Linee guida per la modellazione di Power BI per Power Platform
Microsoft Dataverse è la piattaforma dati standard per molti prodotti di applicazioni aziendali Microsoft, tra cui Dynamics 365 Customer Engagement e app canvas di Power Apps e Dynamics 365 Customer Voice (in precedenza Microsoft Forms Pro), approvazioni di Power Automate, portali di Power Apps e altri.
Questo articolo fornisce indicazioni su come creare un modello di dati di Power BI che si connette a Dataverse. Descrive le differenze tra uno schema di Dataverse e uno schema di Power BI ottimizzato e fornisce indicazioni per espandere la visibilità dei dati delle applicazioni aziendali in Power BI.
Grazie alla sua facilità di configurazione, alla distribuzione rapida e all'adozione diffusa, Dataverse archivia e gestisce un volume crescente di dati negli ambienti delle organizzazioni. Ciò significa che è ancora necessario, e possibile, integrare l'analisi con tali processi. Le opportunità includono:
- Creare report su tutti i dati di Dataverse che si spostano oltre i vincoli dei grafici predefiniti.
- Fornire l'accesso facilitato a report pertinenti e filtrati contestualmente all'interno di un record specifico.
- Migliorare il valore dei dati di Dataverse mediante l'integrazione con dati esterni.
- Sfruttare i vantaggi dell'intelligenza artificiale (IA) incorporata di Power BI senza dover scrivere un codice complesso.
- Aumentare l'adozione delle soluzioni Power Platform aumentandone l'utilità e il valore.
- Offrire il valore dei dati nell'app ai decision maker aziendali.
Connettere Power BI a Dataverse
La connessione di Power BI a Dataverse comporta la creazione di un modello di dati di Power BI. È possibile scegliere tra tre metodi per creare un modello di Power BI.
- Importare dati di Dataverse usando il connettore Dataverse: questo metodo memorizza nella cache i dati di Dataverse in un modello di Power BI. Offre velocità di esecuzione elevate grazie all'esecuzione di query in memoria. Offre inoltre flessibilità di progettazione ai modellatori, consentendo loro di integrare i dati da altre origini. A causa di questi vincoli, l'importazione dei dati è la modalità predefinita quando si crea un modello in Power BI Desktop.
- Importare dati di Dataverse usando collegamento ad Azure Synapse: questo metodo è una variante del metodo di importazione, perché memorizza nella cache anche i dati nel modello di Power BI, ma lo fa connettendosi a Azure Synapse Analytics. Usando Collegamento ad Azure Synapse per Dataverse, le tabelle di Dataverse vengono replicate in modo continuo in Azure Synapse o Azure Data Lake Storage (ADLS) Gen2. Questo approccio viene usato per segnalare centinaia di migliaia o persino milioni di record negli ambienti di Dataverse.
- Creare una connessione DirectQuery usando il connettore Dataverse: questo metodo è un'alternativa all'importazione di dati. Un modello DirectQuery è costituito solo dai metadati che definiscono la struttura del modello. Quando un utente apre un report, Power BI invia query native a Dataverse per recuperare i dati. Prendere in considerazione la creazione di un modello DirectQuery quando i report devono mostrare dati di Dataverse near real-time o quando Dataverse deve applicare la sicurezza basata sui ruoli in modo che gli utenti possano visualizzare solo i dati per cui hanno privilegi di accesso.
Importante
Anche se un modello DirectQuery può essere una buona alternativa quando è necessario creare report near real-time o applicare la sicurezza di Dataverse in un report, può comportare un rallentamento delle prestazioni per tale report.
Altre informazioni sulle considerazioni per DirectQuery sono disponibili più avanti in questo articolo.
Per determinare il metodo corretto per il modello di Power BI, è consigliabile prendere in considerazione:
- Prestazioni delle query
- Volume dei dati
- Latenza dei dati
- Sicurezza basata su ruoli
- Complessità della configurazione
Suggerimento
Per una discussione dettagliata sui framework del modello (importazione, DirectQuery o composito), sui vantaggi e sulle limitazioni e sulle funzionalità per ottimizzare i modelli di dati di Power BI, vedere Scegliere un framework del modello Power BI.
Prestazioni delle query
Le query inviate ai modelli di importazione sono più veloci rispetto alle query native inviate alle origini dati DirectQuery. Questo perché i dati importati vengono memorizzati nella cache e sono ottimizzati per query analitiche (operazioni di filtro, gruppo e riepilogo).
Viceversa, i modelli DirectQuery recuperano solo i dati dall'origine dopo che l'utente apre un report, con conseguente ritardo in termini di secondi durante il rendering del report. Inoltre, le interazioni dell'utente nel report richiedono a Power BI di rieseguire una query sull'origine, riducendo ulteriormente la velocità di risposta.
Volume dei dati
Quando si sviluppa un modello di importazione, è necessario cercare di ridurre al minimo i dati caricati nel modello. Questo è particolarmente vero per i modelli di grandi dimensioni o per i modelli per i quali si prevede un notevole aumento di dimensioni nel tempo. Per altre informazioni, vedere Tecniche di riduzione dei dati per i modelli di importazione.
Una connessione DirectQuery a Dataverse è una scelta ottimale quando il risultato della query del report non è di grandi dimensioni. Un risultato di query di grandi dimensioni contiene più di 20.000 righe nelle tabelle di origine del report oppure il risultato restituito al report dopo l'applicazione dei filtri è superiore a 20.000 righe. In questo caso, è possibile creare un report di Power BI usando il connettore Dataverse.
Nota
Il limite di 20.000 righe non è un limite rigido. Tuttavia, ogni query dell'origine dati deve restituire un risultato entro 10 minuti. Più avanti in questo articolo si apprenderà come usare tali limitazioni e altre considerazioni sulla progettazione DirectQuery di Dataverse.
È possibile migliorare le prestazioni dei modelli semantici più grandi usando il connettore Dataverse per importare i dati nel modello di dati.
Anche modelli semantici più grandi, con diverse centinaia di migliaia o persino milioni di righe, possono trarre vantaggio dall'uso di Collegamento ad Azure Synapse per Dataverse. Questo approccio configura una pipeline gestita in corso che copia i dati di Dataverse in ADLS Gen2 come file CSV o Parquet. Power BI può quindi eseguire query su un pool SQL serverless di Azure Synapse per caricare un modello di importazione.
Latenza dei dati
Quando i dati di Dataverse cambiano rapidamente e gli utenti del report devono visualizzare dati aggiornati, un modello DirectQuery può offrire risultati di query near real-time.
Suggerimento
È possibile creare un report di Power BI che usa l'aggiornamento automatico della pagina per visualizzare gli aggiornamenti in tempo reale, ma solo quando il report si connette a un modello DirectQuery.
I modelli di importazione dei dati devono completare un aggiornamento dei dati per consentire la creazione di report sulle modifiche recenti ai dati. Tenere presente che esistono limitazioni relative al numero di operazioni di aggiornamento dati pianificate ogni giorno. È possibile pianificare fino a otto aggiornamenti al giorno in una capacità condivisa. In una capacità Premium o capacità di Microsoft Fabric, è possibile pianificare fino a 48 aggiornamenti al giorno, che possono ottenere una frequenza di aggiornamento di 15 minuti.
Importante
A volte questo articolo si riferisce a Power BI Premium o alle relative sottoscrizioni di capacità (SKU P). Tenere presente che Microsoft sta attualmente consolidando le opzioni di acquisto e ritirando gli SKU di Power BI Premium per capacità. I clienti nuovi ed esistenti devono invece prendere in considerazione l'acquisto di sottoscrizioni con capacità Fabric (SKU F).
Per altre informazioni, vedere Aggiornamento importante disponibile per le licenze Power BI Premium e Domande frequenti su Power BI Premium.
È anche possibile usare l'aggiornamento incrementale per ottenere aggiornamenti più rapidi e prestazioni near real-time (disponibile solo con Premium o Fabric).
Sicurezza basata su ruoli
Quando è necessario applicare la sicurezza basata sui ruoli, questa può influenzare direttamente la scelta del framework del modello di Power BI.
Dataverse può applicare una sicurezza basata sui ruoli complessa per controllare l'accesso di record specifici a utenti specifici. Ad esempio, un venditore potrebbe essere autorizzato a visualizzare solo le proprie opportunità di vendita, mentre il responsabile vendite può visualizzare tutte le opportunità di vendita per tutti i venditori. È possibile personalizzare il livello di complessità in base alle esigenze dell'organizzazione.
Un modello DirectQuery basato su Dataverse può connettersi usando il contesto di sicurezza dell'utente del report. In questo modo, l'utente del report visualizzerà solo i dati a cui può accedere. Questo approccio può semplificare la progettazione del report, fornendo prestazioni accettabili.
Per migliorare le prestazioni, è possibile creare invece un modello di importazione che si connette a Dataverse. In questo caso, è possibile aggiungere la sicurezza a livello di riga al modello, se necessario.
Nota
Potrebbe essere difficile replicare una sicurezza basata su ruoli di Dataverse come Sicurezza a livello di riga di Power BI, soprattutto quando Dataverse applica autorizzazioni complesse. Inoltre, potrebbe essere necessaria una gestione continuativa per mantenere sincronizzate le autorizzazioni di Power BI con le autorizzazioni di Dataverse.
Per altre informazioni sulla Sicurezza a livello di riga di Power BI, vedere Linee guida per la sicurezza a livello di riga in Power BI Desktop.
Complessità della configurazione
L'uso del connettore Dataverse in Power BI, per i modelli di importazione o DirectQuery, è semplice e non richiede software speciali o autorizzazioni con privilegi elevati di Dataverse. Questo è un vantaggio per le organizzazioni o i reparti che avviano le attività iniziali.
L'opzione Collegamento ad Azure Synapse richiede l'accesso di amministratore di sistema a Dataverse e ad alcune autorizzazioni di Azure. Queste autorizzazioni di Azure sono necessarie per configurare l'account di archiviazione e una workspace Synapse.
Procedure consigliate
Questa sezione descrive i modelli di progettazione (e gli anti-pattern) da considerare quando si crea un modello di Power BI che si connette a Dataverse. Solo alcuni di questi modelli sono unici per Dataverse, ma tendono a essere solitamente complessi per i creatori di Dataverse quando creano report di Power BI.
Concentrarsi su un caso d'uso specifico
Invece di provare a risolvere tutti i problemi, concentrarsi sul caso d'uso specifico.
Questa raccomandazione è probabilmente l'anti-pattern più comune e spesso più complesso da evitare. Il tentativo di creare un singolo modello che soddisfi tutte le esigenze di creazione di report self-service è complesso. La realtà è che i modelli di successo sono creati per rispondere a domande su un insieme centrale di fatti su un singolo argomento di base. Anche se inizialmente questo potrebbe sembrare una limitazione per il modello, effettivamente consente di ottimizzare e perfezionare il modello per rispondere alle domande all'interno di tale argomento.
Per assicurarsi di avere una chiara comprensione dello scopo del modello, considerare i seguenti aspetti:
- Quale area dell'argomento supporta questo modello?
- Chi sono i destinatari dei report?
- A quali domande stanno tentando di rispondere i report?
- Qual è il modello semantico minimo praticabile?
Evitare di combinare più aree di un argomento in un singolo modello solo perché l'utente del report ha domande su più aree dell'argomento che vuole affrontare con un solo report. Suddividendo il report in più report, ognuno dei quali incentrato su un argomento diverso (o tabella dei fatti), è possibile produrre modelli molto più efficienti, scalabili e gestibili.
Progettare uno schema a stella
Gli sviluppatori e gli amministratori di Dataverse che hanno familiarità con gli schemi di Dataverse potrebbero essere tentati di riprodurre lo stesso schema in Power BI. Questo approccio è un anti-pattern ed è probabilmente il più difficile da superare perché sembra giusto mantenere la coerenza.
Dataverse, come modello relazionale, è adatto a questo scopo. Tuttavia, non è progettato come modello analitico ottimizzato per i report analitici. Il modello più diffuso per i dati di analisi di modellazione è una progettazione con schema star. Lo schema star è un approccio maturo alla modellazione, ampiamente adottato dai data warehouse relazionali. che richiede che le tabelle del modello vengano classificate come dimensione o fatto. I report possono filtrare o raggruppare utilizzando le colonne della tabella delle dimensioni e e riassumere le colonne della tabella dei fatti.
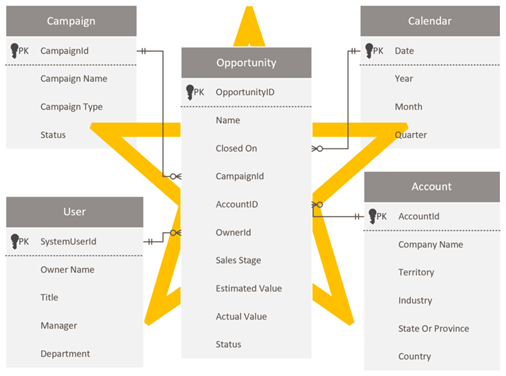
Per altre informazioni, vedere Informazioni su uno schema star e sull'importanza di questo schema per Power BI.
Ottimizzare le query di Power Query
Il motore mashup di Power Query cerca di ottenere la riduzione della query quando possibile per motivi di efficienza. Una query che consente di ottenere la riduzione delega l'elaborazione delle query al sistema di origine.
Il sistema di origine, in questo caso Dataverse, deve solo distribuire i risultati filtrati o riepilogati in Power BI. Una query ridotta è spesso molto più veloce e più efficiente di una query non ridotta.
Per altre informazioni su come ottenere la riduzione della query, vedere Riduzione della query di Power Query.
Nota
L'ottimizzazione di Power Query è un argomento ampio. Per comprendere meglio le operazioni di Power Query in fase di creazione e aggiornamento del modello in Power BI Desktop, vedere Diagnostica query.
Ridurre al minimo il numero di colonne di query
Per impostazione predefinita, quando si usa Power Query per caricare una tabella di Dataverse, vengono recuperate tutte le righe e tutte le colonne. Quando si esegue una query su una tabella dell'utente di sistema, ad esempio, questa può contenere più di 1.000 colonne. Le colonne nei metadati includono relazioni con altre entità e ricerche nelle etichette di opzione, quindi il numero totale di colonne aumenta con la complessità della tabella di Dataverse.
Il tentativo di recuperare i dati da tutte le colonne è un anti-pattern. Spesso comporta operazioni di aggiornamento dei dati estese e causerà l'esito negativo della query quando il tempo necessario per restituire i dati supera i 10 minuti.
È consigliabile recuperare solo le colonne richieste dai report. Spesso è consigliabile rivalutare ed effettuare il refactoring delle query al termine dello sviluppo del report, consentendo di identificare e rimuovere colonne inutilizzate. Per altre informazioni, vedere Tecniche di riduzione dei dati per i modelli di importazione (Rimuovere le colonne non necessarie).
Assicurarsi inoltre di introdurre subito il passaggio Rimuovi colonne di Power Query in modo che si riduca all'origine. In questo modo, Power Query può evitare il lavoro non necessario di estrarre i dati di origine solo per eliminarli in un secondo momento (in un passaggio non ridotto).
Quando si dispone di una tabella che contiene molte colonne, potrebbe risultare poco pratico usare il generatore di query interattivo di Power Query. In questo caso, è possibile iniziare creando una query vuota. È quindi possibile usare l'Editor avanzato per incollare una query minima che crea un punto di partenza.
Si consideri la query seguente che recupera i dati da solamente due colonne della tabella account.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Scrivere query native
Quando si hanno requisiti di trasformazione specifici, è possibile ottenere prestazioni migliori usando una query nativa scritta in Dataverse SQL, ovvero un subset di Transact-SQL. È possibile scrivere una query nativa per:
- Ridurre il numero di righe (usando una clausola
WHERE). - Aggregare i dati (usando le clausole
GROUP BYeHAVING). - Creare un join di tabelle in modo specifico (usando la sintassi
JOINoAPPLY). - Usare le funzioni SQL supportate.
Per altre informazioni, vedi:
Eseguire query native con l'opzione EnableFolding
Power Query esegue una query nativa usando la funzione Value.NativeQuery.
Quando si usa questa funzione, è importante aggiungere l'opzione EnableFolding=true per assicurarsi che le query vengano ridotte di nuovo nel servizio Dataverse. Una query nativa non verrà ridotta a meno che non venga aggiunta questa opzione. L'abilitazione di questa opzione può comportare miglioramenti significativi delle prestazioni, fino al 97% di velocità in più in alcuni casi.
Si consideri la query seguente che usa una query nativa per ottenere le colonne selezionate dalla tabella account. La query nativa verrà ridotta perché è impostata l'opzione EnableFolding=true.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
È possibile prevedere di ottenere miglioramenti ottimali delle prestazioni quando si recupera subset di dati da un volume di dati di grandi dimensioni.
Suggerimento
Il miglioramento delle prestazioni può dipendere anche dal modo in cui Power BI esegue query sul database di origine. Ad esempio, una misura che usa la funzione DAX COUNTDISTINCT ha mostrato quasi un'assenza di miglioramento con o senza l'hint di riduzione. Quando la formula della misura è stata riscritta per usare la funzione DAX SUMX, la query è stata ridotta con un miglioramento del 97% rispetto alla stessa query senza l'hint.
Per altre informazioni, vedere Value.NativeQuery. L'opzione EnableFolding non è documentata perché è specifica solo per determinate origini dati.
Velocizzare la fase di valutazione
Se si usa il connettore Dataverse (noto in precedenza come Common Data Service), è possibile aggiungere l'opzione CreateNavigationProperties=false per velocizzare la fase di valutazione di un'importazione di dati.
La fase di valutazione di un'importazione dati passa attraverso i metadati dell'origine per determinare tutte le possibili relazioni della tabella. Tali metadati possono essere estesi, in particolare per Dataverse. Aggiungendo questa opzione alla query, si informa Power Query che non si intendono usare tali relazioni. L'opzione consente a Power BI Desktop di ignorare tale fase dell'aggiornamento e passare al recupero dei dati.
Nota
Non usare questa opzione quando la query dipende dalle colonne di relazione espansa.
Si consideri un esempio che recupera i dati dalla tabella account. Contiene tre colonne correlate al territorio: territory, territoryide territoryidname.
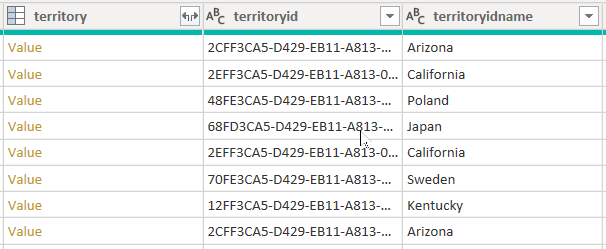
Quando si imposta l'opzione CreateNavigationProperties=false, le colonne territoryid e territoryidname rimarranno, ma la colonna territory, che è una colonna di relazione (mostra i collegamenti del valore con), verrà esclusa. È importante comprendere che le colonne delle relazioni di Power Query sono un concetto diverso dalle relazioni tra modelli, che propagano i filtri tra le tabelle del modello.
