Apa itu Analisis Gambar?
Layanan Analisis Gambar Visi Komputer dapat mengekstrak berbagai fitur visual dari gambar Anda. Misalnya, layanan ini dapat menentukan bahwa gambar berisi konten dewasa atau tidak, menemukan merek atau objek tertentu, atau menemukan wajah manusia.
Versi terbaru dari Analisis Gambar, 4.0, yang sekarang dalam ketersediaan umum, memiliki fitur baru seperti OCR sinkron dan deteksi orang. Kami sarankan Anda menggunakan versi ini ke depannya.
Anda dapat menggunakan Image Analysis melalui SDK pustaka klien atau dengan memanggil REST API secara langsung. Ikuti mulai cepat untuk memulai.
Atau, Anda dapat mencoba kemampuan Analisis Gambar dengan cepat dan mudah di browser menggunakan Vision Studio.
Dokumentasi ini berisi jenis artikel berikut ini:
- Mulai cepat adalah instruksi langkah demi langkah yang memungkinkan Anda membuat panggilan ke layanan dan mendapatkan hasil dalam waktu singkat.
- Panduan cara berisi instruksi untuk menggunakan layanan dengan cara yang lebih spesifik atau yang disesuaikan.
- Artikel konseptual ini memberikan penjelasan mendalam tentang fungsionalitas dan fitur layanan tersebut.
Untuk pendekatan yang lebih terstruktur, ikuti modul Pelatihan untuk Analisis Gambar.
Versi Analisis Gambar
Penting
Pilih versi API Analisis Gambar yang paling sesuai dengan kebutuhan Anda.
| Versi | Fitur yang tersedia | Rekomendasi |
|---|---|---|
| versi 4.0 | Baca teks, Keterangan, Keterangan padat, Tag, Deteksi objek, Klasifikasi gambar kustom/ deteksi objek, Orang, Pemangkasan cerdas | Model yang lebih baik; gunakan versi 4.0 jika mendukung kasus penggunaan Anda. |
| versi 3.2 | Tag, Objek, Deskripsi, Merek, Wajah, Jenis gambar, Skema warna, Tengara, Selebriti, Konten dewasa, Pemangkasan cerdas | Berbagai fitur yang lebih luas; gunakan versi 3.2 jika kasus penggunaan Anda belum didukung di versi 4.0 |
Sebaiknya gunakan API Analisis Gambar 4.0 jika mendukung kasus penggunaan Anda. Gunakan versi 3.2 jika kasus penggunaan Anda belum didukung oleh 4.0.
Anda juga harus menggunakan versi 3.2 jika Anda ingin melakukan keterangan gambar dan sumber daya Visi Anda berada di luar wilayah Azure yang didukung. Fitur keterangan gambar di Analisis Gambar 4.0 hanya didukung di wilayah Azure tertentu. Keterangan gambar di versi 3.2 tersedia di semua wilayah Azure AI Vision. Lihat Ketersediaan wilayah.
Analisis Gambar
Anda dapat menganalisis gambar untuk mendapatkan wawasan tentang fitur dan karakteristik visual mereka. Semua fitur dalam tabel ini disediakan oleh Analyze Image API. Ikuti mulai cepat untuk memulai.
| Nama | Deskripsi | Halaman konsep |
|---|---|---|
| Kustomisasi model (hanya pratinjau v4.0) (tidak digunakan lagi) | Anda dapat membuat dan melatih model kustom untuk melakukan klasifikasi gambar atau deteksi objek. Bawa gambar Anda sendiri, beri label dengan tag kustom, dan Analisis Gambar melatih model yang disesuaikan untuk kasus penggunaan Anda. | Kustomisasi model |
| Membaca teks dari gambar (hanya v4.0) | Pratinjau Analisis Gambar versi 4.0 menawarkan kemampuan untuk mengekstrak teks yang dapat dibaca dari gambar. Dibandingkan dengan API Baca Computer 3.2 Asinkron, versi baru menawarkan mesin Read OCR yang akrab dalam API sinkron yang ditingkatkan performa terpadu yang memudahkan untuk mendapatkan OCR bersama dengan wawasan lain dalam satu panggilan API. | OCR untuk gambar |
| Mendeteksi orang dalam gambar (hanya v4.0) | Analisis Gambar versi 4.0 menawarkan kemampuan untuk mendeteksi orang yang muncul dalam gambar. Koordinat kotak pembatas dari setiap orang yang terdeteksi dikembalikan, bersama dengan skor keyakinan. | Deteksi orang |
| Hasilkan keterangan gambar | Hasilkan keterangan gambar dalam bahasa yang dapat dibaca manusia, menggunakan kalimat lengkap. Algoritma Computer Vision menghasilkan keterangan berdasarkan objek yang diidentifikasi dalam gambar. Model keterangan gambar versi 4.0 adalah implementasi yang lebih canggih dan bekerja dengan berbagai gambar input yang lebih luas. Ini hanya tersedia di wilayah geografis tertentu. Lihat Ketersediaan wilayah. Versi 4.0 juga memungkinkan Anda menggunakan keterangan padat, yang menghasilkan keterangan terperinci untuk objek individual yang ditemukan dalam gambar. API mengembalikan koordinat kotak pembatas (dalam piksel) dari setiap objek yang ditemukan dalam gambar, ditambah keterangan. Anda dapat menggunakan fungsionalitas ini untuk menghasilkan deskripsi bagian gambar yang terpisah. 
|
Hasilkan keterangan gambar (v3.2) (v4.0) |
| Mendeteksi objek | Deteksi objek mirip dengan pemberian tag, tetapi API-nya mengembalikan koordinat kotak pembatas untuk setiap tag yang diterapkan. Misalnya, jika gambar berisi anjing, kucing, dan orang, operasi Deteksi mencantumkan objek tersebut bersama dengan koordinatnya dalam gambar. Anda dapat menggunakan fungsionalitas ini untuk memproses hubungan lebih lanjut antar objek dalam gambar. Fungsionalitas ini juga memberitahu Anda saat ada beberapa instans tag yang sama dalam sebuah gambar. 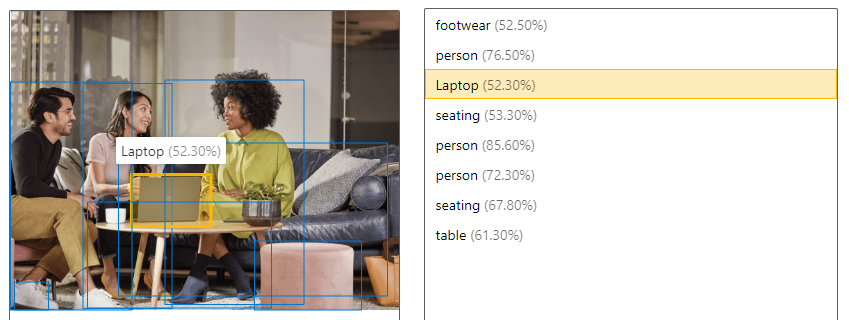
|
Mendeteksi objek (v3.2) (v4.0) |
| Menandai fitur visual | Mengidentifikasi dan menandai (tag) fitur visual dalam gambar, dari ribuan objek, makhluk hidup, pemandangan, dan tindakan yang dapat dikenali. Saat tag bersifat ambigu atau bukan merupakan pengetahuan umum, respons API memberikan petunjuk untuk memperjelas konteks tag. Pemberian tag tidak terbatas pada subjek utama, seperti orang di latar depan, tetapi juga mencakup pengaturan (dalam ruangan atau luar ruangan), furnitur, peralatan, tanaman, hewan, aksesori, gawai/gadget yang digunakan, dll.
