Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In Azure, affidabilità significa resilienza e disponibilità in caso di interruzione o riduzione del servizio. In Azure AI Search, l'affidabilità può essere ottenuta all'interno di un singolo servizio o tramite più servizi di ricerca in aree separate.
Distribuire un singolo servizio di ricerca e aumentare le prestazioni per la disponibilità elevata. È possibile aggiungere più repliche per gestire carichi di lavoro di indicizzazione e query più elevati. Se il servizio di ricerca supporta le zone di disponibilità, il provisioning delle repliche viene eseguito automaticamente in data center fisici diversi per una maggiore resilienza.
Distribuire più servizi di ricerca in aree geografiche diverse. Tutti i carichi di lavoro di ricerca sono completamente contenuti all'interno di un singolo servizio eseguito in una singola area geografica, ma in uno scenario multiservizio sono disponibili opzioni per la sincronizzazione del contenuto in modo che sia lo stesso in tutti i servizi. È anche possibile configurare una soluzione di bilanciamento del carico per ridistribuire le richieste o eseguire il failover in caso di interruzione del servizio.
Per la continuità aziendale e il ripristino da emergenze a livello di area, pianificare una topologia tra aree, costituita da più servizi di ricerca con configurazione e contenuto identici. Lo script personalizzato o il codice fornisce il meccanismo di failover a un servizio di ricerca alternativo se uno diventa improvvisamente non disponibile.
Disponibilità elevata
In Azure AI Search, le repliche sono copie dell'indice. Un servizio di ricerca viene commissionato con almeno una replica e può averne fino a 12. L'aggiunta di repliche consente a Azure AI Search di eseguire riavvii e manutenzione dei computer in una replica, mentre l'esecuzione delle query continua in altre repliche.
Per ogni singolo servizio di ricerca, Microsoft garantisce almeno il 99,9% di disponibilità per le configurazioni che soddisfano questi criteri:
Due repliche per la disponibilità elevata di carichi di lavoro di sola lettura (query)
Tre o più repliche per la disponibilità elevata dei carichi di lavoro di lettura/scrittura (query e indicizzazione)
Il sistema dispone di meccanismi interni per il monitoraggio dell'integrità della replica e dell'integrità della partizione. Se si effettua il provisioning di una combinazione specifica di repliche e partizioni, il sistema garantisce tale livello di capacità per il servizio.
Non viene fornito alcun contratto di servizio per il livello gratuito . Per altre informazioni, vedere contratto di servizio per Ricerca di intelligenza artificiale di Azure.
Supporto della zona di disponibilità
Le zone di disponibilità sono una funzionalità della piattaforma Azure che divide i data center di un'area in gruppi di posizioni fisiche distinti per offrire disponibilità elevata, all'interno della stessa area. In Azure AI Search, le singole repliche sono le unità per l'assegnazione della zona. Un servizio di ricerca viene eseguito all'interno di un'area; le repliche vengono eseguite in data center fisici diversi (o zone) all'interno di tale area.
Le zone di disponibilità vengono usate quando si aggiungono due o più repliche al servizio di ricerca. Ogni replica viene inserita in una zona di disponibilità diversa all'interno dell'area. Se sono presenti più repliche rispetto alle zone disponibili nell'area del servizio di ricerca, le repliche vengono distribuite nel modo più uniforme possibile tra le zone. Non esiste alcuna azione specifica da parte dell'utente, ad eccezione della creazione di un servizio di ricerca in un'area che fornisce zone di disponibilità, e per configurare il servizio per l'uso di più repliche.
Prerequisiti
- Il livello di servizio deve essere Standard o superiore
- L'area del servizio deve trovarsi in un'area con zone disponibili (elencate nella sezione seguente)
- La configurazione deve includere più repliche: due per i carichi di lavoro di query di sola lettura, tre per i carichi di lavoro di lettura/scrittura che includono l'indicizzazione
Aree geografiche supportate
Il supporto per le zone di disponibilità dipende dall'infrastruttura e dall'archiviazione. Attualmente, la zona seguente non dispone di spazio di archiviazione sufficiente e non fornisce una zona di disponibilità per Azure AI Search:
- Giappone occidentale
In caso contrario, le zone di disponibilità per Azure AI Search sono supportate nelle aree seguenti:
| Paese | Data di implementazione |
|---|---|
| Australia orientale | 30 gennaio 2021 o versione successiva |
| Brasile meridionale | 2 maggio 2021 o versione successiva |
| Canada centrale | 30 gennaio 2021 o versione successiva |
| India centrale | 20 gennaio 2022 o versione successiva |
| Stati Uniti centrali | 4 dicembre 2020 o versione successiva |
| Cina settentrionale 3 | 7 settembre 2022 o versione successiva |
| Asia orientale | 13 gennaio 2022 o versione successiva |
| Stati Uniti orientali | 27 gennaio 2021 o versione successiva |
| Stati Uniti orientali 2 | 30 gennaio 2021 o versione successiva |
| Francia centrale | 23 ottobre 2020 o versione successiva |
| Germania centro-occidentale | 3 maggio 2021 o versione successiva |
| Israele centrale | 1 aprile 2024 o versione successiva |
| Italia settentrionale | 1 aprile 2024 o versione successiva |
| Giappone orientale | 30 gennaio 2021 o versione successiva |
| Corea centrale | 20 gennaio 2022 o versione successiva |
| Europa settentrionale | 28 gennaio 2021 o versione successiva |
| Norvegia orientale | 20 gennaio 2022 o versione successiva |
| Qatar centrale | 25 agosto 2022 o versione successiva |
| Sudafrica settentrionale | 7 settembre 2022 o versione successiva |
| Stati Uniti centro-meridionali | 30 aprile 2021 o versione successiva |
| Asia sud-orientale | 31 gennaio 2021 o versione successiva |
| Svezia centrale | 21 gennaio 2022 o versione successiva |
| Svizzera settentrionale | 7 settembre 2022 o versione successiva |
| Emirati Arabi Uniti settentrionali | 9 settembre 2022 o versione successiva |
| Regno Unito meridionale | 30 gennaio 2021 o versione successiva |
| US Gov Virginia | 30 aprile 2021 o versione successiva |
| Europa occidentale | 29 gennaio 2021 o versione successiva |
| Stati Uniti occidentali 2 | 30 gennaio 2021 o versione successiva |
| Stati Uniti occidentali 3 | 2 giugno 2021 o versione successiva |
Nota
Le zone di disponibilità non modificano i termini del contratto di servizio. Sono ancora necessarie tre o più repliche per la disponibilità elevata delle query.
Più servizi in aree geografiche separate
La ridondanza del servizio è necessaria se i requisiti operativi includono:
Requisiti di continuità aziendale e ripristino di emergenza (BCDR). In caso di interruzione, Azure AI Search non fornisce failover istantaneo.
Prestazioni veloci per un'applicazione distribuita a livello globale. Se le richieste di query e indicizzazione provengono da tutto il mondo, gli utenti più vicini al data center host hanno prestazioni più veloci. La creazione di più servizi nelle aree con prossimità vicine a questi utenti può equalizzare le prestazioni per tutti gli utenti.
Se sono necessari due o più servizi di ricerca, la creazione in aree diverse può soddisfare i requisiti dell'applicazione per la continuità e il ripristino e tempi di risposta più rapidi per una base di utenti globale.
Azure AI Search non fornisce un metodo automatizzato per replicare gli indici di ricerca tra aree geografiche, ma esistono alcune tecniche che consentono di semplificare l'implementazione e la gestione di questo processo. Queste tecniche sono descritte nelle prossime sezioni.
L'obiettivo di un set di servizi di ricerca distribuito geograficamente consiste nel disporre di due o più indici disponibili in due o più aree, in cui un utente verrà reindirizzato al servizio di Azure AI Search che offre il tasso di latenza più basso:
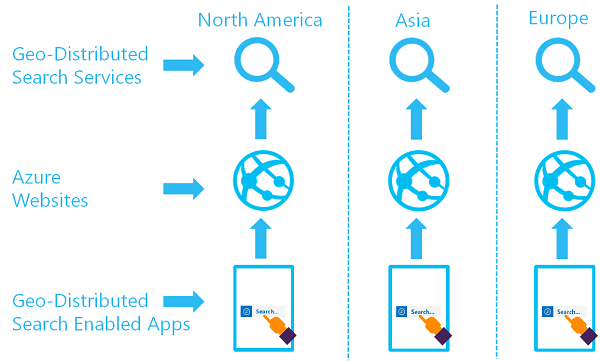
È possibile implementare questa architettura creando più servizi e progettando una strategia per la sincronizzazione dei dati. Facoltativamente, è possibile includere una risorsa come Gestione traffico di Azure per il routing delle richieste.
Suggerimento
Per informazioni sulla distribuzione di più servizi di ricerca in più aree, vedere questo esempio Bicep in GitHub che distribuisce una soluzione di ricerca multi-area completamente configurata. L'esempio offre due opzioni per la sincronizzazione degli indici e il reindirizzamento delle richieste tramite Gestione traffico.
Sincronizzare i dati tra più servizi
Sono disponibili due opzioni per mantenere sincronizzati due o più servizi di ricerca distinti:
- Eseguire il pull degli aggiornamenti del contenuto in un indice di ricerca usando un indicizzatore.
- Eseguire il push del contenuto in un indice usando l'API REST Aggiungi o aggiorna documenti o un'API equivalente di Azure SDK.
Per configurare una delle due opzioni, è consigliabile usare lo script Bicep di esempio nel repository azure-search-multiple-region, modificato nelle aree e nelle strategie di indicizzazione.
Opzione 1: Usare gli indicizzatori per aggiornare il contenuto in più servizi
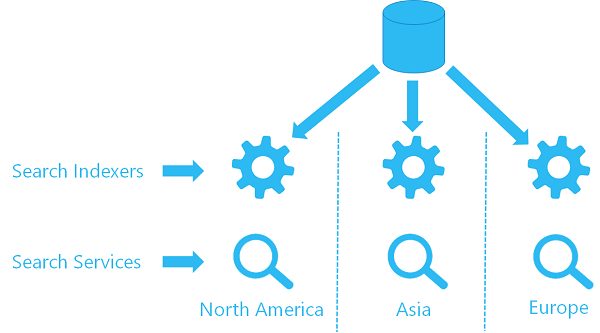
Se si usa già l'indicizzatore in un servizio, è possibile configurare un secondo indicizzatore in un secondo servizio per usare lo stesso oggetto origine dati, eseguendo il pull dei dati dalla stessa posizione. Ogni servizio in ogni area ha un proprio indicizzatore e un indice di destinazione (l'indice di ricerca non è condiviso, il che significa che ogni indice ha una propria copia dei dati), ma ogni indicizzatore fa riferimento alla stessa origine dati.
Ecco una visione generale di come potrebbe presentarsi l'architettura.
Opzione 2: Usare le API REST per il push degli aggiornamenti del contenuto in più servizi
Se si usa l'API Push di Azure AI Search per eseguire il push di contenuto dell'indice di Azure AI Search, è possibile mantenere sincronizzati i vari servizi di ricerca trasferendo le modifiche apportate a tutti i servizi di ricerca ogni volta che è necessario un aggiornamento. Nel codice, assicurarsi di gestire i casi in cui un aggiornamento a un servizio di ricerca ha esito negativo, ma ha esito positivo per altri.
Eseguire il failover o reindirizzare le richieste di query
Se è necessaria la ridondanza a livello di richiesta, Azure offre diverse opzioni di bilanciamento del carico:
- Gestione traffico di Azure, usato per indirizzare le richieste su più siti Web geograficamente localizzati e supportati da più servizi di Azure AI Search.
