Pemetaan performa aliran data dan panduan penyetelan
BERLAKU UNTUK:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Aliran data pemetaan di Azure Data Factory dan alur Synapse menyediakan antarmuka bebas kode untuk merancang dan menjalankan transformasi data dalam skala besar. Jika Anda tidak terbiasa dengan alur data pemetaan, lihat Gambaran Umum Alur Data Pemetaan. Artikel ini menyoroti berbagai cara untuk menyetel dan mengoptimalkan aliran data Anda agar memenuhi tolok ukur performa Anda.
Tonton video berikut untuk melihat beberapa waktu sampel mengubah data dengan aliran data.
Memantau kinerja aliran data
Setelah Anda memverifikasi logika transformasi menggunakan mode debug, jalankan aliran data Anda secara end-to-end sebagai aktivitas dalam alur. Aliran data dioperasionalkan dalam alur menggunakan jalankan aktivitas aliran data. Aktivitas aliran data memiliki pengalaman pemantauan yang unik dibandingkan dengan aktivitas lain yang menampilkan rencana eksekusi terperinci dan profil performa logika transformasi. Untuk melihat informasi pemantauan terperinci dari aliran data, pilih ikon kacamata dalam output eksekusi aktivitas dari alur. Untuk informasi selengkapnya, lihat Memantau aliran data pemetaan.

Saat Anda memantau performa aliran data, ada empat kemungkinan hambatan yang perlu diwaspadai:
- Waktu mulai aktif kluster
- Membaca dari sumber
- Waktu transformasi
- Menulis ke sink
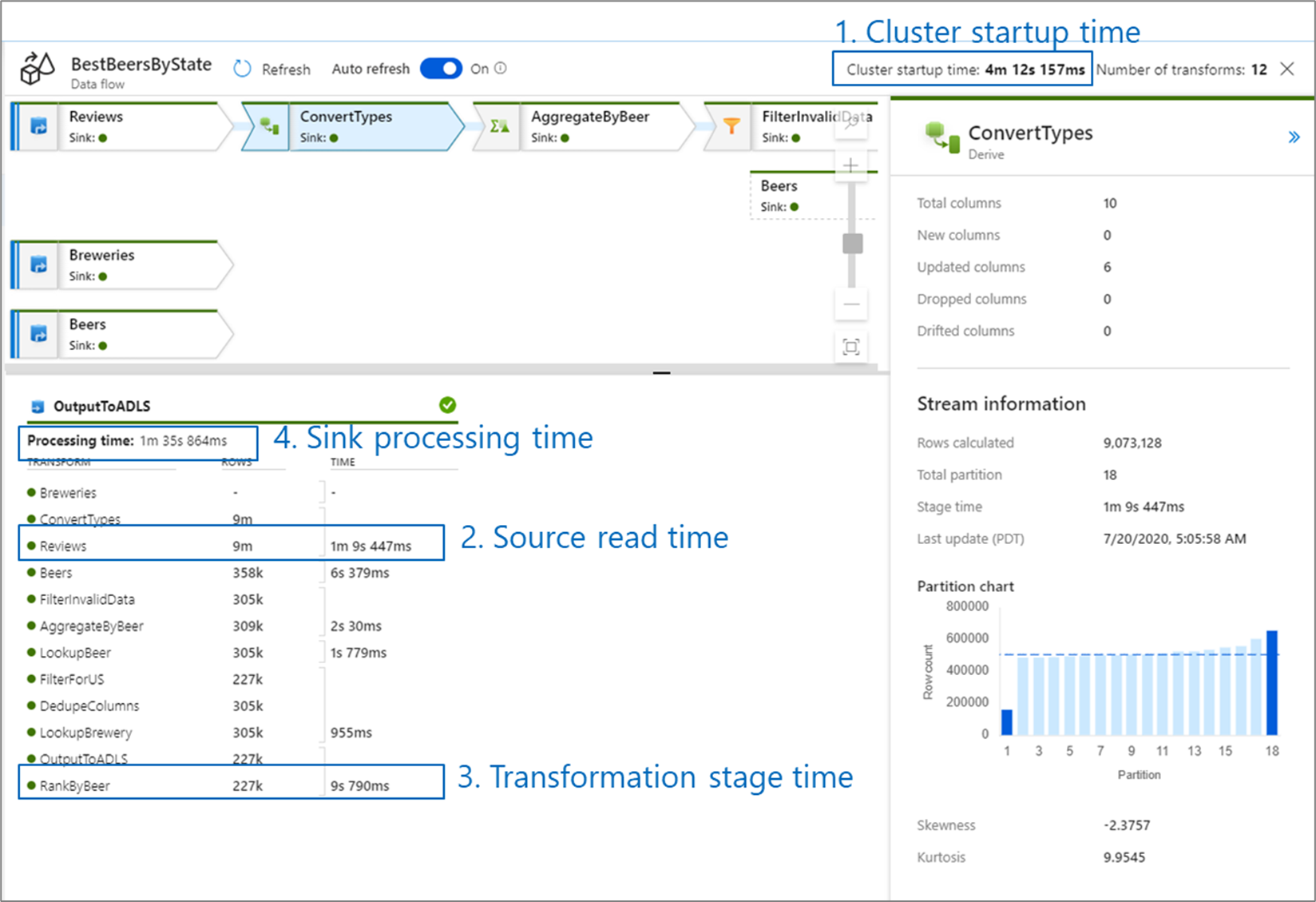
Waktu mulai aktif kluster adalah waktu yang diperlukan untuk melakukan spin up pada kluster Apache Spark. Nilai ini terletak di sudut kanan atas layar pemantauan. Aliran data berjalan pada model just-in-time di mana setiap pekerjaan menggunakan kluster yang terisolasi. Waktu startup ini umumnya memakan waktu 3-5 menit. Untuk pekerjaan berurutan, waktu mulai dapat dikurangi dengan mengaktifkan nilai waktu hidup. Untuk informasi selengkapnya, lihat bagian Waktu hidup di performa Integration Runtime.
Aliran data menggunakan pengoptimal Spark yang menyusun ulang dan menjalankan logika bisnis Anda dalam 'tahapan' untuk bekerja secepat mungkin. Untuk setiap sink yang ditulis oleh aliran data Anda, output pemantauan mencantumkan durasi setiap tahap transformasi, bersama dengan waktu yang diperlukan untuk menulis data ke sink. Waktu dengan jumlah paling banyak kemungkinan menjadi penyempitan aliran data Anda. Jika tahap transformasi yang mengambil yang terbesar berisi sumber, maka Anda mungkin ingin melihat lebih lanjut mengoptimalkan waktu baca Anda. Jika transformasi membutuhkan waktu lama, maka Anda mungkin perlu mempartisi ulang atau meningkatkan ukuran runtime integrasi Anda. Jika waktu pemrosesan sink besar, Anda mungkin perlu meningkatkan skala database Anda atau memverifikasi bahwa Anda tidak menghasilkan ke satu file.
Setelah Anda mengidentifikasi penyempitan aliran data Anda, gunakan strategi pengoptimalan di bawah ini untuk meningkatkan performa.
Menguji logika aliran data
Saat Anda merancang dan menguji aliran data dari UI, mode debug memungkinkan Anda untuk menguji secara interaktif terhadap kluster Spark langsung, yang memungkinkan Anda untuk mempratinjau data dan menjalankan aliran data Anda tanpa menunggu kluster dihangatkan. Untuk informasi selengkapnya, lihat Mode Debug.
Tab Optimalkan
Tab Optimalkan berisi pengaturan untuk mengonfigurasi skema partisi kluster Spark. Tab Optimalkan ada di setiap transformasi aliran data dan menjadi penentu jika Anda ingin mempartisi ulang data setelah transformasi selesai. Menyesuaikan pemartisian memberikan kontrol atas distribusi data Anda di seluruh simpul komputasi dan pengoptimalan lokalitas data yang dapat memiliki efek positif dan negatif pada performa aliran data Anda secara keseluruhan.
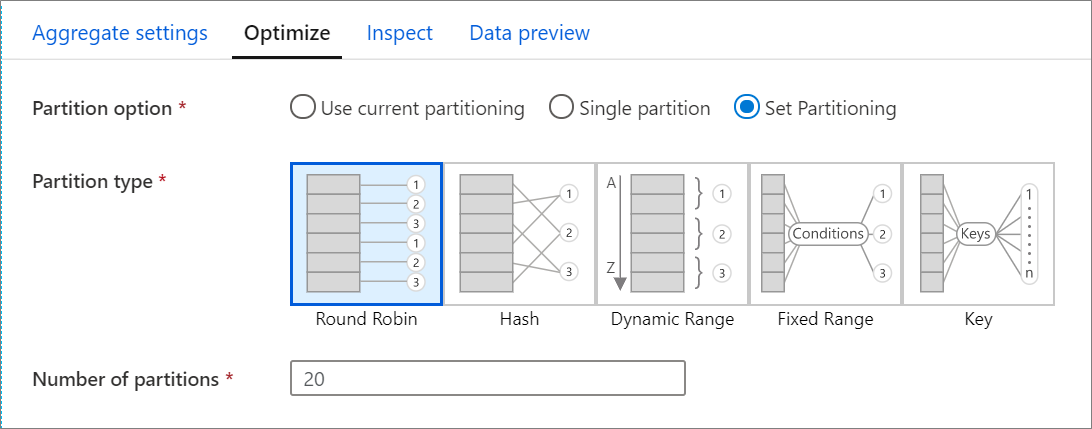
Secara default, Gunakan partisi saat ini dipilih yang menginstruksikan layanan untuk menyimpan partisi output saat ini dari transformasi. Karena pemartisian ulang data membutuhkan waktu, Anda disarankan Menggunakan pemartisian saat ini di sebagian besar skenario. Skenario di mana Anda mungkin ingin mempartisi ulang data Anda termasuk setelah agregat dan gabungan yang secara signifikan condong data Anda atau saat menggunakan partisi Sumber pada database SQL.
Untuk mengubah pemartisian pada transformasi apa pun, pilih tab Optimalkan dan pilih tombol radio Atur Pemartisian. Anda disajikan dengan serangkaian opsi untuk pemartisian. Metode pemartisian terbaik berbeda berdasarkan volume data Anda, kunci kandidat, nilai null, dan kardinalitas.
Penting
Partisi tunggal menggabungkan semua data yang didistribusikan ke dalam satu partisi. Ini adalah operasi yang sangat lambat yang juga secara signifikan mempengaruhi semua transformasi dan penulisan downstream. Opsi ini sangat tidak disarankan kecuali ada alasan bisnis yang jelas untuk menggunakannya.
Opsi pemartisian berikut tersedia di setiap transformasi:
Round robin
Round robin mendistribusikan data secara merata di seluruh partisi. Gunakan round-robin ketika Anda tidak memiliki kandidat kunci yang baik untuk menerapkan strategi pemartisian yang solid dan cerdas. Anda dapat mengatur jumlah partisi fisik.
Hash
Layanan menghasilkan hash kolom untuk menghasilkan partisi yang seragam sehingga baris dengan nilai yang sama jatuh di partisi yang sama. Saat Anda menggunakan opsi Hash, uji kemungkinan kecondongan partisi. Anda dapat mengatur jumlah partisi fisik.
Rentang dinamis
Rentang dinamis menggunakan rentang dinamis Spark berdasarkan kolom atau ekspresi yang Anda sediakan. Anda dapat mengatur jumlah partisi fisik.
Rentang tetap
Bangun ekspresi yang menyediakan rentang tetap untuk nilai dalam kolom data yang dipartisi. Untuk menghindari kecondongan partisi, Anda harus memiliki pemahaman yang baik tentang data Anda sebelum Anda menggunakan opsi ini. Nilai yang Anda masukkan untuk ekspresi digunakan sebagai bagian dari fungsi partisi. Anda dapat mengatur jumlah partisi fisik.
Tombol
Jika Anda memiliki pemahaman yang baik tentang kardinalitas data Anda, partisi kunci mungkin menjadi strategi yang baik. Partisi kunci membuat partisi untuk setiap nilai unik di kolom Anda. Anda tidak dapat mengatur jumlah partisi karena angka didasarkan pada nilai unik dalam data.
Tip
Mengatur skema partisi secara manual akan merombak data dan dapat mengimbangi manfaat dari pengoptimal Spark. Praktik terbaik adalah untuk tidak mengatur partisi secara manual kecuali diperlukan.
Tingkat pengelogan
Jika Anda tidak mengharuskan setiap eksekusi alur aktivitas aliran data Anda untuk sepenuhnya mencatat semua log telemetri verbose, Anda dapat secara opsional mengatur tingkat pengelogan Anda ke "Dasar" atau "Tidak Ada". Saat menjalankan aliran data Anda dalam mode "Verbose" (default), Anda meminta layanan untuk sepenuhnya mencatat aktivitas di setiap tingkat partisi individu selama transformasi data Anda. Ini bisa menjadi operasi yang mahal, jadi aktifkan verbose hanya saat pemecahan masalah dapat meningkatkan aliran data dan performa alur Anda secara keseluruhan. Mode "Dasar" hanya mencatat durasi transformasi sementara "Tidak Ada" hanya akan memberikan ringkasan durasi.

Konten terkait
- Mengoptimalkan sumber
- Mengoptimalkan sink
- Mengoptimalkan transformasi
- Menggunakan aliran data dalam alur
Lihat artikel Aliran Data lainnya yang terkait dengan performa: