Nota
Questo articolo si basa su una libreria open source ospitata in GitHub all'indirizzo: https://github.com/mspnp/spark-monitoring.
La libreria originale supporta Azure Databricks Runtimes 10.x (Spark 3.2.x) e versioni precedenti.
Databricks ha contribuito a una versione aggiornata per supportare Azure Databricks Runtimes 11.0 (Spark 3.3.x) e versioni successive nel l4jv2 ramo in: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Si noti che la versione 11.0 non è compatibile con le versioni precedenti a causa dei diversi sistemi di registrazione usati nei runtime di Databricks. Assicurarsi di usare la compilazione corretta per il runtime di Databricks. La libreria e il repository GitHub sono in modalità di manutenzione. Non sono previsti piani per altre versioni e il supporto per i problemi sarà solo un'operazione ottimale. Per eventuali altre domande relative alla libreria o alla roadmap per il monitoraggio e la registrazione degli ambienti Azure Databricks, contattare azure-spark-monitoring-help@databricks.com.
Questa soluzione illustra modelli di osservabilità e metriche per migliorare le prestazioni di elaborazione di un sistema Big Data che usa Azure Databricks.
Architettura

Scaricare un file di Visio di questa architettura.
Workflow
La azione include i passaggi seguenti:
Il server invia un file GZIP di grandi dimensioni raggruppato per cliente alla cartella Source in Azure Data Lake Storage (ADLS).
ADLS invia quindi un file di clienti estratto correttamente a Griglia di eventi di Azure, che trasforma i dati del file del cliente in diversi messaggi.
Griglia di eventi di Azure invia i messaggi al servizio Archiviazione code di Azure, che li archivia in una coda.
Archiviazione code di Azure invia la coda alla piattaforma di analisi dei dati Azure Databricks per l'elaborazione.
Azure Databricks decomprime ed elabora i dati della coda in un file elaborato che invia nuovamente ad ADLS:
Se il file elaborato è valido, viene inserito nella cartella Landing.
In caso contrario, il file passa all'albero delle cartelle Bad. Inizialmente, il file viene inserito nella sottocartella Retry e ADLS tenta di nuovo l'elaborazione dei file dei clienti (passaggio 2). Se dopo un paio di tentativi Azure Databricks restituisce ancora file elaborati non validi, il file elaborato viene inserito nella sottocartella Failure.
Quando Azure Databricks decomprime ed elabora i dati nel passaggio precedente, invia anche i log e le metriche dell'applicazione a Monitoraggio di Azure per l'archiviazione.
Un'area di lavoro Azure Log Analytics applica query Kusto ai log e alle metriche dell'applicazione di Monitoraggio di Azure per la risoluzione dei problemi e la diagnostica approfondita.
Componenti
- Azure Data Lake Storage è un set di funzionalità dedicate all'analisi dei Big Data.
- Griglia di eventi di Azure consente agli sviluppatori di compilare facilmente applicazioni con architetture basate su eventi.
- Archiviazione code di Azure è un servizio per l'archiviazione di un numero elevato di messaggi. Consente di accedere ai messaggi ovunque ci si trovi con chiamate autenticate tramite HTTP o HTTPS. È possibile usare le code per creare un backlog di lavoro da elaborare in modo asincrono.
- Azure Databricks è una piattaforma di analisi dei dati ottimizzata per la piattaforma cloud di Azure. Uno dei due ambienti offerti da Azure Databricks per lo sviluppo di applicazioni a uso intensivo di dati è l'area di lavoro di Azure Databricks, un motore di analisi unificato basato su Apache Spark per l'elaborazione dei dati su larga scala.
- Monitoraggio di Azure raccoglie e analizza i dati di telemetria delle app, ad esempio metriche delle prestazioni e log attività.
- Azure Log Analytics è uno strumento usato per modificare ed eseguire query di log con i dati.
Dettagli dello scenario
Il team di sviluppo può usare modelli e metriche di osservabilità per individuare i colli di bottiglia e migliorare le prestazioni di un sistema di Big Data. Il team deve eseguire test di carico di un flusso di metriche con volumi elevati in un'applicazione su larga scala.
Questo scenario offre indicazioni per l'ottimizzazione delle prestazioni. Poiché lo scenario presenta una problematica in termini di prestazioni per la registrazione per ogni cliente, si usa Azure Databricks, che consente di monitorare questi elementi in modo affidabile:
- Metriche personalizzate dell'applicazione
- Eventi di query di streaming
- Messaggi del log dell'applicazione
Azure Databricks può inviare questi dati di monitoraggio a diversi servizi di registrazione, ad esempio Azure Log Analytics.
Questo scenario descrive l'inserimento di un set di dati di grandi dimensioni raggruppati per cliente e archiviati in un file di archivio GZIP. I log dettagliati di Azure Databricks non sono disponibili all'esterno dell'interfaccia utente Apache Spark™ in tempo reale, quindi il team deve trovare un modo per archiviare tutti i dati per ogni cliente e quindi eseguire il benchmark e il confronto. Con uno scenario di dati di grandi dimensioni, è importante trovare una combinazione ottimale di pool di executor e dimensioni della macchina virtuale (VM) per accelerare i tempi di elaborazione. Per questo scenario aziendale, l'applicazione complessiva si basa sulla velocità di inserimento e sui requisiti di query, in modo che la velocità effettiva del sistema non diminuisca in modo imprevisto con l'aumento del volume di lavoro. Lo scenario deve garantire che il sistema soddisfi i contratti di servizio stabiliti con i clienti.
Potenziali casi d'uso
Gli scenari che possono trarre vantaggio da questa soluzione includono:
- Monitoraggio dell'integrità del sistema.
- Manutenzione delle prestazioni.
- Monitoraggio dell'utilizzo quotidiano del sistema.
- Individuazione di tendenze che potrebbero causare problemi futuri se non vengono risolte.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
Tenere presenti questi punti quando si considera questa architettura:
Azure Databricks può allocare automaticamente le risorse di calcolo necessarie per un processo di grandi dimensioni, evitando così problemi introdotti da altre soluzioni. Ad esempio, con la scalabilità automatica ottimizzata per Databricks in Apache Spark, un provisioning eccessivo può causare l'uso non ottimale delle risorse. Oppure si potrebbe non conoscere il numero di executor necessari per un processo.
Un messaggio in coda in Archiviazione code di Azure può avere dimensioni massime di 64 KB. Una coda può contenere milioni di messaggi, fino al limite di capacità totale dell'account di archiviazione.
Ottimizzazione dei costi
L'ottimizzazione dei costi riguarda l'analisi dei modi per ridurre le spese non necessarie e migliorare l'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
Per stimare il costo di implementazione di questa soluzione, usare il calcolatore dei prezzi di Azure.
Distribuire lo scenario
Nota
I passaggi di distribuzione descritti qui si applicano solo ad Azure Databricks, Monitoraggio di Azure e Azure Log Analytics. La distribuzione degli altri componenti non è illustrata in questo articolo.
Per ottenere tutti i log e le informazioni del processo, configurare Azure Log Analytics e la libreria di monitoraggio di Azure Databricks. La libreria di monitoraggio trasmette eventi a livello di Apache Spark e metriche di Spark Structured Streaming dai processi a Monitoraggio di Azure. Non è necessario apportare modifiche al codice dell'applicazione per questi eventi e metriche.
I passaggi per configurare l'ottimizzazione delle prestazioni per un sistema di Big Data sono i seguenti:
Nel portale di Azure creare un'area di lavoro di Azure Databricks. Copiare e salvare l'ID sottoscrizione di Azure (un GUID), il nome del gruppo di risorse, il nome dell'area di lavoro di Databricks e l'URL del portale dell'area di lavoro per usarli in seguito.
In un Web browser passare all'URL dell'area di lavoro di Databricks e generare un token di accesso personale di Databricks. Copiare e salvare la stringa del token visualizzata (che inizia con
dapie un valore esadecimale di 32 caratteri) per usarla in seguito.Clonare il repository GitHub mspnp/spark-monitoring nel computer locale. Questo repository include il codice sorgente per i componenti seguenti:
- Il modello di Azure Resource Manager (ARM) per la creazione di un'area di lavoro Azure Log Analytics, che installa anche le query predefinite per la raccolta di metriche Spark
- Librerie di monitoraggio di Azure Databricks
- L'applicazione di esempio per l'invio di metriche e log dell'applicazione da Azure Databricks a Monitoraggio di Azure
Usando il comando dell'interfaccia della riga di comando di Azure per la distribuzione di un modello di ARM, creare un'area di lavoro Azure Log Analytics con query predefinite sulle metriche Spark. Dall'output del comando copiare e salvare il nome generato per la nuova area di lavoro Log Analytics nel formato spark-monitoring-<randomized-string>.
Nel portale di Azure copiare e salvare l'ID e la chiave dell'area di lavoro Log Analytics per usarli in seguito.
Installare la Community Edition di IntelliJ IDEA, un ambiente di sviluppo integrato (IDE) con supporto incorporato per Java Development Kit (JDK) e Apache Maven. Aggiungere il plug-in Scala.
Usando IntelliJ IDEA, creare le librerie di monitoraggio di Azure Databricks. Per eseguire il passaggio di compilazione effettivo, selezionare Visualizza>Finestre degli strumenti>Maven per aprire le finestre degli strumenti Maven, quindi selezionare Esegui pacchetto Maven Goal>mvn.
Usando uno strumento di installazione di pacchetti Python, installare l'interfaccia della riga di comando di Azure Databricks e configurare l'autenticazione con il token di accesso personale di Databricks copiato in precedenza.
Configurare l'area di lavoro di Azure Databricks modificando lo script init di Databricks con i valori di Databricks e Log Analytics copiati in precedenza e quindi usando l'interfaccia della riga di comando di Azure Databricks per copiare lo script init e le librerie di monitoraggio di Azure Databricks nell'area di lavoro di Databricks.
Nel portale dell'area di lavoro di Databricks creare e configurare un cluster di Azure Databricks.
In IntelliJ IDEA compilare l'applicazione di esempio usando Maven. Quindi, nel portale dell'area di lavoro di Databricks eseguire l'applicazione di esempio per generare log e metriche di esempio per Monitoraggio di Azure.
Mentre il processo di esempio è in esecuzione in Azure Databricks, passare al portale di Azure per visualizzare ed eseguire query sui tipi di evento (log e metriche dell'applicazione) nell'interfaccia di Log Analytics:
- Selezionare Tabelle>Log personalizzati per visualizzare lo schema della tabella per gli eventi di listener di Spark (SparkListenerEvent_CL), gli eventi di registrazione di Spark (SparkLoggingEvent_CL) e le metriche di Spark (SparkMetric_CL).
- Selezionare Esplora query>Query salvate>Metriche di Spark per visualizzare ed eseguire le query aggiunte quando è stata creata l'area di lavoro Log Analytics.
Per altre informazioni sulla visualizzazione e l'esecuzione di query predefinite e personalizzate, vedere la sezione successiva.
Eseguire query su log e metriche in Azure Log Analytics
Accedere alle query predefinite
I nomi delle query predefinite per il recupero di metriche di Spark sono elencati di seguito.
- % di tempo CPU per executor
- % di tempo deserializzazione per executor
- % di tempo JVM per executor
- % di tempo serializzazione per executor
- Byte del disco distribuiti
- Tracce di errori (record errato o file errati)
- Letture di byte del file system per executor
- Scritture di byte del file system per executor
- Errori dei processi per processo
- Latenza dei processi per processo (durata batch)
- Velocità effettiva dei processi
- Executor in esecuzione
- Lettura byte in sequenza casuale
- Lettura byte in sequenza casuale per executor
- Lettura byte in sequenza casuale su disco per executor
- Memoria diretta client in sequenza casuale
- Memoria client in sequenza casuale per executor
- Byte su disco in sequenza casuale distribuiti per executor
- Memoria heap in sequenza casuale per executor
- Byte di memoria in sequenza casuale distribuiti per executor
- Latenza delle fasi per fase (durata fasi)
- Velocità effettiva delle fasi per fase
- Errori di streaming per flusso
- Latenza di streaming per flusso
- Righe/sec di input in velocità effettiva di streaming
- Righe/sec elaborate in velocità effettiva di streaming
- Somma esecuzione attività per host
- Tempo di deserializzazione attività
- Errori di attività per fase
- Tempo di calcolo dell'executor attività (tempo di asimmetria dei dati)
- Byte di input di attività letti
- Latenza delle attività per fase (durata attività)
- Tempo di serializzazione dei risultati attività
- Latenza di ritardo dell'utilità di pianificazione attività
- Byte in sequenza casuale attività letti
- Byte in sequenza casuale attività scritti
- Tempo di lettura sequenza casuale attività
- Tempo di scrittura sequenza casuale attività
- Velocità effettiva delle attività (somma delle attività per fase)
- Attività per executor (somma delle attività per executor)
- Attività per fase
Scrivere query personalizzate
È anche possibile scrivere query personalizzate nel linguaggio di query Kusto (KQL). È sufficiente selezionare il riquadro centrale superiore, che è modificabile, e personalizzare la query in base alle esigenze.
Le due query seguenti estraggono i dati dagli eventi di registrazione di Spark:
SparkLoggingEvent_CL | where logger_name_s contains "com.microsoft.pnp"
SparkLoggingEvent_CL
| where TimeGenerated > ago(7d)
| project TimeGenerated, clusterName_s, logger_name_s
| summarize Count=count() by clusterName_s, logger_name_s, bin(TimeGenerated, 1h)
Questi due esempi sono query sul log delle metriche di Spark:
SparkMetric_CL
| where name_s contains "executor.cpuTime"
| extend sname = split(name_s, ".")
| extend executor=strcat(sname[0], ".", sname[1])
| project TimeGenerated, cpuTime=count_d / 100000
SparkMetric_CL
| where name_s contains "driver.jvm.total."
| where executorId_s == "driver"
| extend memUsed_GB = value_d / 1000000000
| project TimeGenerated, name_s, memUsed_GB
| summarize max(memUsed_GB) by tostring(name_s), bin(TimeGenerated, 1m)
Terminologia delle query
La tabella seguente illustra alcuni dei termini usati quando si crea una query di log e metriche dell'applicazione.
| Termine | ID | Osservazioni: |
|---|---|---|
| Cluster_init | ID applicazione | |
| Queue | ID esecuzione | Un ID esecuzione equivale a più batch. |
| Batch | ID batch | Un batch equivale a due processi. |
| Posizione | ID lavoro | Un processo equivale a due fasi. |
| Fase | ID fase | Una fase include 100-200 ID attività a seconda dell'attività (lettura, riproduzione casuale o scrittura). |
| Attività | ID attività | Un'attività viene assegnata a un executor. Un'attività viene assegnata per eseguire partitionBy per una partizione. Per circa 200 clienti, dovrebbero essere presenti 200 attività. |
Le sezioni seguenti contengono le metriche tipiche usate in questo scenario per il monitoraggio della velocità effettiva del sistema, dello stato di esecuzione dei processi Spark e dell'utilizzo delle risorse di sistema.
Velocità effettiva del sistema
| Nome | Misura | Insieme unità misura |
|---|---|---|
| Velocità effettiva del flusso | Velocità media di input rispetto alla velocità media di elaborazione al minuto | Righe al minuto |
| Durata processi | Durata media dei processi Spark terminati al minuto | Durata/e al minuto |
| Conteggio processi | Numero medio di processi Spark terminati al minuto | Numero di processi al minuto |
| Durata fasi | Durata media delle fasi completate al minuto | Durata/e al minuto |
| Conteggio fasi | Numero medio di fasi completate al minuto | Numero di fasi al minuto |
| Durata attività | Durata media delle attività completate al minuto | Durata/e al minuto |
| Conteggio attività | Numero medio di attività completate al minuto | Numero di attività al minuto |
Stato di esecuzione dei processi Spark
| Nome | Misura | Insieme unità misura |
|---|---|---|
| Conteggio pool dell'utilità di pianificazione | Numero di valori distinti di pool dell'utilità di pianificazione al minuto (numero di code operative) | Numero di pool dell'utilità di pianificazione |
| Numero di executor in esecuzione | Numero di executor in esecuzione al minuto | Numero di executor in esecuzione |
| Traccia degli errori | Tutti i log degli errori di livello Error e l'ID attività/fase corrispondente (mostrato in thread_name_s) |
Utilizzo delle risorse di sistema
| Nome | Misura | Insieme unità misura |
|---|---|---|
| Utilizzo medio della CPU per executor/complessivo | Percentuale di CPU usata per executor al minuto | % al minuto |
| Media della memoria diretta usata (MB) per host | Media della memoria diretta usata per executor al minuto | MB al minuto |
| Memoria distribuita per host | Media della memoria distribuita per executor | MB al minuto |
| Monitoraggio dell'impatto dell'asimmetria dei dati sulla durata | Intervallo di misure e differenza tra il 70° e il 90° percentile e tra il 90° e il 100° percentile nella durata delle attività | Differenza netta tra 100%, 90% e 70%; differenza in percentuale tra 100%, 90% e 70% |
Decidere come correlare l'input del cliente, combinato in un file di archivio GZIP, a un particolare file di output di Azure Databricks, poiché Azure Databricks gestisce l'intera operazione batch come unità. In questo caso si applica la granularità alla traccia. È anche possibile usare metriche personalizzate per tracciare un file di output nel file di input originale.
Per definizioni più dettagliate di ogni metrica, vedere Visualizzazioni nei dashboard in questo sito Web o vedere la sezione relativa alle metriche nella documentazione di Apache Spark.
Valutare le opzioni di ottimizzazione delle prestazioni
Definizione della baseline
L'utente e il team di sviluppo devono stabilire una baseline, in modo da poter confrontare gli stati futuri dell'applicazione.
Misurare le prestazioni dell'applicazione in modo quantitativo. In questo scenario, la metrica chiave è la latenza dei processi, che è tipica della maggior parte delle attività di pre-elaborazione e inserimento di dati. Provare ad accelerare il tempo di elaborazione dei dati e concentrarsi sulla misurazione della latenza, come nel grafico seguente:
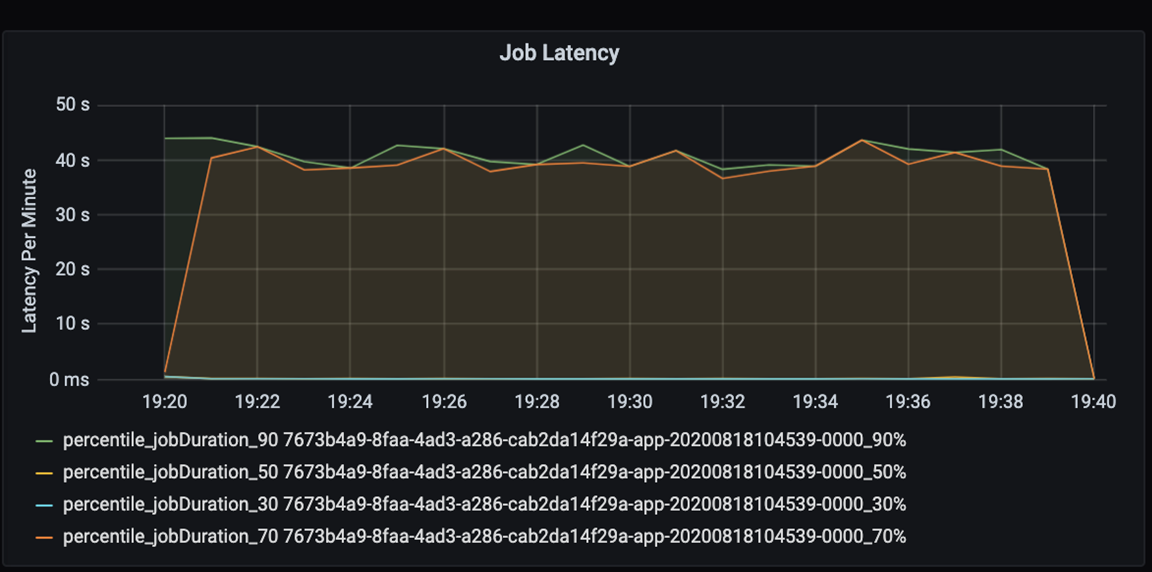
Misurare la latenza di esecuzione per un processo: una visualizzazione approssimativa delle prestazioni complessive del processo e la durata dell'esecuzione del processo dall'inizio al completamento (tempo di microbatch). Nel grafico precedente, in corrispondenza del contrassegno 19:30, il tempo necessario per elaborare il processo è di circa 40 secondi.
Osservando ulteriormente questi 40 secondi, si notano i dati seguenti per le fasi:
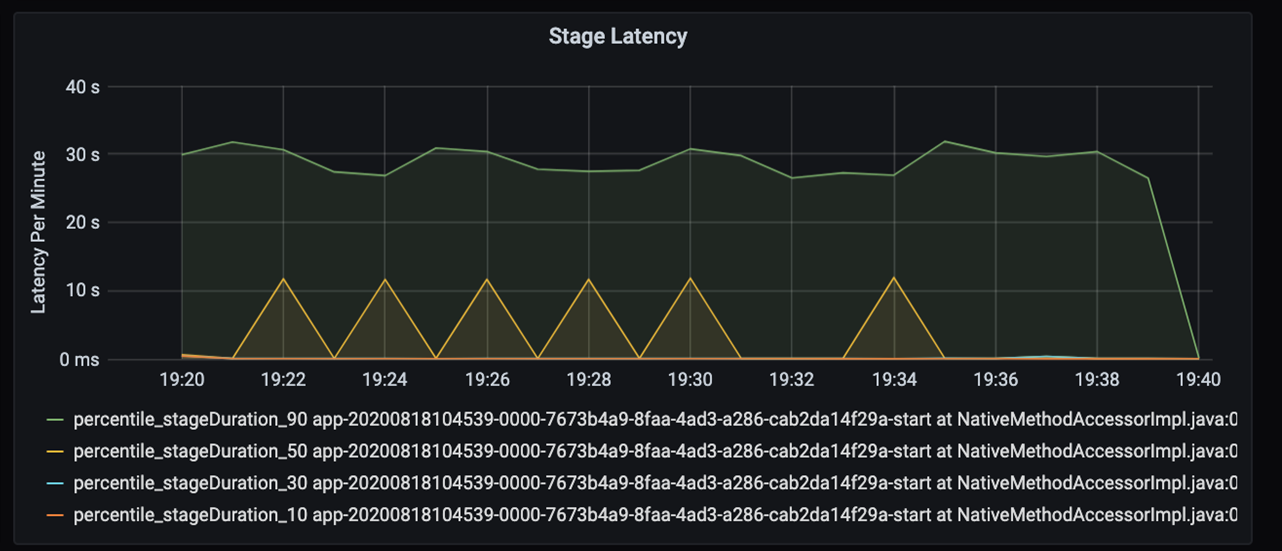
In corrispondenza del contrassegno 19:30 sono presenti due fasi: una fase arancione di 10 secondi e una fase verde di 30 secondi. Controllare se per una fase si verificano picchi, perché un picco indica un ritardo in una fase.
Verificare se una determinata fase viene eseguita lentamente. Nello scenario di partizionamento esistono in genere almeno due fasi: una fase per leggere un file e l'altra per eseguire la riproduzione casuale, la partizione e la scrittura del file. Se si ha una latenza di fase elevata principalmente nella fase di scrittura, potrebbe essersi verificato un problema di collo di bottiglia durante il partizionamento.
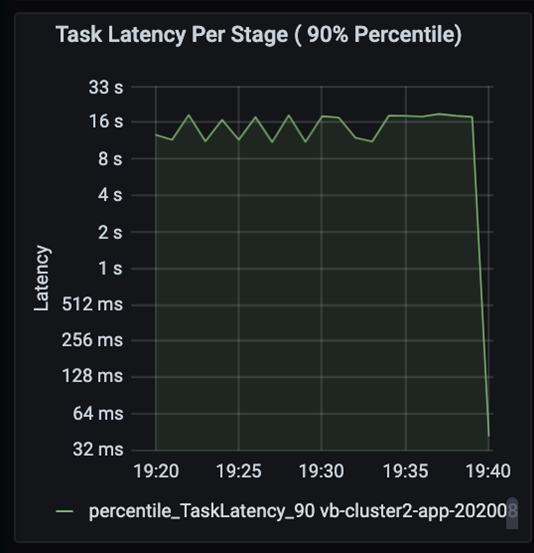
Osservare le attività mentre le fasi di un processo vengono eseguite in sequenza, con le fasi precedenti che bloccano quelle successive. All'interno di una fase, se un'attività esegue una partizione con riproduzione casuale più lenta rispetto ad altre attività, è necessario che tutte le attività nel cluster attendano il completamento dell'attività più lenta prima che la fase venga completata. Le attività offrono quindi un modo per monitorare l'asimmetria dei dati e i possibili colli di bottiglia. Nel grafico precedente è possibile notare che tutte le attività sono distribuite in modo uniforme.
Monitorare ora il tempo di elaborazione. Poiché lo scenario riguarda lo streaming, esaminare la velocità effettiva di streaming.
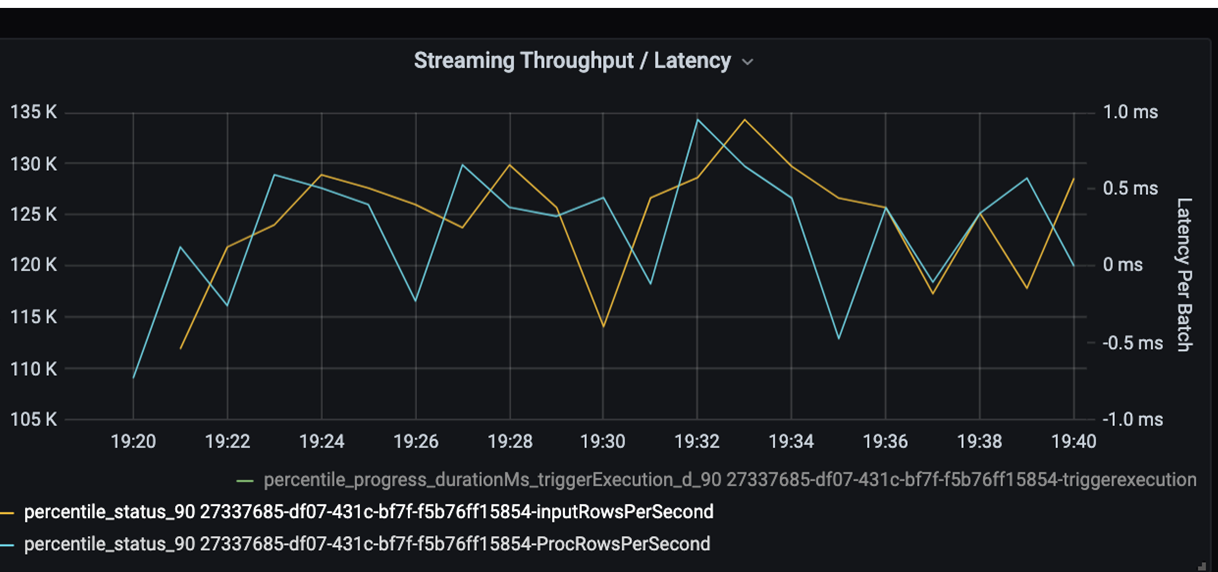
Nel grafico precedente della velocità effettiva/latenza in batch di streaming, la linea arancione rappresenta la velocità di input (righe di input al secondo). La linea blu rappresenta la velocità di elaborazione (righe elaborate al secondo). In alcuni punti, la velocità di elaborazione non raggiunge la velocità di input. Il possibile problema è che i file di input si accumulano nella coda.
Poiché la velocità di elaborazione non corrisponde alla velocità di input nel grafico, cercare di migliorare la velocità di elaborazione per coprire completamente la velocità di input. Un possibile motivo potrebbe essere lo sbilanciamento dei dati del cliente in ogni chiave di partizione che causa un collo di bottiglia. Per un passaggio successivo e una possibile soluzione, sfruttare la scalabilità di Azure Databricks.
Analisi del partizionamento
In primo luogo, identificare ulteriormente il numero corretto di executor di ridimensionamento necessari con Azure Databricks. Applicare la regola generale di assegnare ogni partizione con una CPU dedicata negli executor in esecuzione. Ad esempio, nel caso di 200 chiavi di partizione, il numero di CPU moltiplicato per il numero di executor deve essere uguale a 200. Ad esempio, otto CPU combinate con 25 executor sarebbero una buona corrispondenza. Con 200 chiavi di partizione, ogni executor può funzionare solo su un'attività, riducendo così la probabilità di un collo di bottiglia.
Poiché in questo scenario sono presenti alcune partizioni lente, analizzare le cause dell'elevata varianza nella durata delle attività. Verificare la presenza di eventuali picchi nella durata delle attività. Un'attività gestisce un'unica partizione. Se un'attività richiede più tempo, la partizione potrebbe essere troppo grande e causare un collo di bottiglia.
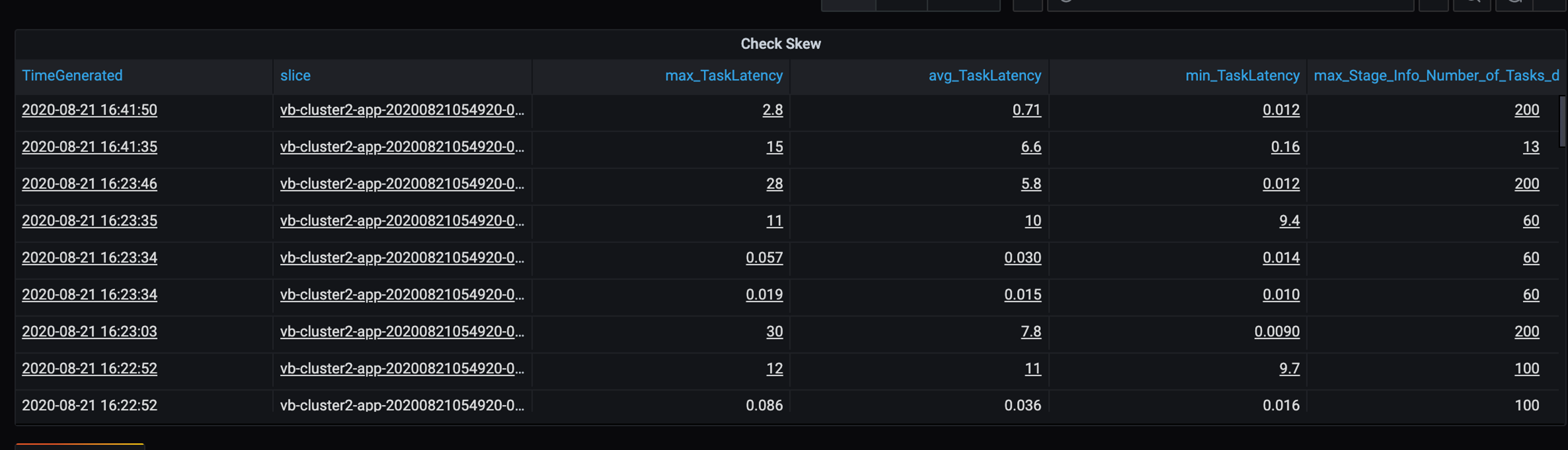
Traccia degli errori
Aggiungere un dashboard per la traccia degli errori in modo da individuare gli errori dei dati specifici del cliente. Durante la pre-elaborazione dei dati, in alcuni casi i file vengono danneggiati e i record al loro interno non corrispondono allo schema dei dati. Il dashboard seguente rileva molti file errati e record errati.
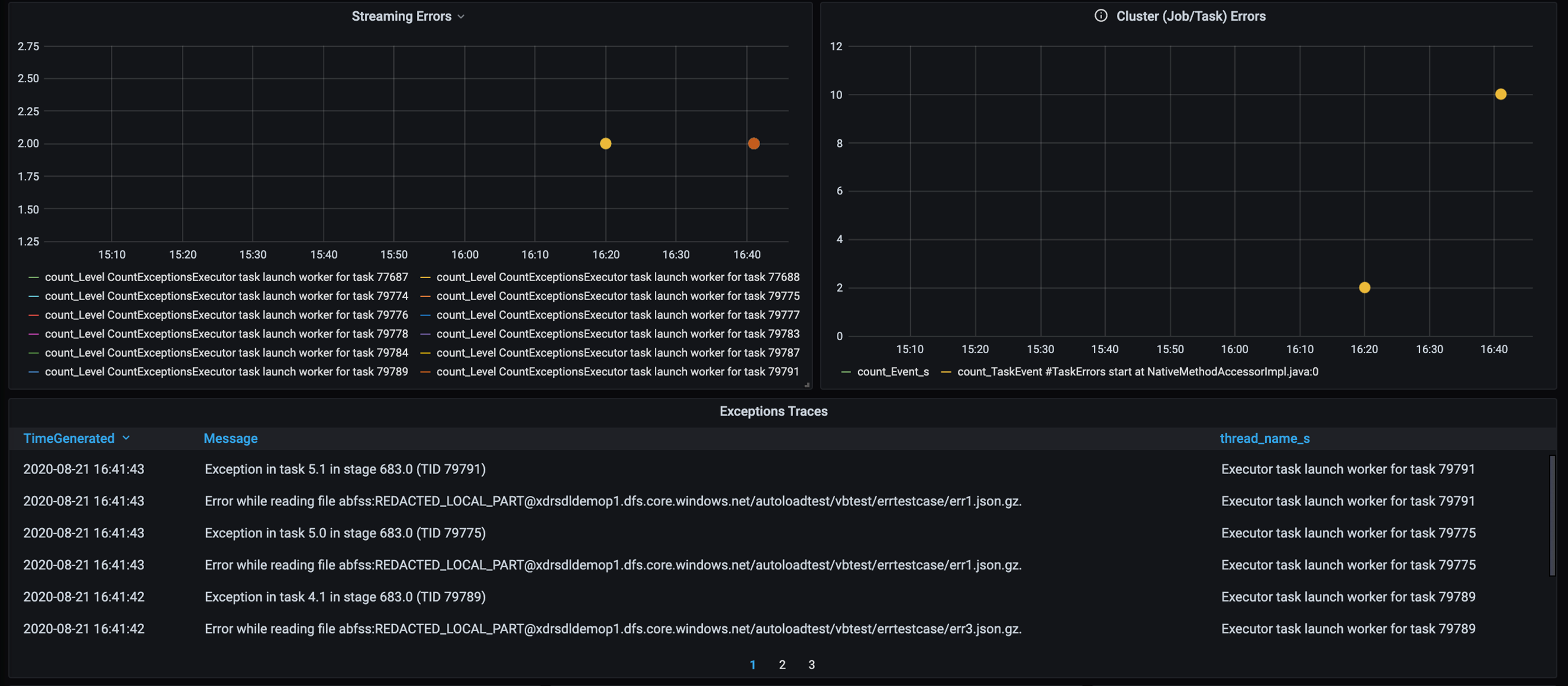
Questo dashboard visualizza il numero di errori, il messaggio di errore e l'ID attività per il debug. Nel messaggio è possibile tracciare facilmente l'errore nel file di errori. Durante la lettura sono presenti diversi file con errori. Esaminare la sequenza temporale superiore ed esaminare i punti specifici del grafico (16:20 e 16:40).
Altri colli di bottiglia
Per altri esempi e indicazioni, vedere Risolvere i colli di bottiglia delle prestazioni in Azure Databricks.
Riepilogo della valutazione per l'ottimizzazione delle prestazioni
Per questo scenario, queste metriche identificano le osservazioni seguenti:
- Nel grafico della latenza delle fasi, le fasi di scrittura richiedono la maggior parte del tempo di elaborazione.
- Nel grafico della latenza delle attività, la latenza delle attività è stabile.
- Nel grafico della velocità effettiva di streaming, la velocità di output è inferiore alla velocità di input in alcuni punti.
- Nella tabella della durata dell'attività è presente una varianza delle attività a causa dello sbilanciamento dei dati del cliente.
- Per ottenere prestazioni ottimizzate nella fase di partizionamento, il numero di executor di ridimensionamento deve corrispondere al numero di partizioni.
- Sono presenti errori di traccia, ad esempio file errati e record errati.
Per diagnosticare questi problemi, sono state usate le metriche seguenti:
- Latenza del processo
- Latenza delle fasi
- Latenza delle attività
- Velocità effettiva di streaming
- Durata attività (max, media, min) per fase
- Traccia degli errori (conteggio, messaggio, ID attività)
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- David McGhee | Principal Program Manager
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
- Vedere l'esercitazione su Log Analytics.
- Monitoraggio di Azure Databricks in un'area di lavoro Azure Log Analytics
- Distribuzione di Azure Log Analytics con le metriche di Spark
- Modelli di osservabilità