- Gateway applicazione, usato per bilanciare il carico tra server in un'area a livello di applicazione.
- Frontdoor di Azure, usato per ottimizzare il routing globale del traffico Web e fornire il failover globale.
- Azure Load Balancer, usato per bilanciare il carico tra i servizi in un pool back-end.
Alcuni aspetti da tenere presenti quando si valutano le opzioni di bilanciamento del carico:
La ricerca è un servizio back-end che accetta richieste di query e indicizzazione da un client.
Le richieste dal client a un servizio di ricerca devono essere autenticate. Per l'accesso alle operazioni di ricerca, il chiamante deve disporre di autorizzazioni basate su ruoli o fornire una chiave API nella richiesta.
Gli endpoint di servizio vengono raggiunti tramite una connessione Internet pubblica per impostazione predefinita. Se si configura un endpoint privato per le connessioni client provenienti dall'interno di una rete virtuale, usare il gateway applicazione.
Azure AI Search accetta le richieste indirizzate all'endpoint
<your-search-service-name>.search.windows.net. Se si raggiunge lo stesso endpoint usando un nome DNS diverso nell'intestazione host, ad esempio un CNAME, la richiesta viene rifiutata.
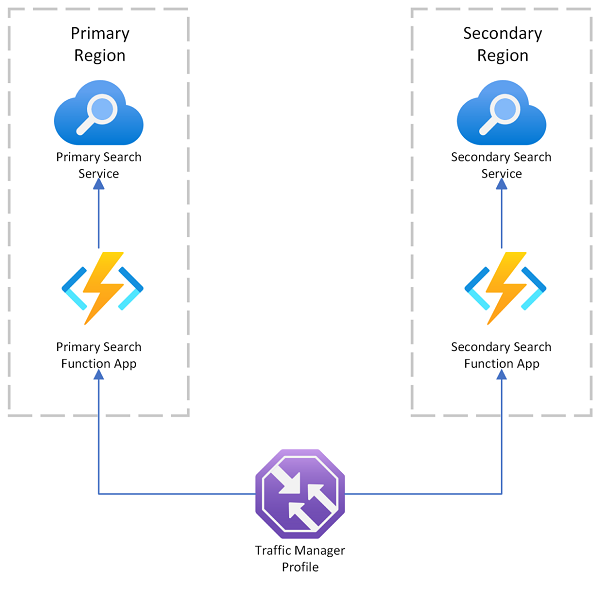
Azure AI Search offre un esempio di distribuzione in più aree che usa Gestione traffico di Azure per il reindirizzamento delle richieste in caso di errore dell'endpoint primario. Questa soluzione è utile quando si esegue il routing a un client abilitato per la ricerca che chiama solo un servizio di ricerca nella stessa area.
Gestione traffico di Azure viene usato principalmente per il routing del traffico di rete tra endpoint diversi in base a metodi di routing specifici, ad esempio priorità, prestazioni o posizione geografica. Agisce a livello DNS per indirizzare le richieste in ingresso all'endpoint appropriato. Se un endpoint di gestione traffico inizia a rifiutare le richieste, il traffico viene instradato a un altro endpoint.
Gestione traffico non fornisce un endpoint per una connessione diretta a Azure AI Search, il che significa che non è possibile inserire un servizio di ricerca direttamente dietro Gestione traffico. Il presupposto è invece che le richieste passano a Gestione traffico, quindi a un client Web abilitato per la ricerca e infine a un servizio di ricerca nel back-end. Il client e il servizio si trovano nella stessa area. Se un servizio di ricerca diventa inattivo, il client di ricerca inizia con esito negativo e Gestione traffico reindirizza al client rimanente.
Nota
Se si usano probe di integrità di Azure Load Balancer in un servizio di ricerca, è necessario usare un probe HTTPS con /ping come percorso.
Residenza dei dati in una distribuzione in più aree
Quando si distribuiscono più servizi di ricerca in varie aree geografiche, il contenuto viene archiviato nell'area scelta per ogni servizio di ricerca.