Si consideri la query seguente che usa l'opzione CreateNavigationProperties=false (nel passaggio Origine) per velocizzare la fase di valutazione di un'importazione di dati.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
Quando si usa questa opzione, è probabile che si verifichi un miglioramento significativo delle prestazioni quando una tabella Dataverse ha molte relazioni con altre tabelle. Ad esempio, poiché la tabella SystemUser è correlata a tutte le altre tabelle del database, le prestazioni di aggiornamento di questa tabella possono trarre vantaggio impostando l'opzione CreateNavigationProperties=false.
Nota
Questa opzione può migliorare le prestazioni dell'aggiornamento dei dati delle tabelle di importazione o delle tabelle in modalità di archiviazione doppia, incluso il processo di applicazione delle modifiche della finestra dell'editor di Power Query. Non migliora le prestazioni del filtro incrociato interattivo delle tabelle in modalità di archiviazione DirectQuery.
Risolvere le etichette di scelta vuote
Se si scopre che le etichette di scelta di Dataverse sono vuote in Power BI, è possibile ciò sia dovuto al fatto che le etichette non sono state pubblicate nell'endpoint TDS (Tabular Data Stream).
In questo caso, aprire il portale degli autori di Dataverse, passare all'area Soluzioni e quindi selezionare Pubblica tutte le personalizzazioni. Il processo di pubblicazione aggiornerà l'endpoint TDS con i metadati più recenti, rendendo disponibili le etichette delle opzioni per Power BI.
Modelli semantici più grandi con Collegamento ad Azure Synapse
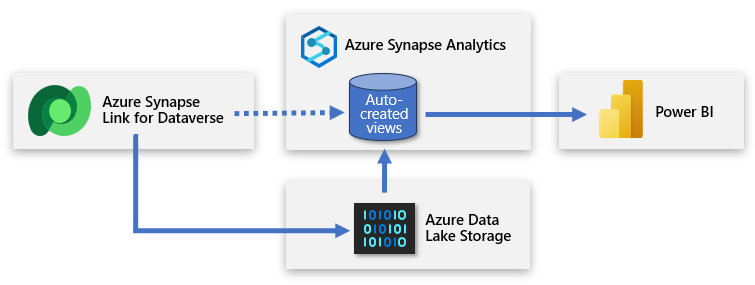
Dataverse consente di sincronizzare le tabelle con Azure Data Lake Storage (ADLS) e successivamente di connettersi a tali dati tramite un'area di lavoro di Azure Synapse. Con uno sforzo minimo, è possibile configurare Collegamento ad Azure Synapse per popolare i dati di Dataverse in Azure Synapse e consentire ai team di dati di individuare informazioni più approfondite.
Collegamento ad Azure Synapse consente una replica continua dei dati e dei metadati di Dataverse nel data lake. Offre anche un pool SQL serverless predefinito come origine dati pratica per le query di Power BI.
I punti di forza di questo approccio sono significativi. I clienti ottengono la possibilità di eseguire carichi di lavoro di analisi, business intelligence e apprendimento automatico nei dati di Dataverse usando vari servizi avanzati. I servizi avanzati includono Apache Spark, Power BI, Azure Data Factory, Azure Databricks e Azure Machine Learning.
Creazione di un Azure Synapse Link for Dataverse
Per creare un Collegamento ad Azure Synapse per Dataverse, sono necessari i prerequisiti seguenti.
- Accesso dell'amministratore di sistema all'ambiente Dataverse.
- Per Azure Data Lake Storage:
- È necessario disporre di un account di archiviazione da usare con ADLS Gen2.
- È necessario assegnare l'accesso Proprietario dei dati dei BLOB di archiviazione e Collaboratore ai dati dei BLOB di archiviazione all'account di archiviazione. Per ulteriori informazioni, vedere Controllo degli accessi in base al ruolo di Azure.
- L'account di archiviazione deve abilitare lo spazio dei nomi gerarchico.
- È consigliabile che l'account di archiviazione usi l'archiviazione con ridondanza geografica e accesso in lettura (RA-GRS).
- Per la workspace Synapse:
- È necessario avere accesso a una workspace Synapse e avere l'accesso amministratore di Synapse assegnato. Per altre informazioni, vedere Ruoli e ambiti predefiniti del controllo degli accessi in base al ruolo di Synapse.
- L'area di lavoro deve trovarsi nella stessa area dell'account di archiviazione di ADLS Gen2.
La configurazione comporta l'accesso a Power Apps e la connessione di Dataverse all'area di lavoro di Azure Synapse. Un'esperienza simile alla procedura guidata consente di creare un nuovo collegamento selezionando l'account di archiviazione e le tabelle da esportare. Collegamento ad Azure Synapse copia quindi i dati nell'archiviazione di ADLS Gen2 e crea automaticamente viste nel pool SQL serverless di Azure Synapse predefinito. È quindi possibile connettersi a tali viste per creare un modello di Power BI.
Suggerimento
Per la documentazione completa sulla creazione, la gestione e il monitoraggio di Collegamento ad Azure Synapse, vedere Creare Azure Synapse Link for Dataverse con Azure Synapse Workspace.
Creare un secondo database SQL serverless
È possibile creare un secondo database SQL serverless e usarlo per aggiungere viste del report personalizzate. In questo modo, è possibile presentare un set semplificato di dati all'autore di Power BI che consente di creare un modello basato su dati utili e pertinenti. Il nuovo database SQL serverless diventa la connessione dell'origine primaria dell'autore e una semplice rappresentazione dei dati che derivano dal data lake.

Questo approccio offre dati a Power BI incentrati, arricchiti e filtrati.
È possibile creare un database SQL serverless nell'area di lavoro di Azure Synapse usando Azure Synapse Studio. Selezionare Serverless come tipo di database SQL e immettere un nome di database. Power Query può connettersi a questo database connettendosi all'endpoint SQL dell'area di lavoro.
Creare viste personalizzate
È possibile creare viste personalizzate che eseguono il wrapping di query del pool SQL serverless. Queste viste fungeranno da origini di dati semplici e pulite a cui si connette Power BI. Le viste devono:
- Includere le etichette associate ai campi di scelta.
- Ridurre la complessità includendo solo le colonne necessarie per la modellazione dei dati.
- Filtrare le righe non necessarie, ad esempio record inattivi.
Si consideri la vista seguente che recupera i dati della campagna.
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
Si noti che la vista include solo quattro colonne, ognuna con un alias di un nome descrittivo. Esiste anche una clausola WHERE per restituire solo le righe necessarie, in questo caso campagne attive. Inoltre, la vista esegue una query sulla tabella delle campagne unita alle tabelle OptionsetMetadata e StatusMetadata, le quali recuperano le etichette di scelta.
Suggerimento
Per altre informazioni su come recuperare i metadati, vedere Accedere a etichette a scelta direttamente da Azure Synapse Link for Dataverse.
Eseguire query su tabelle appropriate
Collegamento ad Azure Synapse per Dataverse garantisce che i dati vengano continuamente sincronizzati con i dati nel data lake. Per le attività di utilizzo elevato di operazione, la scrittura e la lettura simultanee possono creare blocchi che causano l'esito negativo delle query. Per garantire l'affidabilità durante il recupero dei dati, due versioni dei dati della tabella vengono sincronizzate in Azure Synapse.
- Dati quasi in tempo reale: fornisce una copia dei dati sincronizzati da Dataverse tramite collegamento ad Azure Synapse in modo efficiente rilevando i dati modificati dall'estrazione iniziale o dall'ultima sincronizzazione.
- I dati snapshot: forniscono una copia di sola lettura di dati aggiornati a intervalli regolari e quasi in tempo reale (in questo caso ogni ora). I nomi delle tabelle di dati snapshot _partitioned sono accodati al nome.
Se si prevede che verrà eseguito un volume elevato di operazioni di lettura e scrittura contemporanee, recuperare i dati dalle tabelle di snapshot per evitare errori di query.
Per altre informazioni, vedere Accedere ai dati near real-time e ai dati snapshot di sola lettura.
Connettersi a Synapse Analytics
Per eseguire query su un pool SQL serverless di Azure Synapse, è necessario l'endpoint SQL dell'area di lavoro. È possibile recuperare l'endpoint da Synapse Studio aprendo le proprietà del pool SQL serverless.
In Power BI Desktop è possibile connettersi ad Azure Synapse usando il connettore SQL di Azure Synapse Analytics. Quando richiesto per il server, immettere l'endpoint SQL dell'area di lavoro.
Considerazioni per DirectQuery
Esistono molti casi d'uso quando si usa DirectQuery, la modalità di archiviazione può risolvere i requisiti. Tuttavia, l'uso di DirectQuery può influire negativamente sulle prestazioni del report di Power BI. Un report che usa una connessione DirectQuery a Dataverse non sarà veloce quanto un report che usa un modello di importazione. In generale, è opportuno importare i dati in Power BI laddove possibile.
È consigliabile prendere in considerazione gli argomenti di questa sezione quando si usa DirectQuery.
Per altre informazioni su come determinare quando usare la modalità di archiviazione DirectQuery, vedere Scegliere un framework di modello di Power BI.
Usare le tabelle delle dimensioni in modalità di archiviazione doppia
Una tabella in modalità di archiviazione doppia è impostata per usare le modalità di archiviazione sia di importazione che di archiviazione DirectQuery. In fase di query, Power BI determina la modalità più efficiente da usare. Quando possibile, Power BI tenta di soddisfare le query usando i dati importati perché l'operazione è più veloce.
