Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il provisioning automatizzato è un processo per distribuire e configurare rapidamente le risorse necessarie per eseguire il cluster di Azure Esplora dati. È una parte fondamentale di un flusso di lavoro DevOps o DataOps. Il processo di provisioning non richiede la configurazione manuale del cluster, non richiede l'intervento umano ed è facile da configurare.
È possibile usare il provisioning automatizzato per distribuire un cluster preconfigurato con dati, come parte di una pipeline di integrazione continua e recapito continuo (CI/CD). Alcuni dei principali vantaggi di questa operazione includono la possibilità di:
- Definire e gestire più ambienti.
- Tenere traccia delle distribuzioni nel controllo del codice sorgente.
- Eseguire più facilmente il rollback alle versioni precedenti.
- Facilitare i test automatizzati effettuando il provisioning di ambienti di test dedicati.
Questo articolo offre una panoramica dei diversi meccanismi per automatizzare il provisioning degli ambienti di Esplora dati di Azure, tra cui infrastruttura, entità dello schema e inserimento dati. Fornisce anche riferimenti ai diversi strumenti e tecniche usati per automatizzare il processo di provisioning.

Distribuire l'infrastruttura
La distribuzione dell'infrastruttura riguarda la distribuzione delle risorse di Azure, inclusi cluster, database e connessioni dati. Esistono diversi tipi di distribuzioni dell'infrastruttura, tra cui:
- Distribuzione di modelli di Azure Resource Manager (ARM)
- Distribuzione di Terraform
- Distribuzione imperativa
I modelli arm e gli script Terraform sono i due modi principali e dichiarativi per distribuire l'infrastruttura di Azure Esplora dati.
Distribuzione di modelli di Resource Manager
I modelli arm sono file JSON o Bicep che definiscono l'infrastruttura e la configurazione di una distribuzione. È possibile usare i modelli per distribuire cluster, database, connessioni dati e molti altri componenti dell'infrastruttura. Per altre informazioni, vedere Creare un cluster e un database di Azure Esplora dati usando un modello di Azure Resource Manager.
È anche possibile usare i modelli di Resource Manager per distribuire script di comando, che consentono di creare uno schema di database e definire i criteri. Per altre informazioni, vedere Configurare un database usando uno script di Linguaggio di query Kusto.
È possibile trovare altri modelli di esempio nel sito Modelli di avvio rapido di Azure.
Distribuzione Terraform
Terraform è uno strumento software open source, infrastructure-as-code. Offre un flusso di lavoro coerente dell'interfaccia della riga di comando per gestire i servizi cloud. Terraform codifica le API cloud in file di configurazione dichiarativi.
Terraform offre le stesse funzionalità dei modelli arm. È possibile usare Terraform per distribuire cluster, database, connessioni dati e altri componenti dell'infrastruttura.
È anche possibile usare Terraform per distribuire script di comando che consentono di creare uno schema di database e definire i criteri.
Distribuzione imperativa
È anche possibile distribuire l'infrastruttura in modo imperativo usando una delle piattaforme supportate:
Distribuire le entità dello schema
Il provisioning delle entità dello schema riguarda la distribuzione di tabelle, funzioni, criteri e autorizzazioni. È possibile creare o aggiornare entità eseguendo script costituiti da comandi di gestione.
È possibile automatizzare la distribuzione delle entità dello schema usando i metodi seguenti:
- Modelli di Gestione risorse di Azure
- Script Terraform
- Interfaccia della riga di comando di Kusto
- SDK
- Utensileria
- Sincronizzare Kusto. Usare questo strumento di sviluppo interattivo per estrarre lo schema del database o lo script di comando di gestione. È quindi possibile usare lo script di comando contenuto estratto per la distribuzione automatica.
- Delta Kusto: richiamare questo strumento in una pipeline CI/CD. Può confrontare due origini, ad esempio lo schema del database o lo script del comando di gestione, e calcolare uno script di comando di gestione differenziale. È quindi possibile usare lo script di comando contenuto estratto per la distribuzione automatica.
- Attività Di Azure DevOps per Azure Esplora dati.
Inserire i dati
In alcuni casi si vogliono inserire dati nel cluster. Ad esempio, è possibile inserire dati per eseguire test o ricreare un ambiente. Per inserire dati, è possibile usare i metodi seguenti:
- SDK
- Strumento dell'interfaccia della riga di comando più chiaro
- Attivazione di una pipeline di Azure Data Factory
Distribuzione di esempio con una pipeline CI/CD
Nell'esempio seguente si usa una pipeline CI/CD di Azure DevOps che esegue strumenti per automatizzare la distribuzione di infrastruttura, entità dello schema e dati. Questo è un esempio di una pipeline che usa un determinato set di strumenti, ma è possibile usare altri strumenti e passaggi. Ad esempio, in un ambiente di produzione può essere necessario creare una pipeline che non inserisce dati. È anche possibile aggiungere altri passaggi alla pipeline, ad esempio l'esecuzione di test automatizzati nel cluster creato.
In questo caso si usano gli strumenti seguenti:
| Tipo di distribuzione | Strumento | Attività |
|---|---|---|
| Infrastruttura | Modelli di Gestione risorse di Azure | Creare un cluster e un database |
| Entità dello schema | Interfaccia della riga di comando di Kusto | Creare tabelle nel database |
| Dati | LightIngest | Inserire dati in una tabella |

Usare la procedura seguente per creare una pipeline.
Passaggio 1: Creare una connessione al servizio
Definire una connessione al servizio di tipo Azure Resource Manager. Puntare la connessione alla sottoscrizione e al gruppo di risorse in cui si vuole distribuire il cluster. Viene creata un'entità servizio di Azure e viene usata per distribuire il modello di Resource Manager. È possibile usare la stessa entità per distribuire le entità dello schema e inserire i dati. È necessario passare in modo esplicito le credenziali all'interfaccia della riga di comando di Kusto e agli strumenti LightIngest.
Passaggio 2: Creare una pipeline
Definire la pipeline (deploy-environ) che verrà usata per distribuire il cluster, creare entità dello schema e inserire dati.
Prima di poter usare la pipeline, è necessario creare le variabili segrete seguenti:
| Nome variabile | Descrizione |
|---|---|
clusterName |
Nome del cluster Esplora dati di Azure. |
serviceConnection |
Nome della connessione di Azure DevOps usata per distribuire il modello di Resource Manager. |
appId |
ID client dell'entità servizio usato per interagire con il cluster. |
appSecret |
Segreto dell'entità servizio. |
appTenantId |
ID tenant dell'entità servizio. |
location |
Area di Azure in cui si distribuirà il cluster. Ad esempio: eastus. |
resources:
- repo: self
stages:
- stage: deploy_cluster
displayName: Deploy cluster
variables: []
clusterName: specifyClusterName
serviceConnection: specifyServiceConnection
appId: specifyAppId
appSecret: specifyAppSecret
appTenantId: specifyAppTenantId
location: specifyLocation
jobs:
- job: e2e_deploy
pool:
vmImage: windows-latest
variables: []
steps:
- bash: |
nuget install Microsoft.Azure.Kusto.Tools -Version 5.3.1
# Rename the folder (including the most recent version)
mv Microsoft.Azure.Kusto.Tools.* kusto.tools
displayName: Download required Kusto.Tools Nuget package
- task: AzureResourceManagerTemplateDeployment@3
displayName: Deploy Infrastructure
inputs:
deploymentScope: 'Resource Group'
# subscriptionId and resourceGroupName are specified in the serviceConnection
azureResourceManagerConnection: $(serviceConnection)
action: 'Create Or Update Resource Group'
location: $(location)
templateLocation: 'Linked artifact'
csmFile: deploy-infra.json
overrideParameters: "-clusterName $(clusterName)"
deploymentMode: 'Incremental'
- bash: |
# Define connection string to cluster's database, including service principal's credentials
connectionString="https://$(clusterName).$(location).kusto.windows.net/myDatabase;Fed=true;AppClientId=$(appId);AppKey=$(appSecret);TenantId=$(appTenantId)"
# Execute a KQL script against the database
kusto.tools/tools/Kusto.Cli $connectionString -script:MyDatabase.kql
displayName: Create Schema Entities
- bash: |
connectionString="https://ingest-$(CLUSTERNAME).$(location).kusto.windows.net/;Fed=true;AppClientId=$(appId);AppKey=$(appSecret);TenantId=$(appTenantId)"
kusto.tools/tools/LightIngest $connectionString -table:Customer -sourcePath:customers.csv -db:myDatabase -format:csv -ignoreFirst:true
displayName: Ingest Data
Passaggio 3: Creare un modello di Resource Manager per distribuire il cluster
Definire il modello di Resource Manager (deploy-infra.json) che verrà usato per distribuire il cluster nella sottoscrizione e nel gruppo di risorse.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"clusterName": {
"type": "string",
"minLength": 5
}
},
"variables": {
},
"resources": [
{
"name": "[parameters('clusterName')]",
"type": "Microsoft.Kusto/clusters",
"apiVersion": "2021-01-01",
"location": "[resourceGroup().location]",
"sku": {
"name": "Dev(No SLA)_Standard_E2a_v4",
"tier": "Basic",
"capacity": 1
},
"resources": [
{
"name": "myDatabase",
"type": "databases",
"apiVersion": "2021-01-01",
"location": "[resourceGroup().location]",
"dependsOn": [
"[resourceId('Microsoft.Kusto/clusters', parameters('clusterName'))]"
],
"kind": "ReadWrite",
"properties": {
"softDeletePeriodInDays": 365,
"hotCachePeriodInDays": 31
}
}
]
}
]
}
Passaggio 4: Creare uno script KQL per creare le entità dello schema
Definire lo script KQL (MyDatabase.kql) che verrà usato per creare le tabelle nei database.
.create table Customer(CustomerName:string, CustomerAddress:string)
// Set the ingestion batching policy to trigger ingestion quickly
// This is to speedup reaction time for the sample
// Do not do this in production
.alter table Customer policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:10", "MaximumNumberOfItems": 500, "MaximumRawDataSizeMB": 1024}'
.create table CustomerLogs(CustomerName:string, Log:string)
Passaggio 5: Creare uno script KQL per inserire i dati
Creare il file di dati CSV (customer.csv) da inserire.
customerName,customerAddress
Contoso Ltd,Paris
Datum Corporation,Seattle
Fabrikam,NYC
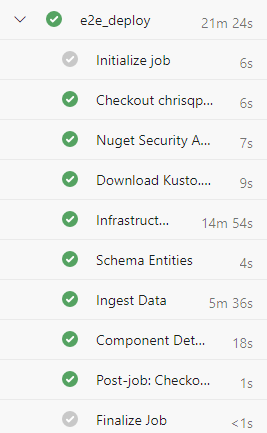
Il cluster viene creato usando le credenziali dell'entità servizio specificate nella pipeline. Per concedere le autorizzazioni agli utenti, seguire la procedura descritta in Gestire le autorizzazioni del database di Azure Esplora dati.
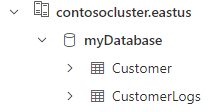
È possibile verificare la distribuzione eseguendo una query sulla tabella Customer . Verranno visualizzati i tre record importati dal file CSV.
Contenuto correlato
- Creare un cluster e un database usando un modello di Azure Resource Manager.
- Configurare un database usando uno script KQL