Ricerca di intelligenza artificiale di Azure non archivia i dati all'esterno dell'area specificata senza l'autorizzazione. L'autorizzazione è implicita quando si usano funzionalità che scrivono in una risorsa di Archiviazione di Azure: cache di arricchimento, sessione di debug, archivio conoscenze. In tutti i casi, l'account di archiviazione è quello fornito, nell'area di propria scelta.
Nota
Se sia l'account di archiviazione che il servizio di ricerca si trovano nella stessa area, il traffico di rete tra la ricerca e l'archiviazione usa un indirizzo IP privato e si verifica sulla rete backbone Microsoft. Poiché vengono usati indirizzi IP privati, non è possibile configurare firewall IP o un endpoint privato per la sicurezza di rete. Usare invece l'eccezione del servizio attendibile come alternativa quando entrambi i servizi si trovano nella stessa area.
Informazioni sulle interruzioni del servizio e sugli eventi irreversibili
Come indicato nel contratto di servizio, Microsoft garantisce un elevato livello di disponibilità per le richieste di query sugli indici quando un'istanza di Azure per intelligenza artificiale servizio di ricerca è configurata con due o più repliche e le richieste di aggiornamento degli indici quando un'istanza di Azure per intelligenza artificiale servizio di ricerca è configurata con tre o più repliche. Tuttavia, non esiste alcun meccanismo incorporato per il ripristino di emergenza. Se un servizio continuo è necessario in caso di errori irreversibili che Microsoft non può controllare, è consigliabile eseguire il provisioning di un servizio secondario in un'area diversa e implementare una strategia di replica geografica per garantire che gli indici siano completamente ridondanti in tutti i servizi.
I clienti che usano gli indicizzatori per compilare e aggiornare gli indici possono gestire il ripristino di emergenza tramite gli indicizzatori specifici per l'area geografica che raccolgono dati dalla stessa origine dati. Due servizi in diverse aree, ognuno dei quali esegue un indicizzatore, possono indicizzare la stessa origine dati per ottenere la ridondanza geografica. Se si esegue l'indicizzazione da origini dati con ridondanza geografica, tenere presente che gli indicizzatori di Azure AI Search possono eseguire solo l'indicizzazione incrementale (unione di aggiornamenti da documenti nuovi, modificati o eliminati) dalle repliche primarie. In un evento di failover, assicurarsi reindirizzare l'indicizzatore ala nuova replica primaria.
Se non si usano gli indicizzatori, l'utente userà il codice dell'applicazione per eseguire il push sugli oggetti e i dati per diversi servizi in parallelo. Per altre informazioni, vedere Sincronizzare i dati tra più servizi.
Backup e ripristino di alternative
Una strategia di continuità aziendale per il livello dati include in genere un passaggio di ripristino dal backup. Poiché Azure AI Search non è una soluzione di archiviazione dei dati primaria, Microsoft non fornisce un meccanismo formale per il backup e il ripristino self-service. Tuttavia, è possibile usare il codice di esempio index-backup-restore in questo repository di esempio .NET di Azure AI Search, per eseguire il backup della definizione e dello snapshot dell'indice in una serie di file JSON e quindi usare questi file per ripristinare l'indice, se necessario. Questo strumento può anche spostare gli indici tra i livelli di servizio.
Altrimenti, il codice dell'applicazione usato per la creazione e la compilazione di un indice è l'opzione di ripristino di fatto se si elimina un indice per errore. Per ricompilare un indice, è necessario eliminarlo (supponendo che sia presente), ricreare l'indice nel servizio e ricaricare recuperando i dati dall'archivio dati primario.
Contenuto correlato
- Per altre informazioni sui piani tariffari e sui limiti dei servizi, vedere Limiti del servizio.
- Per altre informazioni sulle combinazioni di partizione e replica, vedere Pianificazione della capacità.
- Per altre indicazioni sulla configurazione, vedere Case Study: usare Ricerca cognitiva per supportare scenari di intelligenza artificiale complessi.