Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Questo articolo illustra come usare l'attività di copia nelle pipeline di Azure Data Factory e Synapse Analytics per copiare dati da un database PostgreSQL. Si basa sull'articolo di panoramica dell'attività di copia che presenta una panoramica generale sull'attività di copia.
Nota
Questo connettore è disponibile anche in Data Factory in Microsoft Fabric. Per la configurazione e le funzionalità specifiche di Fabric, vedere la documentazione del connettore PostgreSQL Fabric.
Importante
Il connettore PostgreSQL V1 è in fase di rimozione. È consigliabile aggiornare il connettore PostgreSQL da V1 a V2.
Funzionalità supportate
Questo connettore PostgreSQL è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività di copia (fonte/-) | (1) (2) |
| Attività di ricerca | (1) (2) |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per un elenco degli archivi dati supportati come origini/sink dall'attività di copia, vedere la tabella relativa agli archivi dati supportati.
In particolare, questo connettore PostgreSQL supporta PostgreSQL versione 12 e successive.
Prerequisiti
Se l'archivio dati si trova all'interno di una rete locale, di una rete virtuale Azure o di Amazon Virtual Private Cloud, è necessario configurare un runtime di integrazione self-hosted per connettersi.
Se l'archivio dati è un servizio dati cloud gestito, è possibile usare il Azure Integration Runtime. Se l'accesso è limitato agli indirizzi IP approvati nelle regole del firewall, è possibile aggiungere Azure Integration Runtime IP all'elenco elementi consentiti.
È anche possibile usare la funzionalità managed virtual network integration runtime in Azure Data Factory per accedere alla rete locale senza installare e configurare un runtime di integrazione self-hosted.
Per altre informazioni sui meccanismi di sicurezza di rete e sulle opzioni supportate da Data Factory, vedere strategie di accesso ai dati.
Il Integration Runtime fornisce un driver PostgreSQL predefinito a partire dalla versione 3.7, pertanto non è necessario installare manualmente alcun driver.
Per iniziare
Per eseguire l'attività Copy con una pipeline, è possibile usare uno degli strumenti o degli SDK seguenti:
- Strumento Copia dati
- portale Azure
- .NET SDK
- PYTHON SDK
- Azure PowerShell
- API REST
- modello Azure Resource Manager
Creare un servizio collegato a PostgreSQL usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a PostgreSQL nell'interfaccia utente del portale di Azure.
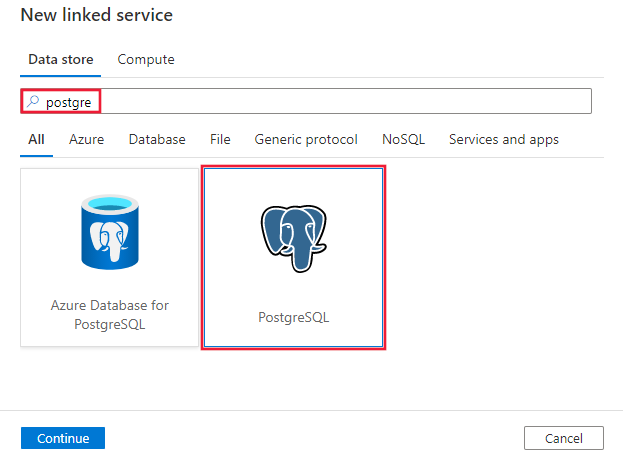
Passare alla scheda Gestisci nell'area di lavoro Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare Postgre e selezionare il connettore PostgreSQL.
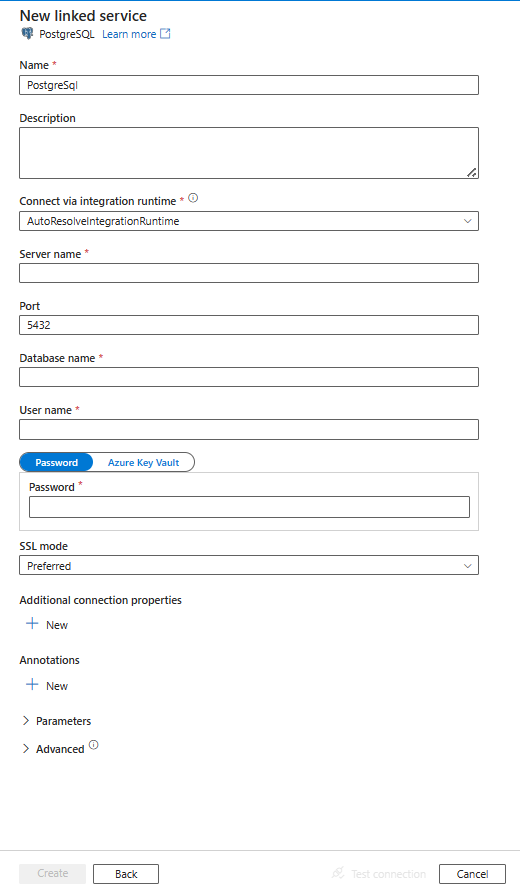
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti riportano informazioni dettagliate sulle proprietà che vengono usate per definire entità di data factory specifiche per il connettore PostgreSQL.
Proprietà del servizio collegato
Per il servizio collegato di PostgreSQL sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type deve essere impostata su: PostgreSqlV2 | Sì |
| server | Specifica il nome host e, facoltativamente, la porta in cui è in esecuzione PostgreSQL. | Sì |
| porto | Porta TCP del server PostgreSQL. | NO |
| banca dati | Database PostgreSQL a cui connettersi. | Sì |
| nome utente | Nome utente con cui connettersi. | Sì |
| parola d'ordine | Password con cui connettersi. | Sì |
| sslMode | Controlla se viene usato SSL, a seconda del supporto del server. - Disabilitato: SSL è disabilitato. Se il server richiede SSL, la connessione avrà esito negativo. - Consenti: preferisce le connessioni non SSL se il server le consente, ma consente le connessioni SSL. - Preferito: preferisce le connessioni SSL se il server le consente, ma consente le connessioni senza SSL. - Obbligatorio: non eseguire la connessione se il server non supporta SSL. - Verify_ca: non eseguire la connessione se il server non supporta SSL. Verifica anche il certificato del server. - Verify_full: non eseguire la connessione se il server non supporta SSL. Verifica anche il certificato del server con il nome dell'host. Opzioni: Disabilitato (0) / Consenti (1) / Preferito (2) (impostazione predefinita) / Obbligatorio (3) / Verify_ca (4) / Verify_full (5) |
NO |
| tipo di autenticazione | Tipo di autenticazione per la connessione al database. Supporta solo Basic. | Sì |
| connectVia | Integration Runtime da usare per connettersi all'archivio dati. Per altre informazioni, vedere la sezione Prerequisiti. Se non specificato, usa il Azure Integration Runtime predefinito. | NO |
| Proprietà di connessione aggiuntive: | ||
| schema | Imposta il percorso di ricerca dello schema. | NO |
| raggruppamento | Se debba essere utilizzato il pooling delle connessioni. | NO |
| connectionTimeout | Tempo di attesa (in secondi) durante il tentativo di stabilire una connessione prima di terminare il tentativo e generare un errore. | NO |
| commandTimeout | Tempo di attesa (in secondi) durante il tentativo di esecuzione di un comando prima di terminare il tentativo e generare un errore. Impostare su zero per infinito. | NO |
| trustServerCertificate | Se considerare attendibile il certificato del server senza convalidarlo. | NO |
| Certificato ssl | Percorso di un certificato client da inviare al server. | NO |
| chiave SSL | Posizione di una chiave client per l'invio di un certificato client al server. | NO |
| sslPassword | Password per una chiave per un certificato client. | NO |
| dimensione del buffer di lettura (readBufferSize) | Determina le dimensioni del buffer interno usato da Npgsql durante la lettura. L'aumento può migliorare le prestazioni se si trasferiscono valori di grandi dimensioni dal database. | NO |
| logParameters | Se abilitata, i valori dei parametri vengono registrati quando vengono eseguiti i comandi. | NO |
| fuso orario | Ottiene o imposta il fuso orario della sessione. | NO |
| codifica | Ottiene o imposta la codifica .NET che verrà usata per codificare/decodificare i dati della stringa PostgreSQL. | NO |
Nota
Per avere la verifica SSL completa tramite la connessione ODBC quando si usa l'Integration Runtime self-hosted, è necessario usare una connessione di tipo ODBC anziché il connettore PostgreSQL in modo esplicito e completare la configurazione seguente:
- Configurare il DSN in qualsiasi server SHIR.
- Inserire il certificato appropriato per PostgreSQL in C:\Windows\ServiceProfiles\DIAHostService\AppData\Roaming\postgresql\root.crt nei server SHIR. In questo caso, il driver ODBC cerca > il certificato SSL da verificare quando si connette al database.
- Nella connessione del tuo data factory, utilizza una connessione di tipo ODBC, con una stringa di connessione che punta al DSN creato sui server SHIR.
Esempio:
{
"name": "PostgreSqlLinkedService",
"properties": {
"type": "PostgreSqlV2",
"typeProperties": {
"server": "<server>",
"port": 5432,
"database": "<database>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"sslmode": <sslmode>,
"authenticationType": "Basic"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Esempio: archiviare la password in Azure Key Vault
{
"name": "PostgreSqlLinkedService",
"properties": {
"type": "PostgreSqlV2",
"typeProperties": {
"server": "<server>",
"port": 5432,
"database": "<database>",
"username": "<username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
"sslmode": <sslmode>,
"authenticationType": "Basic"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione di set di dati, vedere l'articolo sui set di dati. Questa sezione presenta un elenco delle proprietà supportate dal set di dati di PostgreSQL.
Per copiare dati da PostgreSQL, sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type del set di dati deve essere impostata su: PostgreSqlV2Table | Sì |
| schema | Nome dello schema. | No (se nell'origine dell'attività è specificato "query") |
| tabella | Nome della tabella. | No (se nell'origine dell'attività è specificato "query") |
Esempio
{
"name": "PostgreSQLDataset",
"properties":
{
"type": "PostgreSqlV2Table",
"linkedServiceName": {
"referenceName": "<PostgreSQL linked service name>",
"type": "LinkedServiceReference"
},
"annotations": [],
"schema": [],
"typeProperties": {
"schema": "<schema name>",
"table": "<table name>"
}
}
}
Il set di dati tipizzato RelationalTable è ancora supportato senza modifiche, ma è consigliato l'uso del nuovo per il futuro.
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dall'origine PostgreSQL.
PostgreSQL come origine
Per copiare dati da PostgreSQL, nella sezione origine dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type dell'origine dell'attività di copia deve essere impostata su: PostgreSqlV2Source | Sì |
| quesito | Usare la query SQL personalizzata per leggere i dati. Ad esempio: "query": "SELECT * FROM \"MySchema\".\"MyTable\"". |
No (se nel set di dati è specificato "tableName") |
| queryTimeout | Il tempo di attesa prima di terminare il tentativo di eseguire un comando e generare un errore, il valore predefinito è 120 minuti. Se il parametro è impostato per questa proprietà, i valori consentiti sono timepan, ad esempio "02:00:00" (120 minuti). Per altre informazioni, vedere CommandTimeout. Se sia commandTimeout che queryTimeout sono configurati, queryTimeout ha la precedenza. |
NO |
Nota
I nomi di schemi e tabelle fanno distinzione tra maiuscole e minuscole. Racchiudere i nomi tra "" (virgolette doppie) nella query.
Esempio:
"activities":[
{
"name": "CopyFromPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<PostgreSQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "PostgreSqlV2Source",
"query": "SELECT * FROM \"MySchema\".\"MyTable\"",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Se utilizzavi l'origine tipizzata RelationalSource, è ancora supportata senza modifiche, ma è consigliato l'uso della nuova in futuro.
Mapping dei tipi di dati per PostgreSQL
Quando si copiano dati da PostgreSQL, i mapping seguenti vengono usati dai tipi di dati PostgreSQL ai tipi di dati provvisori usati internamente dal servizio. Vedere Mapping dello schema e del tipo di dati per informazioni su come l'attività di copia esegue il mapping dello schema di origine e del tipo di dati al sink.
| Tipo di dati di PostgreSQL | Tipo di dati del servizio provvisorio per PostgreSQL V2 | Tipo di dati del servizio provvisorio per PostgreSQL V1 |
|---|---|---|
SmallInt |
Int16 |
Int16 |
Integer |
Int32 |
Int32 |
BigInt |
Int64 |
Int64 |
Decimal (Precisione <= 28) |
Decimal |
Decimal |
Decimal (Precisione > 28) |
Non supportato | String |
Numeric |
Decimal |
Decimal |
Real |
Single |
Single |
Double |
Double |
Double |
SmallSerial |
Int16 |
Int16 |
Serial |
Int32 |
Int32 |
BigSerial |
Int64 |
Int64 |
Money |
Decimal |
String |
Char |
String |
String |
Varchar |
String |
String |
Text |
String |
String |
Bytea |
Byte[] |
Byte[] |
Timestamp |
DateTime |
DateTime |
Timestamp with time zone |
DateTime |
String |
Date |
DateTime |
DateTime |
Time |
TimeSpan |
TimeSpan |
Time with time zone |
DateTimeOffset |
String |
Interval |
TimeSpan |
String |
Boolean |
Boolean |
Boolean |
Point |
String |
String |
Line |
String |
String |
Iseg |
String |
String |
Box |
String |
String |
Path |
String |
String |
Polygon |
String |
String |
Circle |
String |
String |
Cidr |
String |
String |
Inet |
String |
String |
Macaddr |
String |
String |
Macaddr8 |
String |
String |
Tsvector |
String |
String |
Tsquery |
String |
String |
UUID |
Guid |
Guid |
Json |
String |
String |
Jsonb |
String |
String |
Array |
String |
String |
Bit |
Byte[] |
Byte[] |
Bit varying |
Byte[] |
Byte[] |
XML |
String |
String |
IntArray |
String |
String |
TextArray |
String |
String |
NumericArray |
String |
String |
DateArray |
String |
String |
Range |
String |
String |
Bpchar |
String |
String |
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Aggiornare il connettore PostgreSQL
Ecco i passaggi che consentono di aggiornare il connettore PostgreSQL:
Creare un nuovo servizio collegato PostgreSQL e configurarlo facendo riferimento alle Proprietà del servizio collegato.
Il mapping dei tipi di dati per il connettore PostgreSQL V2 è diverso da quello per V1. Per informazioni sul mapping dei tipi di dati più recente, vedere Mapping dei tipi di dati per PostgreSQL.
Differenze tra PostgreSQL V2 e V1
La tabella seguente illustra le differenze di mapping dei tipi di dati tra PostgreSQL V2 e V1.
| Tipo di dati di PostgreSQL | Tipo di dati del servizio provvisorio per PostgreSQL V2 | Tipo di dati del servizio provvisorio per PostgreSQL V1 |
|---|---|---|
| Moneta | Decimal | string |
| Timestamp con fuso orario | Datetime | string |
| Ora con fuso orario | DateTimeOffset | string |
| Intervallo | TimeSpan | string |
| BigDecimal | Non supportato. In alternativa, usare la funzione to_char() per convertire BigDecimal in String. |
string |
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e destinazioni dall'attività di copia, vedere archivi dati supportati.