Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Questo articolo illustra come usare l'attività di copia in Azure Data Factory per copiare dati da e in un archivio dati ODBC. Si basa sull'articolo di panoramica dell'attività di copia che presenta una panoramica generale sull'attività di copia.
Funzionalità supportate
Questo connettore ODBC è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività Copy (origine/sink) | 2 |
| Attività di Ricerca | 2 |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per un elenco degli archivi dati supportati come origini o sink, vedere la tabella Archivi dati supportati.
In particolare, il connettore ODBC supporta la copia dei dati da o verso qualsiasi archivio dati compatibile con ODBC tramite l'autenticazione di base o anonima. È necessario un driver ODBC a 64 bit. Per il sink ODBC, il servizio supporta lo standard ODBC versione 2.0.
Prerequisiti
Per usare il connettore ODBC è necessario:
- Configurare un Integration Runtime autogestito. Per informazioni dettagliate, vedere l'articolo Self-hosted Integration Runtime.
- Installare il driver ODBC a 64 bit per l'archivio dati nel computer Integration Runtime.
Iniziare
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o degli SDK seguenti:
- Strumento Copia Dati
- portale Azure
- .NET SDK
- Python SDK
- Azure PowerShell
- API REST
- modello Azure Resource Manager
Creare un servizio collegato a un archivio dati ODBC usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a un archivio dati ODBC nell'interfaccia utente del portale di Azure.
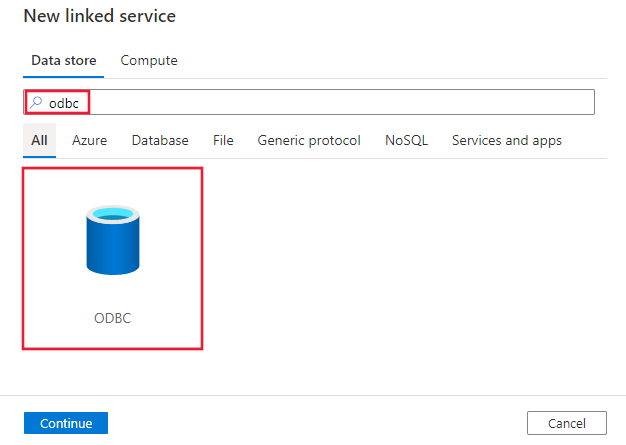
Passare alla scheda Gestisci nell'area di lavoro Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare ODBC e selezionare il connettore ODBC.
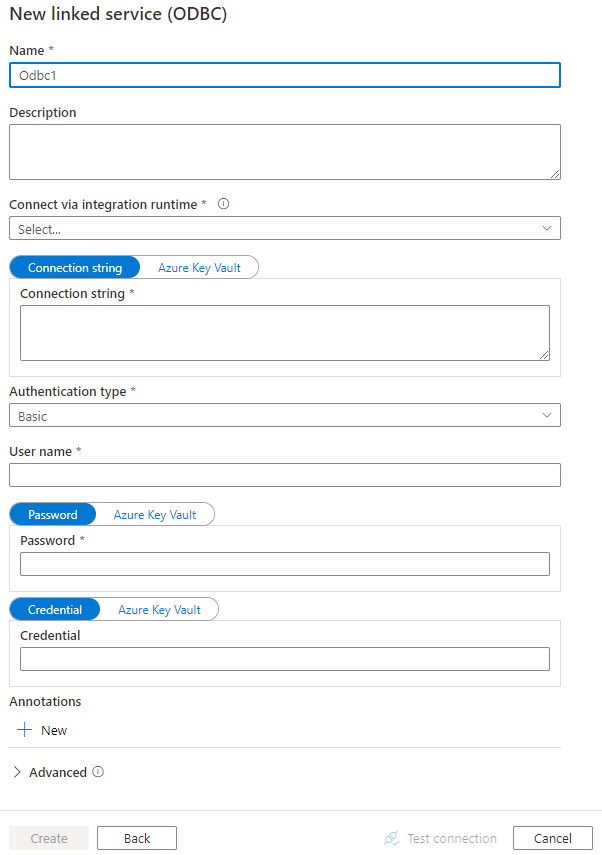
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti riportano informazioni dettagliate sulle proprietà che vengono usate per definire entità di data factory specifiche per il connettore ODBC.