È consigliabile impostare le tabelle delle dimensioni sulla modalità di archiviazione doppia, se appropriato. In questo modo, gli oggetti visivi del filtro dei dati e gli elenchi di schede del filtro, che spesso si basano sulle colonne della tabella delle dimensioni, eseguiranno il rendering più rapidamente perché verranno eseguite query su di esse dai dati importati.
Importante
Quando una tabella delle dimensioni deve ereditare il modello di sicurezza Dataverse, non è appropriato usare la modalità di archiviazione doppia.
Le tabelle dei fatti, che in genere archiviano grandi volumi di dati, devono rimanere come tabelle in modalità di archiviazione DirectQuery. Verranno filtrati in base alle tabelle delle dimensioni correlate in modalità di archiviazione doppia, che possono essere aggiunte alla tabella dei fatti per ottenere filtri e raggruppamenti efficienti.
Si consideri la progettazione del modello di dati seguente. Tre tabelle dimensionali, Owner, Accounte Campaign, hanno un bordo superiore a righe, il che significa che sono impostate sulla modalità di archiviazione doppia.
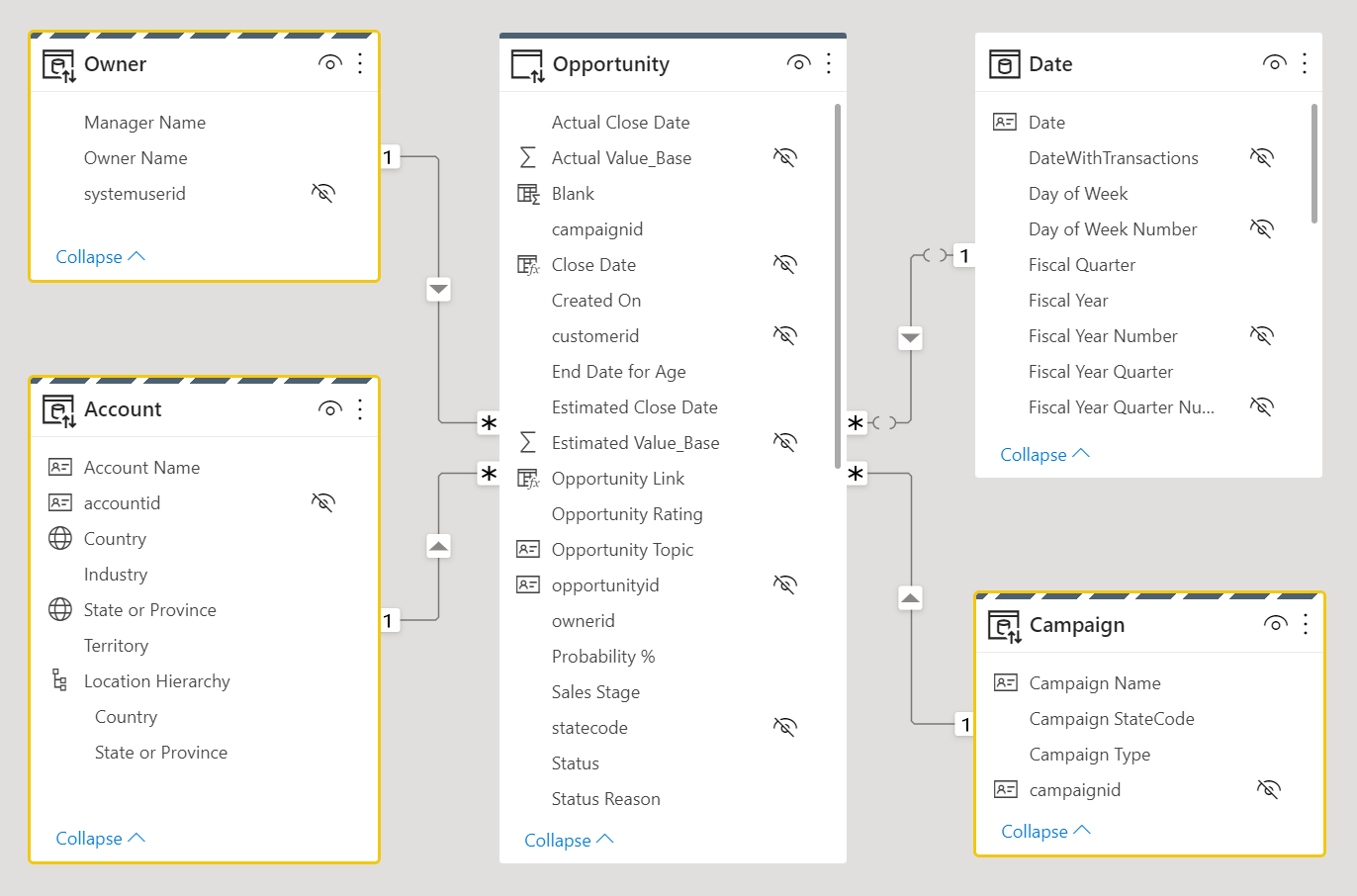
Per altre informazioni sulle modalità di archiviazione tabelle, tra cui l'archiviazione doppia, vedere Gestire la modalità di archiviazione in Power BI Desktop.
Abilitare l'accesso Single Sign-On
Quando si pubblica un modello DirectQuery nel servizio Power BI, è possibile usare le impostazioni del modello semantico per abilitare l'accesso Single Sign-On (SSO) usando Microsoft Entra ID OAuth2 per gli utenti del report. È consigliabile abilitare questa opzione quando le query di Dataverse devono essere eseguite nel contesto di sicurezza dell'utente del report.
Quando l'opzione SSO è abilitata, Power BI invia le credenziali di Microsoft Entra autenticate dell'utente del report nelle query a Dataverse. Questa opzione consente a Power BI di rispettare le impostazioni di sicurezza configurate nell'origine dati.
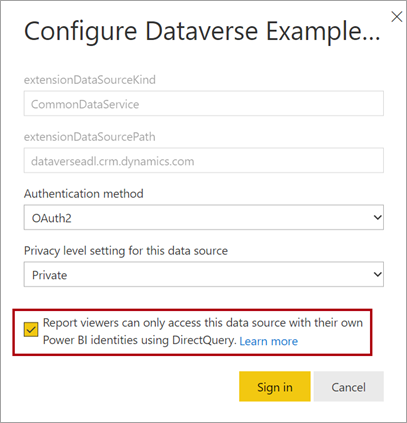
Per altre informazioni, vedere Single Sign-On (SSO) per le origini DirectQuery.
Replicare i filtri "Personali" in Power Query
Quando si usano Microsoft Dynamics 365 Customer Engagement (CE) e Power Apps basate su modello costruite su Dataverse, è possibile creare visualizzazioni che mostrano solo i record in cui un campo nome utente, ad esempio Owner, corrisponde all'utente corrente. Ad esempio, è possibile creare visualizzazioni denominate "Opportunità personali aperte", "Casi attivi personali" e altre.
Si consideri un esempio di come la vista Account personali attivi di Dynamics 365 include un filtro per cui il Proprietario è uguale all'utente corrente.
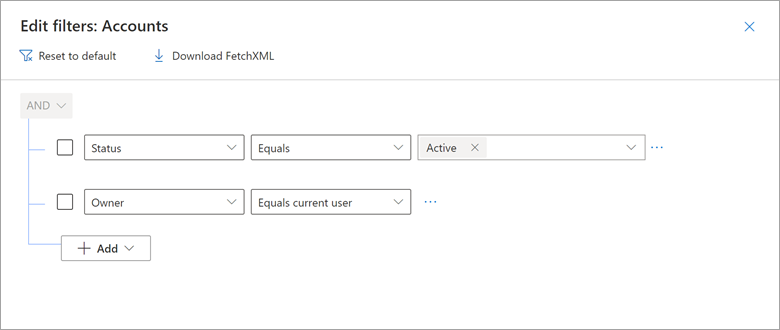
È possibile riprodurre questo risultato in Power Query usando una query nativa che incorpora il token CURRENT_USER.
Si consideri l'esempio seguente che mostra una query nativa che restituisce gli account per l'utente corrente. Nella clausola WHERE, si noti che la colonna ownerid viene filtrata dal token CURRENT_USER.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
Quando si pubblica il modello nel servizio Power BI, è necessario abilitare l'accesso Single Sign-On (SSO) in modo che Power BI invii le credenziali di Microsoft Entra autenticate dell'utente del report a Dataverse.
Creare modelli di importazione supplementari
È possibile creare un modello DirectQuery che applica le autorizzazioni di Dataverse sapendo che le prestazioni verranno rallentate. È quindi possibile integrare questo modello con modelli di importazione destinati a soggetti o gruppi di destinatari specifici che potrebbero applicare autorizzazioni di Sicurezza a livello di riga.
Ad esempio, un modello di importazione può fornire l'accesso a tutti i dati di Dataverse, ma non applicare alcuna autorizzazione. Questo modello è adatto ai dirigenti che hanno già accesso a tutti i dati di Dataverse.
Come altro esempio, quando Dataverse applica le autorizzazioni basate sui ruoli per area di vendita, è possibile creare un modello di importazione e replicare tali autorizzazioni usando la Sicurezza a livello di riga. In alternativa, è possibile creare un modello per ogni area di vendita. È quindi possibile concedere l'autorizzazione di lettura a tali modelli (modelli semantici) ai venditori di ogni area. Per facilitare la creazione di questi modelli a livello di area, è possibile usare parametri e modelli di report. Per altre informazioni, vedere Creare e usare modelli di report in Power BI Desktop.
Contenuto correlato
Per altre informazioni correlate a questo articolo, vedere le risorse seguenti.