Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Petunjuk
Data Factory di Microsoft Fabric adalah generasi Azure Data Factory berikutnya, dengan arsitektur yang lebih sederhana, AI bawaan, dan fitur baru. Jika Anda baru menggunakan integrasi data, mulailah dengan Fabric Data Factory. Beban kerja ADF yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik real time, dan pelaporan.
Alur di ruang kerja Azure Data Factory atau Synapse Analytics memproses data di layanan penyimpanan tertaut dengan menggunakan layanan komputasi tertaut. Ini berisi urutan kegiatan yang setiap aktivitasnya melakukan operasi pemrosesan tertentu. Artikel ini menjelaskan Aktivitas U-SQL Data Lake Analytics yang menjalankan skrip U-SQL pada layanan komputasi tertaut Azure Data Lake Analytics.
Buat akun Azure Data Lake Analytics sebelum membuat alur dengan Aktivitas U-SQL Data Lake Analytics. Untuk mempelajari tentang Azure Data Lake Analytics, lihat Mulai dengan Azure Data Lake Analytics.
Menambahkan aktivitas U-SQL untuk Azure Data Lake Analytics ke alur dengan UI
Untuk menggunakan aktivitas U-SQL untuk Azure Data Lake Analytics dalam alur, selesaikan langkah-langkah berikut:
Cari Data Lake di panel Aktivitas alur, dan seret aktivitas U-SQL ke kanvas alur.
Pilih aktivitas U-SQL baru di kanvas jika belum dipilih.
Pilih tab akun ADLA untuk memilih atau membuat layanan tertaut Azure Data Lake Analytics baru yang akan digunakan untuk menjalankan aktivitas U-SQL.
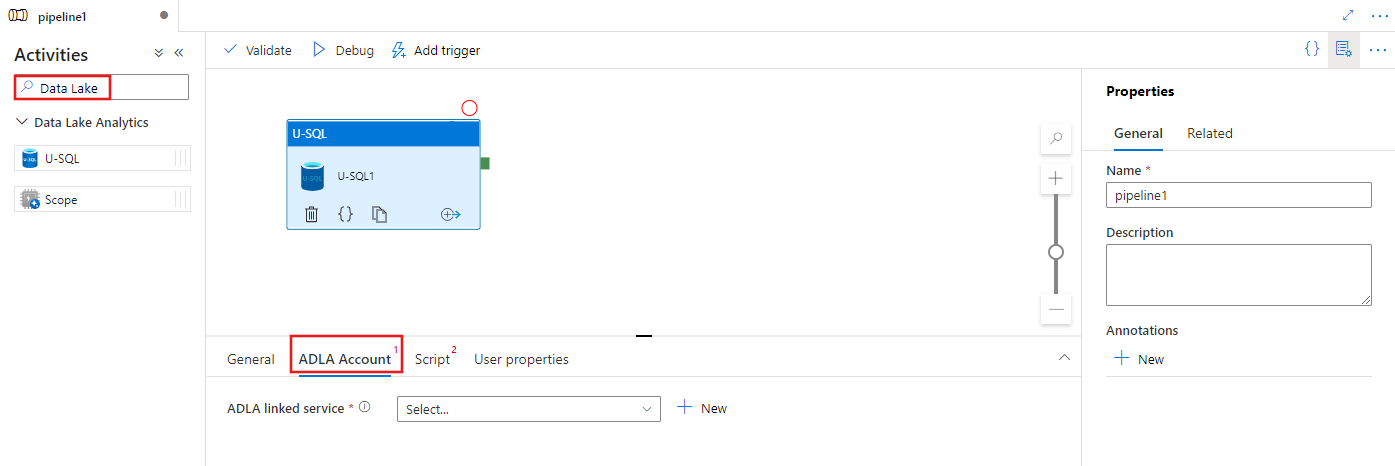
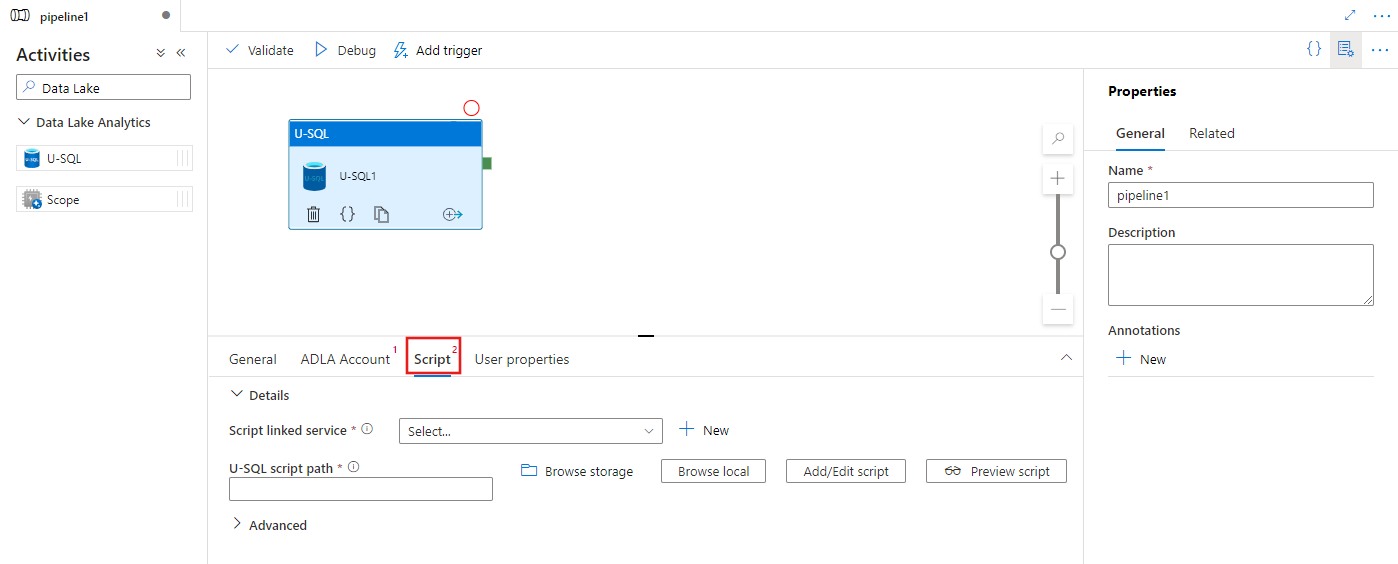
Pilih tab Skrip untuk memilih atau membuat layanan tertaut penyimpanan baru, dan jalur di dalam lokasi penyimpanan, yang akan menghosting skrip.
layanan tertaut Azure Data Lake Analytics
Anda membuat layanan tertaut Azure Data Lake Analytics untuk menautkan layanan komputasi Azure Data Lake Analytics ke ruang kerja Azure Data Factory atau Synapse Analytics. Aktivitas Analitik Data Lake U-SQL dalam pipeline berkaitan dengan layanan tertaut ini.
Tabel berikut ini mendeskripsikan properti generik yang digunakan dalam definisi JSON.
| Properti | Deskripsi | Wajib |
|---|---|---|
| jenis | Properti jenis harus diatur ke: AzureDataLakeAnalytics. | Ya |
| accountName | Nama Akun Azure Data Lake Analytics. | Ya |
| dataLakeAnalyticsUri | Azure Data Lake Analytics URI. | Tidak |
| subscriptionId | ID langganan Azure | Tidak |
| resourceGroupName | nama grup sumber daya Azure | Tidak |
Autentikasi principal layanan
Layanan tertaut Azure Data Lake Analytics memerlukan autentikasi perwakilan layanan untuk terhubung ke layanan Azure Data Lake Analytics. Untuk menggunakan autentikasi perwakilan layanan, daftarkan entitas aplikasi di Microsoft Entra ID dan berikan akses ke Data Lake Analytics dan Data Lake Store yang digunakannya. Untuk langkah-langkah terperinci, lihat Autentikasi layanan ke layanan. Catat nilai berikut, yang Anda gunakan untuk menentukan layanan tertaut:
- ID aplikasi
- Kunci Aplikasi
- ID Penyewa
Berikan izin perwakilan layanan ke Azure Data Lake Analytics Anda menggunakan Wizard Pengguna Tambahkan.
Gunakan autentikasi perwakilan layanan dengan menentukan properti berikut:
| Properti | Deskripsi | Wajib |
|---|---|---|
| servicePrincipalId | Menentukan ID klien aplikasi. | Ya |
| servicePrincipalKey | Tentukan kunci aplikasi. | Ya |
| tenant | Tentukan informasi penyewa (nama domain atau ID penyewa) tempat aplikasi Anda berada. Anda dapat mengambilnya dengan mengarahkan mouse ke sudut kanan atas portal Azure. | Ya |
Contoh: Autentikasi perwakilan layanan
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Untuk mempelajari layanan tertaut ini, lihat Layanan tertaut komputasi.
Aktivitas Data Lake Analytics U-SQL
Cuplikan JSON berikut mendefinisikan alur dengan Aktivitas U-SQL Data Lake Analytics. Definisi aktivitas memiliki referensi ke layanan tertaut Azure Data Lake Analytics yang Anda buat sebelumnya. Untuk menjalankan skrip U-SQL Data Lake Analytics, layanan mengirimkan skrip yang Anda tentukan ke Data Lake Analytics, dan input dan output yang diperlukan didefinisikan dalam skrip agar Data Lake Analytics mengambil dan menghasilkan.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
Tabel berikut ini menjelaskan nama dan deskripsi properti yang spesifik untuk aktivitas ini.
| Properti | Deskripsi | Wajib |
|---|---|---|
| nama | Nama aktivitas di dalam alur | Ya |
| deskripsi | Teks yang menjelaskan apa yang dilakukan aktivitas. | Tidak |
| jenis | Untuk aktivitas Data Lake Analytics U-SQL, jenis aktivitasnya adalah DataLakeAnalyticsU-SQL. | Ya |
| NamaLayananTertaut | Layanan Tertaut ke Azure Data Lake Analytics. Untuk mempelajari layanan tertaut ini, lihat artikel Layanan tertaut komputasi. | Ya |
| scriptPath | Jalur ke folder yang berisi skrip U-SQL. Nama berkas sensitif terhadap huruf besar/kecil. | Ya |
| scriptLinkedService | Layanan tertaut yang menautkan Azure Data Lake Store atau Azure Storage yang berisi skrip | Ya |
| derajatParalelisme | Jumlah maksimum node yang digunakan secara bersamaan untuk menjalankan pekerjaan. | Tidak |
| prioritas | Menentukan pekerjaan mana dari semua yang diantrekan harus dipilih untuk dijalankan terlebih dahulu. Semakin rendah angkanya, semakin tinggi prioritasnya. | Tidak |
| parameter | Parameter untuk diteruskan ke skrip U-SQL. | Tidak |
| runtimeVersion | Versi runtime dari mesin U-SQL untuk digunakan. | Tidak |
| modeKompilasi | Mode kompilasi U-SQL. Harus menjadi salah satu nilai ini: Semantik: Hanya lakukan pemeriksaan semantik dan pemeriksaan kewarasan yang diperlukan, Penuh: Lakukan kompilasi penuh, termasuk pemeriksaan sintaks, pengoptimalan, pembuatan kode, dll., SingleBox: Lakukan kompilasi lengkap, dengan pengaturan TargetType ke SingleBox. Jika Anda tidak menentukan nilai untuk properti ini, server menentukan mode kompilasi yang optimal. |
Tidak |
Lihat SearchLogProcessing.txt untuk definisi skrip.
Contoh skrip U-SQL
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
Dalam contoh skrip di atas, input dan output ke skrip ditentukan dalam parameter @in dan @out. Nilai untuk parameter @in dan @out dalam skrip U-SQL diteruskan secara dinamis oleh layanan menggunakan bagian 'parameter'.
Anda dapat menentukan properti lain seperti degreeOfParallelism dan prioritas juga dalam definisi alur Anda untuk pekerjaan yang berjalan pada layanan Azure Data Lake Analytics.
Parameter dinamis
Dalam definisi jalur sampel, parameter masuk dan keluar ditetapkan dengan nilai yang dikodekan secara permanen.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
Dimungkinkan untuk menggunakan parameter dinamis sebagai gantinya. Contohnya:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
Dalam hal ini, file input masih diambil dari folder /datalake/input dan file output dihasilkan dalam folder /datalake/output. Nama file bersifat dinamis berdasarkan waktu mulai jendela yang ditentukan saat pipeline dipicu.
Konten terkait
Lihat artikel berikut yang menjelaskan cara mentransformasikan data dengan cara lain: