Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Questo articolo fornisce informazioni sull'uso di Azure Machine Learning SDK v1. SDK v1 è deprecato a partire dal 31 marzo 2025. Il supporto per questo terminerà il 30 giugno 2026. È possibile installare e usare l'SDK v1 fino a tale data. I flussi di lavoro esistenti che usano SDK v1 continueranno a funzionare dopo la data di fine del supporto. Tuttavia, potrebbero essere esposti a rischi per la sicurezza o a modifiche di rilievo nel caso di cambiamenti dell'architettura del prodotto.
È consigliabile passare all'SDK v2 prima del 30 giugno 2026. Per altre informazioni su SDK v2, vedere Che cos'è l'interfaccia della riga di comando di Azure Machine Learning e Python SDK v2? e il Riferimento SDK v2.
Importante
Questo articolo illustra come usare l'interfaccia della riga di comando di Azure Machine Learning (v1) e l'SDK di Azure Machine Learning per Python (v1) per distribuire un modello. Per l'approccio consigliato per v2, vedere Distribuire e assegnare un punteggio a un modello di Machine Learning usando un endpoint online.
Informazioni su come usare Azure Machine Learning per distribuire un modello come servizio Web nel servizio Azure Kubernetes (AKS). Il servizio Azure Kubernetes è una soluzione ideale per le distribuzioni di produzione su vasta scala. Usare il servizio Azure Kubernetes se sono necessarie una o più funzionalità seguenti:
- Tempo di risposta rapido
- Scalabilità automatica del servizio distribuito
- Registrazione
- Raccolta dei dati del modello
- Autenticazione
- Terminazione TLS
- Opzioni di accelerazione hardware, ad esempio GPU e array di gate programmabili sul campo (FPGA)
La distribuzione al servizio Azure Kubernetes viene eseguita in un cluster del servizio Azure Kubernetes connesso all'area di lavoro. Per informazioni sulla connessione di un cluster del servizio Azure Kubernetes all'area di lavoro, vedere Creare e collegare un cluster del servizio Azure Kubernetes.
Importante
È consigliabile eseguire il debug in locale prima della distribuzione nel servizio Web. Per altre informazioni, vedere Risoluzione dei problemi con una distribuzione del modello locale.
Nota
Gli endpoint di Azure Machine Learning (v2) offrono un'esperienza di distribuzione migliore e più semplice. Gli endpoint supportano scenari di inferenza batch e in tempo reale. Gli endpoint forniscono un'unica interfaccia per richiamare e gestire le distribuzioni di modelli tra i tipi di calcolo. Consultare Che cosa sono gli endpoint di Azure Machine Learning?.
Prerequisiti
Un'area di lavoro di Azure Machine Learning. Per ulteriori informazioni, vedere Creare un'area di lavoro di Azure Machine Learning.
Un modello di Machine Learning registrato nell'area di lavoro. Se non si ha un modello registrato, vedere Distribuire modelli di Machine Learning in Azure.
L'estensione dell'interfaccia della riga di comando (v1) di Azure per il servizio Machine Learning, Azure Machine Learning Python SDK, o l'estensione Visual Studio Code di Azure Machine Learning.
Importante
Alcuni comandi dell'interfaccia della riga di comando di Azure in questo articolo usano l'estensione
azure-cli-ml, o v1, per Azure Machine Learning. Il supporto per l'interfaccia della riga di comando v1 è terminato il 30 settembre 2025. Microsoft non fornirà più supporto tecnico o aggiornamenti per questo servizio. I flussi di lavoro esistenti che usano l'interfaccia della riga di comando v1 continueranno a funzionare dopo la data di fine del supporto. Tuttavia, potrebbero essere esposti a rischi per la sicurezza o a modifiche di rilievo nel caso di cambiamenti dell'architettura del prodotto.È consigliabile passare all'estensione
ml, o v2, il prima possibile. Per altre informazioni sull'estensione v2, vedere Estensione dell'interfaccia della riga di comando di Azure Machine Learning e Python SDK v2.I frammenti di codice Python in questo articolo presuppongono che siano impostate le variabili seguenti:
-
ws- Impostare l'area di lavoro. -
model- Impostare il modello registrato. -
inference_config- Impostare la configurazione dell'inferenza per il modello.
Per altre informazioni sull'impostazione di queste variabili, vedere Come e dove distribuire i modelli.
-
I frammenti dell'interfaccia della riga di comando in questo articolo presuppongono che sia già stato creato un documento inferenceconfig.json. Per altre informazioni sulla creazione di questo documento, vedere Distribuire modelli di Machine Learning in Azure.
Un cluster del servizio Azure Kubernetes connesso all'area di lavoro. Per ulteriori informazioni, consultare Creare e collegare un cluster del servizio Azure Kubernetes.
- Se si intende distribuire modelli in nodi GPU o FPGA (o in un prodotto specifico), è necessario creare un cluster con il prodotto specifico. La creazione di un pool di nodi secondario in un cluster esistente e la distribuzione di modelli nel pool di nodi secondario non sono supportate.
Informazioni sui processi di distribuzione
La parola distribuzione viene usata sia in Kubernetes che in Azure Machine Learning.
Distribuzione ha significati diversi in questi due contesti. In Kubernetes, una distribuzione è un'entità concreta, specificata con un file YAML dichiarativo. Una distribuzione Kubernetes ha un ciclo di vita definito e relazioni concrete con altre entità Kubernetes, ad esempio Pods e ReplicaSets. Per informazioni su Kubernetes, vedere la documentazione e i video in Che cos'è Kubernetes?.
In Azure Machine Learning, la distribuzione viene usata nel senso più ampio di rendere disponibili e pulire le risorse del progetto. I passaggi che Azure Machine Learning considera parte della distribuzione sono:
- Compressione dei file nella cartella del progetto, ignorando quelli specificati in .amlignore o .gitignore
- Aumento del cluster di elaborazione (correlato a Kubernetes)
- Compilazione o download del dockerfile nel nodo di calcolo (correlato a Kubernetes)
- Il sistema calcola un hash di:
- Immagine di base
- Procedura Docker personalizzata (vedere Distribuire un modello usando un'immagine di base Docker personalizzata)
- La definizione di conda YAML (vedere Creare e usare ambienti software in Azure Machine Learning)
- Il sistema usa questo hash come chiave in una ricerca del Registro Azure Container (ACR) dell’area di lavoro
- Se non viene trovato, cerca una corrispondenza nel Registro Azure Container globale
- Se non viene trovato, il sistema compila una nuova immagine memorizzata nella cache e inserita nel Registro Azure Container dell'area di lavoro
- Il sistema calcola un hash di:
- Download del file di progetto compresso nell'archiviazione temporanea nel nodo di calcolo
- Decomprimere il file di progetto
- Il nodo di calcolo che esegue
python <entry script> <arguments> - Salvataggio di log, file modello e altri file scritti in ./outputs nell'account di archiviazione associato all'area di lavoro
- Riduzione dell'ambiente di calcolo, inclusa la rimozione dell'archiviazione temporanea (correlata a Kubernetes)
Router di Azure Machine Learning
Il componente front-end (azureml-fe) che indirizza le richieste di inferenza in ingresso ai servizi distribuiti viene ridimensionato automaticamente in base alle esigenze. Il ridimensionamento di azureml-fe si basa sullo scopo e sulle dimensioni del cluster del servizio Azure Kubernetes (numero di nodi). Lo scopo e i nodi del cluster vengono configurati quando si crea o si collega un cluster del servizio Azure Kubernetes. È disponibile un servizio azureml-fe per ogni cluster, che può essere in esecuzione su più pod.
Importante
- Quando si usa un cluster configurato come
dev-test, Self-Scaler è disabilitato. Anche per i cluster FastProd/DenseProd, Self-Scaler è abilitato solo quando i dati di telemetria ne indicano la necessità. - Azure Machine Learning non carica o archivia automaticamente i log da alcun contenitore, inclusi i contenitori di sistema. Per il debug completo, è consigliabile abilitare Informazioni dettagliate sui contenitori per il cluster del servizio Azure Kubernetes. In questo modo è possibile salvare, gestire e condividere i log dei contenitori con il team AML quando necessario. Senza di ciò, AML non può garantire il supporto per i problemi correlati ad azureml-fe.
- Il payload massimo della richiesta è 100 MB.
Azureml-fe aumenta (verticalmente) per usare più core e out (orizzontalmente) per usare più pod. Quando si prende la decisione di aumentare le prestazioni, viene usato il tempo necessario per indirizzare le richieste di inferenza in ingresso. Se questo tempo supera la soglia, si verifica una scalabilità orizzontale. Se il tempo necessario per indirizzare le richieste in ingresso continua a superare la soglia, si verifica un aumento del numero di istanze.
In caso di riduzione e aumento, viene usato l'utilizzo della CPU. Se viene raggiunta la soglia di utilizzo della CPU, come prima cosa il front-end viene ridotto. Se l'utilizzo della CPU scende alla soglia riduzione, si verifica un'operazione di riduzione. L'aumento e la riduzione si verificano solo se sono disponibili risorse cluster sufficienti.
Quando si aumentano o si riducono le prestazioni, i pod azureml-fe vengono riavviati per applicare le modifiche di cpu/memoria. I riavvii non influiscono sulle richieste di inferenza.
Informazioni sui requisiti di connettività per il cluster di inferenza del servizio Azure Kubernetes
Quando Azure Machine Learning crea o collega un cluster del servizio Azure Kubernetes, il cluster del servizio Azure Kubernetes viene distribuito con uno dei due modelli di rete seguenti:
- Rete kubenet: le risorse di rete vengono in genere create e configurate quando viene distribuito il cluster del servizio Azure Kubernetes.
- Rete di Azure Container Networking Interface (CNI): il cluster del servizio Azure Kubernetes è connesso alle configurazioni e alla risorsa di rete virtuale esistenti.
Per la rete Kubenet, la rete viene creata e configurata in modo appropriato per il servizio Azure Machine Learning. Per la rete CNI, è necessario comprendere i requisiti di connettività e garantire la risoluzione DNS e la connettività in uscita per l'inferenza del servizio Azure Kubernetes. Ad esempio, è possibile usare un firewall per bloccare il traffico di rete.
Il diagramma seguente illustra i requisiti di connettività per l'inferenza del servizio Azure Kubernetes. Le frecce nere rappresentano le comunicazioni effettive e le frecce blu rappresentano i nomi di dominio. Potrebbe essere necessario aggiungere voci per questi host al firewall o al server DNS personalizzato.
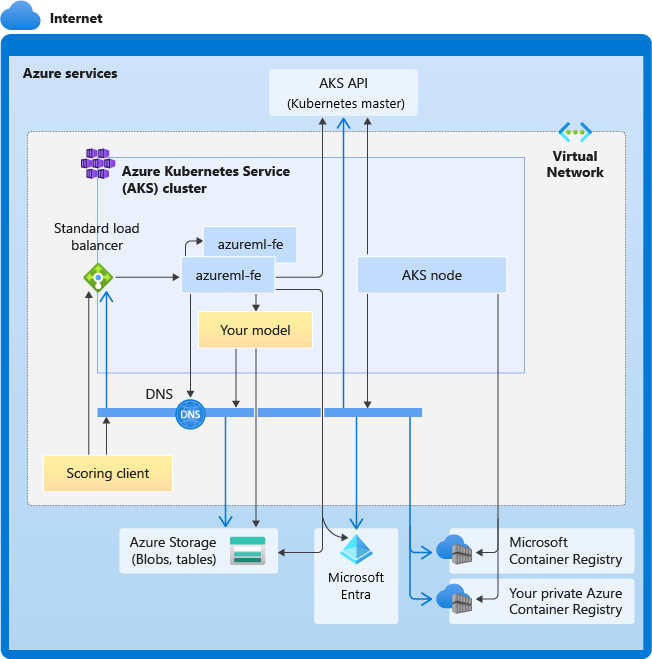
Per i requisiti generali di connettività del servizio Azure Kubernetes, vedere Limitare il traffico di rete con Firewall di Azure nel servizio Azure Kubernetes.
Per accedere ai servizi di Azure Machine Learning dietro un firewall, vedere Configurare il traffico di rete in ingresso e in uscita.
Requisiti generali di risoluzione DNS
La risoluzione DNS all'interno di una rete virtuale esistente è sotto controllo. Ad esempio, un firewall o un server DNS personalizzato. Gli host seguenti devono essere raggiungibili:
| Nome host | Usato da |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Server API del servizio Azure Kubernetes |
mcr.microsoft.com |
Registro Container Microsoft (MCR) |
<ACR name>.azurecr.io |
Registro Azure Container (ACR) dell'utente |
<account>.table.core.windows.net |
Account di archiviazione di Azure (archiviazione tabelle) |
<account>.blob.core.windows.net |
Account di archiviazione di Azure (archiviazione BLOB) |
api.azureml.ms |
Autenticazione di Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Endpoint Kusto per il caricamento di dati di telemetria |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
Nome di dominio dell'endpoint, se generato automaticamente con Azure Machine Learning. Se è stato usato un nome di dominio personalizzato, questa voce non è necessaria. |
Requisiti di connettività in ordine cronologico
Nel processo di creazione o collegamento del servizio Azure Kubernetes, il router di Azure Machine Learning (azureml-fe) viene distribuito nel cluster del servizio Azure Kubernetes. Per distribuire il router di Azure Machine Learning, il nodo servizio Azure Kubernetes deve essere in grado di:
- Risolvere il DNS per il server API del servizio Azure Kubernetes
- Risolvere il DNS per MCR per scaricare le immagini Docker per il router di Azure Machine Learning
- Scaricare immagini da MCR, dove è necessaria la connettività in uscita
Subito dopo la distribuzione, azureml-fe tenta l'avvio e ciò richiede di:
- Risolvere il DNS per il server API del servizio Azure Kubernetes
- Eseguire query sul server API del servizio Azure Kubernetes per individuare altre istanze di se stesso (si tratta di un servizio multi-pod)
- Connettersi ad altre istanze di se stesso
Dopo l'avvio di azureml-fe, per il corretto funzionamento è necessaria la connettività seguente:
- Connettersi ad Archiviazione di Azure per scaricare la configurazione dinamica
- Risolvere il DNS per il server di autenticazione Microsoft Entra api.azureml.ms e comunicare con esso quando il servizio distribuito usa l'autenticazione di Microsoft Entra.
- Eseguire query sul server API del servizio Azure Kubernetes per individuare i modelli distribuiti
- Comunicare con i POD del modello distribuiti
Al momento della distribuzione del modello, per la riuscita del modello di distribuzione il nodo del servizio Azure Kubernetes dovrebbe essere in grado di:
- Risolvere il DNS per il Registro Azure Container del cliente
- Scaricare immagini dal Registro Azure Container del cliente
- Risolvere Il DNS per BLOB di Azure in cui è archiviato il modello
- Scaricare modelli da BLOB di Azure
Dopo la distribuzione del modello e l'avvio del servizio, azureml-fe lo rileva automaticamente usando l'API del servizio Azure Kubernetes ed è pronto per instradare la richiesta. Deve essere in grado di comunicare con i POD del modello.
Nota
Se il modello distribuito richiede connettività (ad esempio l'esecuzione di query su un database esterno o altro servizio REST o il download di un BLOB), è necessario abilitare sia la risoluzione DNS che la comunicazione in uscita per questi servizi.
Distribuire nel servizio Azure Kubernetes
Per distribuire un modello nel servizio Azure Kubernetes, creare una configurazione di distribuzione che descriva le risorse di calcolo necessarie. Ad esempio, il numero di core e la memoria. È necessaria anche una configurazione di inferenza che descriva l'ambiente necessario per ospitare il modello e il servizio Web. Per altre informazioni sulla creazione della configurazione dell'inferenza, vedere Come e dove distribuire i modelli.
Nota
Il numero di modelli da distribuire è limitato a 1.000 modelli per distribuzione (per contenitore).
SI APPLICA A: Azure Machine Learning SDK v1 per Python
Azure Machine Learning SDK v1 per Python
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Per altre informazioni sulle classi, i metodi e i parametri usati in questo esempio, vedere i documenti di riferimento seguenti:
Scalabilità automatica
SI APPLICA A:Azure Machine Learning SDK v1 per Python
Il componente che gestisce la scalabilità automatica per le distribuzioni di modelli di Azure Machine Learning è azureml-fe, ovvero un router di richiesta intelligente. Poiché tutte le richieste di inferenza passano attraverso di esso, questo dispone dei dati necessari per scalare automaticamente i modelli distribuiti.
Importante
Non abilitare Kubernetes Horizontal Pod Autoscaler (HPA) per le distribuzioni di modelli. In questo modo, i due componenti di ridimensionamento automatico competono tra loro. Azureml-fe è stato progettato per ridimensionare automaticamente i modelli distribuiti da Azure Machine Learning, in cui HPA deve indovinare o approssimare l'utilizzo del modello da una metrica generica, ad esempio l'utilizzo della CPU o la configurazione di una metrica personalizzata.
Azureml-fe non ridimensiona il numero di nodi in un cluster del servizio Azure Kubernetes, poiché ciò potrebbe causare un aumento imprevisto dei costi. Invece ridimensiona il numero di repliche per il modello entro i limiti del cluster fisico. Se è necessario ridimensionare il numero di nodi all'interno del cluster, è possibile ridimensionare manualmente il cluster o configurare il dimensionamento automatico del cluster del servizio Azure Kubernetes.
La scalabilità automatica può essere controllata impostando autoscale_target_utilization, autoscale_min_replicas e autoscale_max_replicas per il servizio Web del servizio Azure Kubernetes. L'esempio seguente illustra come abilitare la scalabilità automatica:
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
Le decisioni per l'aumento o la riduzione si basano sull'utilizzo delle repliche dei contenitori correnti. Il numero di repliche occupate (che elaborano una richiesta) diviso per il numero totale di repliche correnti è l'utilizzo corrente. Se questo numero supera autoscale_target_utilization, vengono create più repliche. Se è inferiore, le repliche vengono ridotte. Per impostazione predefinita, l'utilizzo della destinazione è del 70%.
Le decisioni per aggiungere repliche sono veloci e immediate (circa 1 secondo). Le decisioni per rimuovere le repliche sono conservative (circa 1 minuto).
È possibile calcolare le repliche necessarie usando il codice seguente:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Per altre informazioni sull'impostazione di autoscale_target_utilization, autoscale_max_replicas e autoscale_min_replicas, vedere il riferimento al modulo AksWebservice.
Autenticazione dei servizi Web
L'autenticazione basata su chiave è abilitata per impostazione predefinita quando si distribuisce nel servizio Azure Kubernetes. È anche possibile abilitare l'autenticazione basata su token. L'autenticazione basata su token richiede ai client di usare un account Microsoft Entra per richiedere un token di autenticazione, che viene usato per effettuare richieste al servizio distribuito.
Per disabilitare l'autenticazione, impostare il parametro auth_enabled=False durante la creazione della configurazione della distribuzione. L'esempio seguente disabilita l'autenticazione con l'SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
Per informazioni sull'autenticazione da un'applicazione client, vedere Usare un modello di Azure Machine Learning distribuito come servizio Web.
Autenticazione con chiavi
Se è abilitata l'autenticazione con chiave, è possibile usare il metodo get_keys per recuperare una chiave di autenticazione primaria e una secondaria:
primary, secondary = service.get_keys()
print(primary)
Importante
Se è necessario rigenerare una chiave, usare service.regen_key.
Autenticazione con token
Per abilitare l'autenticazione con token, impostare il parametro token_auth_enabled=True durante la creazione o l'aggiornamento di una distribuzione. L'esempio seguente abilita l'autenticazione con token usando l'SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
Se l'autenticazione del token è abilitata, è possibile usare il get_token metodo per recuperare un token JWT e l'ora di scadenza del token:
token, refresh_by = service.get_token()
print(token)
Importante
Al termine della durata del token refresh_by, è necessario richiedere un nuovo token.
Microsoft consiglia di creare l'area di lavoro Azure Machine Learning nella stessa area del cluster del servizio Azure Kubernetes. Per eseguire l'autenticazione con un token, il servizio Web effettua una chiamata all'area in cui viene creata l'area di lavoro Azure Machine Learning. Se tale area non è disponibile, allora non è possibile recuperare un token per il servizio Web, anche se il cluster si trova in un'area diversa dall'area di lavoro. In questo modo, l'autenticazione basata su token non sarà disponibile finché l'area dell'area di lavoro non sarà nuovamente disponibile. Inoltre, maggiore è la distanza tra l'area del cluster e l'area dell'area di lavoro, più tempo sarà necessario per recuperare un token.
Per recuperare un token, è necessario usare l'SDK di Azure Machine Learning o il comando az ml service get-access-token.
Analisi delle vulnerabilità
Microsoft Defender per il cloud offre la gestione unificata della sicurezza e la protezione avanzata dalle minacce nei carichi di lavoro su cloud ibrido. È consigliabile consentire a Microsoft Defender per il cloud di analizzare le risorse e seguire i relativi consigli. Per altre informazioni, vedere Sicurezza dei contenitori in Microsoft Defender per contenitori.
Contenuti correlati
- Usare il controllo degli accessi in base al ruolo di Azure per l'autorizzazione Kubernetes
- Proteggere un ambiente di inferenza di Azure Machine Learning con reti virtuali
- Usare un contenitore personalizzato per distribuire un modello in un endpoint online
- Risoluzione dei problemi relativi alla distribuzione di un modello remoto
- Aggiornare un servizio Web distribuito
- Usare TLS per proteggere un servizio Web tramite Azure Machine Learning
- Utilizzare un modello di Azure Machine Learning distribuito come servizio Web
- Monitorare e raccogliere dati da endpoint del servizio Web di ML
- Raccogliere dati da modelli in produzione