Proprietà del servizio collegato
Le seguenti proprietà sono supportate per il servizio collegato ODBC:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| tipo | La proprietà type deve essere impostata su ODBC | Sì |
| stringa di connessione | La stringa di connessione esclude la parte delle credenziali. È possibile specificare il connection string con modello come Driver={SQL Server};Server=Server.database.windows.net; Database=TestDatabase; oppure usare il DSN di sistema (nome origine dati) configurato nel computer Integration Runtime con DSN=<name of the DSN on IR machine>; (è comunque necessario specificare di conseguenza la parte delle credenziali nel servizio collegato).È anche possibile inserire una password in Azure Key Vault ed estrarre la configurazione password dalla connection string. Per ulteriori dettagli, consultare Archiviare le credenziali in Azure Key Vault. |
Sì |
| tipo di autenticazione | Tipo di autenticazione usato per connettersi all'archivio dati ODBC. I valori consentiti sono Base e Anonimo. |
Sì |
| userName | Specificare il nome utente se si usa l'autenticazione di base. | No |
| password | Specificare la password per l'account utente specificato per userName. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro o referenziare un segreto archiviato in Azure Key Vault. | No |
| credenziali | La parte delle credenziali di accesso della stringa di connessione specificata nel formato di valore della proprietà specifico del driver. Esempio: "RefreshToken=<secret refresh token>;". Contrassegnare questo campo come SecureString. |
No |
| connectVia | Integration Runtime da usare per connettersi all'archivio dati. Un Self-hosted Integration Runtime è necessario come indicato in Prerequisiti. | Sì |
Esempio 1: uso dell'autenticazione di base
{
"name": "ODBCLinkedService",
"properties": {
"type": "Odbc",
"typeProperties": {
"connectionString": "<connection string>",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio 2: uso dell'autenticazione anonima
{
"name": "ODBCLinkedService",
"properties": {
"type": "Odbc",
"typeProperties": {
"connectionString": "<connection string>",
"authenticationType": "Anonymous",
"credential": {
"type": "SecureString",
"value": "RefreshToken=<secret refresh token>;"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione di set di dati, vedere l'articolo sui set di dati. Questa sezione presenta un elenco delle proprietà supportate dal set di dati ODBC.
Per copiare dati da e verso un archivio dati compatibile con ODBC, sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| tipo | La proprietà type del set di dati deve essere impostata su OdbcTable | Sì |
| tableName | Nome della tabella nell'archivio dati ODBC. | No per l'origine (se nell'origine dell'attività è specificato "query"); Sì per il lavello |
Esempio
{
"name": "ODBCDataset",
"properties": {
"type": "OdbcTable",
"schema": [],
"linkedServiceName": {
"referenceName": "<ODBC linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "<table name>"
}
}
}
Il set di dati tipizzato RelationalTable è ancora supportato senza modifiche, ma è consigliato l'uso del nuovo per il futuro.
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dall'origine di ODBC.
ODBC come origine
Per copiare i dati da un archivio dati compatibile con ODBC, nella sezione origine dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| tipo | La proprietà type dell'origine dell'attività di copia deve essere impostata su OdbcSource | Sì |
| interrogazione | Usare la query SQL personalizzata per leggere i dati. Ad esempio: "SELECT * FROM MyTable". |
No (se nel set di dati è specificato "tableName") |
Esempio:
"activities":[
{
"name": "CopyFromODBC",
"type": "Copy",
"inputs": [
{
"referenceName": "<ODBC input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "OdbcSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
L'origine tipizzata RelationalSource è ancora supportata senza modifiche, ma è consigliato l'uso della nuova per il futuro.
ODBC come sink
Per copiare i dati nell'archivio dati compatibile con ODBC, impostare il tipo di sink nell'attività di copia su OdbcSink. Nella sezione sink dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| tipo | La proprietà type del sink dell'attività di copia deve essere impostata su: OdbcSink | Sì |
| writeBatchTimeout | Tempo di attesa per l'operazione di inserimento batch da completare prima del timeout. I valori consentiti sono: intervallo di tempo. Ad esempio: "00:30:00" (30 minuti). |
No |
| writeBatchSize | Inserisce dati nella tabella SQL quando la dimensione del buffer raggiunge writeBatchSize. I valori consentiti sono integer, ovvero il numero di righe. |
No (l'impostazione predefinita è 0 - rilevamento automatico) |
| preCopyScript | Specificare una query SQL per l'attività di copia da eseguire prima di scrivere i dati nell'archivio dati in ogni esecuzione. È possibile usare questa proprietà per pulire i dati precaricati. | No |
Nota
Per "writeBatchSize", se non impostato tramite il rilevamento automatico, l'attività di copia rileva prima se il driver supporta le operazioni batch e in caso affermativo lo imposta su 10000, in caso contrario lo imposta su 1. Se si imposta in modo esplicito un valore diverso da 0, l'attività di copia rispetta il valore e fallisce in fase di runtime se il driver non supporta le operazioni batch.
Esempio:
"activities":[
{
"name": "CopyToODBC",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ODBC output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "OdbcSink",
"writeBatchSize": 100000
}
}
}
]
Proprietà dell'attività Lookup
Per conoscere i dettagli delle proprietà, vedere Attività di ricerca.
Risolvere i problemi di connettività
Per risolvere i problemi di connessione, usare la scheda Diagnostics di Integration Runtime Configuration Manager.
- Avviare Integration Runtime Configuration Manager.
- Passare alla scheda Diagnostica .
- Nella sezione "Connessione di test" selezionare il tipo di archivio dati, ovvero il servizio collegato.
- Specificare il connection string usato per connettersi all'archivio dati. scegliere il autenticazione e immettere nome utente, password e/o credentials.
- Fare clic su Test connessione per testare la connessione all'archivio dati.
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e sink dall'attività Copy, consultare la sezione Archivi dati supportati.