Apa itu Apache Flink® di Azure HDInsight di AKS? (Pratinjau)
Catatan
Kami akan menghentikan Azure HDInsight di AKS pada 31 Januari 2025. Sebelum 31 Januari 2025, Anda harus memigrasikan beban kerja anda ke Microsoft Fabric atau produk Azure yang setara untuk menghindari penghentian tiba-tiba beban kerja Anda. Kluster yang tersisa pada langganan Anda akan dihentikan dan dihapus dari host.
Hanya dukungan dasar yang akan tersedia hingga tanggal penghentian.
Penting
Fitur ini masih dalam mode pratinjau. Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure mencakup lebih banyak persyaratan hukum yang berlaku untuk fitur Azure yang dalam versi beta, dalam pratinjau, atau belum dirilis ke ketersediaan umum. Untuk informasi tentang pratinjau khusus ini, lihat Azure HDInsight pada informasi pratinjau AKS. Untuk pertanyaan atau saran fitur, kirimkan permintaan di AskHDInsight dengan detail dan ikuti kami untuk pembaruan lebih lanjut di Komunitas Azure HDInsight.
Apache Flink adalah kerangka kerja dan mesin pemrosesan terdistribusi untuk komputasi stateful melalui aliran data yang tidak terbatas dan terikat. Flink telah dirancang untuk berjalan di semua lingkungan kluster umum, melakukan komputasi dan aplikasi streaming stateful pada kecepatan dalam memori dan pada skala apa pun. Aplikasi diparalelkan menjadi mungkin ribuan tugas yang didistribusikan dan dijalankan secara bersamaan dalam kluster. Oleh karena itu, aplikasi dapat menggunakan vCPU dalam jumlah tak terbatas, memori utama, disk, dan IO jaringan. Selain itu, Flink dengan mudah mempertahankan status aplikasi besar. Algoritma titik pemeriksaan asinkron dan inkremental memastikan pengaruh minimal pada latensi pemrosesan sambil menjamin konsistensi status persis sekali.
Apache Flink adalah mesin analitik yang dapat diskalakan secara besar-besaran untuk pemrosesan aliran.
Beberapa fitur utama yang ditawarkan Flink adalah:
- Operasi pada aliran terikat dan tidak terbatas
- Dalam performa memori
- Kemampuan untuk komputasi streaming dan batch
- Latensi rendah, operasi throughput tinggi
- Tepat sekali pemrosesan
- Ketersediaan Tinggi
- Toleransi status dan kesalahan
- Kompatibel sepenuhnya dengan ekosistem Hadoop
- API SQL Terpadu untuk aliran dan batch
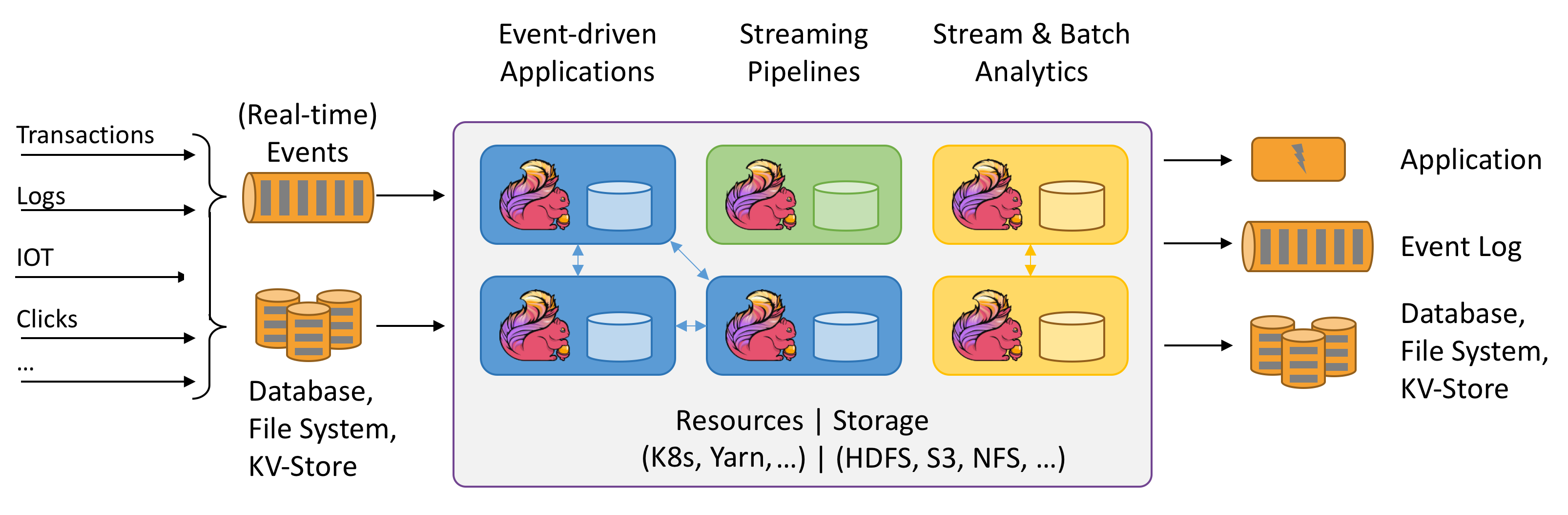
Apache Flink adalah pilihan yang sangat baik untuk mengembangkan dan menjalankan berbagai jenis aplikasi karena set fiturnya yang luas. Fitur Flink mencakup dukungan untuk pemrosesan aliran dan batch, manajemen status canggih, semantik pemrosesan waktu peristiwa, dan jaminan konsistensi persis sekali untuk status. Flink tidak memiliki satu titik kegagalan. Flink telah terbukti menskalakan ke ribuan inti dan terabyte status aplikasi, memberikan throughput tinggi dan latensi rendah, dan mendukung beberapa aplikasi pemrosesan aliran yang paling menuntut di dunia.
- Deteksi penipuan: Flink dapat digunakan untuk mendeteksi transaksi atau aktivitas penipuan secara real time dengan menerapkan aturan kompleks dan model pembelajaran mesin pada data streaming.
- Deteksi anomali: Flink dapat digunakan untuk mengidentifikasi outlier atau pola abnormal dalam data streaming, seperti pembacaan sensor, lalu lintas jaringan, atau perilaku pengguna.
- Peringatan berbasis aturan: Flink dapat digunakan untuk memicu pemberitahuan atau pemberitahuan berdasarkan kondisi atau ambang batas yang telah ditentukan sebelumnya pada data streaming, seperti suhu, tekanan, atau harga saham.
- Pemantauan proses bisnis: Flink dapat digunakan untuk melacak dan menganalisis status dan performa proses bisnis atau alur kerja secara real time, seperti pemenuhan pesanan, pengiriman, atau layanan pelanggan.
- Aplikasi web (jejaring sosial): Flink dapat digunakan untuk mendukung aplikasi web yang memerlukan pemrosesan data yang dihasilkan pengguna secara real time, seperti pesan, suka, komentar, atau rekomendasi.
Baca selengkapnya tentang kasus penggunaan umum yang dijelaskan pada kasus Penggunaan Apache Flink
Kluster Apache Flink di HDInsight di AKS adalah layanan yang dikelola sepenuhnya. Manfaat membuat kluster Flink di HDInsight di AKS tercantum di sini.
| Fitur | Deskripsi |
|---|---|
| Pembuatan yang mudah | Anda dapat membuat kluster Flink baru di HDInsight dalam hitungan menit menggunakan portal Azure, Azure PowerShell, atau SDK. Lihat Mulai menggunakan kluster Apache Flink di HDInsight di AKS. |
| Kemudahan penggunaan | Kluster Flink di HDInsight di AKS mencakup manajemen konfigurasi berbasis portal, dan penskalakan. Selain ini dengan API manajemen pekerjaan, Anda menggunakan REST API atau portal Azure untuk manajemen pekerjaan. |
| REST API | Kluster Flink di HDInsight di AKS mencakup Job management API, metode pengiriman pekerjaan Flink berbasis REST API untuk mengirimkan dan memantau pekerjaan dari jarak jauh pada portal Azure. |
| Jenis Penyebaran | Flink dapat menjalankan aplikasi dalam mode Sesi atau mode Aplikasi. Saat ini HDInsight di AKS hanya mendukung kluster Sesi. Anda dapat menjalankan beberapa pekerjaan Flink pada kluster Sesi. Mode aplikasi ada di peta strategi untuk HDInsight pada kluster AKS |
| Dukungan untuk Metastore | Kluster Flink di HDInsight di AKS dapat mendukung katalog dengan Apache Hive Metastore dalam format file terbuka yang berbeda dengan titik pemeriksaan jarak jauh ke Azure Data Lake Storage Gen2. |
| Dukungan untuk Azure Storage | Kluster Flink di HDInsight dapat menggunakan Azure Data Lake Storage Gen2 sebagai sink File. Untuk informasi selengkapnya tentang Data Lake Storage Gen2, lihat Azure Data Lake Storage Gen2. |
| Integrasi dengan layanan Azure | Kluster Flink di HDInsight di AKS dilengkapi dengan integrasi ke Kafka bersama dengan Azure Event Hubs dan Azure HDInsight. Anda dapat membangun aplikasi streaming menggunakan Azure Event Hubs atau HDInsight. |
| Adaptasi | HDInsight pada AKS memungkinkan Anda untuk menskalakan node kluster Flink berdasarkan jadwal dengan fitur Autoscale. Lihat Menskalakan Azure HDInsight secara otomatis pada kluster AKS. |
| Backend Status | HDInsight di AKS menggunakan RocksDB sebagai StateBackend default. RocksDB adalah penyimpanan nilai kunci persisten yang dapat disematkan untuk penyimpanan cepat. |
| Titik pemeriksaan | Titik pemeriksaan diaktifkan di HDInsight pada kluster AKS secara default. Pengaturan default pada HDInsight pada AKS mempertahankan lima titik pemeriksaan terakhir dalam penyimpanan persisten. Jika, pekerjaan Anda gagal, pekerjaan dapat dimulai ulang dari titik pemeriksaan terbaru. |
| Titik Pemeriksaan Inkremental | RocksDB mendukung Titik Pemeriksaan Bertahap. Kami mendorong penggunaan titik pemeriksaan inkremental untuk status besar, Anda perlu mengaktifkan fitur ini secara manual. Mengatur default di Anda flink-conf.yaml: state.backend.incremental: true mengaktifkan titik pemeriksaan inkremental, kecuali aplikasi mengambil alih pengaturan ini dalam kode. Pernyataan ini benar secara default. Anda dapat mengonfigurasi nilai ini secara langsung dalam kode (mengambil alih default konfigurasi) EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true); . Secara default, kami mempertahankan lima titik pemeriksaan terakhir di dir titik pemeriksaan yang dikonfigurasi. Nilai ini dapat diubah dengan mengubah konfigurasi pada bagian manajemen konfigurasi state.checkpoints.num-retained: 5 |
Kluster Apache Flink di HDInsight pada AKS menyertakan komponen berikut, kluster tersedia pada kluster secara default.
Lihat Peta Strategi tentang apa yang akan segera hadir!
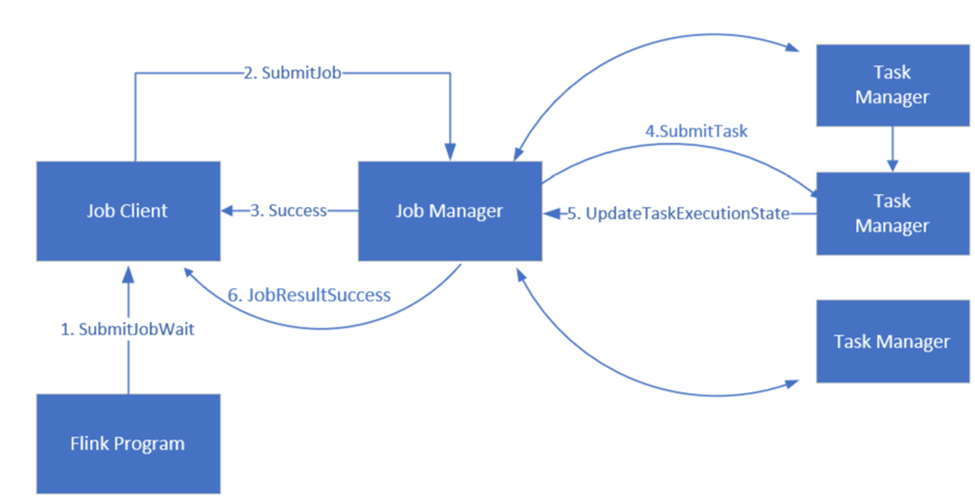
Flink menjadwalkan pekerjaan menggunakan tiga komponen terdistribusi, manajer Pekerjaan, Manajer tugas, dan Klien Pekerjaan, yang diatur dalam pola Leader-Follower.
Pekerjaan Flink: Pekerjaan atau program Flink terdiri dari beberapa tugas. Tugas adalah unit dasar eksekusi di Flink. Setiap tugas Flink memiliki beberapa instans tergantung pada tingkat paralelisme dan setiap instans dijalankan pada TaskManager.
Manajer pekerjaan: Manajer pekerjaan bertindak sebagai penjadwal dan menjadwalkan tugas pada manajer tugas.
Pengelola tugas: Pengelola Tugas dilengkapi dengan satu atau beberapa slot untuk menjalankan tugas secara paralel.
Klien pekerjaan: Klien pekerjaan berkomunikasi dengan manajer pekerjaan untuk mengirimkan pekerjaan Flink
Flink Web UI: Flink menampilkan UI web untuk memeriksa, memantau, dan men-debug aplikasi yang berjalan.
- Situs Web Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink, dan nama proyek sumber terbuka terkait adalah merek dagang dari Apache Software Foundation (ASF).