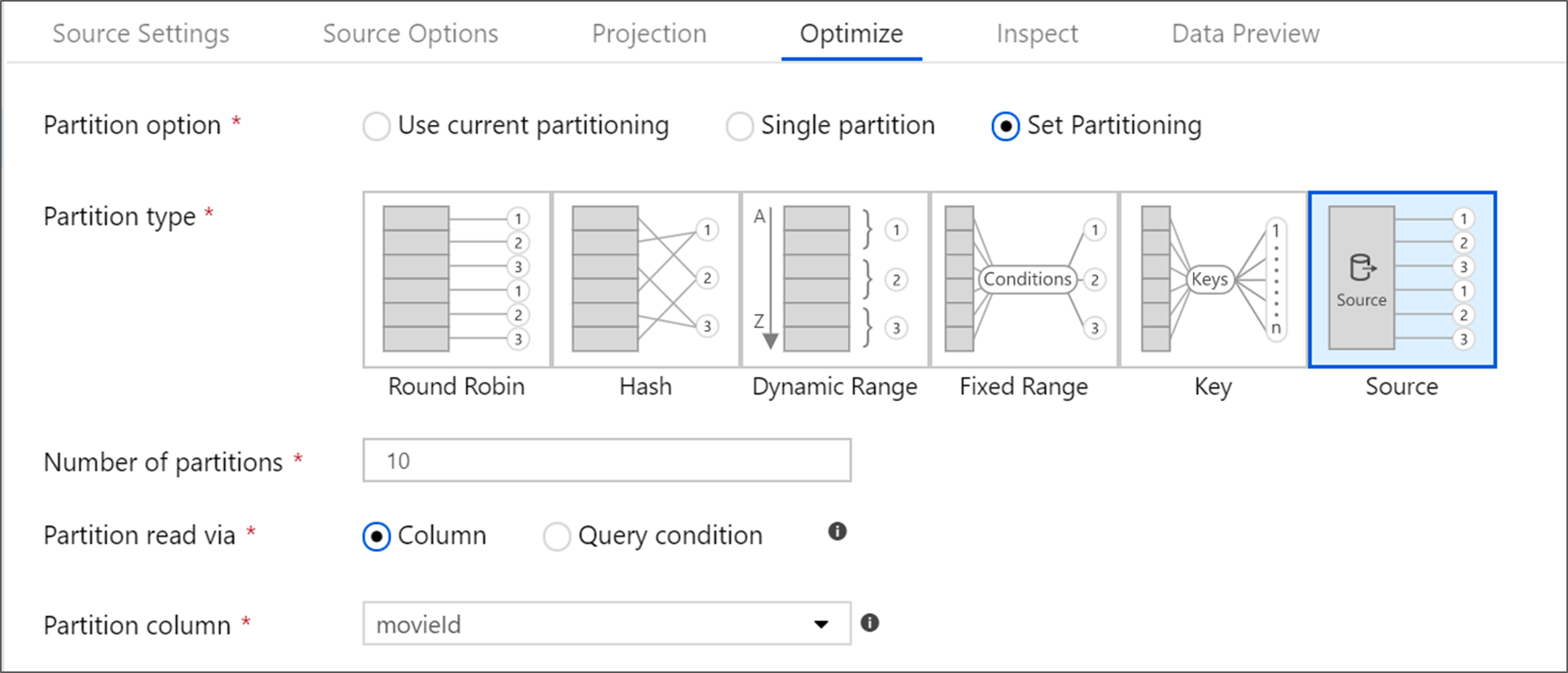
Mengoptimalkan sumber
Untuk setiap sumber kecuali Azure SQL Database, disarankan agar Anda tetap Menggunakan partisi saat ini sebagai nilai yang dipilih. Saat Anda membaca dari semua sistem sumber lainnya, data mengalir secara otomatis mempartisi data secara merata berdasarkan ukuran data. Partisi baru dibuat untuk setiap 128 MB data. Ketika ukuran data Anda meningkat, jumlah partisi akan meningkat.
Setiap pemartisian kustom terjadi setelah Spark membaca dalam data dan berdampak negatif pada performa aliran data Anda. Karena data dipartisi secara merata saat dibaca, tidak disarankan kecuali Anda memahami bentuk dan kardinalitas data Anda terlebih dahulu.
Catatan
Kecepatan baca dapat dibatasi oleh throughput sistem sumber Anda.
Sumber Azure SQL Database
Azure SQL Database memiliki opsi pemartisian unik yang disebut pemartisian 'Sumber'. Mengaktifkan partisi sumber dapat meningkatkan waktu baca Anda dari Azure SQL Database dengan mengaktifkan koneksi paralel pada sistem sumber. Tentukan jumlah partisi dan cara mempartisi data Anda. Gunakan kolom partisi dengan kardinalitas tinggi. Anda juga bisa memasukkan kueri yang cocok dengan skema pemartisian tabel sumber Anda.
Tip
Untuk pemartisian sumber, I/O SQL Server adalah penyempitan. Menambahkan terlalu banyak partisi dapat menjenuhkan database sumber Anda. Umumnya empat atau lima partisi adalah jumlah ideal saat menggunakan opsi ini.
Tingkat isolasi
Tingkat isolasi bacaan pada sistem sumber Azure SQL memengaruhi performa. Memilih 'Baca tidak terkomit' memberikan performa tercepat dan mencegah kunci database apa pun. Untuk mempelajari selengkapnya tentang tingkat Isolasi SQL, lihat Memahami tingkat isolasi.
Baca menggunakan kueri
Anda bisa membaca dari Azure SQL Database menggunakan tabel atau kueri SQL. Jika Anda menjalankan kueri SQL, kueri harus diselesaikan sebelum transformasi dapat dimulai. Kueri SQL dapat berguna untuk mendorong operasi yang mungkin dijalankan lebih cepat dan mengurangi jumlah data yang dibaca dari SQL Server seperti pernyataan SELECT, WHERE, dan JOIN. Saat menekan operasi, Anda kehilangan kemampuan untuk melacak silsilah data dan performa transformasi sebelum data masuk ke aliran data.
Sumber Microsoft Azure Synapse Analytics
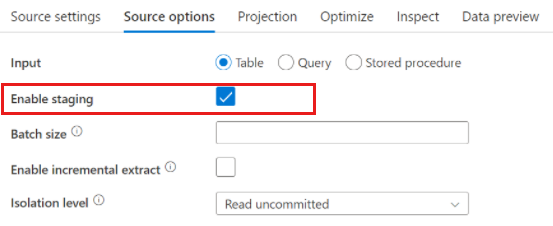
Saat menggunakan Azure Synapse Analytics, pengaturan bernama Aktifkan tahapan ada di opsi sumber. Ini memungkinkan layanan untuk membaca dari Synapse menggunakan Staging, yang sangat meningkatkan performa baca dengan menggunakan kemampuan pemuatan massal yang paling berkinerja seperti cetas dan perintah COPY. Mengaktifkan Staging mengharuskan Anda menentukan lokasi tahapan Azure Blob Storage atau Azure Data Lake Storage gen2 di pengaturan aktivitas aliran data.
Sumber berbasis file
Parquet vs. teks yang dibatasi
Meskipun aliran data mendukung berbagai jenis file, format Parquet asli Spark direkomendasikan untuk waktu baca dan tulis yang optimal.
Jika Anda menjalankan aliran data yang sama pada sekumpulan file, sebaiknya baca dari folder, menggunakan jalur pencarian wildcard atau membaca dari daftar file. Satu aktivitas aliran data yang dijalankan dapat memproses semua file Anda dalam batch. Informasi selengkapnya tentang cara mengatur pengaturan ini dapat ditemukan di dokumentasi konektor Azure Blob Storage bagian Transformasi penyedia sumber .
Jika memungkinkan, hindari menggunakan aktivitas Untuk- Setiap untuk menjalankan aliran data pada sekumpulan file. Ini menyebabkan setiap iterasi untuk masing-masing memutar kluster Spark sendiri, yang sering tidak diperlukan dan bisa mahal.
Himpunan data sebaris vs. himpunan data bersama
Himpunan data ADF dan Synapse adalah sumber daya bersama di pabrik dan ruang kerja Anda. Namun, ketika Anda membaca sejumlah besar folder sumber dan file dengan teks yang dibatasi dan sumber JSON, Anda dapat meningkatkan performa penemuan file aliran data dengan mengatur opsi "Skema yang diproyeksikan pengguna" di dalam Proyeksi | Dialog opsi skema. Opsi ini menonaktifkan penemuan otomatis skema default ADF dan sangat meningkatkan performa penemuan file. Sebelum mengatur opsi ini, pastikan untuk mengimpor proyeksi sehingga ADF memiliki skema yang ada untuk proyeksi. Opsi ini tidak berfungsi dengan penyimpangan skema.
Konten terkait
- Gambaran umum performa aliran data
- Mengoptimalkan sink
- Mengoptimalkan transformasi
- Menggunakan aliran data dalam alur
Lihat artikel Aliran Data lainnya yang terkait dengan performa: