Pemantauan dan diagnostik untuk Azure Service Fabric
Artikel ini menyediakan gambaran umum pemantauan dan diagnostik untuk Azure Service Fabric. Pemantauan dan diagnostik sangat penting untuk mengembangkan, menguji, dan menyebarkan beban kerja di lingkungan cloud apa pun. Contohnya, Anda dapat melacak bagaimana aplikasi Anda digunakan, tindakan yang diambil oleh platform Service Fabric, pemanfaatan sumber daya Anda dengan penghitung kinerja, dan kesehatan keseluruhan kluster Anda. Anda dapat menggunakan informasi ini untuk mendiagnosis dan memperbaiki masalah, dan mencegahnya terjadi di masa mendatang. Beberapa bagian berikutnya akan menjelaskan secara singkat setiap area pemantauan Service Fabric untuk dipertimbangkan beban kerja produksi.
Catatan
Artikel ini baru-baru ini diperbarui untuk menggunakan istilah log Azure Monitor alih-alih Analitik Log. Data log masih disimpan di ruang kerja Analitik Log dan masih dikumpulkan dan dianalisis oleh layanan Analitik Log yang sama. Kami memperbarui terminologi untuk mencerminkan peran log di Azure Monitor dengan lebih baik. Lihat Perubahan terminologi Azure Monitor untuk detailnya.
Pemantauan Aplikasi
Pemantauan aplikasi melacak bagaimana fitur dan komponen aplikasi Anda digunakan. Anda ingin memantau aplikasi untuk memastikan masalah yang memengaruhi pengguna bisa diketahui. Pemantauan aplikasi adalah tanggung jawab pengguna yang mengembangkan aplikasi dan layanannya karena bersifat unik dengan logika bisnis aplikasi Anda. Memantau aplikasi Anda dapat berguna dalam skenario berikut:
- Berapa banyak lalu lintas yang dialami aplikasi saya? - Apakah Anda perlu menskalakan layanan untuk memenuhi permintaan pengguna atau mengatasi potensi penyempitan dalam aplikasi Anda?
- Apakah layanan saya untuk panggilan layanan berhasil dan dilacak?
- Tindakan apa yang diambil oleh pengguna aplikasi saya? - Mengumpulkan data telemetri dapat memandu pengembangan fitur di masa mendatang dan diagnostik yang lebih baik untuk kesalahan aplikasi
- Apakah aplikasi saya menjatuhkan pengecualian yang tidak tertangani?
- Apa yang terjadi dalam layanan yang berjalan di dalam kontainer saya?
Hal yang hebat tentang pemantauan aplikasi adalah bahwa pengembang dapat menggunakan alat dan kerangka kerja apa pun yang mereka inginkan karena berlaku dalam konteks aplikasi Anda! Anda dapat mempelajari selengkapnya tentang solusi Azure untuk pemantauan aplikasi dengan Azure Monitor Application Insights dalam Analisis peristiwa dengan Application Insights. Kami juga memiliki tutorial tentang cara mengatur ini untuk Aplikasi .NET. Tutorial ini menjelaskan cara menginstal alat yang tepat, contoh untuk menulis data telemetri kustom di aplikasi Anda, dan melihat diagnostik aplikasi dan data telemetri di portal Microsoft Azure.
Pemantauan (Kluster) platform
Pengguna memegang kendali atas data telemetri apa yang berasal dari aplikasi mereka sejak pengguna menulis kode itu sendiri, tetapi bagaimana dengan diagnostik dari platform Service Fabric? Salah satu tujuan Service Fabric adalah membuat aplikasi tangguh terhadap kegagalan perangkat keras. Tujuan ini dicapai melalui kemampuan layanan sistem platform untuk mendeteksi masalah infrastruktur dan beban kerja yang cepat mengalami failover ke node lain di kluster. Tetapi dalam kasus khusus ini, bagaimana jika layanan sistem itu sendiri yang memiliki masalah? Atau jika dalam upaya untuk menyebarkan atau memindahkan beban kerja, aturan untuk penempatan layanan dilanggar? Service Fabric menyediakan diagnostik untuk ini dan banyak lagi untuk memastikan Anda diberitahu tentang aktivitas yang terjadi di kluster Anda. Beberapa skenario sampel untuk pemantauan kluster meliputi:
Service Fabric menyediakan set peristiwa komprehensif di luar kotak. Peristiwa Service Fabric ini bisa diakses melalui EventStore atau saluran operasional (saluran peristiwa yang diekspos oleh platform).
Saluran acara Service Fabric - Pada Windows, acara Service Fabric tersedia dari satu penyedia ETW dengan set
logLevelKeywordFiltersyang relevan serta digunakan untuk memilih antara saluran Operasional dan Data & Olahpesan - ini adalah cara kami memisahkan peristiwa Service Fabric keluar yang akan difilter sesuai kebutuhan. Di Linux, peristiwa Service Fabric datang melalui LTTng dan diletakkan ke dalam tabel Penyimpanan, dari tempat peristiwa bisa difilter sesuai kebutuhan. Saluran ini berisi peristiwa terstruktur dan dikuratori yang dapat digunakan untuk lebih memahami status kluster Anda. Diagnostik diaktifkan secara default pada waktu pembuatan kluster, yang membuat tabel Azure Storage tempat peristiwa dari saluran ini dikirim untuk Anda ke kueri di masa mendatang.EventStore - EventStore adalah fitur yang ditawarkan oleh platform yang menyediakan peristiwa platform Service Fabric yang tersedia dalam Service Fabric Explorer dan melalui REST API. Anda dapat melihat tampilan snapshot tentang apa yang terjadi di kluster Anda untuk tiap-tiap entitas, misalnya node, layanan, aplikasi, dan kueri berdasarkan waktu acara. Anda juga bisa Baca selengkapnya tentang EventStore di Gambaran Umum EventStore.
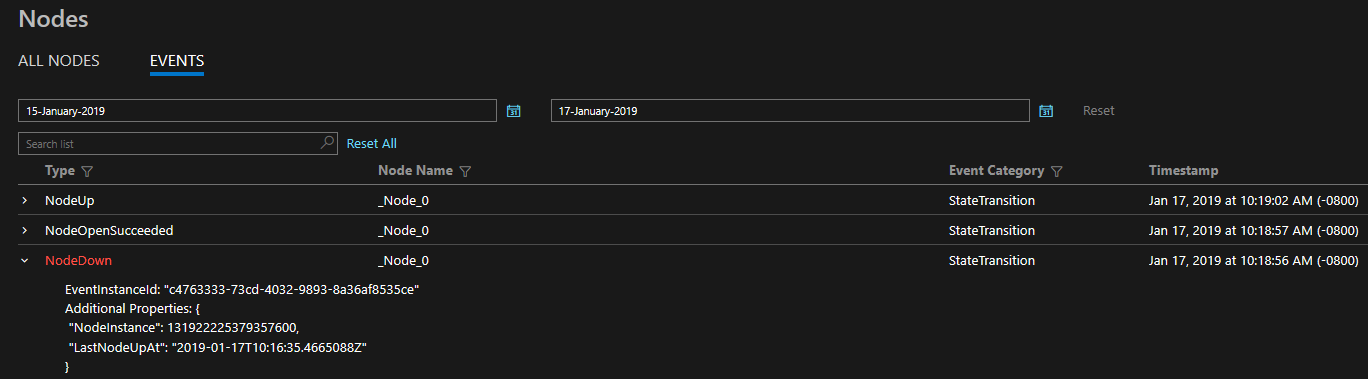
Diagnostik yang disediakan adalah dalam bentuk set peristiwa komprehensif di luar kotak. Peristiwa Service Fabric ini menggambarkan tindakan yang dilakukan oleh platform pada entitas yang berbeda seperti Node, Aplikasi, Layanan, Partisi dll. Dalam skenario terakhir di atas, jika node turun, platform akan memancarkan peristiwa NodeDown dan Anda dapat segera diberitahu oleh alat pemantauan pilihan Anda. Contoh umum lainnya termasuk ApplicationUpgradeRollbackStarted atau PartitionReconfigured selama failover. Peristiwa yang sama tersedia pada kluster Windows dan Linux.
Peristiwa dikirim melalui saluran standar di Windows dan Linux dan dapat dibaca oleh alat pemantauan apa pun yang mendukungnya. Solusi Azure Monitor adalah log Azure Monitor. Silakan baca selengkapnya tentang integrasi log Azure Monitor kami yang mencakup dasbor operasional kustom untuk kluster Anda dan beberapa contoh kueri tempat Anda dapat membuat peringatan. Konsep pemantauan kluster lainnya tersedia di Peristiwa tingkat platform dan pembuatan log.
Pemantauan kesehatan
Platform Service Fabric mencakup model kesehatan, yang menyediakan pelaporan kesehatan yang dapat diperluas untuk status entitas dalam kluster. Setiap node, aplikasi, layanan, partisi, replika, atau instans, memiliki status kesehatan yang terus diperbarui. Status kesehatan dapat berupa "Baik", "Peringatan", atau "Kesalahan". Pikirkan peristiwa Service Fabric sebagai kata kerja yang dilakukan oleh kluster ke berbagai entitas dan kesehatan sebagai kata sifat untuk setiap entitas. Setiap kali kesehatan transisi entitas tertentu, peristiwa juga akan dipancarkan. Dengan cara ini Anda dapat mengatur kueri dan peringatan untuk peristiwa kesehatan di alat pemantauan pilihan Anda, seperti peristiwa lainnya.
Selain itu, kami bahkan membiarkan pengguna mengambil alih kesehatan untuk entitas. Jika aplikasi Anda mengalami peningkatan dan Anda memiliki tes validasi gagal, Anda dapat menulis ke Service Fabric Health menggunakan Health API untuk menunjukkan aplikasi Anda sudah tidak sehat, dan Service Fabric akan secara otomatis memutar kembali peningkatan! Untuk model kesehatan lainnya, lihat pengantar pemantauan kesehatan Service Fabric
Watchdogs
Umumnya, pengawas adalah layanan terpisah yang mengawasi kesehatan dan pemuatan di seluruh layanan, titik akhir ping, dan melaporkan aktivitas kesehatan tak terduga di klaster. Tindakan ini dapat membantu mencegah kesalahan yang mungkin tidak terdeteksi hanya berdasarkan kinerja satu layanan. Watchdog juga merupakan tempat yang baik untuk menyimpan kode yang melakukan tindakan perbaikan yang tidak memerlukan interaksi pengguna, seperti membersihkan file log di penyimpanan pada interval waktu tertentu. Jika Anda menginginkan layanan pengawas SF sumber terbuka yang diimplementasikan sepenuhnya yang menyertakan model ekstensi pengawas yang mudah digunakan dan berjalan di klaster Windows dan Linux, lihat proyek FabricObserver. FabricObserver adalah perangkat lunak siap produksi. Kami menyarankan Anda untuk menerapkan FabricObserver ke klaster pengujian dan produksi dan memperluasnya untuk memenuhi kebutuhan Anda baik melalui model plug-innya atau dengan mem-forknya dan menulis pengamat built-in Anda sendiri. Yang pertama (plug-in) adalah pendekatan yang direkomendasikan.
Pemantauan (performa) infrastruktur
Kini kami telah membahas diagnostik dalam aplikasi Anda dan platform, bagaimana cara mengetahui perangkat keras berfungsi seperti yang diharapkan? Memantau infrastruktur yang mendasari adalah bagian penting dari memahami keadaan kluster Anda dan pemanfaatan sumber daya Anda. Mengukur kinerja sistem tergantung pada banyak faktor yang dapat bersifat subjektif tergantung beban kerja Anda. Faktor-faktor ini biasanya diukur melalui penghitung kinerja. Penghitung kinerja ini bisa berasal dari berbagai sumber termasuk sistem operasi, kerangka kerja .NET, atau platform Service Fabric itu sendiri. Beberapa skenario yang akan berguna
- Apakah saya menggunakan perangkat keras saya secara efisien? Apakah Anda ingin menggunakan perangkat keras pada CPU 90% atau CPU 10%. Ini berguna saat menskalakan kluster Anda, atau mengoptimalkan proses aplikasi Anda.
- Dapatkah saya memprediksi masalah infrastruktur secara proaktif? - banyak masalah didahului oleh perubahan mendadak (hilang) dalam performa, sehingga Anda dapat menggunakan penghitung kinerja seperti I/O jaringan dan pemanfaatan CPU untuk memprediksi dan mendiagnosis masalah secara proaktif.
Daftar penghitung kinerja yang harus dikumpulkan di tingkat infrastruktur dapat ditemukan pada metrik Performa.
Service Fabric juga menyediakan serangkaian penghitung kinerja untuk model pemrograman Reliable Service dan Actor. Jika Anda menggunakan salah satu model ini, penghitung kinerja mendapat informasi untuk memastikan bahwa aktor Anda berputar naik dan turun dengan benar, atau bahwa permintaan layanan andal Anda ditangani dengan cukup cepat. Untuk informasi selengkapnya, lihat Memantau Jarak Jauh Reliable Service dan Pemantauan performa untuk Reliable Actor.
Solusi Azure Monitor untuk mengumpulkan ini adalah log Azure Monitor seperti pemantauan tingkat platform. Anda harus menggunakan agen Analitik Log mengumpulkan penghitung kinerja yang sesuai, dan melihatnya di log Azure Monitor.
Pengaturan yang Disarankan
Sekarang setelah kami melampaui setiap area pemantauan dan contoh skenario, berikut ringkasan alat pemantauan Azure dan penyiapan yang diperlukan untuk memantau semua area di atas.
- Pemantauan aplikasi dengan Application Insights
- Pemantauan kluster dengan Agen Diagnostik dan log Azure Monitor
- Pemantauan infrastruktur dengan log Azure Monitor
Anda juga dapat menggunakan dan memodifikasi contoh templat ARM yang terletak di sini mengotomatiskan penyebaran semua sumber daya dan agen yang diperlukan.
Solusi pengelogan lainnya
Meskipun kami menyarankan dua solusi, log Azure Monitor dan Application Insights sudah membantu integrasi dengan Service Fabric, banyak peristiwa yang ditulis melalui penyedia ETW dan diperluas dengan solusi pengelogan. Anda juga harus melihat Tumpukan Elastis (khususnya jika Anda mempertimbangkan menjalankan kluster di lingkungan offline), Dynatrace, atau platform apa pun lainnya sesuai preferensi Anda. Kami memiliki daftar mitra terintegrasi yang tersedia di sini.
Hal penting untuk platform apa pun yang Anda pilih harus mencakup seberapa nyaman Anda dengan antarmuka pengguna, kemampuan kueri, visualisasi dan dasbor kustom yang tersedia, dan alat tambahan yang disediakan untuk meningkatkan pengalaman pemantauan Anda.
Langkah berikutnya
- Untuk memulai dengan instrumen aplikasi Anda, lihat Peristiwa tingkat aplikasi dan pembuatan log.
- Lakukan langkah-langkah untuk menyiapkan Application Insights untuk aplikasi Anda dengan Pantau dan diagnosis aplikasi ASP.NET Core di Service Fabric.
- Pelajari selengkapnya tentang memantau platform dan peristiwa yang disediakan Service Fabric untuk Anda: Aktivitas tingkat platform dan pembuatan log.
- Konfigurasi integrasi log Azure Monitor dengan Service Fabric pada Siapkan log Azure Monitor untuk kluster
- Pelajari cara menyiapkan log Azure Monitor untuk kontainer pemantauan: Pemantauan dan Diagnostik untuk Kontainer Windows dalam Azure Service Fabric.
- Lihat contoh masalah diagnostik dan solusi dengan Service Fabric dalam mendiagnosis skenario umum
- Lihat produk diagnostik lainnya yang terintegrasi dengan Service Fabric pada mitra diagnostik Service Fabric
- Pelajari tentang rekomendasi pemantauan umum untuk sumber daya Azure - Praktik terbaik - Pemantauan dan Diagnostik.