|
Fitur visual tag (v3.2) (v4.0) |
| Dapatkan area yang menarik / panen cerdas | Analisis konten gambar untuk mengembalikan koordinat area yang menarik yang cocok dengan rasio aspek tertentu. Computer Vision mengembalikan koordinat kotak pembatas wilayah, sehingga aplikasi panggilan dapat memodifikasi gambar asli sesuai keinginan. Model pemangkasan cerdas versi 4.0 adalah implementasi yang lebih canggih dan bekerja dengan berbagai gambar input yang lebih luas. Ini hanya tersedia di wilayah geografis tertentu. Lihat Ketersediaan wilayah. |
Membuat gambar mini (v3.2) (pratinjau v4.0) |
| Mendeteksi merek (hanya v3.2) | Mengidentifikasi merek komersial dalam gambar atau video dari database ribuan logo global. Anda dapat menggunakan fitur ini, misalnya, untuk mengetahui merek mana yang paling populer di media sosial atau paling umum di penempatan produk media. | Mendeteksi merek |
| Mengategorikan gambar (hanya v3.2) | Mengidentifikasi dan mengategorikan seluruh gambar, menggunakan taksonomi kategori dengan hierarki keturunan orang tua/anak. Kategori dapat digunakan sendiri, atau dengan model pemberian tag baru kami. Saat ini, bahasa Inggris adalah satu-satunya bahasa yang didukung untuk pemberian tag dan mengategorikan gambar. |
Mengategorikan gambar |
| Mendeteksi wajah (hanya v3.2) | Mendeteksi wajah dalam gambar dan memberikan informasi tentang setiap wajah yang terdeteksi. Azure AI Vision mengembalikan koordinat, persegi panjang, jenis kelamin, dan usia untuk setiap wajah yang terdeteksi. Anda juga dapat menggunakan API Wajah khusus untuk tujuan ini. Hal ini memberikan analisis yang lebih detail, seperti identifikasi wajah dan deteksi pose. |
Mendeteksi wajah |
| Mendeteksi jenis gambar (hanya v3.2) | Mendeteksi karakteristik tentang gambar, seperti apakah suatu gambar adalah gambar garis atau kemungkinan apakah suatu gambar adalah clip art. | Mendeteksi jenis gambar |
| Mendeteksi konten khusus domain (hanya v3.2) | Menggunakan model domain untuk mendeteksi dan mengidentifikasi konten khusus domain dalam sebuah gambar, seperti selebriti dan bangunan terkenal. Misalnya, jika gambar berisi orang, Azure AI Vision dapat menggunakan model domain untuk selebriti untuk menentukan apakah orang yang terdeteksi dalam gambar adalah selebriti yang diketahui. | Mendeteksi konten khusus domain |
| Mendeteksi skema warna (hanya v3.2) | Menganalisis penggunaan warna dalam gambar. Azure AI Vision dapat menentukan apakah gambar hitam & putih atau warna dan, untuk gambar warna, mengidentifikasi warna dominan dan aksen. | Mendeteksi skema warna |
| Memoderasi konten dalam gambar (hanya v3.2) | Anda dapat menggunakan Azure AI Vision untuk mendeteksi konten dewasa dalam gambar dan mengembalikan skor keyakinan untuk klasifikasi yang berbeda. Ambang batas untuk menandai konten dapat diatur pada skala geser untuk mengakomodasi preferensi Anda. | Mendeteksi konten dewasa |
Pengenalan Produk (hanya pratinjau v4.0) (tidak digunakan lagi)
Penting
Fitur ini sekarang tidak digunakan lagi. Pada 10 Januari 2025, Azure AI Image Analysis 4.0 Custom Image Classification, Custom Object Detection, dan Product Recognition preview API akan dihentikan. Setelah tanggal ini, panggilan API ke layanan ini akan gagal.
Untuk menjaga kelancaran operasi model Anda, transisi ke Azure AI Custom Vision, yang sekarang tersedia secara umum. Custom Vision menawarkan fungsionalitas serupa dengan fitur yang dihentikan ini.
API Pengenalan Produk memungkinkan Anda menganalisis foto rak di toko ritel. Anda dapat mendeteksi keberadaan atau tidak adanya produk dan mendapatkan koordinat kotak pembatasnya. Gunakan dalam kombinasi dengan kustomisasi model untuk melatih model untuk mengidentifikasi produk spesifik Anda. Anda juga dapat membandingkan hasil Pengenalan Produk dengan dokumen planogram toko Anda.
Penyematan multimodal (hanya v4.0)
API penyematan multimodal memungkinkan vektorisasi gambar dan kueri teks. Mereka mengonversi gambar menjadi koordinat dalam ruang vektor multi-dimensi. Kemudian, kueri teks masuk juga dapat dikonversi ke vektor, dan gambar dapat dicocokkan dengan teks berdasarkan kedekatan semantik. Ini memungkinkan pengguna untuk mencari sekumpulan gambar menggunakan teks, tanpa perlu menggunakan tag gambar atau metadata lainnya. Kedekatan semantik sering menghasilkan hasil yang lebih baik dalam pencarian.
2024-02-01 API menyertakan model multibahasa yang mendukung pencarian teks dalam 102 bahasa. Model asli khusus bahasa Inggris masih tersedia, tetapi tidak dapat dikombinasikan dengan model baru dalam indeks pencarian yang sama. Jika Anda mem-vektorisasi teks dan gambar menggunakan model khusus bahasa Inggris, vektor ini tidak akan kompatibel dengan teks multibahasa dan vektor gambar.
API ini hanya tersedia di wilayah geografis tertentu. Lihat Ketersediaan wilayah.
Penghapusan latar belakang (hanya pratinjau v4.0)
Penting
Fitur ini sekarang tidak digunakan lagi. Pada 10 Januari 2025, Azure AI Image Analysis 4.0 Segment API dan layanan penghapusan latar belakang akan dihentikan. Semua permintaan ke layanan ini akan gagal setelah tanggal ini.
Untuk mempertahankan pengoperasian model Anda yang lancar, instal model Florence 2 sumber terbuka dan gunakan fitur Wilayah ke segmentasi, yang memungkinkan operasi penghapusan latar belakang serupa.
Analisis Gambar 4.0 (pratinjau) menawarkan kemampuan untuk menghapus latar belakang gambar. Fitur ini dapat menghasilkan gambar objek latar depan yang terdeteksi dengan latar belakang transparan, atau gambar alpha matte skala abu-abu yang menunjukkan keburaman objek latar depan yang terdeteksi.
| Gambar asli | Dengan latar belakang dihapus | Matte alfa |
|---|---|---|

|

|

|
Batas layanan
Persyaratan input
Image Analysis berfungsi pada gambar yang memenuhi persyaratan berikut:
- Gambar harus disajikan dalam format JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF, atau MPO
- Ukuran file gambar harus kurang dari 20 megabyte (MB)
- Dimensi gambar harus lebih besar dari 50 x 50 piksel dan kurang dari 16.000 x 16.000 piksel
Tip
Persyaratan input untuk penyematan multimodal berbeda dan tercantum dalam penyematan Multimodal
Dukungan bahasa
Fitur Analisis Gambar yang berbeda tersedia dalam bahasa yang berbeda. Lihat halaman Dukungan bahasa .
Ketersediaan wilayah
Untuk menggunakan API Analisis Gambar, Anda harus membuat sumber daya Azure AI Vision di wilayah yang didukung. Fitur Analisis Gambar tersedia di wilayah berikut:
| Wilayah | Analisis Gambar (minus 4.0 Keterangan) |
Analisis Gambar (termasuk 4.0 Keterangan) |
Pengenalan Produk | Penyematan multimodal | Penghapusan latar belakang |
|---|---|---|---|---|---|
| AS Timur | ✅ | ✅ | ✅ | ✅ | ✅ |
| AS Barat | ✅ | ✅ | ✅ | ✅ | |
| US Barat 2 | ✅ | ✅ | ✅ | ||
| Prancis Tengah | ✅ | ✅ | ✅ | ✅ | |
| Eropa Utara | ✅ | ✅ | ✅ | ✅ | |
| Eropa Barat | ✅ | ✅ | ✅ | ✅ | |
| Swedia Tengah | ✅ | ✅ | |||
| Swiss Utara | ✅ | ✅ | |||
| Australia Timur | ✅ | ✅ | |||
| Asia Tenggara | ✅ | ✅ | ✅ | ✅ | |
| Asia Timur | ✅ | ✅ | |||
| Korea Tengah | ✅ | ✅ | ✅ | ✅ | |
| Jepang Timur | ✅ | ✅ |
Privasi dan keamanan data
Seperti semua layanan Azure AI, pengembang yang menggunakan layanan Azure AI Vision harus mengetahui kebijakan Microsoft tentang data pelanggan. Lihat halaman layanan Azure AI di Pusat Kepercayaan Microsoft untuk mempelajari selengkapnya.
Langkah berikutnya
Mulai menggunakan Analisis Gambar dengan mengikuti panduan mulai cepat dalam bahasa pengembangan dan versi API pilihan Anda: