注
このチュートリアルでは SQL Server 2017 (14.x) と RHEL 7.6 を使用しますが、RHEL 7 または RHEL 8 で SQL Server 2019 (15.x) を使用して高可用性を構成することもできます。 Pacemaker クラスターと可用性グループ リソースを構成するためのコマンドは RHEL 8 で変更されています。適切なコマンドの詳細については、記事「可用性グループのリソースを作成する」および RHEL 8 のリソースを参照してください。
このチュートリアルでは、次の作業を行う方法について説明します。
- 新しいリソース グループ、可用性セット、Linux 仮想マシン (VM) を作成する
- 高可用性 (HA) を有効にする
- Pacemaker クラスターの作成
- STONITH デバイスを作成してフェンス エージェントを構成する
- SQL Server と mssql-tools を RHEL にインストールする
- SQL Server Always On 可用性グループを構成する
- Pacemaker クラスター内に可用性グループ (AG) のリソースを構成する
- フェールオーバーとフェンス エージェントをテストする
このチュートリアルでは、Azure CLI を使用して、Azure にリソースをデプロイします。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
Azure Cloud Shell で Bash 環境を使用します。 詳細については、「Azure Cloud Shell の概要」を参照してください。

CLI リファレンス コマンドをローカルで実行する場合、Azure CLI をインストールします。 Windows または macOS で実行している場合は、Docker コンテナーで Azure CLI を実行することを検討してください。 詳細については、「Docker コンテナーで Azure CLI を実行する方法」を参照してください。
ローカル インストールを使用する場合は、az login コマンドを使用して Azure CLI にサインインします。 認証プロセスを完了するには、ターミナルに表示される手順に従います。 その他のサインイン オプションについては、「 Azure CLI を使用した Azure への認証」を参照してください。
初回使用時にインストールを求められたら、Azure CLI 拡張機能をインストールします。 拡張機能の詳細については、「Azure CLI で拡張機能を使用および管理する」を参照してください。
az version を実行し、インストールされているバージョンおよび依存ライブラリを検索します。 最新バージョンにアップグレードするには、az upgrade を実行します。
- この記事では、Azure CLI のバージョン 2.0.30 以降が必要です。 Azure Cloud Shell を使用している場合は、最新バージョンが既にインストールされています。
リソース グループを作成する
複数のサブスクリプションがある場合は、これらのリソースをデプロイするサブスクリプションを設定します。
次のコマンドを使用して、リージョンにリソース グループ <resourceGroupName> を作成します。
<resourceGroupName> は、任意の名前に置き換えてください。 このチュートリアルでは East US 2 を使用しています。 詳細については、次のクイックスタートを参照してください。
az group create --name <resourceGroupName> --location eastus2
可用性セットの作成
次の手順は可用性セットの作成です。 Azure Cloud Shell で次のコマンドを実行します。<resourceGroupName> は、実際のリソース グループ名に置き換えてください。
<availabilitySetName> の名前を選択します。
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
コマンドが完了すると、次の結果が得られます。
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
可用性セット内に RHEL VM を作成する
警告
従量課金制の RHEL イメージを選択し、高可用性 (HA) を構成する場合は、サブスクリプションの登録が必要になることがあります。 その場合、サブスクリプションに対して 2 回の支払いが生じる可能性があります。それは、VM の Microsoft Azure RHEL サブスクリプションと Red Hat のサブスクリプションに対して課金されるためです。 詳細については、https://access.redhat.com/solutions/2458541を参照してください。
"二重請求" されないようにするには、Azure VM を作成するときに RHEL HA イメージを使用します。 RHEL-HA イメージとして提供されるイメージは、HA リポジトリが事前に有効になっている従量課金制イメージでもあります。
HA を備えた RHEL を提供する仮想マシン イメージの一覧を取得します。
az vm image list --all --offer "RHEL-HA"次のような結果が表示されます。
[ { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "7.4", "urn": "RedHat:RHEL-HA:7.4:7.4.2019062021", "version": "7.4.2019062021" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "7.5", "urn": "RedHat:RHEL-HA:7.5:7.5.2019062021", "version": "7.5.2019062021" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "7.6", "urn": "RedHat:RHEL-HA:7.6:7.6.2019062019", "version": "7.6.2019062019" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "8.0", "urn": "RedHat:RHEL-HA:8.0:8.0.2020021914", "version": "8.0.2020021914" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "8.1", "urn": "RedHat:RHEL-HA:8.1:8.1.2020021914", "version": "8.1.2020021914" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "80-gen2", "urn": "RedHat:RHEL-HA:80-gen2:8.0.2020021915", "version": "8.0.2020021915" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "81_gen2", "urn": "RedHat:RHEL-HA:81_gen2:8.1.2020021915", "version": "8.1.2020021915" } ]このチュートリアルでは、RHEL 7 の例にはイメージ
RedHat:RHEL-HA:7.6:7.6.2019062019を、RHEL 8 の例にはRedHat:RHEL-HA:8.1:8.1.2020021914を選択しています。RHEL8-HA イメージにプレインストールされている SQL Server 2019 (15.x) を選択することもできます。 これらのイメージの一覧を取得するには、次のコマンドを実行します。
az vm image list --all --offer "sql2019-rhel8"次のような結果が表示されます。
[ { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "enterprise", "urn": "MicrosoftSQLServer:sql2019-rhel8:enterprise:15.0.200317", "version": "15.0.200317" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "enterprise", "urn": "MicrosoftSQLServer:sql2019-rhel8:enterprise:15.0.200512", "version": "15.0.200512" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "sqldev", "urn": "MicrosoftSQLServer:sql2019-rhel8:sqldev:15.0.200317", "version": "15.0.200317" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "sqldev", "urn": "MicrosoftSQLServer:sql2019-rhel8:sqldev:15.0.200512", "version": "15.0.200512" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "standard", "urn": "MicrosoftSQLServer:sql2019-rhel8:standard:15.0.200317", "version": "15.0.200317" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "standard", "urn": "MicrosoftSQLServer:sql2019-rhel8:standard:15.0.200512", "version": "15.0.200512" } ]上記のいずれかのイメージを使用して仮想マシンを作成した場合、SQL Server 2019 (15.x) がプレインストールされています。 この記事の「SQL Server と mssql-tools をインストールする」セクションはスキップしてください。
重要
可用性グループを設定するには、マシン名を 15 文字未満にする必要があります。 ユーザー名に大文字を含めることはできません。また、パスワードは 13 文字以上であることが必要です。
可用性セット内に 3 つの VM を作成します。 次のコマンドで、これらの値を置き換えます。
<resourceGroupName><VM-basename><availabilitySetName>-
<VM-Size>- 例: "Standard_D16_v3" <username><password>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --image "RedHat:RHEL-HA:7.6:7.6.2019062019" \ --admin-username "<username>" \ --admin-password "<password>" \ --authentication-type all \ --generate-ssh-keys done
上記のコマンドでは、VM を作成し、それらの VM 用に既定の Virtual Network を作成します。 さまざまな構成の詳細については、az vm create に関する記事を参照してください。
各 VM のコマンドが完了すると、次のような結果が得られます。
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/<VM1>",
"location": "eastus2",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"publicIpAddress": "",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
重要
上記のコマンドで作成される既定のイメージでは、既定で 32 GB の OS ディスクが作成されます。 この既定のインストールでは、領域が不足する可能性があります。 たとえば、パラメーター az vm create を上記の --os-disk-size-gb 128 コマンドに追加して使用すると、128 GB の OS ディスクを作成できます。
インストールに合わせて適切なフォルダー ボリュームを展開する必要がある場合は、 論理ボリューム マネージャー (LVM) を構成 できます。
作成された VM への接続をテストする
Azure Cloud Shell で次のコマンドを使用して、VM1 または他の VM に接続します。 自分の VM の IP がわからない場合は、こちらの Azure Cloud Shell のクイックスタートに従ってください。
ssh <username>@publicipaddress
接続に成功すると、Linux ターミナルを表す次の出力が表示されます。
[<username>@<VM1> ~]$
「exit」と入力して SSH セッションを終了します。
高可用性の有効化
重要
チュートリアルのこの部分を完了するには、RHEL と高可用性アドオンのサブスクリプションが必要です。 前のセクションで推奨されているイメージを使用している場合は、別のサブスクリプションを登録する必要はありません。
各 VM ノードに接続し、このガイドに従って HA を有効にします。 詳細については、「RHEL の高可用性サブスクリプションを有効にする」を参照してください。
ヒント
この記事全体を通して各 VM で同じコマンドを実行する必要があるため、各 VM への SSH セッションを同時に開いておくと便利です。
複数の sudo コマンドをコピーして貼り付けていて、パスワードの入力が求められる場合、追加のコマンドは実行されません。 各コマンドを個別に実行してください。
Pacemaker ファイアウォール ポートを開くには、各 VM で次のコマンドを実行します。
sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reload次のコマンドを使用して、すべてのノードで更新を行い、Pacemaker パッケージをインストールします。
注
このコマンド ブロックの一部によって、自分のネットワーク内で使用可能な IP アドレスを検索するためのツールとして nmap がインストールされます。 nmap をインストールする必要はありませんが、このチュートリアルの後半で役立ちます。
sudo yum update -y sudo yum install -y pacemaker pcs fence-agents-all resource-agents fence-agents-azure-arm nmap sudo rebootPacemaker パッケージをインストールしたときに作成された既定のユーザー用のパスワードを設定します。 すべてのノードで同じパスワードを使います。
sudo passwd hacluster次のコマンドを使用して、hosts ファイルを開き、ホスト名解決を設定します。 hosts ファイルの構成の詳細については、AG の構成に関するページを参照してください。
sudo vi /etc/hostsvi エディターで、テキストを挿入するために「
i」と入力します。空白行に、対応する VM のプライベート IP を追加します。 次に、IP アドレスの後にスペースを入れ、VM 名を追加します。 1 行ごとに別のエントリを入れていきます。<IP1> <VM1> <IP2> <VM2> <IP3> <VM3>重要
前の例では、プライベート IP アドレスを使用することをお勧めします。 この構成でパブリック IP アドレスを使用すると、設定が失敗します。また、VM を外部ネットワークに公開することはお勧めしません。
vi エディターを終了するには、まず Esc キーを押し、コマンド
:wqを入力してファイルを書き込み、終了します。
Pacemaker クラスターを作成する
このセクションでは、pcsd サービスを有効にして開始し、クラスターを構成します。 SQL Server on Linux の場合、クラスター リソースは自動的に作成されません。 Pacemaker リソースを手動で有効にして作成する必要があります。 詳細については、RHEL のフェールオーバー クラスター インスタンスの構成に関する記事を参照してください。
pcsd サービスと Pacemaker を有効にして開始する
すべてのノードでコマンドを実行します。 これらのコマンド群により、再起動後に各ノードは再びクラスターの一部になります。
sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerすべてのノードから既存のクラスター構成を削除します。 次のコマンドを実行します。
sudo pcs cluster destroy sudo systemctl enable pacemakerプライマリ ノードで、次のコマンドを実行してクラスターを設定します。
- クラスター ノードを認証するための
pcs cluster authコマンドを実行すると、パスワードの入力を求められます。 前に作成した hacluster ユーザーのパスワードを入力します。
RHEL7
sudo pcs cluster auth <VM1> <VM2> <VM3> -u hacluster sudo pcs cluster setup --name az-hacluster <VM1> <VM2> <VM3> --token 30000 sudo pcs cluster start --all sudo pcs cluster enable --allRHEL8
RHEL 8 では、ノードを個別に認証する必要があります。 プロンプトが表示されたら、hacluster のユーザー名とパスワードを手動で入力します。
sudo pcs host auth <node1> <node2> <node3> sudo pcs cluster setup <clusterName> <node1> <node2> <node3> sudo pcs cluster start --all sudo pcs cluster enable --all- クラスター ノードを認証するための
次のコマンドを実行して、すべてのノードがオンラインになっていることを確認します。
sudo pcs statusRHEL 7
すべてのノードがオンラインになっている場合、次の例のような出力が表示されます。
Cluster name: az-hacluster WARNINGS: No stonith devices and stonith-enabled is not false Stack: corosync Current DC: <VM2> (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum Last updated: Fri Aug 23 18:27:57 2019 Last change: Fri Aug 23 18:27:56 2019 by hacluster via crmd on <VM2> 3 nodes configured 0 resources configured Online: [ <VM1> <VM2> <VM3> ] No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledRHEL 8
Cluster name: az-hacluster WARNINGS: No stonith devices and stonith-enabled is not false Cluster Summary: * Stack: corosync * Current DC: <VM2> (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum * Last updated: Fri Aug 23 18:27:57 2019 * Last change: Fri Aug 23 18:27:56 2019 by hacluster via crmd on <VM2> * 3 nodes configured * 0 resource instances configured Node List: * Online: [ <VM1> <VM2> <VM3> ] Full List of Resources: * No resources Daemon Status: * corosync: active/enabled * pacemaker: active/enabled * pcsd: active/enabledライブ クラスターの期待される投票数を 3 に設定します。 このコマンドは、ライブ クラスターにのみ影響し、構成ファイルに変更を加えるものではありません。
すべてのノードで、次のコマンドを使用して期待される投票数を設定します。
sudo pcs quorum expected-votes 3
フェンス エージェントを構成する
フェンス エージェントを構成する場合、このチュートリアルでは次の手順が変更されます。 詳細については、「STONITH デバイスの作成」を参照してください。
Azure フェンス エージェントのバージョンを確認して、更新されていることを確認します。 次のコマンドを使用します。
sudo yum info fence-agents-azure-arm
次の例のような出力が表示されます。
Loaded plugins: langpacks, product-id, search-disabled-repos, subscription-manager
Installed Packages
Name : fence-agents-azure-arm
Arch : x86_64
Version : 4.2.1
Release : 11.el7_6.8
Size : 28 k
Repo : installed
From repo : rhel-ha-for-rhel-7-server-eus-rhui-rpms
Summary : Fence agent for Azure Resource Manager
URL : https://github.com/ClusterLabs/fence-agents
License : GPLv2+ and LGPLv2+
Description : The fence-agents-azure-arm package contains a fence agent for Azure instances.
新しいアプリケーションを Microsoft Entra ID に登録する。
Microsoft Entra ID (旧称 Azure Active Directory) に新しいアプリケーションを登録するには、次の手順に従います。
- 「 https://portal.azure.com 」を参照してください。
-
Microsoft Entra ID の [プロパティ] ウィンドウを開き、
Tenant IDをメモしておきます。 - [アプリの登録] を選択します。
- [新規登録] を選択します。
-
名前を入力します (
<resourceGroupName>-appなど)。 [サポートされているアカウントの種類] については、[Accounts in this organizational directory only (Microsoft only - Single tenant)] (この組織のディレクトリ内のアカウントのみ (Microsoft のみ - 単一テナント)) を選択します。 -
[リダイレクト URI] で [Web] を選択して URL (たとえば
http://localhostなど) を入力し、[追加] を選択します。 サインオン URL は、任意の有効な URL を指定することができます。 完了したら、[登録] を選択します。 - 新しいアプリの登録用に [Certificates and Secrets] を選択し、[新しいクライアント シークレット] を選択します。
- 新しいキー (クライアント シークレット) の記述を入力し、[追加] を選択します。
- シークレットの値を書き留めます。 これは、サービス プリンシパルのパスワードとして使用します。
- 概要を選択します。 アプリケーション ID をメモします。 これは、サービス プリンシパルのユーザー名 (下記の手順のログイン ID) として使用します。
フェンス エージェントのカスタム ロールを作成する
「Azure CLI を使用して Azure カスタム ロールを作成する」チュートリアルに従ってください。
JSON ファイルは次の例のようになります。
-
<username>を任意の名前に置き換えます。 これは、このロール定義を作成するときに重複が発生しないようにするためです。 -
<subscriptionId>は、実際の Azure サブスクリプション ID に置き換えます。
{
"Name": "Linux Fence Agent Role-<username>",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [
],
"AssignableScopes": [
"/subscriptions/<subscriptionId>"
]
}
ロールを追加するには、次のコマンドを実行します。
-
<filename>は、対象のファイルの名前に置き換えます。 - ファイルが保存されているフォルダー以外のパスからコマンドを実行する場合は、ファイルのフォルダー パスをコマンドに含めます。
az role definition create --role-definition "<filename>.json"
次の出力が表示されます。
{
"assignableScopes": [
"/subscriptions/<subscriptionId>"
],
"description": "Allows to power-off and start virtual machines",
"id": "/subscriptions/<subscriptionId>/providers/Microsoft.Authorization/roleDefinitions/<roleNameId>",
"name": "<roleNameId>",
"permissions": [
{
"actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"dataActions": [],
"notActions": [],
"notDataActions": []
}
],
"roleName": "Linux Fence Agent Role-<username>",
"roleType": "CustomRole",
"type": "Microsoft.Authorization/roleDefinitions"
}
サービス プリンシパルにカスタム ロールを割り当てる
最後の手順で作成したカスタム ロール Linux Fence Agent Role-<username> をサービス プリンシパルに割り当てます。 所有者ロールは今後使わないでください。
- [https://resources.azure.com](https://portal.azure.com) に移動します
- [すべてのリソース] ペインを開きます
- 1 つ目のクラスター ノードの仮想マシンを選択します
- [アクセス制御 (IAM)] を選択します
- [ロールの割り当てを追加する] を選択します。
-
Linux Fence Agent Role-<username>一覧からロール を選択します -
[選択] 一覧に、前に作成したアプリケーションの名前 (
<resourceGroupName>-app) を入力します。 - [保存] を選びます。
- すべてのクラスター ノードでこれらの手順を繰り返します。
STONITH デバイスを作成する
ノード 1 で次のコマンドを実行します。
-
<ApplicationID>は、自分のアプリケーション登録の ID 値に置き換えます。 -
<password>は、クライアント シークレットの値に置き換えます。 -
<resourceGroupName>は、このチュートリアル用に使用しているサブスクリプションのリソース グループに置き換えます。 -
<tenantID>と<subscriptionId>は、自分の Azure サブスクリプションの値に置き換えます。
sudo pcs property set stonith-timeout=900
sudo pcs stonith create rsc_st_azure fence_azure_arm login="<ApplicationID>" passwd="<password>" resourceGroup="<resourceGroupName>" tenantId="<tenantID>" subscriptionId="<subscriptionId>" power_timeout=240 pcmk_reboot_timeout=900
HA サービス (--add-service=high-availability) を許可するルールをファイアウォールに既に追加しているため、すべてのノードで次のファイアウォール ポートを開く必要はありません: 2224、3121、21064、5405。 ただし、HA でなんらかの接続の問題が発生している場合は、次のコマンドを使用して、HA に関連付けられているこれらのポートを開きます。
ヒント
必要に応じて、このチュートリアルのすべてのポートを一度に追加して、時間を節約することができます。 開く必要があるポートについては、以降の関連セクションで説明します。 ここですべてのポートを追加する場合は、その他のポートも追加します: 1433 および 5022。
sudo firewall-cmd --zone=public --add-port=2224/tcp --add-port=3121/tcp --add-port=21064/tcp --add-port=5405/tcp --permanent
