Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
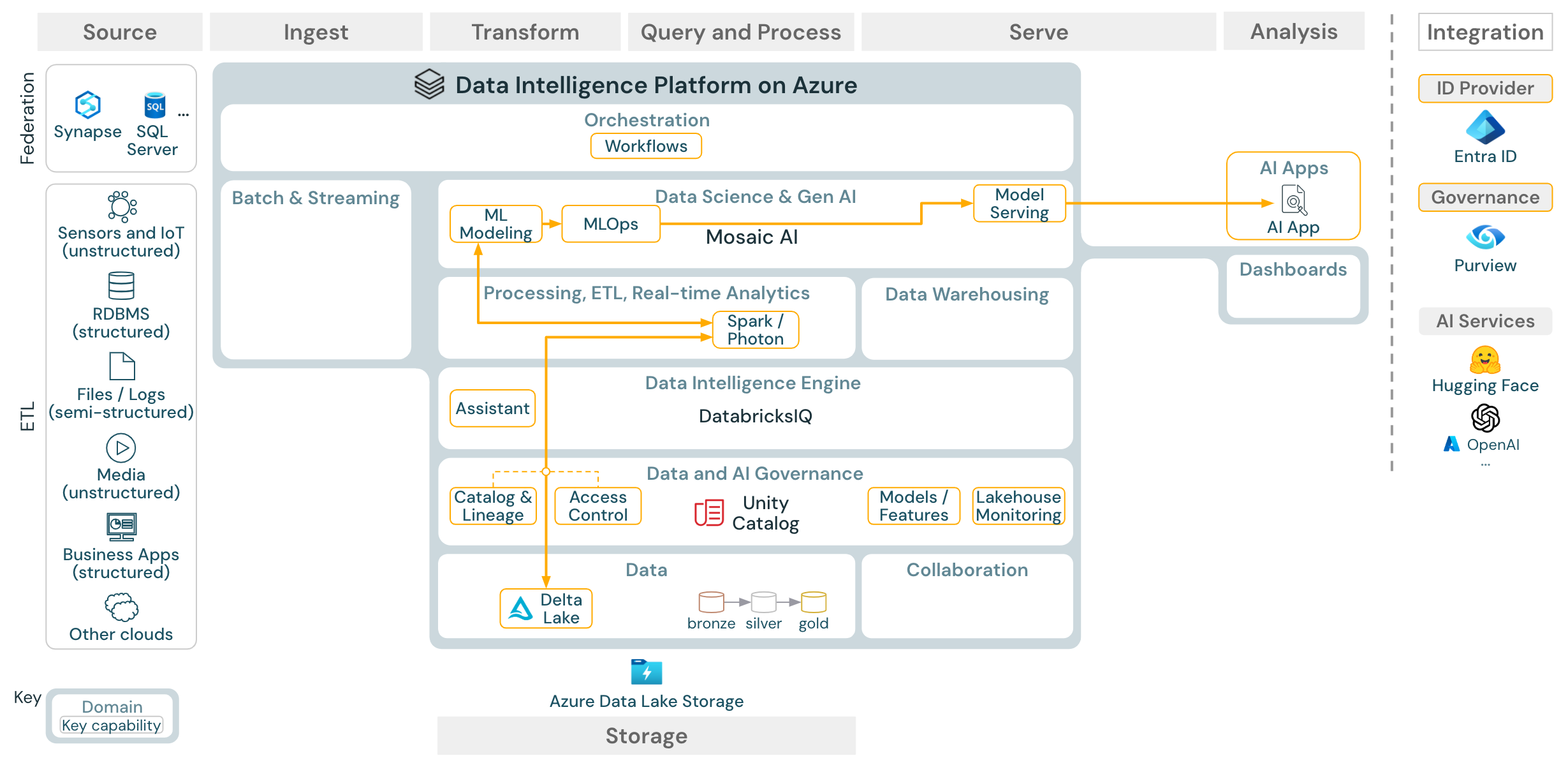
Questo articolo fornisce indicazioni sull'architettura per il data lakehouse, illustrando le origini dati, l'inserimento, la trasformazione, le query e l'elaborazione, il servizio, l'analisi e l'archiviazione.
Ogni architettura di riferimento ha un PDF scaricabile in formato 11 x 17 (A3).
Anche se il lakehouse in Databricks è una piattaforma aperta che si integra con un ampio ecosistema di strumenti partner, le architetture di riferimento si concentrano solo sui servizi di Azure e sul lakehouse di Databricks. I servizi del provider di servizi cloud visualizzati sono selezionati per illustrare i concetti e non sono esaustivi.
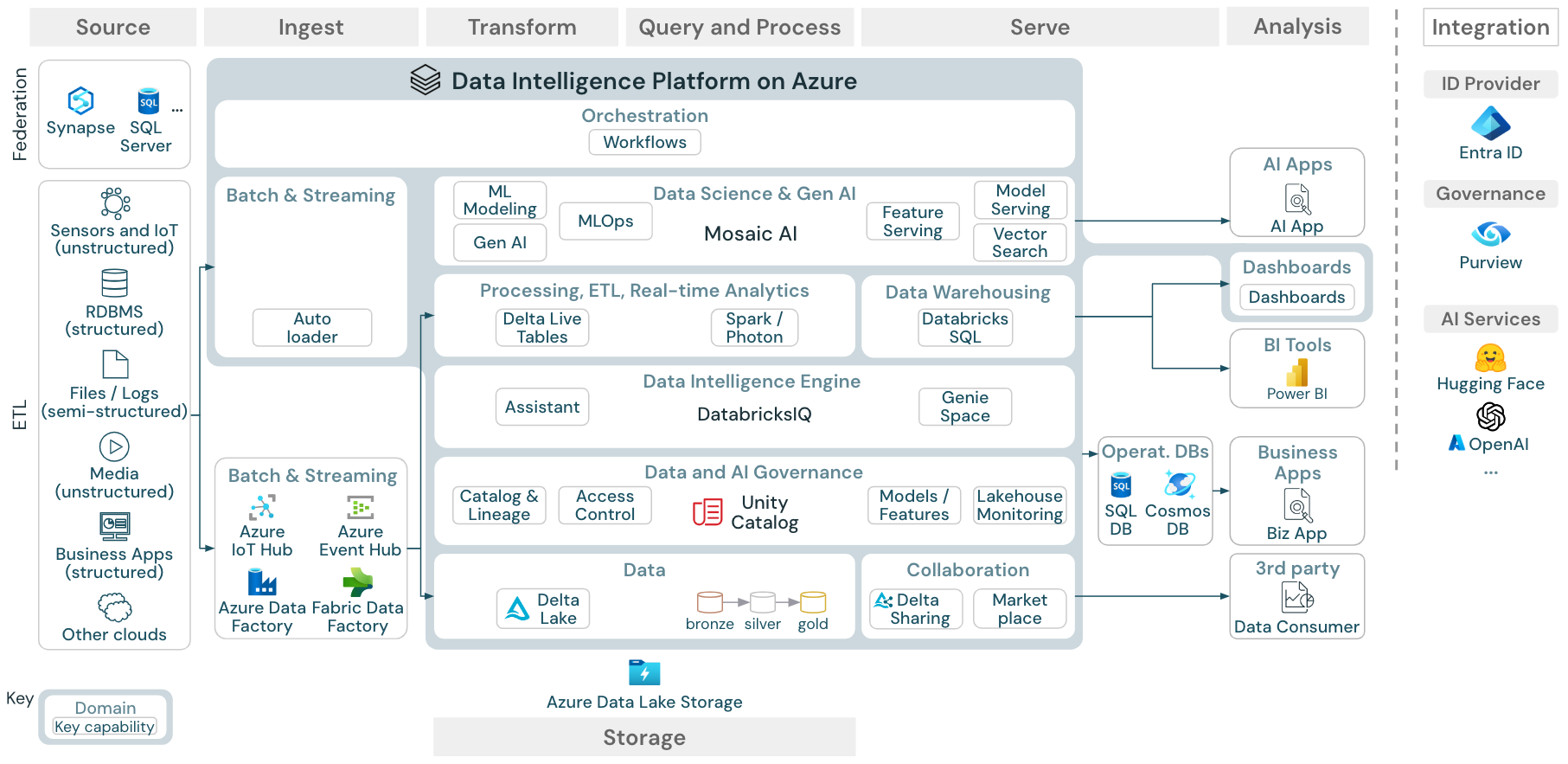
Download : Architettura di riferimento per Azure Databricks lakehouse
L'architettura di riferimento di Azure mostra i servizi specifici di Azure seguenti per l'inserimento, l'archiviazione, la gestione e l'analisi:
- Azure Synapse e SQL Server come sistemi di origine per Lakehouse Federation
- Hub IoT di Azure e Event Hubs di Azure per l'inserimento in streaming
- Utilizzo di Azure Data Factory per l’ingestione batch
- Azure Data Lake Storage Gen 2 (ADLS) come risorsa di archiviazione degli oggetti per gli asset di dati e intelligenza artificiale
- Database SQL di Azure e Azure Cosmos DB come database operativi
- Azure Purview come catalogo aziendale al quale UC esporta informazioni sullo schema e sulla provenienza
- Power BI come strumento BI
- Azure OpenAI può essere usato da Model Serving come LLM esterno
Organizzazione delle architetture di riferimento
L'architettura di riferimento è strutturata lungo le corsie Origine, Acquisizione, Trasformazione, Interrogazione/Elaborazione, Servizio, Analisi, e Archiviazione:
Source
Esistono tre modi per integrare dati esterni nella piattaforma di Data Intelligence:
- ETL: la piattaforma consente l'integrazione con sistemi che forniscono dati semistrutturati e non strutturati (ad esempio sensori, dispositivi IoT, supporti, file e log), nonché dati strutturati da database relazionali o applicazioni aziendali.
- Lakehouse Federation: le origini SQL, ad esempio i database relazionali, possono essere integrate nel Lakehouse e nel Catalogo Unity senza ETL. In questo caso, i dati di sistema di origine sono governati da Unity Catalog e le query sono inviate al sistema di origine.
- Federazione del catalogo: i cataloghi metastore Hive possono anche essere integrati nel catalogo Unity tramite la federazione del catalogo, consentendo al catalogo Unity di controllare le tabelle archiviate in Metastore Hive.
Ingest
Integrare i dati nel data lakehouse tramite processi in batch o streaming.
- Databricks Lakeflow Connect offre connettori predefiniti per l'inserimento da applicazioni e database aziendali. La pipeline di inserimento risultante è governata da Unity Catalog e utilizza il calcolo computazionale serverless e Pipelines.
- I file recapitati all'archiviazione cloud possono essere caricati direttamente usando il caricatore automatico di Databricks.
- Per l’inserimento batch di dati da applicazioni aziendali in Delta Lake, il Databricks Lakehouse si basa su strumenti di inserimento dei partner con adattatori specifici per questi sistemi di registrazione.
- Gli eventi di streaming possono essere inseriti direttamente da sistemi di streaming di eventi come Kafka usando Databricks Structured Streaming. Le risorse di streaming possono essere sensori, IoT, o in processi di acquisizione dei cambiamenti dei dati.
Storage
- I dati vengono in genere archiviati nel sistema di archiviazione cloud in cui le pipeline ETL usano l'architettura medallion per archiviare i dati in modo curato come file/tabelle Delta o tabelle Apache Iceberg.
Trasformazione e query/processo
Databricks lakehouse usa i motori Apache Spark e Photon per tutte le trasformazioni e le query.
Pipelines è un framework dichiarativo per semplificare e ottimizzare pipeline di elaborazione dati affidabili, gestibili e testabili.
Basato su Apache Spark e Photon, Databricks Data Intelligence Platform supporta entrambi i tipi di carichi di lavoro: query SQL tramite SQL warehouse e carichi di lavoro SQL, Python e Scala tramite cluster di aree di lavoro.
Per la scienza dei dati (modellazione ML e IA generativa), la piattaforma Databricks per intelligenza artificiale e Machine Learning fornisce un runtime di Machine Learning specializzato per AutoML e per la codifica dei processi di Machine Learning. Tutti i flussi di lavoro di data science e MLOps sono supportati in modo ottimale da MLflow.
Serving
Per i casi d'uso di data warehousing (DWH) e BI, il Databricks lakehouse fornisce Databricks SQL, il data warehouse basato su SQL Warehouses e Serverless SQL Warehouses.
Per l'apprendimento automatico, Mosaic AI Model Serving è una funzionalità di gestione di modelli di livello aziendale scalabile e in tempo reale ospitata nel piano di controllo di Databricks. Mosaic AI Gateway è la soluzione di Databricks per gestire e monitorare l'accesso ai modelli di intelligenza artificiale generativi supportati e ai relativi modelli associati che servono gli endpoint.
Database operativi:
- Lakebase è un database OLTP (Online Transaction Processing) basato su Postgres e completamente integrato con databricks Data Intelligence Platform. Consente di creare database OLTP in Databricks e integrare carichi di lavoro OLTP con Lakehouse.
- I sistemi esterni, ad esempio i database operativi, possono essere usati per archiviare e distribuire prodotti dati finali alle applicazioni utente.
Collaboration:
I partner aziendali ottengono l'accesso sicuro ai dati necessari tramite la condivisione Delta.
Basato su Delta Sharing, il Databricks Marketplace è un forum aperto per lo scambio di prodotti di dati.
Clean Rooms sono ambienti protetti e protetti dalla privacy in cui più utenti possono collaborare sui dati aziendali sensibili senza accesso diretto ai dati dell'altro.
Analysis
Le applicazioni aziendali finali si trovano in questa corsia. Tra gli esempi sono inclusi i client personalizzati, ad esempio applicazioni di intelligenza artificiale connesse a Mosaic AI Model Serving per inferenza in tempo reale o applicazioni che accedono ai dati di cui è stato eseguito il push dal lakehouse a un database operativo.
Per i casi d’uso di BI, gli analisti usano in genere gli strumenti di business intelligence per accedere al data warehouse. Gli sviluppatori SQL possono anche usare l’editor SQL di Databricks (non illustrato nel diagramma) per le query e il dashboard.
La piattaforma di data intelligence offre anche dashboard per creare visualizzazioni dei dati e condividere informazioni dettagliate.
Integrate
- La piattaforma Databricks si integra con provider di identità standard per la gestione degli utenti e Single Sign-On (SSO).
I servizi di intelligenza artificiale esterni come OpenAI, LangChain o HuggingFace possono essere usati direttamente dall'interno della piattaforma databricks Intelligence.
Gli agenti di orchestrazione esterni possono usare l'API REST completa o connettori dedicati a strumenti di orchestrazione esterni come Apache Airflow.
Unity Catalog è utilizzato per la governance di tutti i dati e l'intelligenza artificiale nella piattaforma Databricks Intelligence e può integrare altri database nella governance tramite Lakehouse Federation.
Inoltre, Il catalogo Unity può essere integrato in altri cataloghi aziendali, ad esempio Purview. Per informazioni dettagliate, contattare il fornitore del catalogo aziendale.
Funzionalità comuni per tutti i carichi di lavoro
Inoltre, Databricks lakehouse include funzionalità di gestione che supportano tutti i carichi di lavoro:
Governance dei dati e dell'intelligenza artificiale
Il sistema di governance centrale dei dati e dell'intelligenza artificiale in Databricks Data Intelligence Platform è Unity Catalog. Il catalogo unity offre un’unica posizione per gestire i criteri di accesso ai dati che si applicano in tutte le aree di lavoro e supporta tutti gli asset creati o usati nella lakehouse, ad esempio tabelle, volumi, funzionalità (archivio funzionalità) e modelli (registro modelli). È anche possibile usare Unity Catalog per acquisire la derivazione dei dati di runtime tra query eseguite in Databricks.
Databricks Data Quality Monitoring consente di monitorare la qualità dei dati di tutte le tabelle nell'account. Rileva le anomalie in tutte le tabelle e fornisce un profilo dati completo per ogni tabella.
Per l'osservabilità, le tabelle di sistema sono un archivio analitico ospitato in Databricks dei dati operativi dell'account. Le tabelle di sistema possono essere usate per un’osservabilità cronologica nell’account.
Motore di intelligence dei dati
Databricks Data Intelligence Platform consente all'intera organizzazione di usare i dati e l'intelligenza artificiale, combinando l'intelligenza artificiale generativa con i vantaggi unificati di una lakehouse per comprendere la semantica univoca dei dati. Consulta le funzionalità di intelligenza artificiale assistita di Databricks.
Genie Code è disponibile nei notebook di Databricks, nell'editor SQL, nell'editor di file e altrove come assistente di intelligenza artificiale compatibile con il contesto per gli utenti.
automazione & orchestrazione
Lakeflow Jobs orchestrano l'elaborazione dei dati, il machine learning e le pipeline di analisi sulla piattaforma di data intelligence di Databricks. Le pipeline dichiarative di Lakeflow Spark consentono di creare pipeline ETL affidabili e gestibili con sintassi dichiarativa. La piattaforma supporta anche CI/CD e MLOps
Casi d'uso di alto livello per la piattaforma di business intelligence dei dati in Azure
Integrazione incorporata da applicazioni SaaS e database con Lakeflow Connect
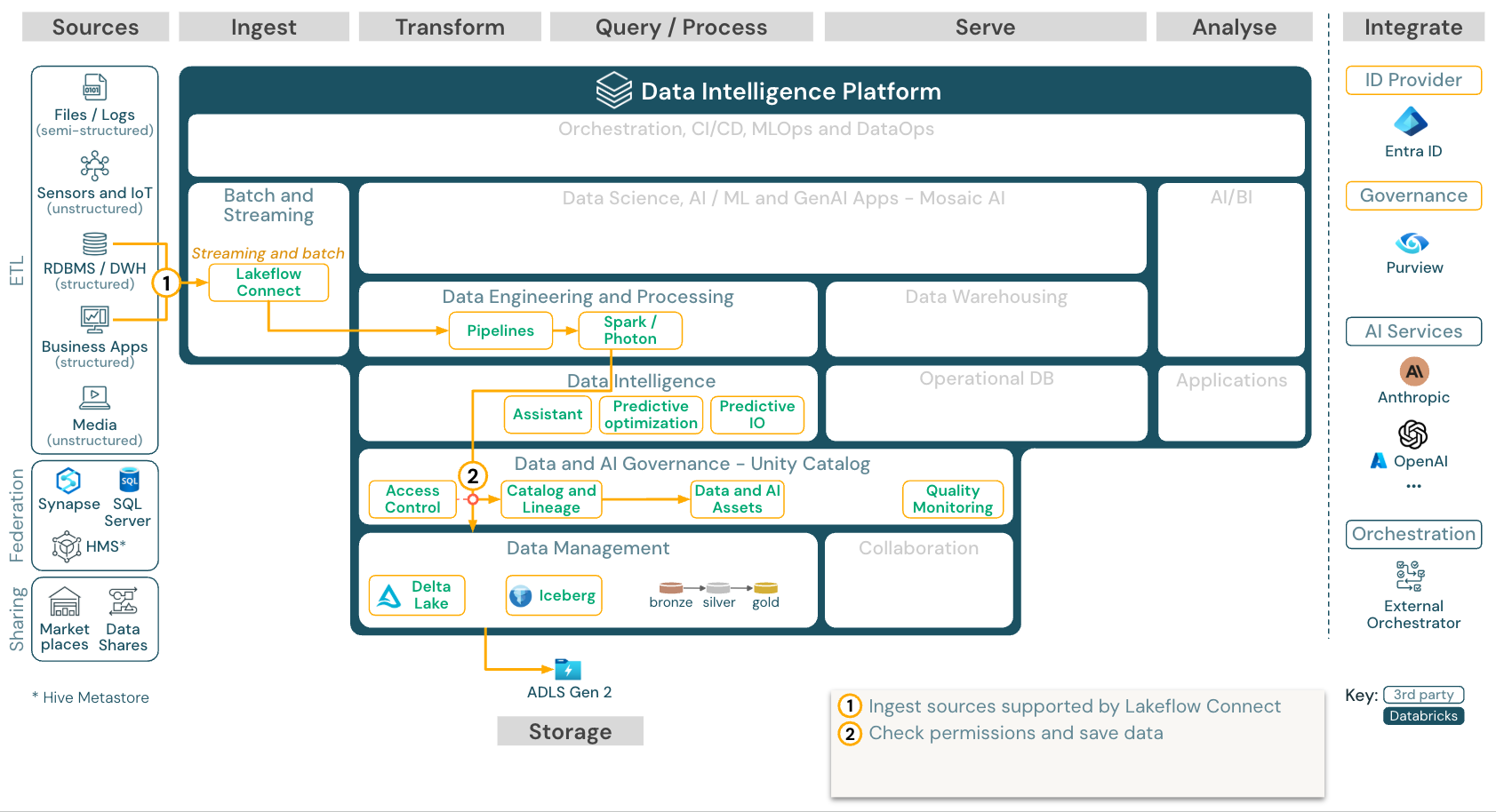
Download: Architettura di riferimento di Lakeflow Connect per Azure Databricks.
Databricks Lakeflow Connect offre connettori predefiniti per l'inserimento da applicazioni e database aziendali. La pipeline di inserimento risultante è governata da Unity Catalog ed è alimentata da calcolo serverless e da Lakeflow Spark Declarative Pipelines.
Lakeflow Connect sfrutta letture incrementali e scritture efficienti per rendere l'inserimento dei dati più veloce, scalabile e più conveniente, mentre i dati rimangono aggiornati per l'utilizzo downstream.
Inserimento batch ed ETL
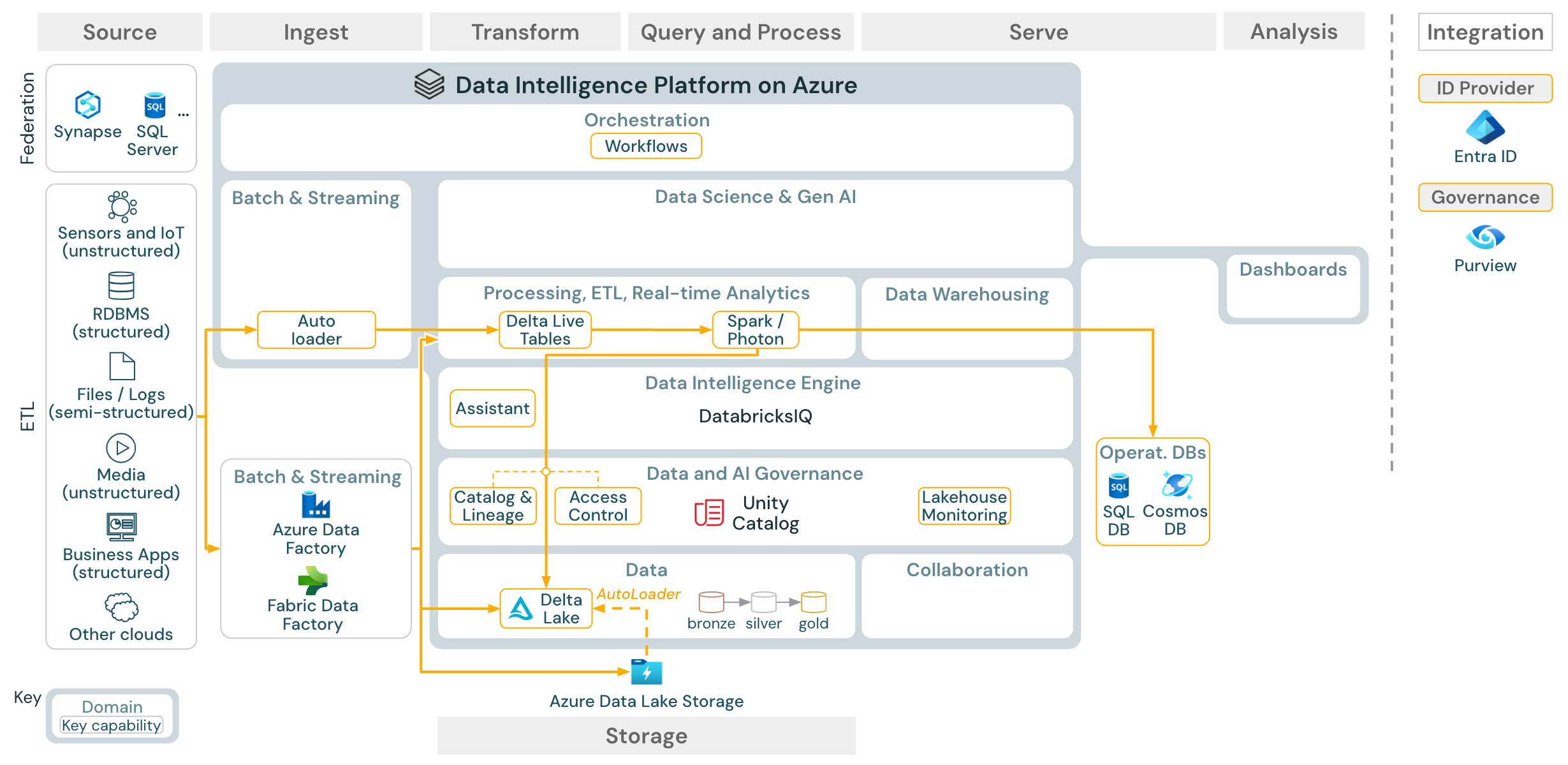
Download: Architettura di riferimento batch ETL per Azure Databricks
Gli strumenti di inserimento usano adattatori specifici dell'origine per leggere i dati dall'origine e quindi archiviarli nell'archiviazione cloud da cui Auto Loader può leggerli, o interagire direttamente con Databricks (ad esempio, con strumenti di inserimento dei partner integrati nel lakehouse di Databricks). Per caricare i dati, il motore ETL di Databricks ed elaborazione esegue le query tramite Pipelines. Orchestrare lavori singoli o multitask usando Lakeflow Jobs e gestirli usando Unity Catalog (controllo di accesso, audit, lineage e così via). Per fornire accesso a tabelle d'oro specifiche per sistemi operativi a bassa latenza, esportare le tabelle in un database operativo, ad esempio un sistema di gestione di basi di dati relazionali (RDBMS) o un archivio chiave-valore, alla fine della pipeline ETL.
Streaming e acquisizione dei dati modificati (CDC)
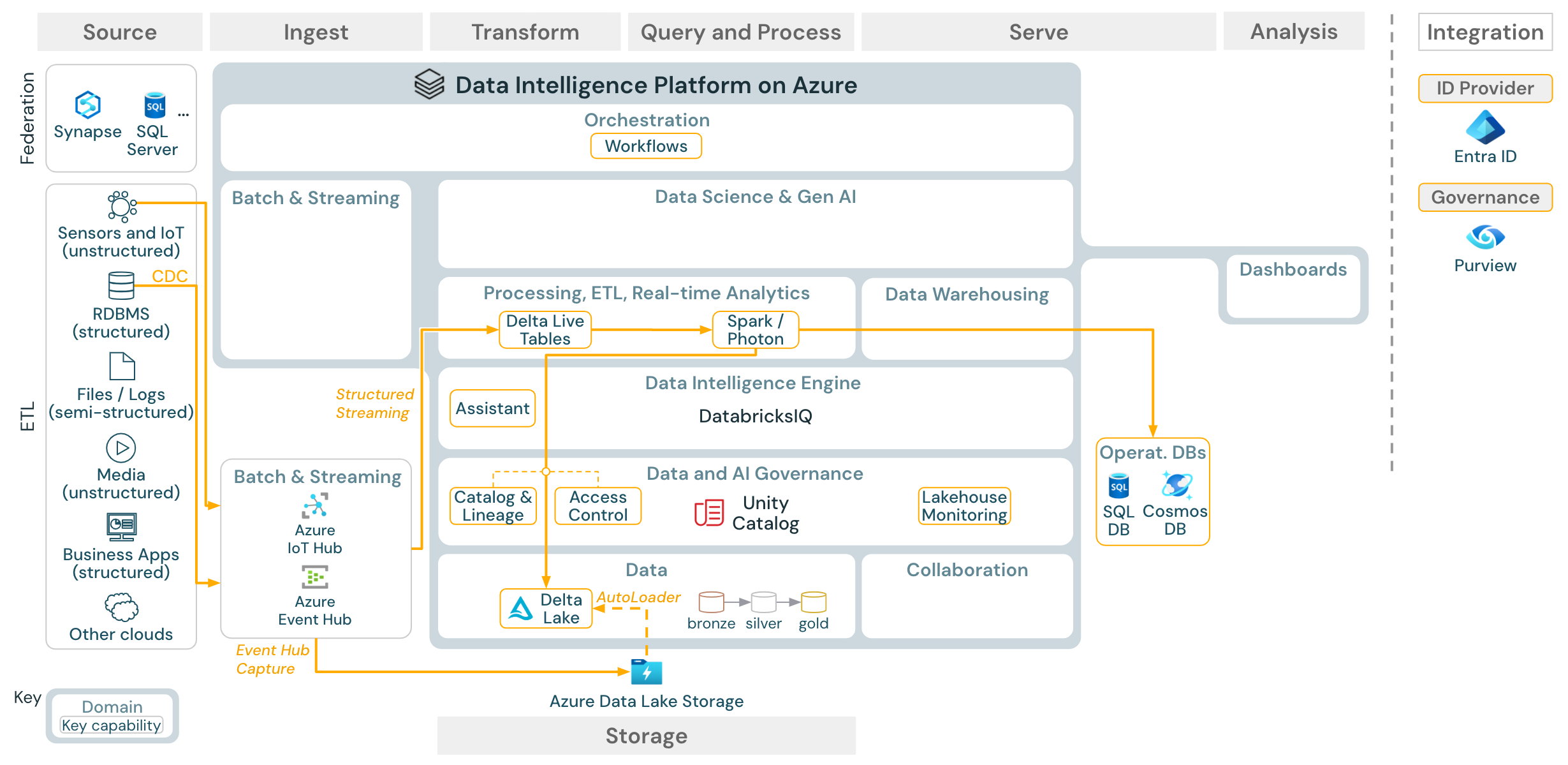
Download: Architettura di streaming strutturato Spark per Azure Databricks
Il motore ETL di Databricks usa Spark Structured Streaming per leggere da code di eventi come Apache Kafka o Hub eventi di Azure. I passaggi downstream seguono l’approccio del caso d'uso di Batch precedente.
La cattura dei dati di cambio (CDC) in tempo reale archivia in genere gli eventi estratti in una coda di eventi. Da qui, il caso d'uso segue il caso d’utilizzo di streaming.
Se CDC viene eseguito in batch, con i record estratti archiviati prima nell'archiviazione cloud, il Databricks Auto Loader può leggerli e il caso d'uso segue Batch ETL.
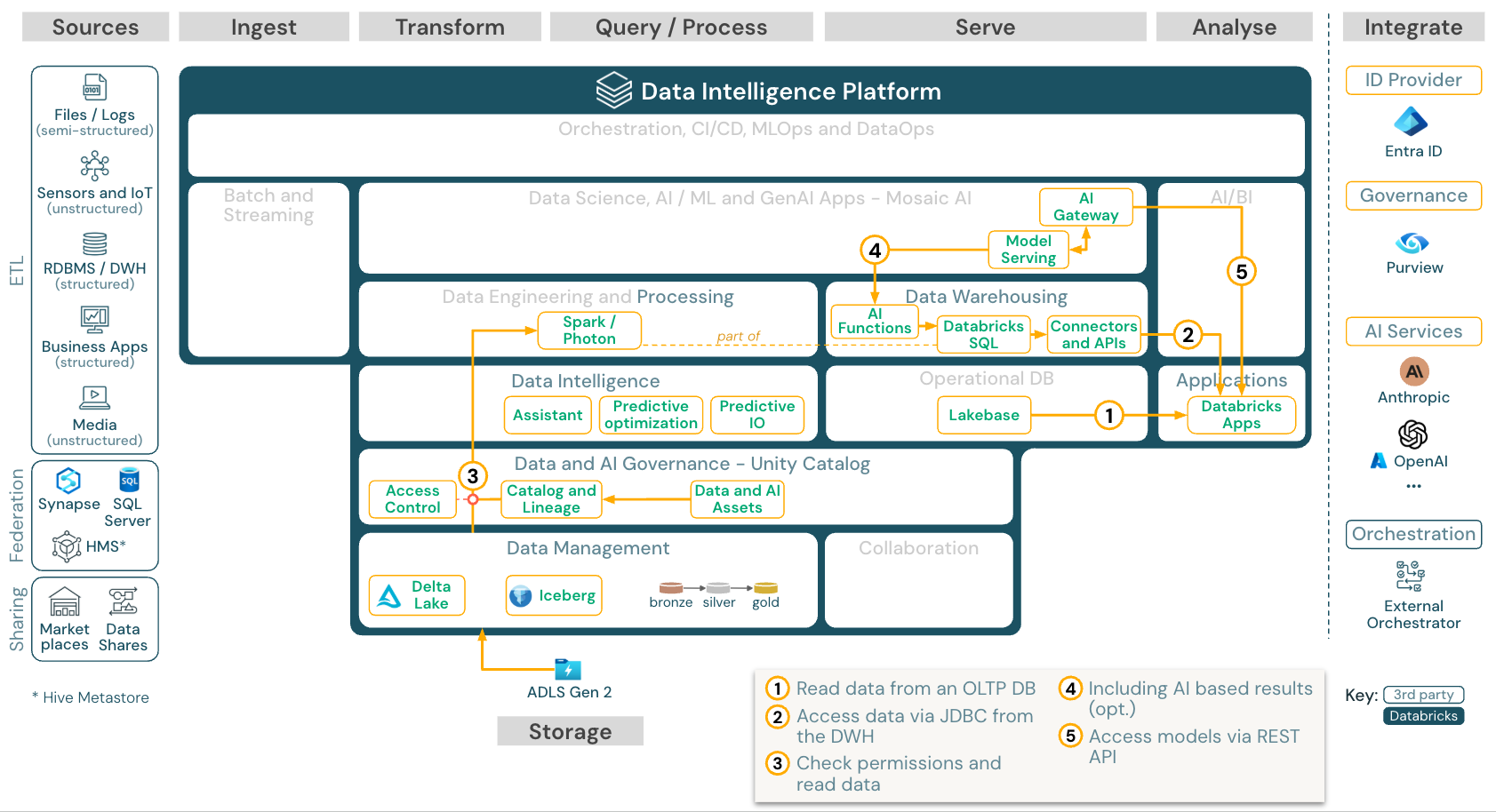
Machine Learning e intelligenza artificiale (tradizionale)
Per l'apprendimento automatico, Databricks Data Intelligence Platform offre l'intelligenza artificiale mosaica, fornita con librerie di machine machine e deep learning all'avanguardia. Offre funzionalità come Feature Store e Registro modelli (integrati nel catalogo unity), funzionalità a basso codice con AutoML e integrazione di MLflow nel ciclo di vita dell'analisi scientifica dei dati.
Il catalogo unity gestisce tutti gli asset correlati all'analisi scientifica dei dati (tabelle, funzionalità e modelli) e i data scientist possono usare i processi Lakeflow per orchestrare i processi.
Per la distribuzione di modelli in modo scalabile e di livello aziendale, usare le funzionalità MLOps per pubblicare i modelli nella gestione dei modelli.
Applicazioni degli agenti AI (IA generativa)
Architettura di riferimento dell'applicazione di intelligenza artificiale generativa per 
Scarica: Architettura di riferimento per l'applicazione di intelligenza artificiale generativa su Azure Databricks
Per la distribuzione di modelli in modo scalabile e di livello aziendale, usare le funzionalità MLOps per pubblicare i modelli nella gestione dei modelli.
Analisi BI e SQL
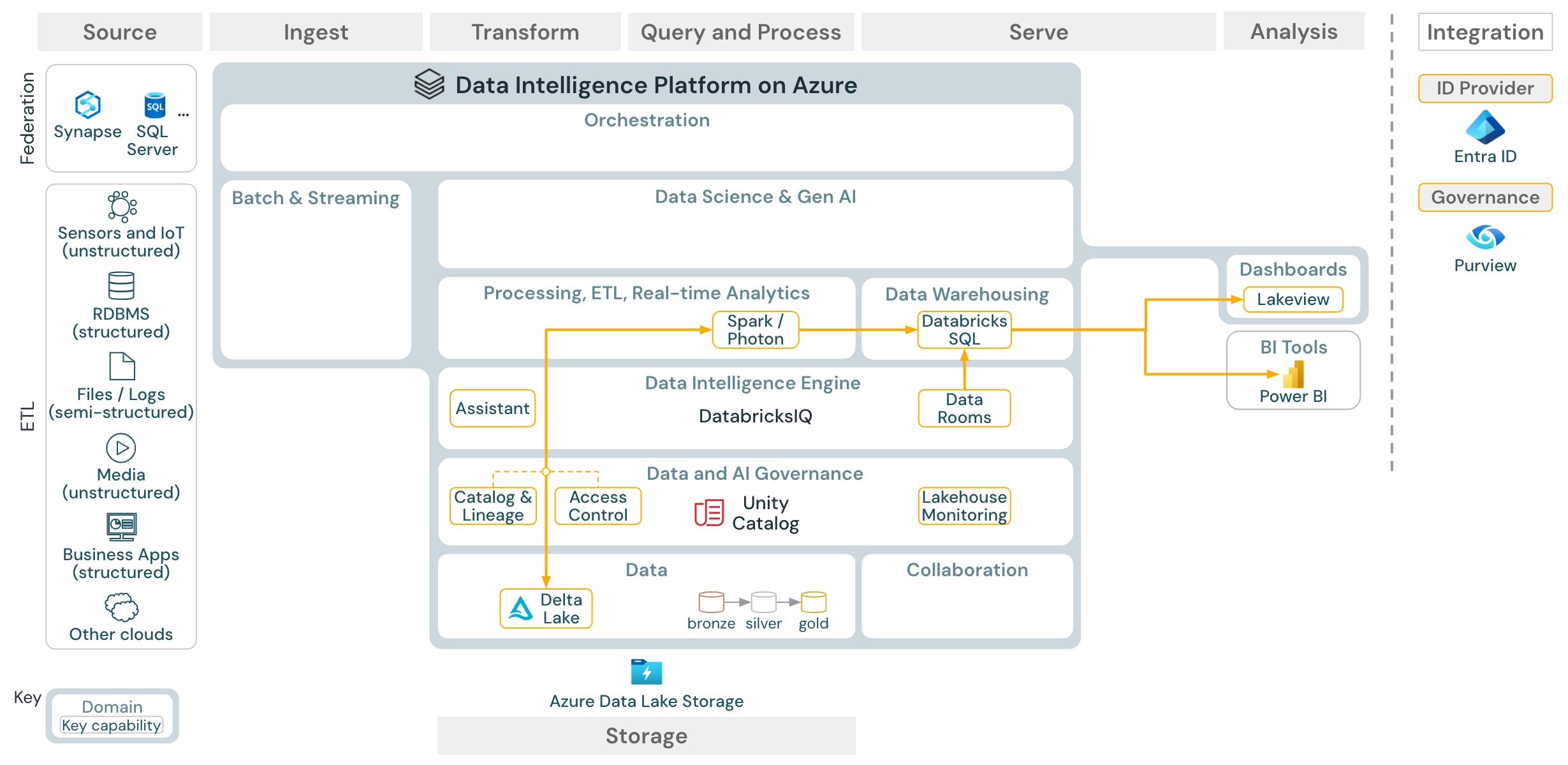
Download: Architettura di riferimento di analisi BI e SQL per Azure Databricks
Per i casi d'uso di business intelligence, gli analisti aziendali possono usare dashboard, l'editor SQL di Databricks o gli strumenti BI, ad esempio Tableau o Power BI. In tutti i casi, il motore è Databricks SQL (serverless o non serverless) e Unity Catalog fornisce l'individuazione dei dati, l'esplorazione e il controllo di accesso.
App aziendali
Download: Applicazioni per Databricks aziendali per Azure
Databricks Apps consente agli sviluppatori di creare e distribuire applicazioni di dati e intelligenza artificiale sicure direttamente nella piattaforma Databricks, eliminando così la necessità di un'infrastruttura separata. Le app sono ospitate nella piattaforma serverless di Databricks e si integrano con i principali servizi della piattaforma. Usare Lakebase se l'app necessita di dati OLTP sincronizzati da Lakehouse.
Federazione lakehouse
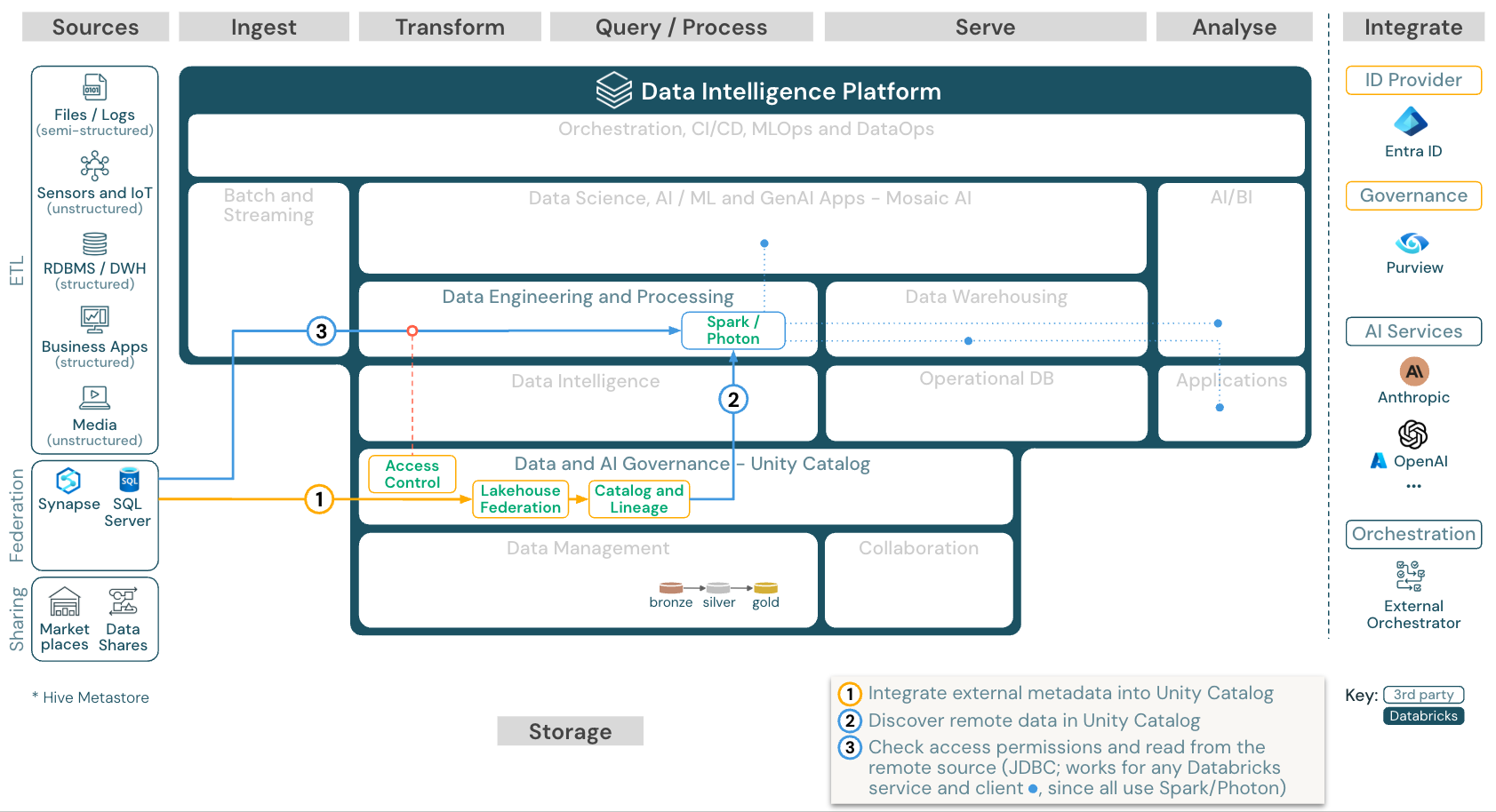
Download: Architettura di riferimento della federazione Lakehouse per Azure Databricks
La federazione di Lakehouse consente l'integrazione di database SQL dati esterni( ad esempio MySQL, Postgres, SQL Server o Azure Synapse) con Databricks.
Tutti i carichi di lavoro (IA, DWH e BI) possono trarre vantaggio da questo senza dover prima trasformare ed elaborare i dati nell’archiviazione a oggetti. Il catalogo di origine esterno viene mappato nel catalogo Unity e il controllo di accesso con granularità fine può essere applicato all’accesso tramite la piattaforma Databricks.
Federazione del catalogo
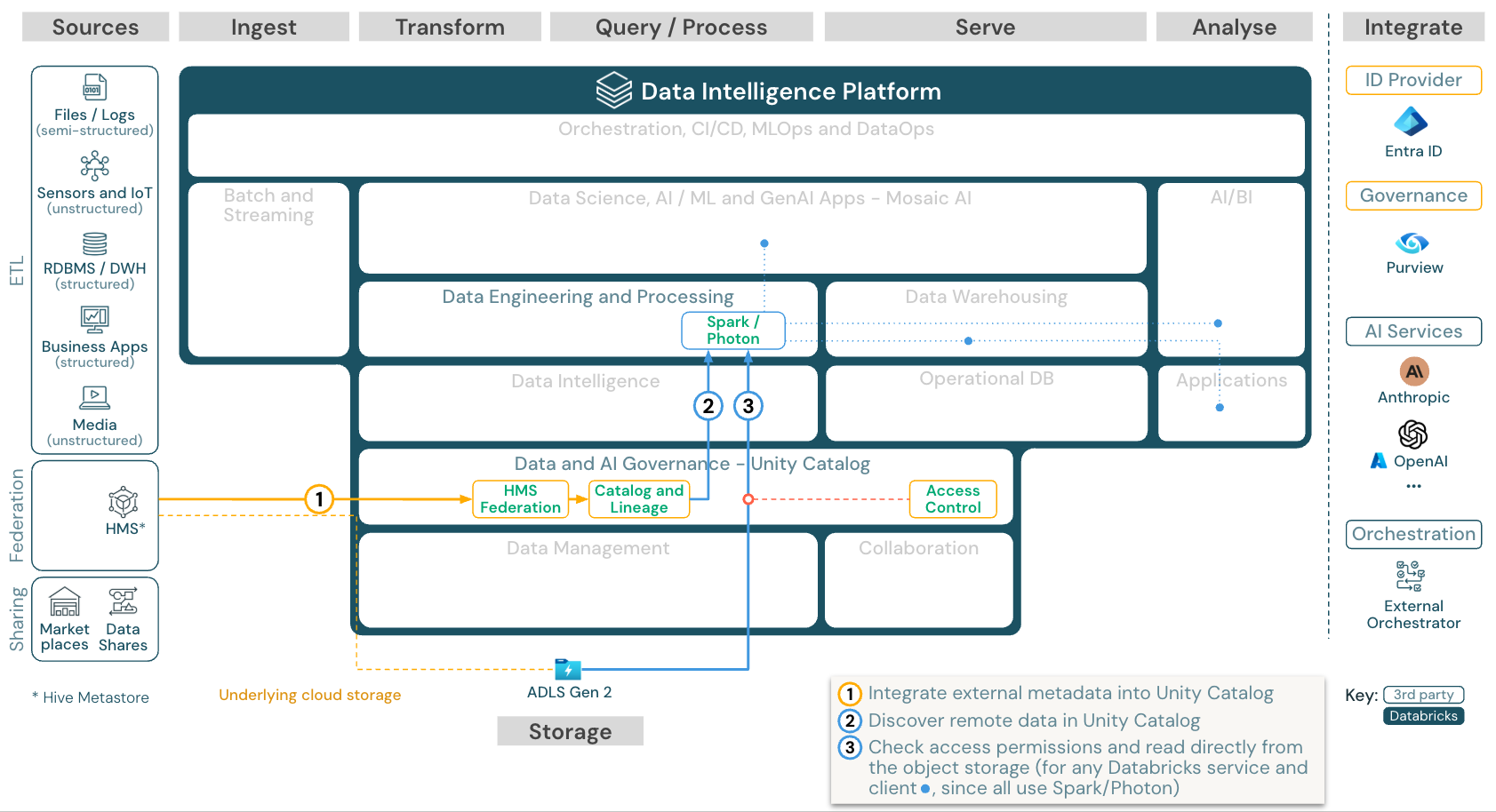
Download: Architettura di riferimento per la federazione del catalogo per Azure Databricks
La federazione del catalogo consente l'integrazione di metastore Hive esterni (ad esempio MySQL, Postgres, SQL Server o Azure Synapse) con Databricks.
Tutti i carichi di lavoro (IA, DWH e BI) possono trarre vantaggio da questo senza dover prima trasformare ed elaborare i dati nell’archiviazione a oggetti. Il catalogo di origine esterno viene aggiunto al catalogo unity in cui il controllo di accesso con granularità fine viene applicato tramite la piattaforma Databricks.
Condividere dati con strumenti di terze parti
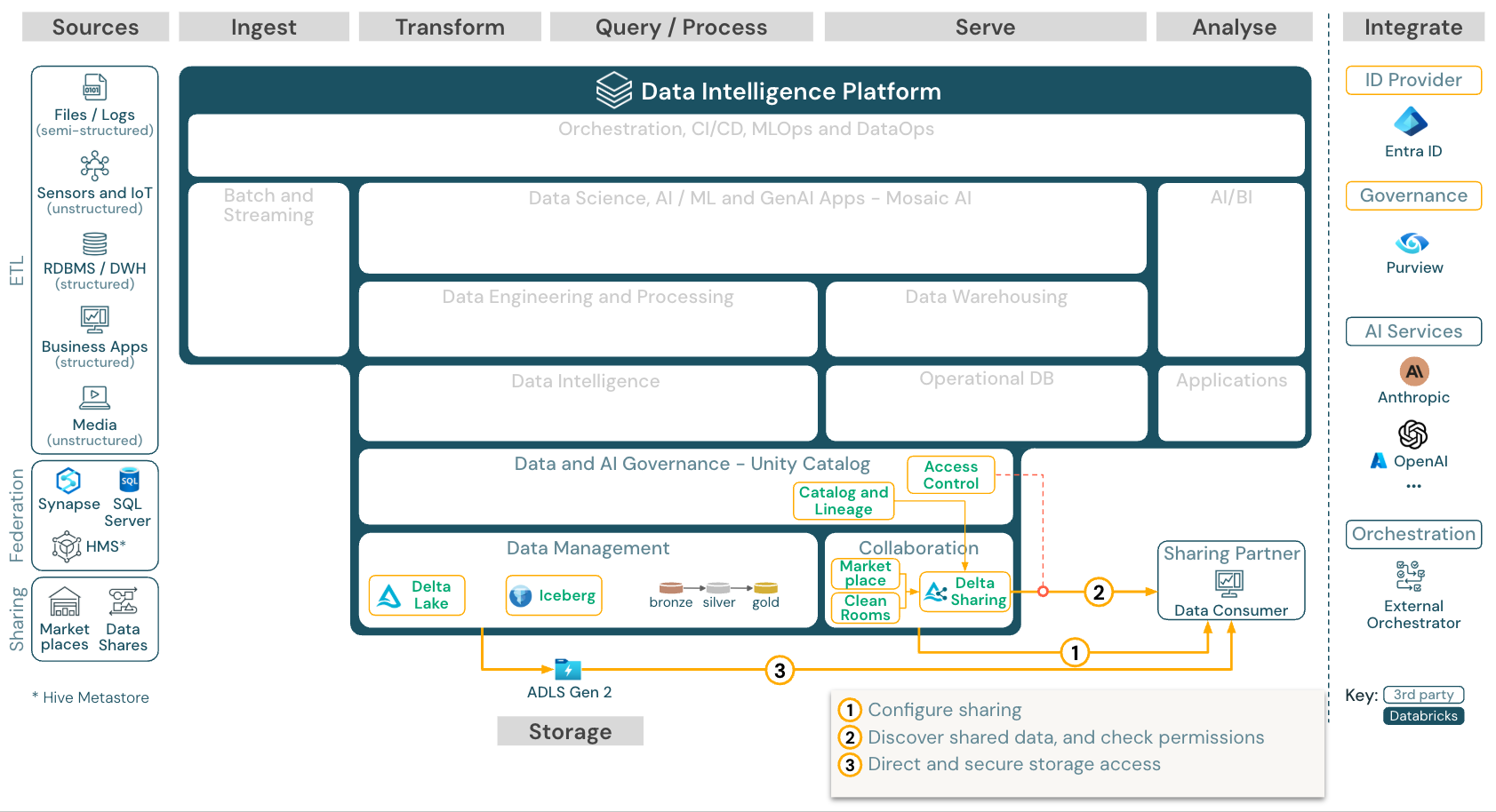
La condivisione dei dati di livello aziendale con terze parti viene fornita dalla condivisione delta. Consente l'accesso diretto ai dati nell'archivio oggetti protetto da Unity Catalog. Questa funzionalità viene usata anche in Databricks Marketplace, un forum aperto per lo scambio di prodotti dati.
Utilizzare dati condivisi da Databricks
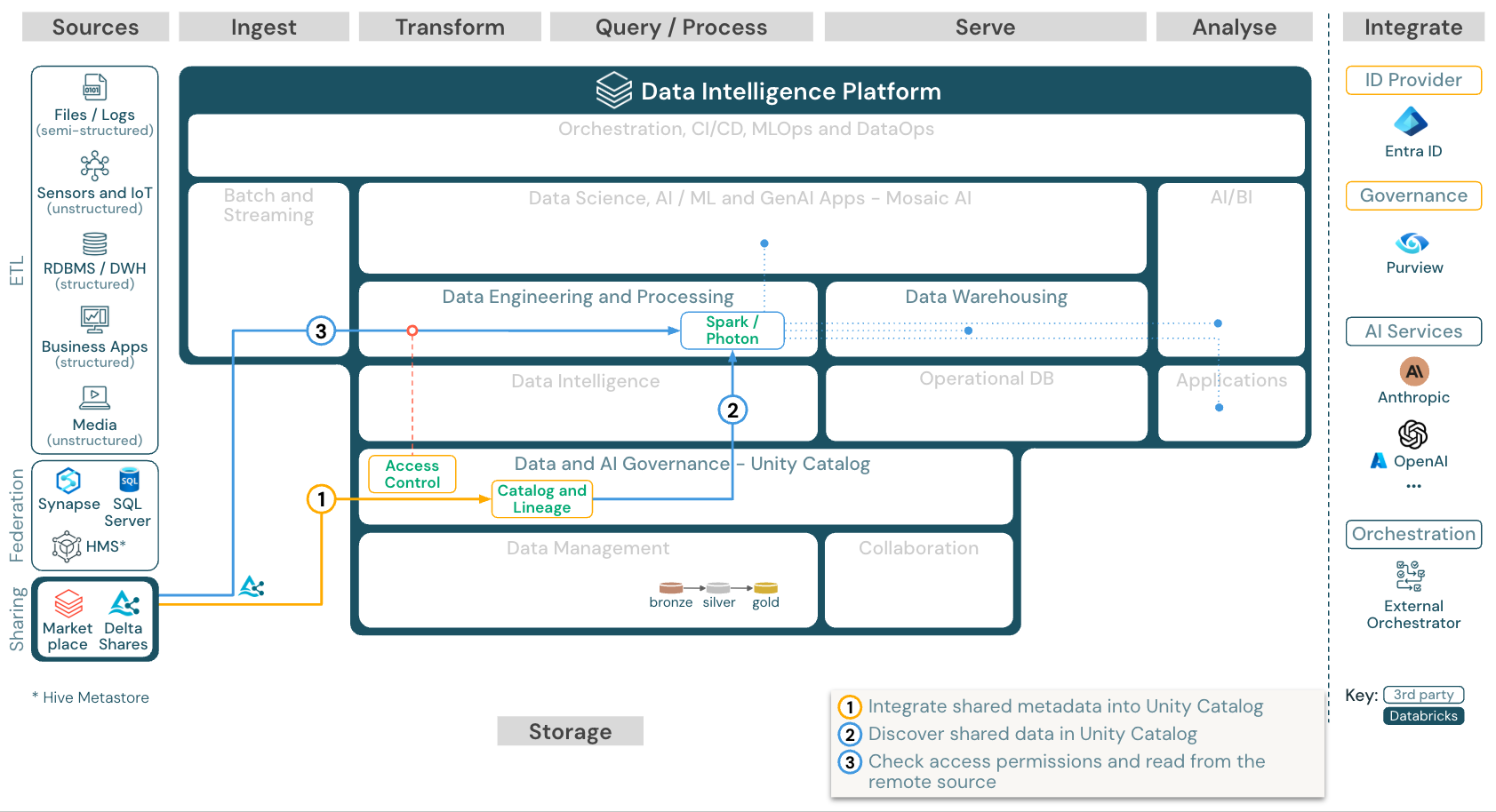
Download: Usare dati condivisi dall'architettura di riferimento di Databricks per Azure Databricks
Il protocollo Delta Sharing Databricks-to-Databricks consente agli utenti di condividere i dati in modo sicuro con qualsiasi utente di Databricks, indipendentemente dall'account o dall'host cloud, purché l'utente abbia accesso a un'area di lavoro abilitata per Unity Catalog.