójának, ügyfélazonosítójának és titkos ügyfélkulcs-értékeinek.
Válassza ki a Kiszolgáló nélküli Spark-számítást az Azure Machine Tanulás Kiszolgáló nélküli Spark alatt a Számítási kijelölés menüből, vagy válasszon ki egy csatolt Synapse Spark-készletet a Synapse Spark-készletek alatt a Számítási kijelölés menüből.
A szolgáltatásnév bérlőazonosítójának, ügyfélazonosítójának és titkos ügyfélkulcsának beállításához és a következő kódminta végrehajtásához.
A
get_secret()kódban szereplő hívás az Azure Key Vault nevétől és a szolgáltatásnév bérlőazonosítója, ügyfélazonosítója és ügyféltitkához létrehozott Azure Key Vault-titkos kulcsok nevétől függ. Adja meg a megfelelő tulajdonságnevet/értékeket a konfigurációban:- Ügyfélazonosító tulajdonság:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Titkos ügyféltulajdonság:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Bérlőazonosító tulajdonság:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Bérlőazonosító értéke:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- Ügyfélazonosító tulajdonság:
Adatok importálása és leküldése adat URI használatával a kódmintában látható módon
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>, a Titanic-adatok használatával.
Adatok importálása és leküldése az Azure Blob Storage-ból
Az Azure Blob Storage-adatokat a tárfiók hozzáférési kulcsával vagy egy közös hozzáférésű jogosultságkód (SAS) jogkivonattal érheti el. Ezeket a hitelesítő adatokat titkos kulcsként kell tárolnia az Azure Key Vaultban, és tulajdonságokként kell beállítania őket a munkamenet-konfigurációban.
Interaktív adatmegrendezés indítása:
Az Azure Machine Tanulás studio bal oldali paneljén válassza a Jegyzetfüzetek lehetőséget.
Válassza ki a Kiszolgáló nélküli Spark-számítást az Azure Machine Tanulás Kiszolgáló nélküli Spark alatt a Számítási kijelölés menüből, vagy válasszon ki egy csatolt Synapse Spark-készletet a Synapse Spark-készletek alatt a Számítási kijelölés menüből.
A tárfiók hozzáférési kulcsának vagy a közös hozzáférésű jogosultságkód (SAS) jogkivonatának konfigurálása adathozzáféréshez az Azure Machine Tanulás-jegyzetfüzetekben:
A hozzáférési kulcshoz állítsa be a tulajdonságot
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.neta kódrészletben látható módon:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )Az SAS-jogkivonathoz állítsa be a tulajdonságot
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.neta kódrészletben látható módon:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Feljegyzés
A
get_secret()fenti kódrészletekben szereplő hívásokhoz szükség van az Azure Key Vault nevére, valamint az Azure Blob Storage-fiók hozzáférési kulcsához vagy SAS-jogkivonatához létrehozott titkos kódok nevére
Hajtsa végre az adatküldő kódot ugyanabban a jegyzetfüzetben. Formázza az adat URI-t
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>a kódrészlethez hasonlóan:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Feljegyzés
Ez a Python-kódminta a következőt használja
pyspark.pandas: . Ezt csak a Spark 3.2-es vagy újabb verziója támogatja.
Adatok importálása és leküldése az Azure Machine Tanulás Datastore-ból
Ha az Azure Machine Tanulás Datastore-ból szeretne adatokat elérni, adjon meg egy elérési utat az adattár adataihoz URI formátumbanazureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>. Adatok interaktív módon való leküldése egy Azure Machine Tanulás Datastore-ból egy Jegyzetfüzet-munkamenetben:
Válassza ki a Kiszolgáló nélküli Spark-számítást az Azure Machine Tanulás Kiszolgáló nélküli Spark alatt a Számítási kijelölés menüből, vagy válasszon ki egy csatolt Synapse Spark-készletet a Synapse Spark-készletek alatt a Számítási kijelölés menüből.
Ez a kódminta bemutatja, hogyan olvashatók be és távolíthat el Titanic-adatokat egy Azure Machine Tanulás Datastore-ból az
azureml://adattár URIpyspark.pandaséspyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Feljegyzés
Ez a Python-kódminta a következőt használja
pyspark.pandas: . Ezt csak a Spark 3.2-es vagy újabb verziója támogatja.
Az Azure Machine Tanulás-adattárak az Azure Storage-fiók hitelesítő adataival férhetnek hozzá az adatokhoz
- hozzáférési kulcs
- SAS-jogkivonat
- szolgáltatásnév
vagy hitelesítőadat-ritkábban biztosítson adathozzáférést. Az adattár típusától és az alapul szolgáló Azure Storage-fiók típusától függően válasszon ki egy megfelelő hitelesítési mechanizmust az adathozzáférés biztosításához. Ez a táblázat az Azure Machine-Tanulás-adattárakban lévő adatok elérésére szolgáló hitelesítési mechanizmusokat foglalja össze:
* A felhasználói identitás átadása az Azure Blob Storage-fiókokra mutató hitelesítő adatok nélküli adattárak esetében működik, csak akkor, ha a helyreállítható törlés nincs engedélyezve.
Adatok elérése az alapértelmezett fájlmegosztáson
Az alapértelmezett fájlmegosztás a kiszolgáló nélküli Spark-számításhoz és a csatolt Synapse Spark-készletekhez is csatlakoztatva van.
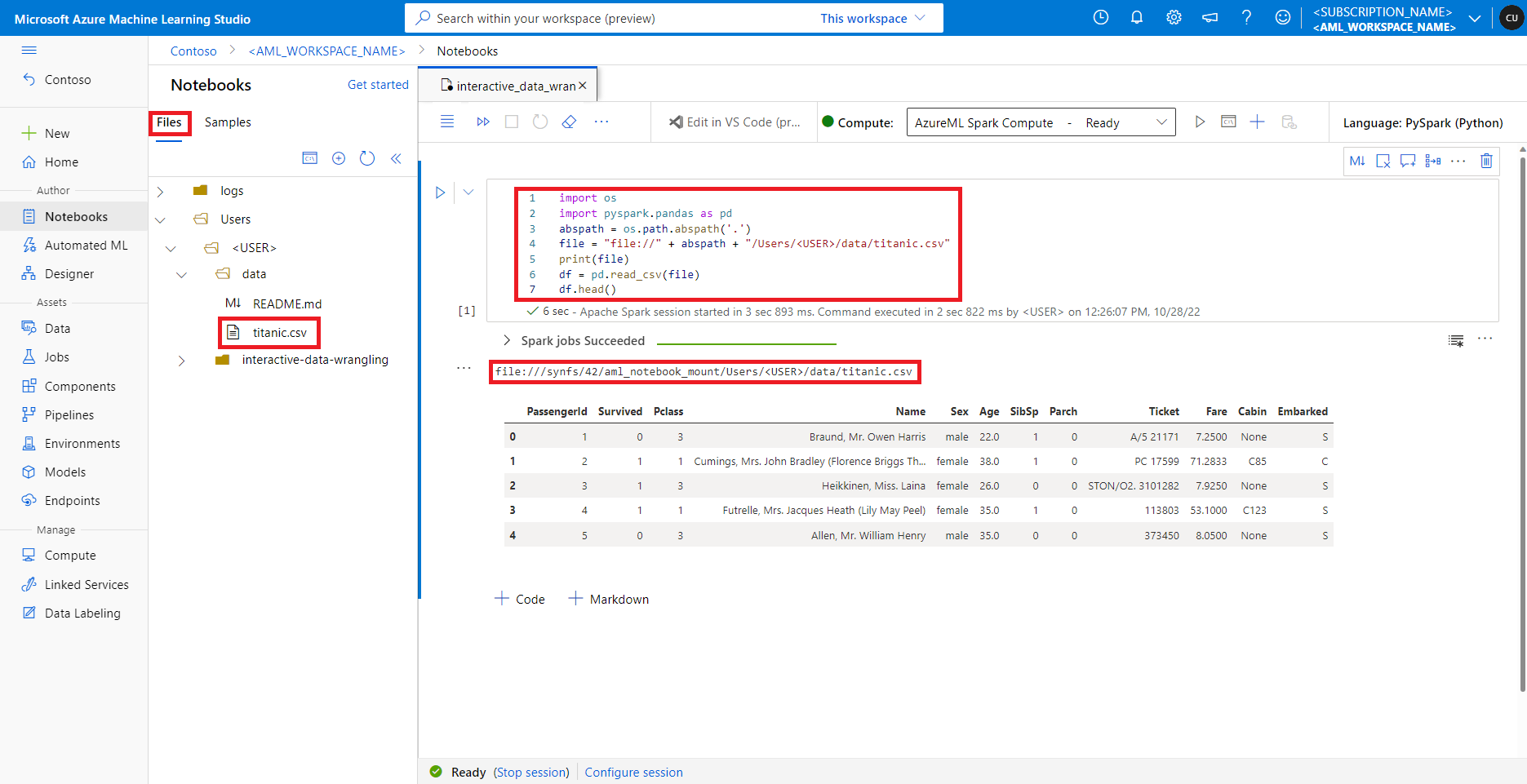
Az Azure Machine Tanulás Studióban az alapértelmezett fájlmegosztásban lévő fájlok a Fájlok lap könyvtárfája alatt jelennek meg. A jegyzetfüzetkód a fájlmegosztásban tárolt fájlokat közvetlenül, protokollalfile://, a fájl abszolút elérési útjával együtt, további konfigurációk nélkül is elérheti. Ez a kódrészlet bemutatja, hogyan férhet hozzá az alapértelmezett fájlmegosztáson tárolt fájlokhoz:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Feljegyzés
Ez a Python-kódminta a következőt használja pyspark.pandas: . Ezt csak a Spark 3.2-es vagy újabb verziója támogatja.