sudo firewall-cmd --reload
SQL Server と mssql-tools をインストールする
注
RHEL8-HA に SQL Server 2019 (15.x) がプレインストールされた VM を作成した場合、次の手順をスキップして SQL Server と mssql-tools のインストールを省略できます。その後、すべての VM で コマンドを実行して sa パスワードを設定した後、sudo /opt/mssql/bin/mssql-conf set-sa-passwordセクションを開始できます。
次のセクションを使用して、SQL Server と mssql-tools を VM にインストールします。 以下のいずれかのサンプルを選択して、SQL Server 2017 (14.x) を RHEL 7 にインストールするか、SQL Server 2019 (15.x) を RHEL 8 にインストールしてください。 すべてのノードでこれらのアクションをそれぞれ実行します。 詳細については、Red Hat VM への SQL Server のインストールに関するページを参照してください。
SQL Server を VM にインストールする
SQL Server をインストールするには、次のコマンドを使用します。
RHEL 7 と SQL Server 2017
sudo curl -o /etc/yum.repos.d/mssql-server.repo https://packages.microsoft.com/config/rhel/7/mssql-server-2017.repo
sudo yum install -y mssql-server
sudo /opt/mssql/bin/mssql-conf setup
sudo yum install mssql-server-ha
RHEL 8 と SQL Server 2019
sudo curl -o /etc/yum.repos.d/mssql-server.repo https://packages.microsoft.com/config/rhel/8/mssql-server-2019.repo
sudo yum install -y mssql-server
sudo /opt/mssql/bin/mssql-conf setup
sudo yum install mssql-server-ha
リモート接続用にファイアウォール ポート 1433 を開く
リモートで接続するには、VM 上のポート 1433 を開く必要があります。 次のコマンドを使用して、各 VM のファイアウォールでポート 1433 を開きます。
sudo firewall-cmd --zone=public --add-port=1433/tcp --permanent
sudo firewall-cmd --reload
SQL Server コマンドライン ツールをインストールする
SQL Server コマンドライン ツールをインストールするには、次のコマンドを使用します。 詳細については、「SQL Server コマンドライン ツールをインストールする」を参照してください。
RHEL 7
sudo curl -o /etc/yum.repos.d/msprod.repo https://packages.microsoft.com/config/rhel/7/prod.repo
sudo yum install -y mssql-tools unixODBC-devel
RHEL 8
sudo curl -o /etc/yum.repos.d/msprod.repo https://packages.microsoft.com/config/rhel/8/prod.repo
sudo yum install -y mssql-tools unixODBC-devel
注
PATH 環境変数に /opt/mssql-tools/bin/ を追加すると便利です。 完全なパスを指定せずにツールを実行できます。 次のコマンドを実行して、ログイン セッションと対話型および非ログイン セッションの両方の PATH を変更します:echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profileecho 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrcsource ~/.bashrc
SQL Server の状態を確認する
構成が完了したら、SQL Server の状態を確認して、それが動作していることを確かめられます。
systemctl status mssql-server --no-pager
次の出力が表示されます。
● mssql-server.service - Microsoft SQL Server Database Engine
Loaded: loaded (/usr/lib/systemd/system/mssql-server.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2019-12-05 17:30:55 UTC; 20min ago
Docs: https://learn.microsoft.com/sql/linux
Main PID: 11612 (sqlservr)
CGroup: /system.slice/mssql-server.service
├─11612 /opt/mssql/bin/sqlservr
└─11640 /opt/mssql/bin/sqlservr
可用性グループを構成する
次の手順を使用して、対象の VM の SQL Server Always On 可用性グループを構成します。 詳細については、「Linux で高可用性を実現するために SQL Server の Always On 可用性グループを構成する」を参照してください。
Always On 可用性グループを有効にして mssql-server を再起動する
SQL Server インスタンスをホストする各ノードで Always On 可用性グループを有効にします。 次に、mssql-server を再起動します。 次のスクリプトを実行します。
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
証明書を作成する
現在、AG エンドポイントに対する AD 認証はサポートされていません。 そのため、AG エンドポイントの暗号化には証明書を使用する必要があります。
SQL Server Management Studio (SSMS) または sqlcmd を使用して、すべてのノードに接続します。 次のコマンドを実行して、AlwaysOn_health セッションを有効にし、マスター キーを作成します。
重要
自分の SQL Server インスタンスにリモートで接続する場合は、ファイアウォールでポート 1433 を開いておく必要があります。 さらに、各 VM の NSG でポート 1433 へのインバウンド接続を許可する必要があります。 インバウンド セキュリティ規則の作成の詳細については、「セキュリティ規則を作成する」を参照してください。
-
<password>は、実際のパスワードに置き換えます。
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';-
SSMS または sqlcmd を使用してプライマリ レプリカに接続します。 以下のコマンドを実行すると、プライマリ SQL Server レプリカの
/var/opt/mssql/data/dbm_certificate.cerに証明書が作成され、var/opt/mssql/data/dbm_certificate.pvkに秘密キーが作成されます。-
<password>は、実際のパスワードに置き換えます。
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<password>' ); GO-
コマンドを実行して exit セッションを終了し、SSH セッションに戻ります。
証明書をセカンダリ レプリカにコピーし、サーバー上に証明書を作成します
作成された 2 つのファイルを、可用性レプリカをホストするすべてのサーバー上の同じ場所にコピーします。
プライマリ サーバー上で次の
scpコマンドを実行して、証明書をターゲット サーバーにコピーします。-
<username>と<VM2>を、使用しているユーザー名とターゲット VM 名に置き換えます。 - すべてのセカンダリ レプリカに対してこのコマンドを実行します。
注
root 環境が提供される
sudo -iを実行する必要はありません。 このチュートリアルで以前に行ったように、各コマンドの前でsudoコマンドを実行するだけで済みます。# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@<VM2>:/home/<username>-
ターゲット サーバー上で、次のコマンドを実行します。
-
<username>は、実際のユーザー名に置き換えます。 -
mvコマンドにより、ある場所から別の場所にファイルまたはディレクトリが移動されます。 -
chownコマンドは、ファイル、ディレクトリ、またはリンクの所有者とグループを変更するために使用します。 - すべてのセカンダリ レプリカに対してこれらのコマンドを実行します。
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*-
次の Transact-SQL スクリプトでは、プライマリ SQL Server レプリカ上に作成したバックアップから証明書を作成します。 強力なパスワードでスクリプトを更新してください。 解読パスワードは、前の手順で .pvk ファイルの作成に使ったのと同じパスワードです。 証明書を作成するには、すべてのセカンダリ サーバーで sqlcmd または SSMS を使用して次のスクリプトを実行します。
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<password>' ); GO
すべてのレプリカにデータベース ミラーリング エンドポイントを作成する
sqlcmd または SSMS を使用して、すべての SQL Server インスタンスで次のスクリプトを実行します。
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
可用性グループを作成する
sqlcmd または SSMS を使用して、プライマリ レプリカをホストする SQL Server インスタンスに接続します。 次のコマンドを実行して、可用性グループを作成します。
-
ag1は、目的の可用性グループ名に置き換えます。 -
<VM1>、<VM2>、および<VM3>の値は、レプリカをホストする SQL Server インスタンスの名前に置き換えます。
CREATE AVAILABILITY GROUP [ag1]
WITH (DB_FAILOVER = ON, CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'<VM1>'
WITH (
ENDPOINT_URL = N'tcp://<VM1>:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<VM2>'
WITH (
ENDPOINT_URL = N'tcp://<VM2>:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<VM3>'
WITH(
ENDPOINT_URL = N'tcp://<VM3>:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
GO
Pacemaker 用の SQL Server ログインを作成する
すべての SQL Server インスタンスで、Pacemaker 用 SQL Server ログインを作成します。 次の Transact-SQL により、ログインが作成されます。
-
<password>は、独自の複雑なパスワードに置き換えます。
USE [master]
GO
CREATE LOGIN [pacemakerLogin] with PASSWORD= N'<password>';
GO
ALTER SERVER ROLE [sysadmin] ADD MEMBER [pacemakerLogin];
GO
すべての SQL Server インスタンスで、SQL Server ログインに使用される資格情報を保存します。
ファイルを作成します。
sudo vi /var/opt/mssql/secrets/passwd次の行をファイルに追加します。
pacemakerLogin <password>vi エディターを終了するには、まず Esc キーを押し、コマンド
:wqを入力してファイルを書き込み、終了します。ファイルが root によってのみ読み取り可能になるようにします。
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
セカンダリ レプリカを可用性グループに参加させる
セカンダリ レプリカを AG に参加させるには、すべてのサーバーのファイアウォールでポート 5022 を開く必要があります。 SSH セッションで次のコマンドを実行します。
sudo firewall-cmd --zone=public --add-port=5022/tcp --permanent sudo firewall-cmd --reload対象のセカンダリ レプリカで次のコマンドを実行して、AG に参加させます。
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOプライマリ レプリカと各セカンダリ レプリカで次の Transact-SQL スクリプトを実行します。
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GOセカンダリ レプリカを参加させたら、 [Always On 高可用性] ノードを展開して、SSMS オブジェクト エクスプローラーでそれらを確認できます。
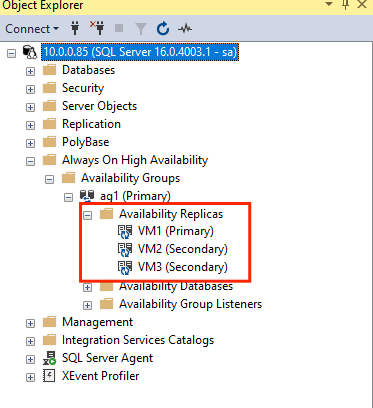
可用性グループにデータベースを追加する
データベースの追加については、可用性グループの構成に関する記事に従います。
この手順では、次の Transact-SQL コマンドを使用します。 プライマリ レプリカ上でこれらのコマンドを実行します。
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery model
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
セカンダリ サーバーにデータベースが作成されたことを確認する
各セカンダリ SQL Server レプリカで次のクエリを実行して、db1 データベースが作成され、SYNCHRONIZED 状態にあるかどうかを確認します。
SELECT * FROM sys.databases WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database', synchronization_state_desc FROM sys.dm_hadr_database_replica_states;
synchronization_state_desc に対して db1 が SYNCHRONIZED と示される場合は、レプリカが同期されていることを意味します。 セカンダリでは、プライマリ レプリカの db1 が表示されます。
Pacemaker クラスター内に可用性グループのリソースを作成する
ガイドに従って、Pacemaker クラスター内に可用性グループのリソースを作成します。
注
この記事には、Microsoft が使用しなくなったスレーブという用語への参照が含まれています。 ソフトウェアから用語が削除されると、この記事から削除されます。
AG クラスター リソースを作成する
先ほど選択した環境に応じて次のいずれかのコマンドを使用し、可用性グループ
ag_clusterにag1リソースを作成します。RHEL 7
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=ag1 meta failure-timeout=30s master notify=trueRHEL 8
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=ag1 meta failure-timeout=30s promotable notify=true次のコマンドを使用して、リソースがオンラインになっていることを確認してから、続行してください。
sudo pcs resource次の出力が表示されます。
RHEL 7
[<username>@VM1 ~]$ sudo pcs resource Master/Slave Set: ag_cluster-master [ag_cluster] Masters: [ <VM1> ] Slaves: [ <VM2> <VM3> ]RHEL 8
[<username>@VM1 ~]$ sudo pcs resource * Clone Set: ag_cluster-clone [ag_cluster] (promotable): * ag_cluster (ocf::mssql:ag) : Slave VMrhel3 (Monitoring) * ag_cluster (ocf::mssql:ag) : Master VMrhel1 (Monitoring) * ag_cluster (ocf::mssql:ag) : Slave VMrhel2 (Monitoring)
仮想 IP リソースを作成する
お使いのネットワークの使用可能な静的 IP アドレスを使用して、仮想 IP リソースを作成します。 これは、コマンド ツール
nmapを使用して見つけることができます。nmap -sP <IPRange> # For example: nmap -sP 10.0.0.* # The above will scan for all IP addresses that are already occupied in the 10.0.0.x space.stonith-enabled プロパティを false に設定します。
sudo pcs property set stonith-enabled=false次のコマンドを使用して、仮想 IP リソースを作成します。
<availableIP>値は、使用されていない IP アドレスに置き換えてください。sudo pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=<availableIP>
制約を追加する
IP アドレスと AG リソースが同じノードで実行するように、コロケーション制約を構成する必要があります。 次のコマンドを実行します。
RHEL 7
sudo pcs constraint colocation add virtualip ag_cluster-master INFINITY with-rsc-role=MasterRHEL 8
sudo pcs constraint colocation add virtualip with master ag_cluster-clone INFINITY with-rsc-role=Master順序制約を作成して、IP アドレスよりも前に AG リソースが稼働するようにします。 コロケーション制約により順序制約が暗黙に示されますが、これによって適用されます。
RHEL 7
sudo pcs constraint order promote ag_cluster-master then start virtualipRHEL 8
sudo pcs constraint order promote ag_cluster-clone then start virtualip制約を確認するには、次のコマンドを実行します。
sudo pcs constraint list --full次の出力が表示されます。
RHEL 7
Location Constraints: Ordering Constraints: promote ag_cluster-master then start virtualip (kind:Mandatory) (id:order-ag_cluster-master-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-master (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-master-INFINITY) Ticket Constraints:RHEL 8
Location Constraints: Ordering Constraints: promote ag_cluster-clone then start virtualip (kind:Mandatory) (id:order-ag_cluster-clone-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-clone (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-clone-INFINITY) Ticket Constraints:
stonith を再度有効にする
これで、テストの準備が整いました。 ノード 1 で次のコマンドを実行して、クラスターの stonith を再度有効にします。
sudo pcs property set stonith-enabled=true
クラスターの状態の確認
次のコマンドを使用して、クラスター リソースの状態を確認できます。
[<username>@VM1 ~]$ sudo pcs status
Cluster name: az-hacluster
Stack: corosync
Current DC: <VM3> (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum
Last updated: Sat Dec 7 00:18:38 2019
Last change: Sat Dec 7 00:18:02 2019 by root via cibadmin on VM1
3 nodes configured
5 resources configured
Online: [ <VM1> <VM2> <VM3> ]
Full list of resources:
Master/Slave Set: ag_cluster-master [ag_cluster]
Masters: [ <VM2> ]
Slaves: [ <VM1> <VM3> ]
virtualip (ocf::heartbeat:IPaddr2): Started <VM2>
rsc_st_azure (stonith:fence_azure_arm): Started <VM1>
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[テスト フェールオーバー]
これまでの構成が成功していることを確認するために、フェールオーバーをテストします。 詳細については、「Linux での Always On 可用性グループのフェールオーバー」を参照してください。
次のコマンドを実行して、プライマリ レプリカを
<VM2>に手動でフェールオーバーします。<VM2>は、実際のサーバー名の値に置き換えてください。RHEL 7
sudo pcs resource move ag_cluster-master <VM2> --masterRHEL 8
sudo pcs resource move ag_cluster-clone <VM2> --masterまた、リソースを目的のノードに移動するために作成された一時的な制約を自動的に無効にし、以下の手順の手順 2 および 3 を実行する必要がなくなるように、追加のオプションを指定することもできます。
RHEL 7
sudo pcs resource move ag_cluster-master <VM2> --master lifetime=30SRHEL 8
sudo pcs resource move ag_cluster-clone <VM2> --master lifetime=30Sまた、手順 2 および 3 を自動化する別の方法もあります。これにより、リソース移動コマンド自体で一時的な制約が解除されます。そのためには、複数のコマンドを 1 行に結合します。
RHEL 7
sudo pcs resource move ag_cluster-master <VM2> --master && sleep 30 && pcs resource clear ag_cluster-masterRHEL 8
sudo pcs resource move ag_cluster-clone <VM2> --master && sleep 30 && pcs resource clear ag_cluster-cloneもう一度制約を確認すると、手動フェールオーバーが理由で別の制約が追加されたことがわかります。
RHEL 7
[<username>@VM1 ~]$ sudo pcs constraint list --full Location Constraints: Resource: ag_cluster-master Enabled on: VM2 (score:INFINITY) (role: Master) (id:cli-prefer-ag_cluster-master) Ordering Constraints: promote ag_cluster-master then start virtualip (kind:Mandatory) (id:order-ag_cluster-master-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-master (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-master-INFINITY) Ticket Constraints:RHEL 8
[<username>@VM1 ~]$ sudo pcs constraint list --full Location Constraints: Resource: ag_cluster-master Enabled on: VM2 (score:INFINITY) (role: Master) (id:cli-prefer-ag_cluster-clone) Ordering Constraints: promote ag_cluster-clone then start virtualip (kind:Mandatory) (id:order-ag_cluster-clone-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-clone (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-clone-INFINITY) Ticket Constraints:次のコマンドを使用して、ID が
cli-prefer-ag_cluster-masterの制約を削除します。RHEL 7
sudo pcs constraint remove cli-prefer-ag_cluster-masterRHEL 8
sudo pcs constraint remove cli-prefer-ag_cluster-cloneコマンド
sudo pcs resourceを使用してクラスター リソースを確認すると、プライマリ インスタンスが<VM2>になっていることがわかります。[<username>@<VM1> ~]$ sudo pcs resource Master/Slave Set: ag_cluster-master [ag_cluster] ag_cluster (ocf::mssql:ag): FAILED <VM1> (Monitoring) Masters: [ <VM2> ] Slaves: [ <VM3> ] virtualip (ocf::heartbeat:IPaddr2): Started <VM2> [<username>@<VM1> ~]$ sudo pcs resource Master/Slave Set: ag_cluster-master [ag_cluster] Masters: [ <VM2> ] Slaves: [ <VM1> <VM3> ] virtualip (ocf::heartbeat:IPaddr2): Started <VM2>
フェンスをテストする
次のコマンドを実行して、フェンスをテストできます。
<VM1> に対して <VM3> から次のコマンドを実行してみてください。
sudo pcs stonith fence <VM3> --debug
注
既定のフェンス アクションでは、ノードをオフにしてからオンにします。 ノードをオフラインにするだけの場合は、コマンドでオプション --off を使用します。
次の出力が表示されます。
[<username>@<VM1> ~]$ sudo pcs stonith fence <VM3> --debug
Running: stonith_admin -B <VM3>
Return Value: 0
--Debug Output Start--
--Debug Output End--
Node: <VM3> fenced
フェンス デバイスのテストの詳細については、Red Hat に関する次の記事を参照してください。