Sincronizzazione multi-motore
La maggior parte delle GPU moderne contiene più motori indipendenti che forniscono funzionalità specializzate. Molti hanno uno o più motori di copia dedicati e un motore di calcolo, in genere distinto dal motore 3D. Ognuno di questi motori può eseguire comandi in parallelo tra loro. Direct3D 12 consente l'accesso con granularità fine ai motori 3D, di calcolo e di copia, usando code ed elenchi di comandi.
Motori GPU
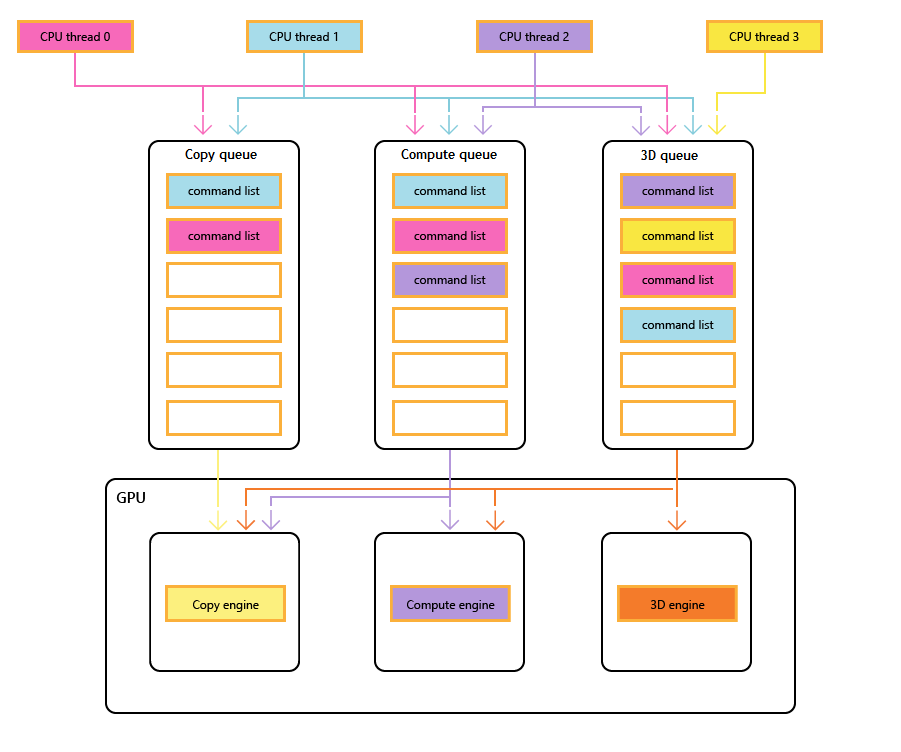
Il diagramma seguente mostra i thread CPU di un titolo, ognuno dei quali popola una o più code di copia, calcolo e 3D. La coda 3D può guidare tutti e tre i motori GPU; la coda di calcolo può guidare i motori di calcolo e copia; e la coda di copia semplicemente il motore di copia.
Man mano che i diversi thread popolano le code, non può esserci alcuna garanzia semplice dell'ordine di esecuzione, quindi la necessità di meccanismi di sincronizzazione, quando il titolo li richiede.
