Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa guida fornisce istruzioni dettagliate per l'uso del riconoscimento personalizzato delle entità denominate (NER) con Microsoft Foundry o l'API REST. NER consente di rilevare e classificare le entità in testo non strutturato, ad esempio persone, luoghi, organizzazioni e numeri. Con NER personalizzato, è possibile eseguire il training dei modelli per identificare le entità specifiche dell'azienda e adattarle man mano che le esigenze si evolvono.
Per iniziare, viene fornito un contratto di prestito di esempio come set di dati per creare un modello NER personalizzato ed estrarre queste entità chiave:
- Data del contratto
- Nome, indirizzo, città e stato del mutuatario
- Nome del creditore, indirizzo, città e stato
- Importi del mutuo e degli interessi
Note
- Se si dispone già di una lingua di Azure in Strumenti Foundry o di risorse multiservizio, usate autonomamente o tramite Language Studio, è possibile continuare a usare tali risorse di linguaggio esistenti all'interno del portale di Microsoft Foundry. Per altre informazioni, vedere Come usare gli strumenti Foundry nel portale foundry.
Prerequisiti
Una sottoscrizione di Azure. Se non hai un account, puoi crearlo gratuitamente.
Autorizzazioni necessarie. Assicurarsi che alla persona che stabilisce l'account e al progetto sia assegnato il ruolo di proprietario dell'account di Azure AI a livello di sottoscrizione. In alternativa, avere il ruolo Collaboratore o Collaboratore Servizi cognitivi nell'ambito della sottoscrizione soddisfa anche questo requisito. Per altre informazioni, vedereControllo degli accessi in base al ruolo.
Risorsa linguistica con un account di archiviazione. Nella pagina Seleziona funzionalità aggiuntive, selezionare la casella Classificazione del testo personalizzata, Riconoscimento di entità denominate personalizzate, Analisi del sentiment personalizzata e Analisi del testo personalizzata per la salute per collegare un account di archiviazione necessario a questa risorsa.

Note
- Per creare una risorsa linguistica, è necessario avere un ruolo di proprietario assegnato nel gruppo di risorse.
- Se si connette un account di archiviazione preesistente, è necessario assegnarvi un ruolo di proprietario.
- Non spostare l'account di archiviazione in un gruppo di risorse o in una sottoscrizione diversa una volta collegato alla risorsa Azure Language.
Un progetto di Fonderia creato in Fonderia. Per altre informazioni, vedereCreare un progetto Foundry.
Set di dati NER personalizzato caricato nel contenitore di archiviazione. Un set di dati NER (Named Entity Recognition) personalizzato è la raccolta di documenti di testo etichettati usati per eseguire il training del modello NER personalizzato. È possibile scaricare il set di dati di esempio per questa guida introduttiva. La lingua di origine è l'inglese.
Passaggio 1: Configurare i ruoli, le autorizzazioni e le impostazioni necessari
Per iniziare, configurare le risorse.
Abilitare la funzionalità di riconoscimento delle entità denominate personalizzata
Assicurarsi che la funzionalità Classificazione testo personalizzata/Riconoscimento entità denominata personalizzata sia abilitata nel portale di Azure.
- Accedi alla risorsa Lingua nel portale di Azure.
- Nel menu a sinistra, nella sezione Gestione risorse selezionare Funzionalità.
- Assicurarsi che la funzionalità Di classificazione testo personalizzata/Riconoscimento di entità denominata personalizzata sia abilitata.
- Se il proprio account di archiviazione non è assegnato, seleziona e connetti il tuo account di archiviazione.
- Selezionare Applica.
Aggiungere i ruoli necessari per la risorsa lingua
- Nella pagina Risorsa lingua nel portale di Azure selezionare Controllo di accesso (IAM) nel riquadro sinistro.
- Selezionare Aggiungi per eseguire l'operazione Aggiungi assegnazioni di ruolo, quindi aggiungere Proprietario del linguaggio di Servizi cognitivi o Collaboratore di Servizi cognitivi per la risorsa di Lingua.
- In Assegna accesso a, selezionare Utente, gruppo o entità servizio.
- Seleziona membri.
- Selezionare il nome utente. È possibile cercare nomi utente nel campo Seleziona. Ripetere questo passaggio per tutti i ruoli.
- Ripetere questi passaggi per tutti gli account utente che devono accedere a questa risorsa.
Aggiungere i ruoli necessari per l'account di archiviazione
- Passare alla pagina dell'account di archiviazione nel portale di Azure.
- Selezionare Controllo di accesso (IAM) nel riquadro sinistro.
- Selezionare Aggiungi per aggiungere assegnazioni di ruolo e scegliere il ruolo Collaboratore ai dati del Blob di archiviazione nell'account di archiviazione.
- In Assegna accesso a selezionare Identità gestita.
- Seleziona membri.
- Seleziona la tua sottoscrizione e Lingua come identità gestita. È possibile cercare la risorsa della lingua nel campo Seleziona .
Aggiungere i ruoli utente necessari
Importante
Se si ignora questo passaggio, viene visualizzato un errore 403 quando si tenta di connettersi al progetto personalizzato. È importante che l'utente corrente abbia questo ruolo per accedere ai dati BLOB dell'account di archiviazione, anche se si è il proprietario dell'account di archiviazione.
- Passare alla pagina dell'account di archiviazione nel portale di Azure.
- Selezionare Controllo di accesso (IAM) nel riquadro sinistro.
- Selezionare Aggiungi per aggiungere assegnazioni di ruolo e scegliere il ruolo Collaboratore ai dati del Blob di archiviazione nell'account di archiviazione.
- In Assegna accesso a, selezionare Utente, gruppo o entità servizio.
- Seleziona membri.
- Selezionare l'utente. È possibile cercare nomi utente nel campo Seleziona.
Importante
Se si dispone di un firewall o di una rete virtuale o di un endpoint privato, assicurarsi di selezionare Consenti ai servizi di Azure nell'elenco dei servizi attendibili di accedere a questo account di archiviazione nella scheda Rete del portale di Azure.

Passaggio 2: Caricare il set di dati nel contenitore di archiviazione
Quindi, aggiungiamo un contenitore e carichiamo i file del tuo set di dati direttamente nella directory radice del tuo contenitore di archiviazione. Questi documenti vengono usati per eseguire il training del modello.
Aggiungere un contenitore all'account di archiviazione associato alla risorsa di lingua. Per altre informazioni, vedereCreare un contenitore.
Scaricare il set di dati di esempio da GitHub. Il set di dati di esempio fornito contiene 20 contratti di prestito:
- Ogni contratto include due parti: un creditore e un mutuatario.
- Estrai informazioni rilevanti per: entrambe le parti, la data del contratto, l'importo del prestito e il tasso di interesse.
Aprire il file .zip ed estrarre la cartella contenente i documenti.
Vai a Foundry.
Se non è già stato eseguito l'accesso, il portale richiede di farlo con le credenziali di Azure.
Dopo aver eseguito l'accesso, accedere al progetto di Fonderia esistente per questa guida introduttiva.
Selezionare Centro gestione dal menu di spostamento a sinistra.
Selezionare Risorse connesse nella sezione Hub del menu Centro gestione .
Successivamente, scegliere l'archiviazione BLOB dell'area di lavoro che è stata configurata per l'utente come risorsa connessa.
Nell'archivio BLOB dell'area di lavoro selezionare Visualizza nel portale di Azure.
Nella pagina AzurePortal per l'archiviazione BLOB selezionare Carica dal menu in alto. Scegliere quindi i
.txtfile e.jsonscaricati in precedenza. Infine, selezionare il pulsante Carica per aggiungere il file al contenitore.
Ora che le risorse di Azure necessarie vengono sottoposte a provisioning e configurate all'interno del portale di Azure, è possibile usare queste risorse in Foundry per creare un modello personalizzato di riconoscimento delle entità denominate (NER) personalizzato ottimizzato.
Passaggio 3: Connetti la risorsa di linguaggio
Successivamente viene creata una connessione alla risorsa Language in modo che Foundry possa accedervi in modo sicuro. Questa connessione fornisce la gestione e l'autenticazione sicure delle identità, nonché l'accesso controllato e isolato ai dati.
Tornare a Foundry.
Accedi al progetto Foundry esistente per questo avvio rapido.
Selezionare Centro gestione dal menu di spostamento a sinistra.
Selezionare Risorse connesse nella sezione Hub del menu Centro gestione .
Nella finestra principale selezionare il pulsante + Nuova connessione .
Selezionare Lingua nella finestra Aggiungi una connessione ad asset esterni .
Selezionare Aggiungi connessione e quindi Chiudi.

Passaggio 4: Ottimizzare il modello NER personalizzato
A questo punto, siamo pronti a creare un modello personalizzato perfezionato NER.
Nella sezione Progetto del menu Centro gestione selezionare Vai al progetto.
Dal menu Panoramica selezionare Ottimizzazione.
Nella finestra principale selezionare la scheda Ottimizzazione del servizio di intelligenza artificiale e successivamente il pulsante + Ottimizza.
Nella finestra Crea servizio di ottimizzazione scegliere la scheda Riconoscimento entità denominata personalizzata e quindi selezionare Avanti.

Nella finestra Crea attività di ottimizzazione del servizio completare i campi come indicato di seguito:
Servizio connesso. Il nome della risorsa lingua dovrebbe essere già visualizzato in questo campo per impostazione predefinita. in caso contrario, aggiungilo dal menu a discesa.
Nome. Assegnare un nome al progetto di attività di ottimizzazione.
Lingua. L'inglese è impostato come predefinito e viene già visualizzato nel campo .
Descrizione. Facoltativamente, è possibile specificare una descrizione o lasciare vuoto questo campo.
Contenitore di archiviazione BLOB. Selezionare il contenitore di archiviazione BLOB dell'area di lavoro nel passaggio 2 e scegliere il pulsante Connetti .
Infine, selezionare il pulsante Crea. Il completamento dell'operazione di creazione può richiedere alcuni minuti.

Passaggio 5: Eseguire il training del modello

- Scegliere Gestisci dati dal menu Attività iniziali. Nella finestra Aggiungi dati per il training e il test vengono visualizzati i dati di esempio caricati in precedenza nel contenitore di Archiviazione BLOB di Azure.
- Quindi, dal menu Attività iniziali, selezionare Eseguire il training del modello.
- Selezionare il pulsante + Eseguire il training del modello. Quando viene visualizzata la finestra Esegui training di un nuovo modello , immettere un nome per il nuovo modello e mantenere i valori predefiniti. Seleziona il pulsante Avanti.
- Nella finestra Esegui training di un nuovo modello mantenere l'impostazione predefinita Suddivide automaticamente il set di test dai dati di training abilitati con la percentuale consigliata impostata su 80% per i dati di training e 20% per i dati di test.
- Esaminare la configurazione del modello e quindi selezionare il pulsante Crea .
- Dopo il training di un modello, è possibile selezionare Valuta modello dal menu Attività iniziali . È possibile selezionare il modello dalla finestra Valuta il modello e apportare miglioramenti, se necessario.
Passaggio 6: Distribuzione del modello
In genere, dopo il training di un modello, esaminare i dettagli di valutazione. Per questa guida introduttiva, è sufficiente distribuire il modello e renderlo disponibile per il test in Azure Language Playground o chiamando l'API di stima. Tuttavia, se si vuole, è possibile dedicare qualche minuto a selezionare Valuta il modello dal menu a sinistra ed esplorare i dati di telemetria approfonditi per il modello. Completare i passaggi seguenti per distribuire il modello in Foundry.
Selezionare Distribuisci modello dal menu a sinistra.
Selezionare quindi Deploy a trained model➕ (Distribuisci un modello sottoposto a training) nella finestra Deploy your model (Distribuisci modello).

Assicurarsi che sia selezionato il pulsante Crea una nuova distribuzione.
Completare i campi della finestra Deploy a trained model (Distribuisci un modello sottoposto a training):
- Nome distribuzione. Assegnare un nome al modello.
- Assegnare un modello. Selezionare il modello addestrato dal menu a discesa.
- Area geografica. Selezionare un'area dal menu a discesa.
Infine, selezionare il pulsante Crea. La distribuzione del modello potrebbe richiedere alcuni minuti.
Dopo aver completato la distribuzione, è possibile visualizzare lo stato della distribuzione del modello nella pagina Distribuisci il modello. La data di scadenza visualizzata contrassegna la data in cui il modello distribuito diventa non disponibile per le attività di stima. Questa data è in genere 18 mesi dopo la distribuzione di una configurazione di training.

Passaggio 7: Provare Azure Language Playground
Il playground del linguaggio offre una sandbox per testare e configurare il modello ottimizzato prima di distribuirlo nell'ambiente di produzione, tutto senza scrivere codice.
- Nella barra dei menu in alto selezionare Prova in Playground.
- Nella finestra Azure Language Playground, selezionare la scheda Riconoscimento di entità denominate personalizzato.
- Nella sezione Configurazione selezionare il nome del progetto e il nome della distribuzione dai menu a discesa.
- Immettere un'entità e selezionare Esegui.
- È possibile valutare i risultati nella finestra Dettagli .
Ecco fatto, congratulazioni!
In questa guida introduttiva è stato creato un modello NER personalizzato ottimizzato, distribuito in Foundry e testato il modello in Azure Language Playground.
Pulire le risorse
Se il progetto non è più necessario, è possibile eliminarlo da Foundry.
- Navigare alla pagina principale di Foundry. Avviare il processo di autenticazione eseguendo l'accesso, a meno che non sia già stato completato questo passaggio e che la sessione sia attiva.
- Seleziona il progetto che vuoi eliminare da Keep building with Foundry.
- Selezionare Centro gestione.
- Selezionare Elimina progetto.
Per eliminare l'hub insieme a tutti i relativi progetti:
Passare alla scheda Panoramica nella sezione Hub .
A destra selezionare Elimina hub.
Il collegamento apre il portale di Azure per eliminare l'hub.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito
Creare una nuova risorsa "Azure Language" nei Foundry Tools e un account di archiviazione Azure.
Prima di poter usare il riconoscimento personalizzato delle entità denominate (NER), è necessario creare una risorsa Lingua, che fornisce le credenziali necessarie per creare un progetto e avviare il training di un modello. È anche necessario un account di archiviazione di Azure, in cui è possibile caricare il set di dati usato per la compilazione del modello.
Importante
Per iniziare rapidamente, è consigliabile creare una nuova risorsa lingua. Usare la procedura descritta in questo articolo per creare una risorsa del linguaggio di Azure e creare e/o connettere un account di archiviazione contemporaneamente. La creazione di entrambi contemporaneamente è più semplice rispetto a quella eseguita in un secondo momento.
Se si dispone di una risorsa preesistente che si vuole usare, è necessario connetterla all'account di archiviazione. Per informazioni, vedere Creare un progetto.
Creare una nuova risorsa dal portale di Azure
Accedere al portale di Azure per creare una nuova risorsa Azure Language in Foundry Tools.
Nella finestra visualizzata, selezionare Classificazione personalizzata del testo Riconoscimento entità denominata personalizzata dalle funzionalità personalizzate. Selezionare Continua per creare la risorsa nella parte inferiore dello schermo.
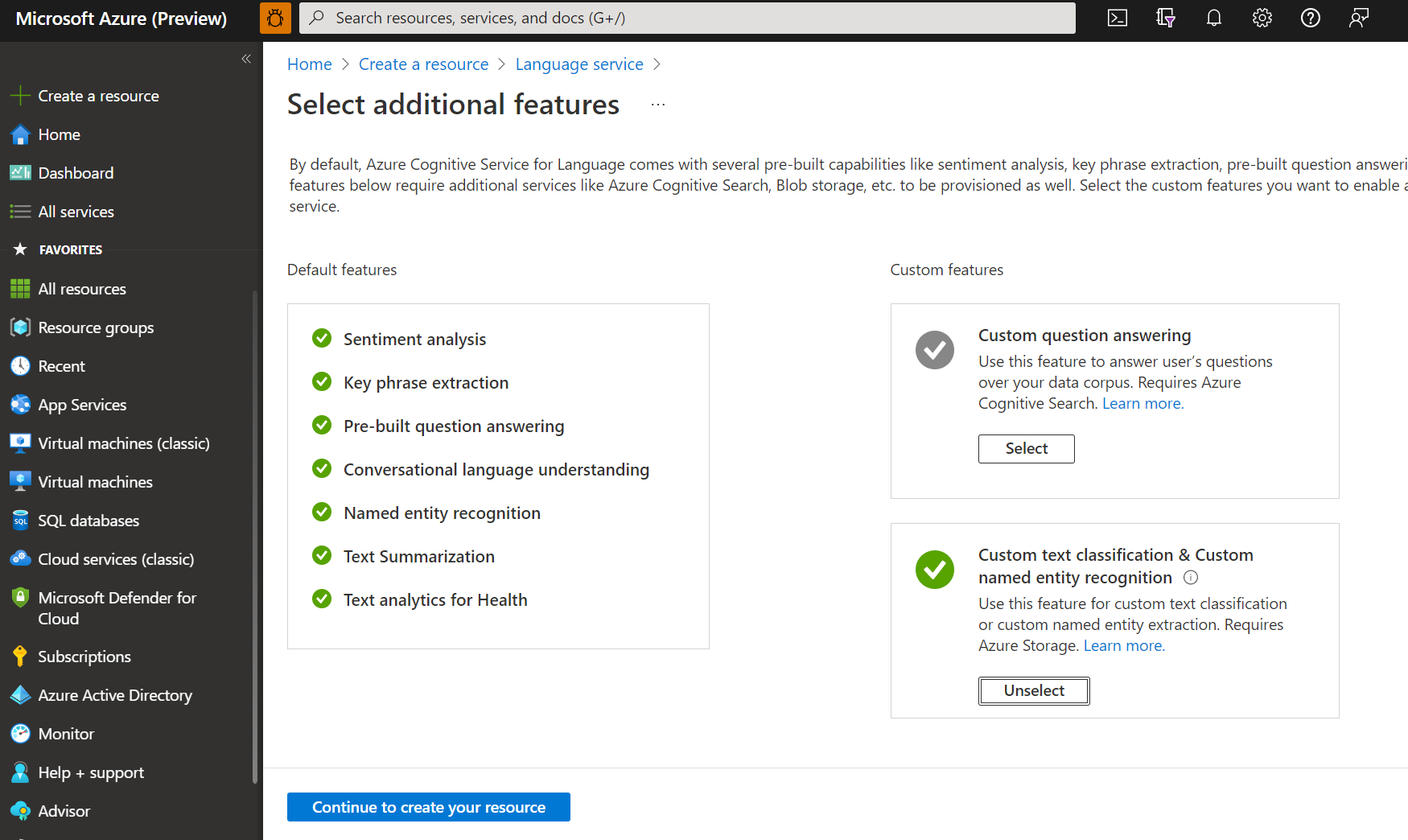
Creare una risorsa linguistica con i dettagli seguenti.
Nome Descrizione Subscription La sottoscrizione di Azure. Gruppo di risorse Il gruppo di risorse che contiene la tua risorsa. È possibile usarne uno esistente o crearne uno nuovo. Region L’area per la risorsa Lingua. Ad esempio, "Stati Uniti occidentali 2". Nome Un nome per la risorsa. Piano tariffario Il piano tariffario per la risorsa Lingua. Per provare il servizio, è possibile usare il livello gratuito (F0). Note
Se viene visualizzato un messaggio che indica che l'account di accesso non è un proprietario del gruppo di risorse dell'account di archiviazione selezionato, l'account deve avere un ruolo di proprietario assegnato nel gruppo di risorse prima di poter creare una risorsa linguistica. Per assistenza contattare il proprietario della sottoscrizione di Azure.
Nella sezione Classificazione personalizzata del testo e Riconoscimento entità denominata personalizzata, selezionare un account di archiviazione esistente o scegliere Nuovo account di archiviazione. Questi valori ti aiutano a iniziare e non sono necessariamente i valori dell'account di archiviazione che desideri usare nei tuoi ambienti di produzione. Per evitare la latenza durante la costruzione del progetto, collegarsi agli account di archiviazione nella stessa area della risorsa linguistica.
Valore dell'account di archiviazione Valore consigliato Nome dell'account di archiviazione Qualsiasi nome Tipo di account di archiviazione Archiviazione con ridondanza locale standard Accertarsi che sia selezionata l’opzione Avviso intelligenza artificiale responsabile. Selezionare Rivedi e crea nella parte inferiore della pagina, quindi selezionare Crea.

Caricare dati di esempio in un contenitore BLOB
Dopo aver creato un account di archiviazione di Azure e averla connessa alla risorsa Lingua, è necessario caricare i documenti dal set di dati di esempio nella directory radice del contenitore. Questi documenti vengono usati per eseguire il training del modello.
Scaricare il set di dati di esempio da GitHub.
Aprire il file .zip ed estrarre la cartella contenente i documenti.
Nel portale di Azure passare all'account di archiviazione creato e selezionarlo.
Nell'account di archiviazione selezionare Contenitori dal menu a sinistra, disponibile sotto Archiviazione dati. Nella schermata visualizzata selezionare + Contenitore. Assegnare al contenitore il nome example-data e lasciare il livello di accesso pubblico predefinito.
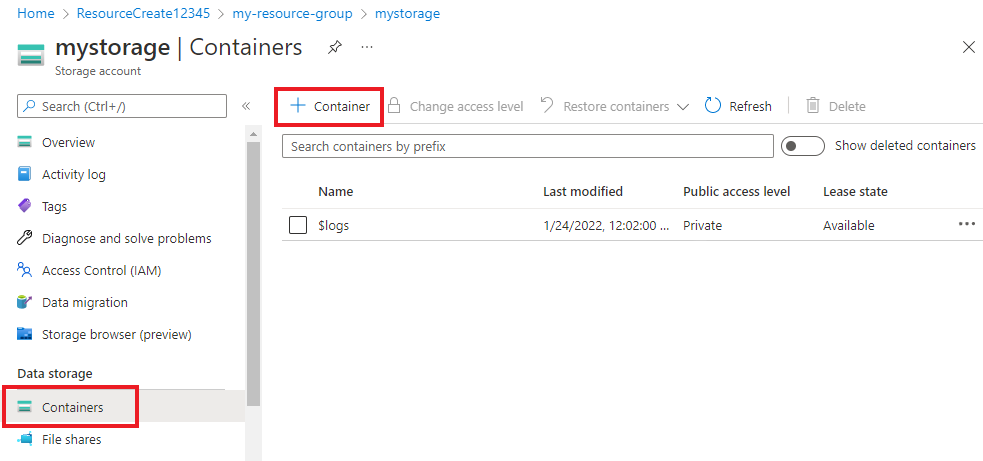
Dopo aver creato il contenitore, selezionarlo. Selezionare quindi il pulsante Carica per selezionare i file
.txte.jsonscaricati in precedenza.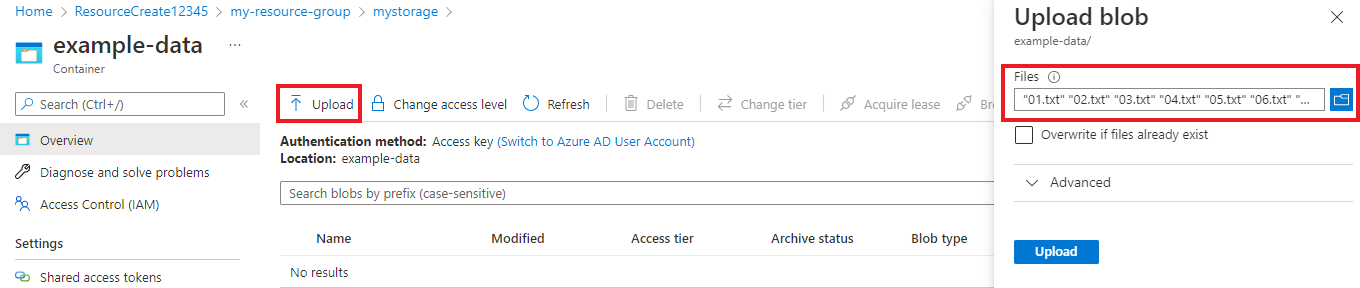


Il set di dati di esempio fornito contiene 20 contratti di mutuo. Ogni contratto include due parti: un creditore e un mutuatario. È possibile usare il file di esempio fornito per estrarre informazioni pertinenti per: entrambe le parti, una data del contratto, un importo del mutuo e un tasso di interesse.
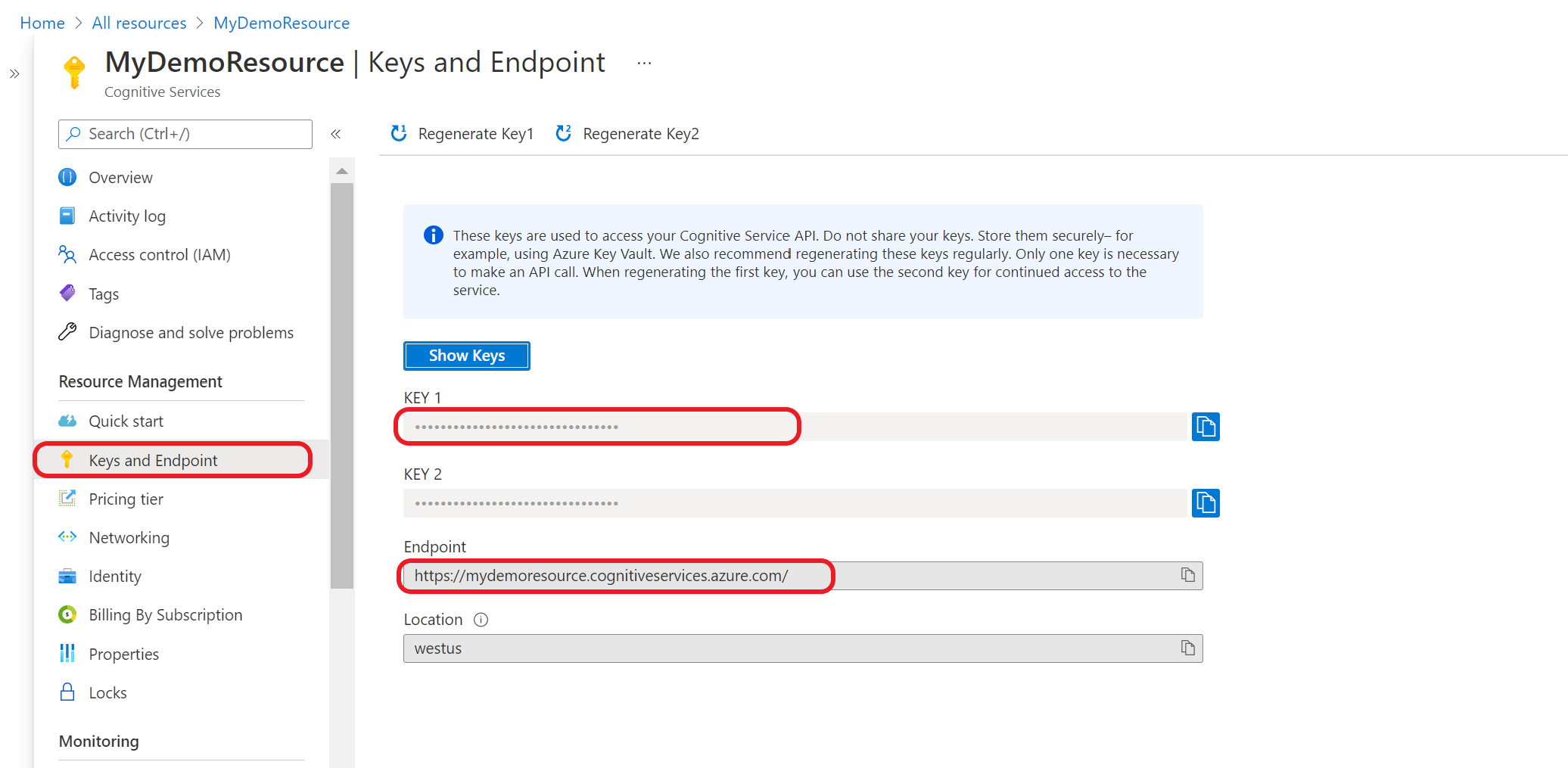
Ottenere le chiavi e l’endpoint di una risorsa
Passare alla pagina di panoramica della risorsa nel portale di Azure
Dal menu a sinistra selezionare Chiavi ed endpoint. L'endpoint e la chiave vengono usati per le richieste API.

Creare un progetto di riconoscimento di entità denominate personalizzato
Dopo aver configurato la risorsa e l'account di archiviazione, creare un nuovo progetto di Riconoscimento entità denominata personalizzato. Un progetto è un'area di lavoro per la creazione di modelli ML personalizzati in base ai dati. Il progetto è accessibile all'utente e ad altri utenti che hanno accesso alla risorsa del linguaggio di Azure in uso.
Usare il file di tag scaricato dal dati di esempio nel passaggio precedente e aggiungerlo al corpo della richiesta seguente.
Attivare un processo di importazione progetto
Inviare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per importare il file di etichette. Accertarsi che il file di etichette rispetti il formato accettato.
Se esiste già un progetto con lo stesso nome, i dati di tale progetto vengono sostituiti.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Segnaposto | valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
La versione dell'API che viene richiamata. Il valore a cui si fa riferimento è per la versione più recente rilasciata. Per altre informazioni, vedereCiclo di vita del modello. | 2022-05-01 |
Headers
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave per la risorsa. È usata per l’autenticazione delle richieste API. |
Corpo
Usare il JSON seguente nella richiesta. Sostituire i valori segnaposto con i propri valori.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomEntityRecognition",
"description": "Trying out custom NER",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomEntityRecognition",
"entities": [
{
"category": "Entity1"
},
{
"category": "Entity2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| Chiave | Segnaposto | valore | Esempio |
|---|---|---|---|
api-version |
{API-VERSION} |
La versione dell'API che viene richiamata. La versione usata qui deve essere la stessa versione dell'API nell'URL. Altre informazioni su altre versioni dell’API disponibili | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
projectKind |
CustomEntityRecognition |
Il tipo di progetto. | CustomEntityRecognition |
language |
{LANGUAGE-CODE} |
Una stringa che specifica il codice lingua per i documenti usati nel progetto. Se il progetto è un progetto multilingue, scegliere il codice linguistico della maggior parte dei documenti. | en-us |
multilingual |
true |
Un valore booleano che consente di avere documenti in più lingue nel set di dati; quando il modello viene distribuito, è possibile eseguire query sul modello in qualunque lingua supportata (non necessariamente inclusa nei documenti di training). Per informazioni sul supporto multilingue, vedere Supporto lingue. | true |
storageInputContainerName |
{CONTAINER-NAME} | Nome del contenitore di archiviazione di Azure contenente i documenti caricati. | myContainer |
entities |
Matrice contenente tutti i tipi di entità presenti nel progetto ed estratti dai documenti. | ||
documents |
Array contenente tutti i documenti nel progetto e l'elenco delle entità etichettate all'interno di ogni documento. | [] | |
location |
{DOCUMENT-NAME} |
Posizione dei documenti nel contenitore di archiviazione. | doc1.txt |
dataset |
{DATASET} |
Set di test a cui verrà sottoposto il file quando viene diviso prima del training. Per altre informazioni, vedereCome eseguire il training di un modello. I valori possibili per questo campo sono Train e Test. |
Train |
Dopo aver inviato la richiesta API, riceverai una 202 risposta che indica che la richiesta è stata inviata correttamente. Nelle intestazioni della risposta, estrarre il valore operation-location. Ecco un esempio del formato:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} viene usato per identificare la richiesta, poiché questa operazione è asincrona. Usare questo URL per ottenere lo stato del processo di importazione.
Possibili scenari di errore per questa richiesta:
- La risorsa selezionata non dispone delle autorizzazioni appropriate per l'account di archiviazione.
- Il valore
storageInputContainerNamespecificato non esiste. - Il codice lingua usato non è non valido o il tipo del codice lingua non è stringa.
-
Il valore
multilingualè una stringa e non un valore booleano.
Ottenere lo stato del processo di importazione
Usare la richiesta GET seguente per ottenere lo stato dell’importazione di un progetto. Sostituire i valori segnaposto con i propri valori.
URL richiesta
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{JOB-ID} |
L'ID per individuare lo stato del training del modello. Questo valore si trova nel valore dell'intestazione location ricevuto nel passaggio precedente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versione dell'API che viene richiamata. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni, vedereCiclo di vita del modello. | 2022-05-01 |
Headers
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave per la risorsa. È usata per l’autenticazione delle richieste API. |
Eseguire il training del modello
In genere, dopo aver creato un progetto, è possibile procedere e cominciare ad aggiungere tag ai documenti inclusi nel contenitore connesso al progetto. Per questa guida introduttiva è stato importato un set di dati con tag di esempio e il progetto è stato inizializzato con il file di tag JSON di esempio.
Avviare il processo di training
Dopo l'importazione del progetto, è possibile avviare il training del modello.
Inviare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per inviare un processo di training. Sostituire i valori segnaposto con i propri valori.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Segnaposto | valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
La versione dell'API che viene richiamata. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni, vedereCiclo di vita del modello. | 2022-05-01 |
Headers
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave per la risorsa. È usata per l’autenticazione delle richieste API. |
Corpo della richiesta
Usare il JSON seguente nel corpo della richiesta. Il modello viene fornito come {MODEL-NAME} una volta completato l'addestramento. Solo i processi di training con esito positivo producono modelli.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Chiave | Segnaposto | valore | Esempio |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Nome del modello che verrà assegnato al modello dopo l’esecuzione corretta del training. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Questa è la versione del modello usata per eseguire il training del modello. | 2022-05-01 |
| evaluationOptions | Opzione per dividere i dati tra set di training e set di test. | {} |
|
| kind | percentage |
Metodi di divisione. I possibili valori sono percentage o manual. Per altre informazioni, vedereCome eseguire il training di un modello. |
percentage |
| trainingSplitPercentage | 80 |
Percentuale dei dati con tag da includere nel set di training. Il valore consigliato è 80. |
80 |
| testingSplitPercentage | 20 |
Percentuale dei dati con tag da includere nel set di test. Il valore consigliato è 20. |
20 |
Note
trainingSplitPercentage e testingSplitPercentage sono necessari solo se Kind è impostato su percentage e la somma di entrambe le percentuali deve essere uguale a 100.
Dopo aver inviato la richiesta API, riceverai una 202 risposta che indica che la richiesta è stata inviata correttamente. Nelle intestazioni di risposta estrarre il valore location formattato come segue:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} viene usato per identificare la richiesta, poiché questa operazione è asincrona. È possibile usare questo URL per ottenere lo stato del training.
Ottenere lo stato del processo di training
Il training potrebbe richiedere da 10 a 30 minuti per questo set di dati di esempio. È possibile usare la richiesta seguente per continuare il polling dello stato del processo di training fino a quando non viene completato correttamente.
Usare la seguente richiesta GET per ottenere lo stato dello stato di avanzamento del training del modello. Sostituire i valori segnaposto con i propri valori.
URL richiesta
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{JOB-ID} |
L'ID per individuare lo stato del training del modello. Questo valore si trova nel valore dell'intestazione location ricevuto nel passaggio precedente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versione dell'API che viene richiamata. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni, vedereCiclo di vita del modello. | 2022-05-01 |
Headers
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave per la risorsa. È usata per l’autenticazione delle richieste API. |
Corpo della risposta
Dopo aver inviato la richiesta, si ottiene la risposta seguente.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Distribuire il modello
Generalmente, dopo il training di un modello è opportuno rivedere i relativi dettagli di valutazione e apportare miglioramenti in base alla necessità. In questa guida introduttiva è sufficiente distribuire il modello e renderlo disponibile per provare in Language Studio oppure chiamare l'API di stima.
Avviare un processo di distribuzione
Inviare una richiesta PUT usando l'URL, le intestazioni e il corpo JSON seguenti per inviare un processo di distribuzione. Sostituire i valori segnaposto con i propri valori.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Segnaposto | valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{DEPLOYMENT-NAME} |
Il nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | staging |
{API-VERSION} |
La versione dell'API che viene richiamata. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni, vedereCiclo di vita del modello. | 2022-05-01 |
Headers
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave per la risorsa. È usata per l’autenticazione delle richieste API. |
Corpo della richiesta
Usare il JSON seguente nel corpo della richiesta. Usare il nome del modello da assegnare alla distribuzione.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Chiave | Segnaposto | valore | Esempio |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Nome del modello assegnato alla distribuzione. È possibile assegnare solo modelli il cui training è stato eseguito correttamente. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myModel |
Dopo aver inviato la richiesta API, riceverai una 202 risposta che indica che la richiesta è stata inviata correttamente. Nelle intestazioni di risposta estrarre il valore operation-location formattato come segue:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} viene usato per identificare la richiesta, poiché questa operazione è asincrona. È possibile usare questo URL per ottenere lo stato della distribuzione.
Ottenere lo stato del processo di distribuzione
Usare la richiesta GET seguente per eseguire una query dello stato del processo di distribuzione. È possibile usare l'URL ricevuto dal passaggio precedente oppure sostituire i valori segnaposto con i propri valori.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{DEPLOYMENT-NAME} |
Il nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | staging |
{JOB-ID} |
L'ID per individuare lo stato del training del modello. Si trova nel valore dell'intestazione location ricevuto nel passaggio precedente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versione dell'API che viene richiamata. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni, vedereCiclo di vita del modello. | 2022-05-01 |
Headers
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave per la risorsa. È usata per l’autenticazione delle richieste API. |
Corpo della risposta
Dopo aver inviato la richiesta, si ottiene la risposta seguente. Continuare il polling di questo endpoint fino a quando il parametro dello stato diventa "succeeded". Si ottiene un codice 200 indicante l'esito positivo della richiesta.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Estrarre entità personalizzate
Dopo aver distribuito il modello, è possibile iniziare a utilizzarlo per estrarre entità dal testo usando l’API di stima. Nel set di dati di esempio scaricato in precedenza è possibile trovare alcuni documenti di test che è possibile usare in questo passaggio.
Inviare un'attività di Riconoscimento entità denominata personalizzata
Usare questa richiesta POST per avviare un'attività di classificazione del testo.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Segnaposto | valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
La versione dell'API che viene richiamata. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni, vedereCiclo di vita del modello. | 2022-05-01 |
Headers
| Chiave | valore |
|---|---|
| Ocp-Apim-Subscription-Key | La chiave che fornisce l'accesso all’API. |
Corpo
{
"displayName": "Extracting entities",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomEntityRecognition",
"taskName": "Entity Recognition",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Chiave | Segnaposto | valore | Esempio |
|---|---|---|---|
displayName |
{JOB-NAME} |
Il nome del processo. | MyJobName |
documents |
[{},{}] | Elenco di documenti per cui eseguire le attività. | [{},{}] |
id |
{DOC-ID} |
Nome o ID del documento. | doc1 |
language |
{LANGUAGE-CODE} |
Una stringa che specifica il codice lingua per il documento. Se questa chiave non è specificata, il servizio presuppone la lingua predefinita del progetto selezionato durante la creazione del progetto. Per un elenco dei codici lingua supportati, vedere Supporto lingua. | en-us |
text |
{DOC-TEXT} |
Attività del documento per cui eseguire le attività. | Lorem ipsum dolor sit amet |
tasks |
Elenco di attività da eseguire. | [] |
|
taskName |
CustomEntityRecognition |
Il nome dell’attività | CustomEntityRecognition |
parameters |
Elenco di parametri da passare all'attività. | ||
project-name |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Il nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | prod |
Risposta
Si riceve una risposta 202 che indica che l'attività è stata inviata correttamente. Nelle intestazioni della risposta, estrarre operation-location.
operation-location è formattato come indicato di seguito:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
È possibile usare questo URL per eseguire una query sullo stato di completamento dell'attività e ottenere i risultati al termine dell'attività.
Ottenere i risultati dell’attività
Usare la richiesta GET seguente per eseguire una query sullo stato/sui risultati dell'attività di riconoscimento di entità personalizzate.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
La versione dell'API che viene richiamata. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni, vedereCiclo di vita del modello. | 2022-05-01 |
Headers
| Chiave | valore |
|---|---|
| Ocp-Apim-Subscription-Key | La chiave che fornisce l'accesso all’API. |
Corpo della risposta
La risposta sarà un documento JSON con i parametri seguenti
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "EntityRecognitionLROResults",
"taskName": "Recognize Entities",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"category": "Event",
"confidenceScore": 0.61,
"length": 4,
"offset": 18,
"text": "trip"
},
{
"category": "Location",
"confidenceScore": 0.82,
"length": 7,
"offset": 26,
"subcategory": "GPE",
"text": "Seattle"
},
{
"category": "DateTime",
"confidenceScore": 0.8,
"length": 9,
"offset": 34,
"subcategory": "DateRange",
"text": "last week"
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Pulire le risorse
Quando il progetto non è più necessario, è possibile eliminarlo con la richiesta DELETE seguente. Sostituire i valori segnaposto con i propri valori.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Segnaposto | valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
La versione dell'API che viene richiamata. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni, vedereCiclo di vita del modello. | 2022-05-01 |
Headers
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
| Ocp-Apim-Subscription-Key | La chiave per la risorsa. È usata per l’autenticazione delle richieste API. |
Dopo aver inviato la richiesta API, si riceve una 202 risposta che indica l'esito positivo, il che significa che il progetto viene eliminato. Risultati di una chiamata con esito positivo con un'intestazione Operation-Location usata per controllare lo stato del processo.
Contenuti correlati
Dopo aver creato il modello di estrazione di entità, è possibile usare l'API di runtime per estrarre le entità.
Quando si creano progetti NER personalizzati, usare i nostri articoli sulle procedure per ottenere ulteriori informazioni sull'etichettatura, l'addestramento e la fruizione del modello in modo più dettagliato: