Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Vektor adalah penyematan dimensi tinggi yang mewakili teks, gambar, dan konten lainnya secara matematis. Azure AI Search menyimpan vektor di tingkat bidang, memungkinkan konten vektor dan nonvektor berdampingan dalam indeks pencarian yang sama.
Indeks pencarian menjadi indeks vektor saat Anda menentukan bidang vektor dan konfigurasi vektor. Untuk memasukkan data ke dalam bidang vektor, Anda dapat menggunakan penyematan yang telah dikomputasi sebelumnya atau memanfaatkan vektorisasi terintegrasi, sebuah fungsi Azure AI Search yang menghasilkan penyematan selama pengindeksan.
Pada waktu kueri, bidang vektor dalam indeks Anda memungkinkan pencarian kesamaan, di mana sistem mengambil dokumen yang vektornya paling mirip dengan kueri vektor. Anda dapat menggunakan pencarian vektor untuk pencocokan kesamaan sendiri atau pencarian hibrid untuk kombinasi kesamaan dan pencocokan kata kunci.
Artikel ini membahas konsep utama untuk membuat dan mengelola indeks vektor, termasuk:
- Pola pemanggilan vektor
- Konten (bidang dan konfigurasi vektor)
- Struktur data fisik
- Operasi dasar
Petunjuk / Saran
Ingin segera memulai? Lihat Membuat indeks vektor.
Pola pemanggilan vektor
Azure AI Search mendukung dua pola untuk pengambilan vektor:
Pencarian klasik. Pola ini menggunakan bilah pencarian, input kueri, dan hasil yang dirender. Selama eksekusi kueri, mesin pencari atau kode aplikasi Anda mem-vektorisasi input pengguna. Mesin pencari kemudian melakukan pencarian vektor di atas bidang vektor dalam indeks Anda dan merumuskan respons yang Anda render di aplikasi klien.
Di Azure AI Search, hasil dikembalikan sebagai kumpulan baris yang diratakan, dan Anda dapat memilih bidang mana yang akan disertakan dalam respons. Meskipun mesin pencari cocok pada vektor, indeks Anda harus memiliki konten nonvektor yang dapat dibaca manusia untuk mengisi hasil pencarian. Pencarian klasik mendukung kueri vektor dan kueri hibrid.
Pencarian generatif. Model bahasa menggunakan data dari Azure AI Search untuk merespons kueri pengguna. Lapisan orkestrasi biasanya mengoordinasikan permintaan dan mempertahankan konteks, memasukkan hasil pencarian ke dalam model obrolan seperti GPT. Pola ini didasarkan pada arsitektur retrieval-augmented generation (RAG), di mana indeks pencarian menyediakan data pendukung.
Skema indeks vektor
Skema indeks vektor memerlukan hal berikut:
- Nama
- Bidang kunci (string)
- Satu atau beberapa bidang vektor
- Konfigurasi vektor
Bidang nonvektor tidak diperlukan, tetapi sebaiknya sertakan untuk kueri hibrid atau untuk mengembalikan konten verbatim yang tidak melalui model bahasa. Untuk informasi selengkapnya, lihat Membuat indeks vektor.
Skema indeks Anda harus mencerminkan pola pengambilan vektor Anda. Bagian ini sebagian besar mencakup komposisi bidang untuk pencarian klasik, tetapi juga menyediakan panduan skema untuk pencarian generatif.
Konfigurasi bidang vektor dasar
Bidang vektor memiliki jenis dan properti data yang unik. Berikut tampilan bidang vektor dalam kumpulan bidang:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Hanya jenis data tertentu yang didukung untuk bidang vektor. Jenis yang paling umum adalah Collection(Edm.Single), tetapi menggunakan jenis sempit dapat menghemat penyimpanan.
Bidang vektor harus dapat dicari dan diambil, tetapi tidak dapat difilter, dapat difaset, atau dapat diurutkan. Mereka juga tidak dapat memiliki penganalisis, normalizer, atau penetapan peta sinonim.
Properti dimensions harus diatur ke jumlah penyematan yang dihasilkan oleh model penyematan. Misalnya, text-embedding-ada-002 menghasilkan 1.536 penyematan untuk setiap potongan teks.
Bidang vektor diindeks menggunakan algoritma yang ditentukan dalam profil pencarian vektor, yang didefinisikan di tempat lain dalam indeks dan tidak ditampilkan dalam contoh ini. Untuk informasi selengkapnya, lihat Menambahkan konfigurasi pencarian vektor.
Kumpulan bidang untuk beban kerja vektor dasar
Indeks vektor memerlukan lebih dari sekadar bidang vektor. Misalnya, semua indeks harus memiliki bidang kunci, yang ada id dalam contoh berikut:
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Bidang lain, seperti bidang content, menyediakan padanan yang dapat dibaca manusia untuk bidang content_vector. Jika Anda menggunakan model bahasa secara eksklusif untuk rumusan respons, Anda dapat menghilangkan bidang konten nonvektor, tetapi solusi yang mendorong hasil pencarian langsung ke aplikasi klien harus memiliki konten nonvektor.
Bidang metadata berguna untuk filter, terutama jika menyertakan informasi asal tentang dokumen sumber. Meskipun Anda tidak dapat memfilter langsung pada bidang vektor, Anda dapat mengatur mode prafilter, postfilter, atau postfilter ketat (pratinjau) untuk memfilter sebelum atau sesudah eksekusi kueri vektor.
Skema yang dihasilkan oleh wizard impor
Kami merekomendasikan wizard Impor data (baru) untuk evaluasi dan pengujian bukti konsep. Wizard menghasilkan contoh skema di bagian ini.
Wizard memotong konten Anda ke dalam dokumen pencarian yang lebih kecil, yang menguntungkan aplikasi RAG yang menggunakan model bahasa untuk merumuskan respons. Chunking membantu Anda tetap berada dalam batas input model bahasa dan batas token penilai semantik. Ini juga meningkatkan presisi dalam pencarian kesamaan dengan mencocokkan kueri terhadap gugus yang ditarik dari beberapa dokumen induk. Untuk informasi selengkapnya, lihat Memotong dokumen besar untuk solusi pencarian vektor.
Untuk setiap dokumen pencarian dalam contoh berikut, ada satu ID gugus, ID induk, gugus, judul, dan bidang vektor. Panduan:
Mengisi bidang
chunk_iddanparent_iddengan metadata blob yang dikodekan base64 (lintasan).Mengekstrak bidang
chunkdari konten blob dan bidangtitledari nama blob.Bidang
vectordibuat dengan memanggil model penyematan Azure OpenAI yang Anda sediakan untuk mem-vektorisasi bidangchunk. Hanya bidang vektor yang sepenuhnya dihasilkan selama proses ini.
"name": "example-index-from-import-wizard",
"fields": [
{ "name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Skema untuk pencarian generatif
Jika Anda merancang penyimpanan vektor untuk RAG dan aplikasi gaya obrolan, Anda dapat membuat dua indeks:
- Satu untuk konten statis yang Anda indeks dan vektorisasi.
- Satu untuk percakapan yang dapat digunakan dalam alur perintah.
Untuk tujuan ilustrasi, bagian ini menggunakan chat-with-your-data-solution-accelerator untuk membuat indeks chat-index dan conversations.
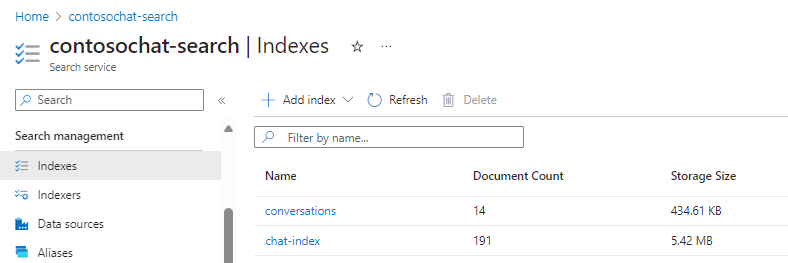
Bidang berikut dari chat-index mendukung pengalaman pencarian generatif:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Bidang berikut dari conversations mendukung orkestrasi dan riwayat obrolan.
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
Cuplikan layar berikut menunjukkan hasil pencarian di conversationsPenjelajah pencarian:
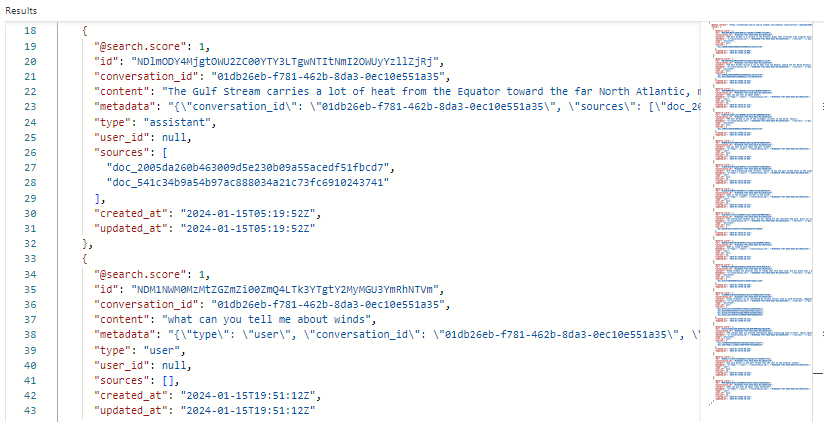
Dalam contoh kami, skor pencarian adalah 1,00 karena pencarian tidak memenuhi syarat. Beberapa bidang mendukung orkestrasi dan alur perintah:
-
conversation_idmengidentifikasi setiap sesi obrolan. -
typemenunjukkan apakah konten berasal dari pengguna atau asisten. -
created_atdanupdated_atmenghapus obrolan dari riwayat setelah waktu tertentu.
Struktur dan ukuran fisik
Dalam Azure AI Search, struktur fisik indeks sebagian besar merupakan implementasi internal. Anda dapat mengakses skemanya, memuat, dan mengkueri kontennya, memantau ukurannya, dan mengelola kapasitasnya. Namun, Microsoft mengelola infrastruktur dan struktur data fisik yang disimpan dengan layanan pencarian Anda.
Ukuran dan substansi indeks ditentukan oleh:
Kuantitas dan komposisi dokumen Anda.
Atribut pada bidang masing-masing. Misalnya, lebih banyak penyimpanan diperlukan untuk bidang yang dapat difilter.
Konfigurasi indeks, termasuk konfigurasi vektor yang menentukan bagaimana struktur navigasi internal dibuat. Anda dapat memilih HNSW atau KNN lengkap untuk pencarian kesamaan.
Azure AI Search memberlakukan batasan pada penyimpanan vektor, yang membantu mempertahankan sistem yang seimbang dan stabil untuk semua beban kerja. Untuk membantu Anda tetap di bawah batas, penggunaan vektor dilacak dan dilaporkan secara terpisah di portal Microsoft Azure dan secara terprogram melalui statistik layanan dan indeks.
Cuplikan layar berikut menunjukkan layanan S1 yang dikonfigurasi dengan satu partisi dan satu replika. Layanan ini memiliki 24 indeks kecil, masing-masing dengan rata-rata satu bidang vektor yang terdiri dari 1.536 penyematan. Ubin kedua menunjukkan kuota dan penggunaan untuk indeks vektor. Karena indeks vektor adalah struktur data internal yang dibuat untuk setiap bidang vektor, penyimpanan untuk indeks vektor selalu merupakan sebagian kecil dari penyimpanan keseluruhan yang digunakan oleh indeks. Bidang nonvektor dan struktur data lainnya mengonsumsi sisanya.
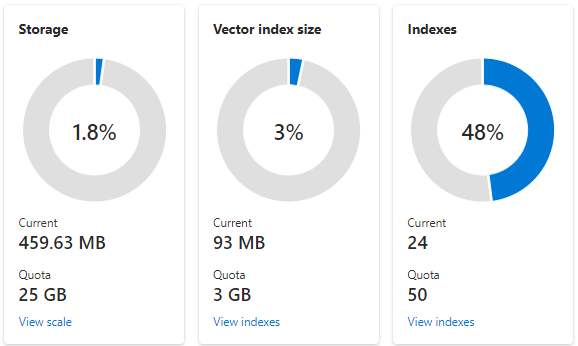
Batas dan estimasi indeks vektor tercakup dalam artikel lain, tetapi dua poin yang perlu ditekankan adalah bahwa penyimpanan maksimum tergantung pada tanggal pembuatan dan tingkat harga layanan pencarian Anda. Layanan tingkat yang sama yang lebih baru memiliki kapasitas yang jauh lebih banyak untuk indeks vektor. Untuk alasan ini, Anda harus:
Periksa tanggal pembuatan layanan pencarian Anda. Jika dibuat sebelum 3 April 2024, Anda mungkin dapat meningkatkan layanan Anda untuk kapasitas yang lebih besar.
Pilih tingkat yang dapat diskalakan jika Anda mengantisipasi fluktuasi dalam persyaratan penyimpanan vektor. Untuk layanan pencarian yang lebih lama, level Dasar dikonfigurasi pada satu partisi. Pertimbangkan Standar 1 (S1) dan yang lebih tinggi untuk fleksibilitas yang lebih baik dan performa yang lebih cepat. Anda juga dapat beralih antara tingkat Dasar dan Standar (S1, S2, dan S3).
Operasi dasar dan interaksi
Bagian ini memperkenalkan operasi runtime vektor, termasuk menyambungkan dan mengamankan satu indeks.
Catatan
Tidak ada dukungan portal atau API untuk memindahkan atau menyalin indeks. Biasanya, Anda mengarahkan penyebaran aplikasi ke layanan pencarian yang berbeda (menggunakan nama indeks yang sama) atau merevisi nama untuk membuat salinan di layanan pencarian Anda saat ini lalu membangunnya.
Isolasi indeks
Di Azure AI Search, Anda bekerja dengan satu indeks dalam satu waktu. Semua operasi terkait indeks menargetkan satu indeks. Tidak ada konsep indeks terkait atau gabungan indeks independen untuk pengindeksan atau kueri.
Terus tersedia
Indeks segera tersedia untuk kueri segera setelah dokumen pertama diindeks, tetapi tidak sepenuhnya beroperasi sampai semua dokumen diindeks. Secara internal, indeks didistribusikan di seluruh partisi dan dijalankan pada replika. Indeks fisik dikelola secara internal. Anda mengelola indeks logis.
Indeks terus tersedia dan tidak dapat dijeda atau diambil secara offline. Karena dirancang untuk operasi berkelanjutan, pembaruan pada kontennya dan penambahan indeks itu sendiri terjadi secara real time. Jika permintaan bertepatan dengan pembaruan dokumen, kueri mungkin untuk sementara mengembalikan hasil yang tidak lengkap.
Kelangsungan kueri ada untuk operasi dokumen, seperti refresh atau penghapusan, dan untuk modifikasi yang tidak memengaruhi struktur atau integritas indeks yang ada, seperti menambahkan bidang baru. Pembaruan struktural, seperti mengubah bidang yang ada, biasanya dikelola menggunakan alur kerja drop-and-rebuild di lingkungan pengembangan atau dengan membuat versi baru indeks pada layanan produksi.
Untuk menghindari pembangunan ulang indeks, beberapa pelanggan yang melakukan perubahan kecil membuat "versi" baru dari sebuah bidang yang hidup berdampingan dengan versi sebelumnya. Seiring waktu, ini mengarah ke konten yatim melalui bidang usang dan definisi penganalisis kustom yang usang, terutama dalam indeks produksi yang mahal untuk direplikasi. Anda dapat mengatasi masalah ini selama pembaruan terencana untuk indeks sebagai bagian dari manajemen siklus hidup indeks.
Koneksi titik akhir
Semua permintaan pengindeksan dan kueri vektor menargetkan indeks. Titik akhir biasanya merupakan salah satu dari berikut ini:
| Titik akhir | Kontrol koneksi dan akses |
|---|---|
<your-service>.search.windows.net/indexes |
Menargetkan kumpulan indeks. Digunakan saat membuat, mencantumkan, atau menghapus indeks. Hak admin diperlukan untuk operasi ini dan tersedia melalui kunci API admin atau peran Kontributor Pencarian. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Menargetkan kumpulan dokumen dari satu indeks. Digunakan saat mengkueri indeks atau refresh data. Untuk kueri, hak akses baca sudah memadai dan tersedia melalui kunci API kueri atau melalui peran pembaca data. Untuk refresh data, hak admin diperlukan. |
Cara menyambungkan ke Azure AI Search
Pastikan Anda memiliki izin atau kunci akses API. Kecuali Anda mengkueri indeks yang sudah ada, Anda memerlukan hak admin atau penetapan peran Kontributor untuk mengelola dan menampilkan konten di layanan pencarian.
Mulailah dengan portal Azure. Orang yang membuat layanan pencarian dapat melihat dan mengelolanya, termasuk memberikan akses ke orang lain di halaman Kontrol akses (IAM).
Lanjutkan ke klien lain untuk akses terprogram. Untuk langkah pertama, kami merekomendasikan Mulai Cepat: Pencarian vektor menggunakan REST dan repositori azure-search-vector-samples .
Mengelola penyimpanan vektor
Azure menyediakan platform pemantauan yang menyertakan pengelogan dan pemberitahuan diagnostik. Kami menyarankan Anda:
Akses aman ke data vektor
Azure AI Search mengimplementasikan enkripsi data, koneksi privat untuk skenario tanpa internet, dan penetapan peran untuk akses aman melalui ID Microsoft Entra. Untuk informasi selengkapnya tentang fitur keamanan perusahaan, lihat Keamanan di Pencarian Azure AI.