Mengoptimalkan sink
Ketika aliran data menulis ke sink, pemartisian kustom apa pun terjadi segera sebelum penulisan. Seperti sumbernya, dalam kebanyakan kasus disarankan agar Anda tetap Menggunakan partisi saat ini sebagai opsi partisi yang dipilih. Data yang dipartisi menulis jauh lebih cepat daripada data yang tidak dipartisi, bahkan tujuan Anda tidak dipartisi. Berikut ini adalah pertimbangan individual untuk berbagai jenis sink.
Sink Azure SQL Database
Dengan Azure SQL Database, pemartisian default harus berfungsi dalam banyak kasus. Ada kemungkinan bahwa sink Anda mungkin memiliki terlalu banyak partisi untuk ditangani database SQL Anda. Jika Anda mengalami hal ini, kurangi jumlah partisi yang dihasilkan oleh sink SQL Database Anda.
Praktik terbaik untuk menghapus baris di sink berdasarkan baris yang hilang di sumber
Berikut adalah panduan video tentang cara menggunakan aliran data dengan transformasi yang ada, ubah baris, dan sink untuk mencapai pola umum ini:
Dampak penanganan baris kesalahan terhadap performa
Saat Anda mengaktifkan penanganan baris kesalahan ("lanjutkan pada kesalahan") dalam transformasi sink, layanan mengambil langkah tambahan sebelum menulis baris yang kompatibel ke tabel tujuan Anda. Langkah tambahan ini memiliki penalti performa kecil yang dapat berada di kisaran 5% ditambahkan untuk langkah ini dengan hit performa ekstra kecil juga ditambahkan jika Anda mengatur opsi untuk juga menulis baris yang tidak kompatibel ke file log.
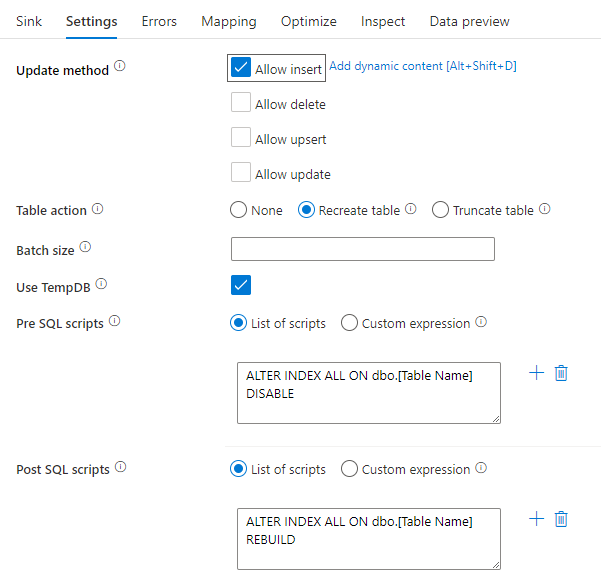
Menonaktifkan indeks menggunakan Skrip SQL
Menonaktifkan indeks sebelum dimuat dalam database SQL dapat sangat meningkatkan performa penulisan ke tabel. Jalankan perintah di bawah ini sebelum menulis ke sink SQL Anda.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
Setelah penulisan selesai, bangun ulang indeks menggunakan perintah berikut:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Keduanya dapat dilakukan secara asli menggunakan skrip Pra dan Pasca-SQL dalam Azure SQL Database atau sink Synapse dalam pemetaan aliran data.
Peringatan
Saat menonaktifkan indeks, aliran data secara efektif mengambil kendali database sehingga kueri tidak mungkin berhasil dilakukan saat ini. Akibatnya, banyak pekerjaan ETL yang dipicu di luar waktu normal untuk menghindari konflik ini. Untuk informasi selengkapnya, pelajari tentang batasan penonaktifan indeks SQL
Meningkatkan skala database Anda
Jadwalkan pengubahan ukuran sumber Anda dan sink Azure SQL DB dan DW sebelum alur Anda berjalan untuk meningkatkan throughput dan meminimalkan pembatasan Azure setelah Anda mencapai batas DTU. Setelah eksekusi alur Anda selesai, ubah ukuran database Anda kembali ke tingkat berjalan normal mereka.
Sink Azure Synapse Analytics
Saat menulis ke Azure Synapse Analytics, pastikan bahwa Aktifkan tahapan diatur ke true. Ini memungkinkan layanan untuk menulis menggunakan Perintah SQL COPY, yang secara efektif memuat data secara massal. Anda harus mereferensikan akun Azure Data Lake Storage gen2 atau Azure Blob Storage untuk penahapan data saat menggunakan Penahapan.
Selain Tahapan, praktik terbaik yang sama berlaku untuk Azure Synapse Analytics sebagai Azure SQL Database.
Sink berbasis file
Meskipun aliran data mendukung berbagai jenis file, format Parquet asli Spark direkomendasikan untuk waktu baca dan tulis yang optimal.
Jika data didistribusikan secara merata, Gunakan partisi saat ini adalah opsi partisi tercepat untuk menulis file.
Opsi nama file
Saat menulis file, Anda memiliki pilihan opsi penamaan yang masing-masing memiliki efek pada performa.
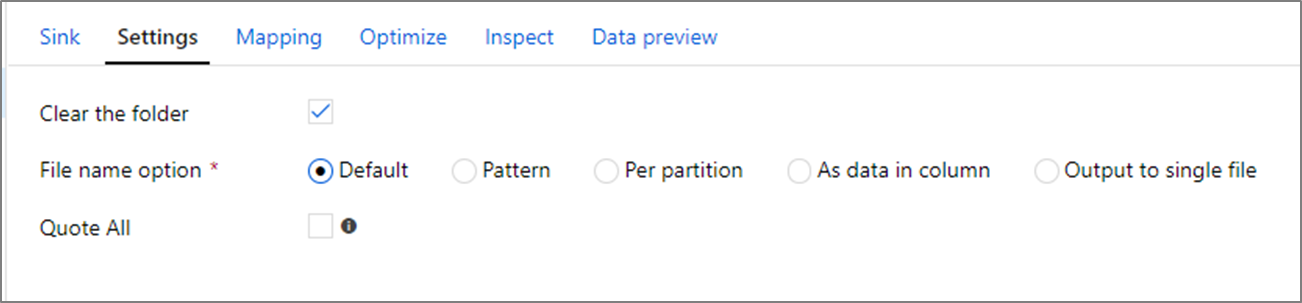
Memilih opsi Default menulis yang tercepat. Setiap partisi sama dengan file dengan nama default Spark. Ini berguna jika Anda hanya membaca dari folder data.
Mengatur penamaan Pola mengganti nama setiap file partisi menjadi nama yang lebih mudah digunakan. Operasi ini terjadi setelah menulis dan sedikit lebih lambat daripada memilih default.
Per partisi memungkinkan Anda memberi nama setiap partisi individu secara manual.
Jika kolom sesuai dengan cara Anda ingin mengeluarkan data, Anda dapat memilih Nama file sebagai data kolom. Tindakan ini akan mengacaukan data dan dapat memengaruhi performa jika kolom tidak didistribusikan secara merata.
Jika kolom sesuai dengan cara Anda ingin membuat nama folder, pilih Nama folder sebagai data kolom.
Output ke file tunggal menggabungkan semua data ke dalam satu partisi. Penggabungan ini mengarah pada waktu penulisan yang lama, terutama untuk himpunan data besar. Opsi ini tidak disarankan kecuali ada alasan bisnis eksplisit untuk menggunakannya.
Sink Azure Cosmos DB
Saat Anda menulis ke Azure Cosmos DB, mengubah throughput dan ukuran batch selama eksekusi aliran data dapat meningkatkan performa. Perubahan ini hanya berlaku selama aktivitas aliran data berjalan dan akan kembali ke pengaturan pengumpulan asli setelah kesimpulan.
Ukuran batch: Biasanya, dimulai dengan ukuran batch default sudah cukup. Untuk lebih menyelaraskan nilai ini, hitung ukuran objek kasar data Anda, dan pastikan ukuran objek * ukuran batch kurang dari 2MB. Jika ya, Anda dapat meningkatkan ukuran batch untuk mendapatkan throughput yang lebih baik.
Throughput: Tetapkan pengaturan throughput yang lebih tinggi di sini untuk memungkinkan dokumen menulis lebih cepat ke Azure Cosmos DB. Perlu diingat biaya RU yang lebih tinggi berdasarkan pengaturan throughput yang tinggi.
Menulis anggaran throughput: Gunakan nilai, yang lebih kecil dari total RU per menit. Jika Anda memiliki aliran data dengan jumlah partisi Spark yang tinggi, menetapkan throughput anggaran memungkinkan lebih banyak keseimbangan di seluruh partisi tersebut.
Konten terkait
- Gambaran umum performa aliran data
- Mengoptimalkan sumber
- Mengoptimalkan transformasi
- Menggunakan aliran data dalam alur
Lihat artikel Aliran Data lainnya yang terkait dengan performa: