Mengoptimalkan transformasi
Gunakan strategi berikut untuk mengoptimalkan kinerja transformasi dalam memetakan aliran data di Azure Data Factory dan saluran Azure Synapse Analytics.
Mengoptimalkan Gabungan, Ada, dan Pencarian
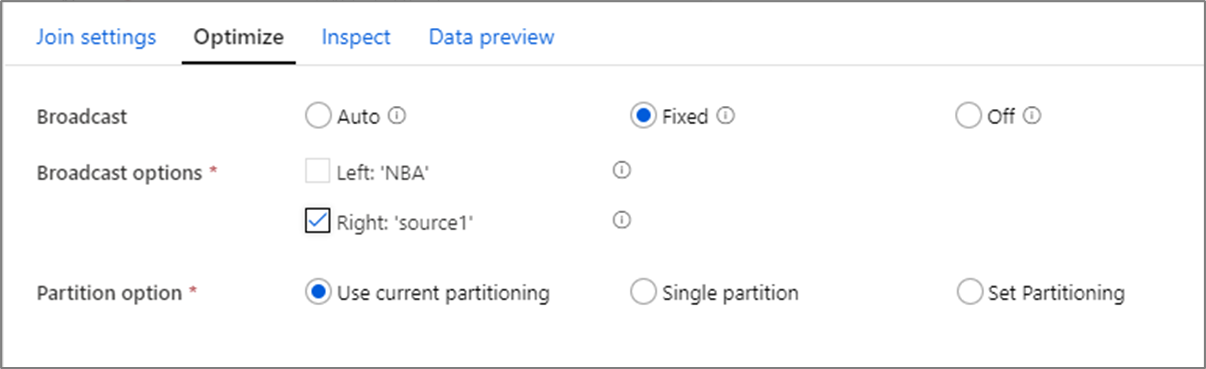
Penyiaran
Dalam gabungan, pencarian, dan transformasi yang ada, jika satu atau kedua aliran data cukup kecil untuk masuk ke dalam memori simpul pekerja, Anda dapat mengoptimalkan kinerja dengan mengaktifkan Penyiaran. Penyiaran adalah ketika Anda mengirim bingkai data kecil ke semua simpul dalam klaster. Hal ini memungkinkan mesin Spark untuk melakukan penggabungan tanpa melakukan perombakan data dalam aliran besar. Secara default, mesin Spark secara otomatis memutuskan apakah akan menyiarkan satu sisi gabungan atau tidak. Jika Anda terbiasa dengan data masuk dan mengetahui bahwa satu aliran lebih kecil dari yang lain, Anda dapat memilih Siaran tetap . Siaran tetap memaksa Spark untuk menyiarkan streaming yang dipilih.
Jika ukuran data yang disiarkan terlalu besar untuk simpul Spark, Anda mungkin mendapatkan kesalahan memori. Untuk menghindari kesalahan memori, gunakan kluster dengan memori yang dioptimalkan. Jika Anda mengalami batas waktu siaran selama eksekusi aliran data, Anda dapat menonaktifkan pengoptimalan siaran. Namun, hal ini mengakibatkan performa aliran data yang lebih lambat.
Saat bekerja dengan sumber data yang bisa memakan waktu lebih lama untuk dikueri, seperti kueri database besar, disarankan untuk menonaktifkan siaran untuk gabungan. Sumber dengan waktu kueri yang lama dapat menyebabkan waktu Spark habis ketika kluster mencoba untuk menyiarkan ke simpul komputasi. Pilihan lain yang baik untuk mematikan siaran adalah ketika Anda memiliki aliran dalam aliran data Anda yang mengagregasikan nilai untuk digunakan dalam transformasi pencarian nanti. Pola ini dapat membingungkan pengoptimal Spark dan menyebabkan waktu habis.
Gabungan silang
Jika Anda menggunakan nilai harfiah dalam kondisi gabungan Anda atau memiliki beberapa kecocokan di kedua sisi gabungan, Spark menjalankan gabungan sebagai gabungan silang. Gabungan silang adalah produk kartesius lengkap yang kemudian memfilter nilai gabungan. Ini lebih lambat daripada jenis gabungan lainnya. Pastikan Anda memiliki referensi kolom di kedua sisi kondisi gabungan Anda untuk menghindari dampak performa.
Mengurutkan sebelum bergabung
Tidak seperti penggabungan dalam alat seperti SSIS, transformasi gabungan bukanlah operasi penggabungan wajib. Kunci gabungan tidak memerlukan pengurutan sebelum transformasi. Menggunakan transformasi Sortir dalam pemetaan aliran data tidak disarankan.
Performa transformasi jendela
Transformasi jendela di pemetaan aliran data membagi data Anda menurut nilai dalam kolom yang Anda pilih sebagai bagian dari klausaover() dalam pengaturan transformasi. Ada banyak fungsi agregat dan analitik populer yang diekspos dalam transformasi Windows. Namun, jika kasus penggunaan Anda adalah menghasilkan jendela di seluruh himpunan rank() data Anda untuk peringkat atau nomor rowNumber()baris , disarankan agar Anda menggunakan transformasi Peringkat dan transformasi Kunci Pengganti. Transformasi tersebut berkinerja lebih baik lagi operasi himpunan data penuh menggunakan fungsi-fungsi tersebut.
Mempartisi ulang data miring
Transformasi tertentu seperti gabungan dan agregat merombak partisi data Anda dan terkadang dapat menyebabkan data miring. Data condong berarti bahwa data tidak didistribusikan secara merata di seluruh partisi. Data yang sangat miring dapat menyebabkan transformasi downstream dan penulisan sink yang lebih lambat. Anda dapat memeriksa kemiringan data Anda di titik mana pun dalam aliran data yang dijalankan dengan mengklik transformasi di tampilan pemantauan.
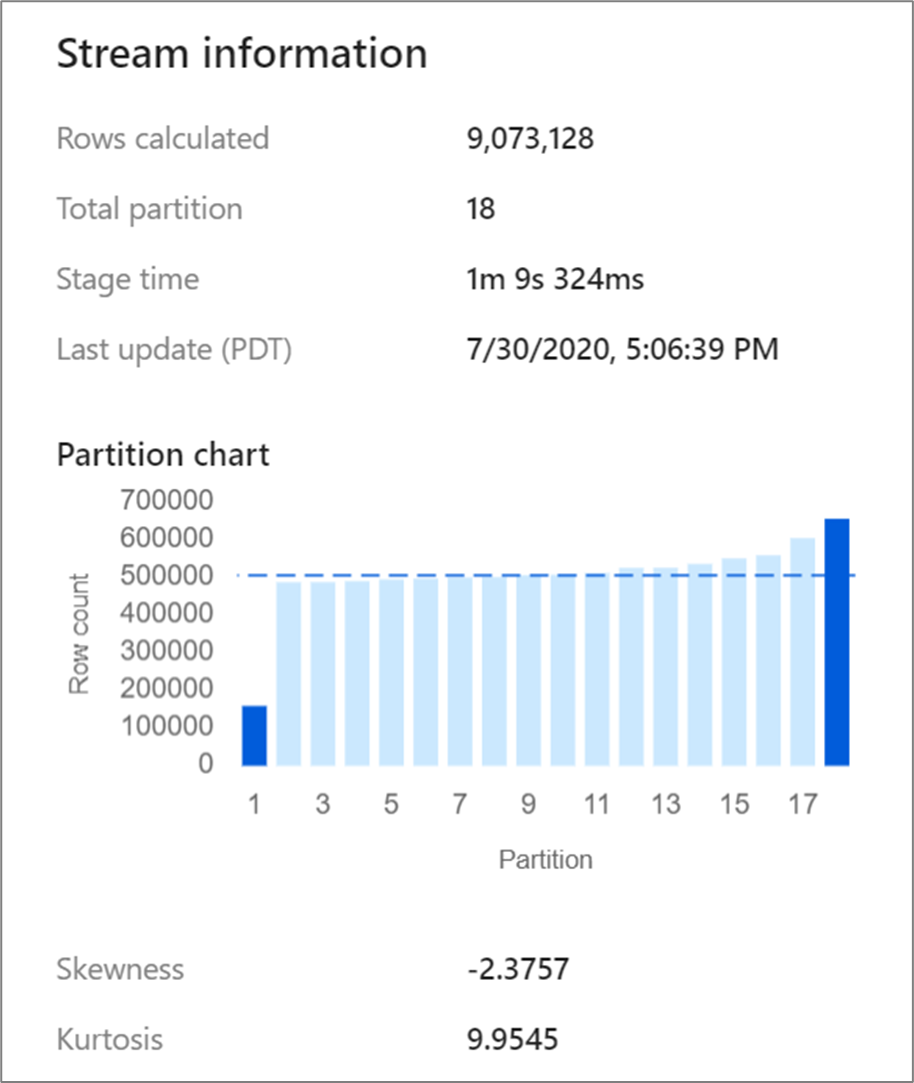
Tampilan pemantauan menunjukkan bagaimana data didistribusikan di setiap partisi bersama dengan dua metrik, ke condong dan kurtosis. Kecondongan adalah ukuran seberapa asimetris data tersebut dan dapat memiliki nilai positif, nol, negatif, atau tidak terdefinisi. Condong negatif berarti ekor kiri lebih panjang dari ekor kanan. Kurtosis adalah ukuran apakah data tersebut berekor berat atau berekor ringan. Nilai kurtosis tinggi tidak diinginkan. Rentang kecondongan yang ideal terletak antara -3 dan 3 dan rentang kurtosis kurang dari 10. Cara mudah untuk menginterpretasikan angka-angka ini adalah dengan melihat bagan partisi dan melihat apakah 1 batang lebih besar dari yang lain.
Jika data Anda tidak dipartisi secara merata setelah transformasi, Anda dapat menggunakan tab optimalkan untuk mempartisi ulang. Perombakan data membutuhkan waktu dan mungkin tidak meningkatkan performa aliran data Anda.
Tip
Jika Anda mempartisi ulang data Anda, tetapi memiliki transformasi downstream yang melakukan perombakan data Anda, gunakan partisi hash pada kolom yang digunakan sebagai kunci gabungan.
Catatan
Transformasi di dalam aliran data Anda (dengan pengecualian transformasi Sink) tidak mengubah partisi file dan folder data tidak aktif. Partisi dalam setiap transformasi akan mempartisi ulang data di dalam bingkai data kluster Spark tanpa server sementara yang dikelola ADF untuk setiap eksekusi aliran data Anda.
Konten terkait
- Gambaran umum performa aliran data
- Mengoptimalkan sumber
- Mengoptimalkan sink
- Menggunakan aliran data dalam alur
Lihat artikel Aliran Data lainnya yang terkait dengan performa: