Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La classificazione dei dati nel Microsoft Purview Data Map è un modo per classificare gli asset di dati assegnando classi o etichette logiche univoche agli asset di dati. La classificazione si basa sul contesto aziendale dei dati. Ad esempio, è possibile classificare gli asset in base al numero di passaporto, al numero di patente di guida, al numero di carta di credito, al codice SWIFT, al nome della persona e così via. Altre informazioni sulla classificazione dei dati in Mappa dati.
Questo articolo descrive le procedure consigliate da adottare quando si classificano gli asset di dati, in modo che le analisi siano più efficaci e siano disponibili le informazioni più complete possibili sull'intero patrimonio dati.
Set di regole di analisi
Usando un set di regole di analisi, è possibile configurare le classificazioni pertinenti che devono essere applicate all'analisi specifica per l'origine dati. Selezionare le classificazioni di sistema pertinenti oppure selezionare classificazioni personalizzate se ne è stata creata una per i dati da analizzare.
Nell'immagine seguente, ad esempio, verranno applicate solo le classificazioni specifiche selezionate e personalizzate per l'origine dati che si sta analizzando, ad esempio i dati finanziari.

Gestione delle annotazioni
Mentre si decide quali classificazioni applicare, è consigliabile:
Passare al riquadroClassificazionidi gestione> annotazioni mappa dati>.
Esaminare le classificazioni di sistema disponibili da applicare agli asset di dati da analizzare. I nomi formali delle classificazioni di sistema hanno un prefisso MICROSOFT .

Creare una classificazione personalizzata, se necessario. Selezionare la scheda Personalizzato e quindi + Nuovo. Informazioni su come creare una classificazione personalizzata.
Creare la regola di classificazione per la classificazione personalizzata creata nel passaggio precedente. Passare aRegole diclassificazione di gestione> annotazioni mappa> dati. Qui è possibile creare la regola di classificazione per il nome di classificazione personalizzato creato nel passaggio precedente.



Classificazioni personalizzate
Creare classificazioni personalizzate solo se le classificazioni di sistema disponibili non soddisfano le proprie esigenze.
Per il nome della classificazione personalizzata, è consigliabile usare una convenzione dello spazio dei nomi, ad esempio il< nome> della società.<business unit>.<nome> di classificazione personalizzato).
Ad esempio, per la classificazione EMPLOYEE_ID personalizzata per la società fittizia Contoso, il nome della classificazione personalizzata verrà CONTOSO.HR. EMPLOYEE_ID e il nome descrittivo viene archiviato nel sistema come HR. ID DIPENDENTE.

Quando si creano e si configurano le regole di classificazione per una classificazione personalizzata, eseguire le operazioni seguenti:
Selezionare il nome di classificazione appropriato per il quale deve essere creata la regola di classificazione.
Il Microsoft Purview Data Map supporta i due metodi seguenti per la creazione di regole di classificazione personalizzate:
Utilizzare il metodo Espressione regolare (regex) se è possibile esprimere in modo coerente l'elemento dati usando un modello di espressione regolare oppure è possibile generare il modello usando un file di dati. Assicurarsi che i dati di esempio riflettano la popolazione.
Utilizzare il metodo Dictionary solo se l'elenco di valori nel file di dizionario rappresenta tutti i valori possibili dei dati da classificare e si prevede che sia conforme a un determinato set di dati (considerando anche i valori futuri).

Utilizzo del metodo espressione regolare :
Configurare il modello regex per i dati da classificare. Assicurarsi che il modello regex sia sufficientemente generico da soddisfare i dati classificati.
Microsoft Purview offre anche una funzionalità per generare un modello regex suggerito. Dopo aver caricato un file di dati di esempio, selezionare uno dei modelli suggeriti e quindi selezionare Aggiungi ai modelli per usare i modelli di dati e colonne suggeriti. È possibile modificare i modelli suggeriti oppure digitare modelli personalizzati senza dover caricare un file.
È anche possibile configurare il modello di nome della colonna, in modo che la colonna venga classificata in modo da ridurre al minimo i falsi positivi.
Configurare il parametro soglia di corrispondenza minima accettabile per i dati che corrispondono al modello di dati per applicare la classificazione. I valori soglia possono essere compresi tra 1% e 100%. È consigliabile specificare un valore di almeno il 60% come soglia per evitare falsi positivi. Tuttavia, è possibile configurare in base alle esigenze per scenari di classificazione specifici. Ad esempio, la soglia potrebbe essere inferiore all'1% se si vuole rilevare e applicare una classificazione per qualsiasi valore nei dati se corrisponde al modello.
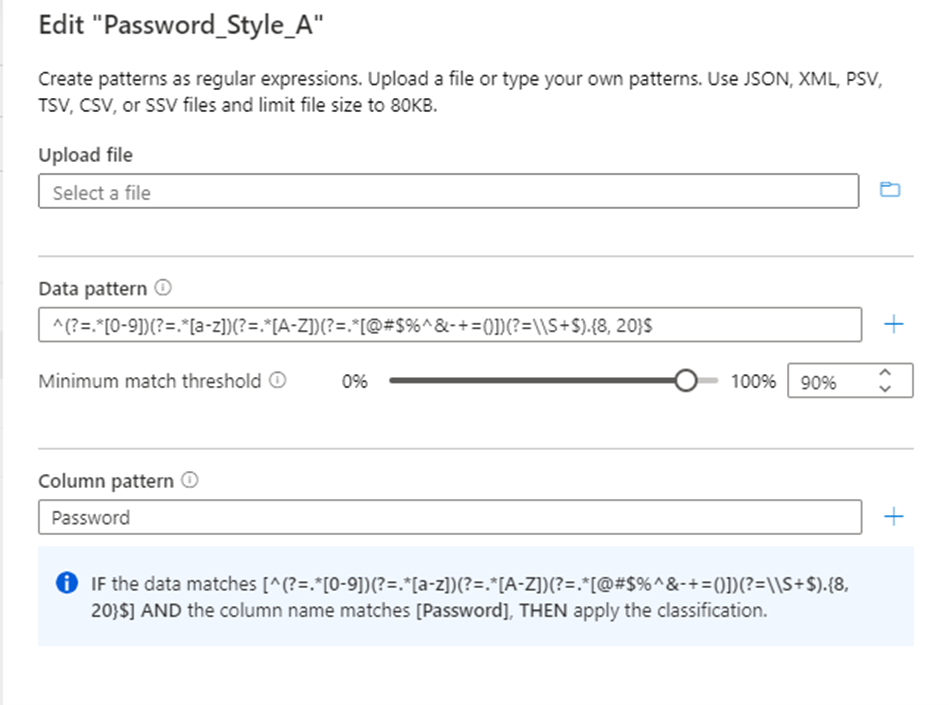
L'opzione per impostare una regola di corrispondenza minima viene disabilitata automaticamente se alla regola di classificazione vengono aggiunti più modelli di dati.
Usare la regola di classificazione test e testare con i dati di esempio per verificare che la regola di classificazione funzioni come previsto. Assicurarsi che nei dati di esempio , ad esempio in un file .csv, siano presenti almeno tre colonne, inclusa la colonna in cui deve essere applicata la classificazione. Se il test ha esito positivo, verrà visualizzata l'etichetta di classificazione nella colonna, come illustrato nell'immagine seguente:

Uso del metodo Dictionary :
È possibile utilizzare il metodo Dictionary per adattare i dati di enumerazione o se è disponibile l'elenco di dizionario dei valori possibili.
Questo metodo supporta i file .csv e tsv, con un limite di dimensioni del file di 30 megabyte (MB).



Archetipi di classificazione personalizzati
Funzionamento del parametro "threshold" nell'espressione regolare
Considerare i dati di origine di esempio nell'immagine seguente. Sono presenti cinque colonne e la regola di classificazione personalizzata deve essere applicata alle colonne Sample_col1, Sample_col2 e Sample_col3 per il modello di dati N{Digit}{Digit}{Digit}{Digit}AN.

La classificazione personalizzata è denominata NDDDAN.
La regola di classificazione (regex per il modello di dati) è ^N[0-9]{3}AN$.

La soglia verrà calcolata per il modello "^N[0-9]{3}AN$", come illustrato nell'immagine seguente:

Se si ha una soglia del 55%, verranno classificate solo le colonne Sample_col1 e Sample_col2 . Sample_col3 non verrà classificato, perché non soddisfa il criterio di soglia del 55%.





Come usare modelli di dati e colonne
Per i dati di esempio specificati, in cui sia la colonna B che la colonna C hanno modelli di dati simili, è possibile classificare nella colonna B in base al modello di dati "^P[0-9]{3}[A-Z]{2}$".

Usare il modello di colonna insieme al modello di dati per assicurarsi che venga classificata solo la colonna ID prodotto .

Nota
Il modello di colonna viene verificato come condizione AND con il modello di dati.
Usare la regola di classificazione test e testare con i dati di esempio per verificare che la regola di classificazione funzioni come previsto.




Come usare più modelli di colonna
Se sono presenti più modelli di colonna da classificare per la stessa regola di classificazione, usare nomi di colonna delimitati da caratteri di pipe (|). Ad esempio, per le colonne ID prodotto, Product_ID, ProductID e così via, scrivere il modello di colonna come illustrato nell'immagine seguente:

Per altre informazioni, vedere Costrutto di alternanza regex.
Considerazioni sulla classificazione
Ecco alcune considerazioni da tenere presenti durante la definizione delle classificazioni:
Per decidere quali classificazioni devono essere applicate agli asset prima dell'analisi, considerare come devono essere usate le classificazioni. Le etichette di classificazione non necessarie potrebbero sembrare rumorose e persino fuorvianti per i consumer di dati. È possibile usare le classificazioni per:
- Descrivere la natura dei dati presenti nell'asset di dati o nello schema che viene analizzato. In altre parole, le classificazioni devono consentire ai clienti di identificare il contenuto dell'asset di dati o dello schema dalle etichette di classificazione durante la ricerca nel catalogo.
- Impostare le priorità e sviluppare un piano per soddisfare le esigenze di sicurezza e conformità di un'organizzazione.
- Descrivere le fasi nei processi di preparazione dei dati (zona non elaborata, zona di destinazione e così via) e assegnare le classificazioni a asset specifici per contrassegnare la fase del processo.
È possibile assegnare automaticamente le classificazioni a livello di asset o colonna includendo le classificazioni pertinenti nella regola di analisi oppure assegnarle manualmente dopo aver inserito i metadati nella Microsoft Purview Data Map.
Per l'assegnazione automatica, vedere archivi dati supportati per il Microsoft Purview Data Map.
Prima di analizzare le origini dati nel Microsoft Purview Data Map, è importante comprendere i dati e configurare il set di regole di analisi appropriato, ad esempio selezionando la classificazione di sistema pertinente, le classificazioni personalizzate o una combinazione di entrambe, perché potrebbe influire sulle prestazioni dell'analisi. Per altre informazioni, vedere classificazioni supportate in Microsoft Purview Data Map.
Lo scanner Microsoft Purview applica regole di campionamento dei dati per analisi approfondite (soggette a classificazione) sia per le classificazioni di sistema che per le classificazioni personalizzate. La regola di campionamento si basa sul tipo di origini dati. Per altre informazioni, vedere la sezione "Campionamento all'interno di un file" in Origini dati supportate e tipi di file in Microsoft Purview.
Nota
Soglia dati distinti: si tratta del numero totale di valori di dati distinti che devono essere trovati in una colonna prima che lo scanner eservi il modello di dati. La soglia dei dati distinti non ha nulla a che fare con la corrispondenza dei criteri, ma è un prerequisito per la corrispondenza dei criteri. Le regole di classificazione del sistema richiedono che siano presenti almeno 8 valori distinti in ogni colonna per sottoporli alla classificazione. Il sistema richiede questo valore per assicurarsi che la colonna contenga dati sufficienti per consentire allo scanner di classificarlo in modo accurato. Ad esempio, una colonna che contiene più righe che contengono tutti il valore 1 non verrà classificata. Anche le colonne che contengono una riga con un valore e le altre righe hanno valori Null non verranno classificate. Se si specificano più modelli, questo valore si applica a ognuno di essi.
Le regole di campionamento si applicano anche ai set di risorse. Per altre informazioni, vedere la sezione "Campionamento di file del set di risorse" in origini dati e tipi di file supportati nel Microsoft Purview Data Map.
Le classificazioni personalizzate non possono essere applicate agli asset di tipo documento usando regole di classificazione personalizzate. Le classificazioni per tali tipi possono essere applicate solo manualmente.
Le classificazioni personalizzate non sono incluse in alcuna regola di analisi predefinita. Pertanto, se è prevista l'assegnazione automatica di classificazioni personalizzate, è necessario distribuire e usare una regola di analisi personalizzata che includa la classificazione personalizzata per eseguire l'analisi.
Se si applicano le classificazioni manualmente dal portale di governance di Microsoft Purview, tali classificazioni vengono mantenute nelle analisi successive.
Le analisi successive non rimuoveranno le classificazioni dagli asset, se sono state rilevate in precedenza, anche se le regole di classificazione non sono applicabili.
Per gli asset di dati di origine crittografati , Microsoft Purview seleziona solo nomi di file, nomi completi, dettagli dello schema per i tipi di file strutturati e tabelle di database. Per il funzionamento della classificazione, decrittografare i dati crittografati prima di eseguire le analisi.