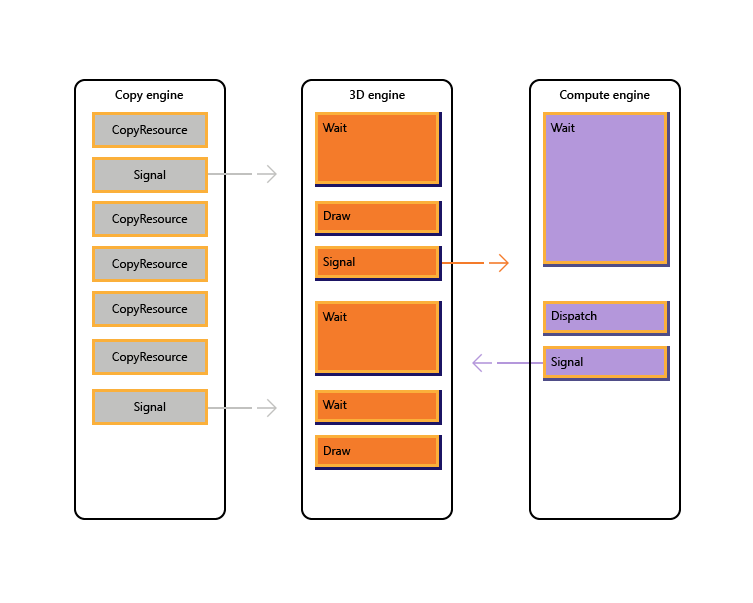
L'immagine seguente illustra come un titolo potrebbe pianificare il lavoro tra più motori GPU, inclusa la sincronizzazione tra motori, se necessario: mostra i carichi di lavoro per motore con dipendenze tra motori. In questo esempio il motore di copia copia copia prima di tutto una geometria necessaria per il rendering. Il motore 3D attende il completamento di queste copie ed esegue il rendering di un passaggio preliminare sulla geometria. Viene quindi utilizzato dal motore di calcolo. I risultati del motore di calcolo Dispatch, insieme a diverse operazioni di copia della trama nel motore di copia, vengono utilizzati dal motore 3D per la chiamata di Disegno finale.
Lo pseudo-codice seguente illustra come un titolo potrebbe inviare un carico di lavoro di questo tipo.
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
Lo pseudo-codice seguente illustra la sincronizzazione tra i motori di copia e 3D per eseguire l'allocazione di memoria simile all'heap tramite un buffer circolare. I titoli hanno la flessibilità di scegliere il giusto equilibrio tra l'ottimizzazione del parallelismo (tramite un buffer di grandi dimensioni) e la riduzione dell'utilizzo e della latenza della memoria (tramite un buffer di piccole dimensioni).
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
Scenari multi-motore
Direct3D 12 consente di evitare di incorrere accidentalmente in inefficienze causate da ritardi di sincronizzazione imprevisti. Consente inoltre di introdurre la sincronizzazione a un livello superiore in cui la sincronizzazione necessaria può essere determinata con maggiore certezza. Un secondo problema risolto da più motori consiste nel rendere più esplicite le operazioni costose, che include transizioni tra 3D e video tradizionalmente costose a causa della sincronizzazione tra più contesti del kernel.
In particolare, gli scenari seguenti possono essere risolti con Direct3D 12.
- Lavoro gpu asincrono e con priorità bassa. Ciò consente l'esecuzione simultanea di operazioni gpu con priorità bassa e atomica che consentono a un thread GPU di utilizzare i risultati di un altro thread non sincronizzato senza bloccare.
- Lavoro di calcolo con priorità elevata. Con il calcolo in background è possibile interrompere il rendering 3D per eseguire una piccola quantità di lavoro di calcolo ad alta priorità. I risultati di questo lavoro possono essere ottenuti in anticipo per un'ulteriore elaborazione sulla CPU.
- Lavoro di calcolo in background. Una coda di priorità bassa separata per i carichi di lavoro di calcolo consente a un'applicazione di usare cicli GPU di riserva per eseguire il calcolo in background senza alcun impatto negativo sul rendering primario (o altre attività). Le attività in background possono includere la decompressione delle risorse o l'aggiornamento di simulazioni o strutture di accelerazione. Le attività in background devono essere sincronizzate raramente sulla CPU (circa una volta per fotogramma) per evitare di bloccarsi o rallentare il lavoro in primo piano.
- Streaming e caricamento dei dati. Una coda di copia separata sostituisce i concetti di D3D11 relativi ai dati iniziali e all'aggiornamento delle risorse. Anche se l'applicazione è responsabile di altri dettagli nel modello Direct3D 12, questa responsabilità è dotata di potenza. L'applicazione può controllare la quantità di memoria di sistema dedicata al buffering dei dati di caricamento. L'app può scegliere quando e come (CPU e GPU, blocco e non blocco) da sincronizzare e tenere traccia dello stato di avanzamento e controllare la quantità di lavoro in coda.
- Parallelismo aumentato. Le applicazioni possono usare code più approfondite per carichi di lavoro in background (ad esempio, decodifica video) quando hanno code separate per il lavoro in primo piano.
In Direct3D 12 il concetto di coda di comandi è la rappresentazione API di una sequenza di lavoro approssimativamente seriale inviata dall'applicazione. Le barriere e altre tecniche consentono l'esecuzione di questo lavoro in una pipeline o in ordine non ordinato, ma l'applicazione vede solo una singola sequenza temporale di completamento. Corrisponde al contesto immediato in D3D11.
API di sincronizzazione
Dispositivi e code
Il dispositivo Direct3D 12 include metodi per creare e recuperare code di comandi di tipi e priorità diversi. La maggior parte delle applicazioni deve usare le code di comandi predefinite perché consentono l'utilizzo condiviso da altri componenti. Le applicazioni con requisiti di concorrenza aggiuntivi possono creare code aggiuntive. Le code vengono specificate dal tipo di elenco di comandi utilizzato.
Fare riferimento ai metodi di creazione seguenti di ID3D12Device.
- CreateCommandQueue : crea una coda di comandi in base alle informazioni in una struttura di 12_COMMAND_QUEUE_DESC Direct3D .
- CreateCommandList : crea un elenco di comandi di tipo Direct3D 12_COMMAND_LIST_TYPE.
- CreateFence : crea un recinto, notando i flag in Direct3D 12_FENCE_FLAGS. Le recinzioni vengono usate per sincronizzare le code.
Le code di tutti i tipi (3D, calcolo e copia) condividono la stessa interfaccia e sono tutte basate su elenchi di comandi.
Fare riferimento ai metodi seguenti di ID3D12CommandQueue.
- ExecuteCommandLists : invia una matrice di elenchi di comandi per l'esecuzione. Ogni elenco di comandi definito da ID3D12CommandList.
- Segnale : imposta un valore di isolamento quando la coda (in esecuzione nella GPU) raggiunge un determinato punto.
- Attesa : la coda attende fino a quando il limite specificato raggiunge il valore specificato.
Si noti che i bundle non vengono utilizzati da code e pertanto questo tipo non può essere usato per creare una coda.
Barriere
L'API multi-engine fornisce API esplicite per creare e sincronizzare usando i recinti. Un recinto è un costrutto di sincronizzazione controllato da un valore UINT64. I valori di isolamento vengono impostati dall'applicazione. Un'operazione di segnalazione modifica il valore di recinto e un'operazione di attesa blocca fino a quando il limite non ha raggiunto il valore richiesto o superiore. Un evento può essere generato quando un recinto raggiunge un determinato valore.
Fare riferimento ai metodi dell'interfaccia ID3D12Fence .
- GetCompletedValue : restituisce il valore corrente del recinto.
- SetEventOnCompletion : causa l'attivazione di un evento quando il limite raggiunge un determinato valore.
- Segnale : imposta la recinzione sul valore specificato.
Le recinzioni consentono l'accesso della CPU al valore limite corrente e i segnali e le attese della CPU.
Il metodo Signal nell'interfaccia ID3D12Fence aggiorna un recinto dal lato CPU. Questo aggiornamento si verifica immediatamente. Il metodo Signal in ID3D12CommandQueue aggiorna un recinto dal lato GPU. Questo aggiornamento si verifica dopo il completamento di tutte le altre operazioni nella coda dei comandi.
Tutti i nodi in una configurazione multi-motore possono leggere e reagire a qualsiasi recinto raggiungendo il valore corretto.
Le applicazioni impostano i propri valori di recinto, un buon punto di partenza potrebbe aumentare una volta per ogni fotogramma.
Un recinto può essere riavvolto. Ciò significa che il valore di recinto non deve essere incrementato esclusivamente. Se un'operazione Signal viene accodata in due code di comandi diverse o se due thread CPU chiamano entrambi Signal su un recinto, potrebbe esserci una gara per determinare quale segnale viene completato per ultimo e quindi quale valore di isolamento è quello che rimarrà. Se un recinto viene riattivato, eventuali nuove attese (incluse le richieste SetEventOnCompletion ) verranno confrontate con il nuovo valore limite inferiore e pertanto potrebbero non essere soddisfatte, anche se il valore di recinto era stato in precedenza sufficientemente elevato per soddisfarli. Se si verifica una gara, tra un valore che soddisfa un'attesa in sospeso e un valore inferiore che non lo sarà, l'attesa verrà soddisfatta indipendentemente dal valore che rimane successivamente.
Le API di isolamento offrono potenti funzionalità di sincronizzazione, ma possono creare problemi potenzialmente difficili da sottoporre a debug. È consigliabile usare ogni recinzione solo per indicare lo stato di avanzamento su una sequenza temporale per evitare gare tra i segnali.
Copiare e calcolare gli elenchi di comandi
Tutti e tre i tipi di elenco di comandi usano l'interfaccia ID3D12GraphicsCommandList , ma solo un subset dei metodi è supportato per la copia e il calcolo.
Gli elenchi di comandi di copia e calcolo possono usare i metodi seguenti.
Gli elenchi di comandi di calcolo possono anche usare i metodi seguenti.
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- DiscardResource
- Dispatch
- ExecuteIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
Gli elenchi di comandi di calcolo devono impostare un PSO di calcolo quando si chiama SetPipelineState.
I bundle non possono essere usati con elenchi di comandi di calcolo o di copia o code.
Esempio di calcolo e grafica con pipeline
In questo esempio viene illustrato come usare la sincronizzazione di isolamento per creare una pipeline di lavoro di calcolo in una coda (a cui pComputeQueuesi fa riferimento ) utilizzata dal lavoro grafico nella coda pGraphicsQueue. Il lavoro di calcolo e grafica viene eseguito tramite pipeline con la coda grafica che utilizza il risultato del lavoro di calcolo da diversi fotogrammi indietro e viene usato un evento cpu per limitare il totale del lavoro in coda nel complesso.
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
Per supportare questa pipelining, è necessario che sia presente un buffer di ComputeGraphicsLatency+1 copie diverse dei dati che passano dalla coda di calcolo alla coda grafica. Gli elenchi di comandi devono usare UAV e indiretto per leggere e scrivere dalla "versione" appropriata dei dati nel buffer. La coda di calcolo deve attendere il completamento della lettura della coda grafica dai dati per il frame N prima di poter scrivere frame N+ComputeGraphicsLatency.
Si noti che la quantità di coda di calcolo funzionata rispetto alla CPU non dipende direttamente dalla quantità di buffering necessaria, tuttavia, l'accodamento della GPU oltre la quantità di spazio disponibile nel buffer è meno utile.
Un meccanismo alternativo per evitare il riferimento indiretto consiste nel creare più elenchi di comandi corrispondenti a ognuna delle versioni "rinominate" dei dati. Nell'esempio seguente viene usata questa tecnica durante l'estensione dell'esempio precedente per consentire l'esecuzione asincrona delle code di calcolo e grafica.
Esempio di calcolo asincrono e grafica
Questo esempio successivo consente di eseguire il rendering della grafica in modo asincrono dalla coda di calcolo. Esiste ancora una quantità fissa di dati memorizzati nel buffer tra le due fasi, tuttavia ora il lavoro grafico procede in modo indipendente e usa il risultato più aggiornato della fase di calcolo, come noto sulla CPU quando il lavoro grafico viene accodato. Ciò sarebbe utile se il lavoro grafico è stato aggiornato da un'altra origine, ad esempio l'input dell'utente. Devono essere presenti più elenchi di comandi per consentire il ComputeGraphicsLatency funzionamento dei fotogrammi grafici in anteprima alla volta e la funzione UpdateGraphicsCommandList rappresenta l'aggiornamento dell'elenco di comandi per includere i dati di input più recenti e leggere dai dati di calcolo dal buffer appropriato.
La coda di calcolo deve comunque attendere il completamento della coda grafica con i buffer della pipe, ma è stata introdotta una terza recinzione (pGraphicsComputeFence) in modo che sia possibile tenere traccia dello stato di avanzamento del lavoro di calcolo della lettura grafica rispetto allo stato di avanzamento della grafica in generale. Ciò riflette il fatto che ora i fotogrammi grafici consecutivi potrebbero leggere dallo stesso risultato di calcolo o potrebbero ignorare un risultato di calcolo. Una progettazione più efficiente ma leggermente più complessa userebbe solo il singolo recinto grafico e archivierebbe un mapping ai fotogrammi di calcolo usati da ogni fotogramma grafico.
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + PipeBufferIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
Accesso alle risorse a più code
Per accedere a una risorsa in più code, un'applicazione deve rispettare le regole seguenti.
L'accesso alle risorse (fare riferimento a Direct3D 12_RESOURCE_STATES) è determinato dalla classe del tipo di coda non dall'oggetto queue. Esistono due classi di tipo di coda: la coda compute/3D è una classe di tipo, Copy è una seconda classe di tipo. Una risorsa con una barriera allo stato NON_PIXEL_SHADER_RESOURCE in una coda 3D può quindi essere usata in tale stato in qualsiasi coda di calcolo o 3D, in base ai requisiti di sincronizzazione che richiedono la maggior parte delle scritture da serializzare. Gli stati delle risorse condivisi tra le due classi di tipi (COPY_SOURCE e COPY_DEST) sono considerati stati diversi per ogni classe di tipo. Pertanto, se una risorsa passa a COPY_DEST in una coda di copia, non è accessibile come destinazione di copia da code 3D o di calcolo e viceversa.
Riepilogare.
- Una coda "object" è qualsiasi coda singola.
- Una coda "type" è una delle tre seguenti: Calcolo, 3D e Copia.
- Una coda "classe di tipo" è una delle due seguenti: Calcolo/3D e Copia.
I flag COPY (COPY_DEST e COPY_SOURCE) usati come stati iniziali rappresentano stati nella classe del tipo 3D/Compute. Per usare inizialmente una risorsa in una coda di copia, deve iniziare nello stato COMMON. Lo stato COMMON può essere usato per tutti gli utilizzi in una coda di copia usando le transizioni di stato implicite.
Anche se lo stato delle risorse è condiviso tra tutte le code di calcolo e 3D, non è consentito scrivere nella risorsa contemporaneamente in code diverse. "Simultaneamente" in questo caso significa non sincronizzato, la notazione dell'esecuzione non sincronizzata non è possibile in alcuni hardware. Si applicano le regole seguenti.
- Una sola coda può scrivere in una risorsa alla volta.
- Più code possono leggere dalla risorsa purché non leggano i byte modificati dal writer (la lettura dei byte scritti contemporaneamente produce risultati non definiti).
- È necessario usare un recinto per la sincronizzazione dopo la scrittura prima che un'altra coda possa leggere i byte scritti o consentire l'accesso in scrittura.
I buffer nascosto presentati devono trovarsi nello stato di 12_RESOURCE_STATE_COMMON Direct3D.
Argomenti correlati
Guida alla programmazione direct3D 12
Uso delle barriere delle risorse per sincronizzare gli stati delle risorse in Direct3D 12
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per