この記事では、Azure Data Factory および Azure Synapse パイプラインのコピー アクティビティを使用して、Amazon RDS for SQL Server データベースからデータをコピーする方法について説明します。 詳細については、Azure Data Factory または Azure Synapse Analytics の概要記事を参照してください。
サポートされる機能
この Amazon RDS for SQL Server コネクタは、次の機能でサポートされます。
| サポートされる機能 | IR |
|---|---|
| コピー アクティビティ (ソース/-) | (1) (2) |
| ルックアップ アクティビティ | (1) (2) |
| GetMetadata アクティビティ | (1) (2) |
| ストアド プロシージャ アクティビティ | (1) (2) |
① Azure integration runtime ② セルフホステッド統合ランタイム
コピー アクティビティによってソースまたはシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関する記事の表をご覧ください。
具体的には、この Amazon RDS for SQL Server コネクタでは以下がサポートされています。
- SQL Server バージョン 2005 以降。
- SQL または Windows 認証を使用したデータのコピー。
- ソースとして、SQL クエリまたはストアド プロシージャを使用してデータを取得する。 Amazon RDS for SQL Server ソースからの並列コピーを選択することもできます。詳細については、「SQL データベースからの並列コピー」を参照してください。
SQL Server Express LocalDB はサポートされていません。
前提条件
データ ストアがオンプレ ミスネットワーク、Azure 仮想ネットワーク、または Amazon Virtual Private Cloud 内にある場合は、それに接続するようセルフホステッド統合ランタイムを構成する必要があります。
データ ストアがマネージド クラウド データ サービスである場合は、Azure Integration Runtime を使用できます。 ファイアウォール規則で承認されている IP にアクセスが制限されている場合は、Azure Integration Runtime の IP を許可リストに追加できます。
また、Azure Data Factory のマネージド仮想ネットワーク統合ランタイム機能を使用すれば、セルフホステッド統合ランタイムをインストールして構成しなくても、オンプレミス ネットワークにアクセスすることができます。
Data Factory によってサポートされるネットワーク セキュリティ メカニズムやオプションの詳細については、「データ アクセス戦略」を参照してください。
概要
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用できます。
- データのコピー ツール
- Azure Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- Azure Resource Manager テンプレート
UI を使用して Amazon RDS for SQL Server のリンク サービスを作成する
次の手順を使用して、Azure portal UI で Amazon RDS for SQL Server のリンク サービスを作成します。
Azure Data Factory または Synapse ワークスペースの [管理] タブに移動し、[リンク サービス] を選択して、[新規] をクリックします。
- Azureデータファクトリー
- Azure Synapse
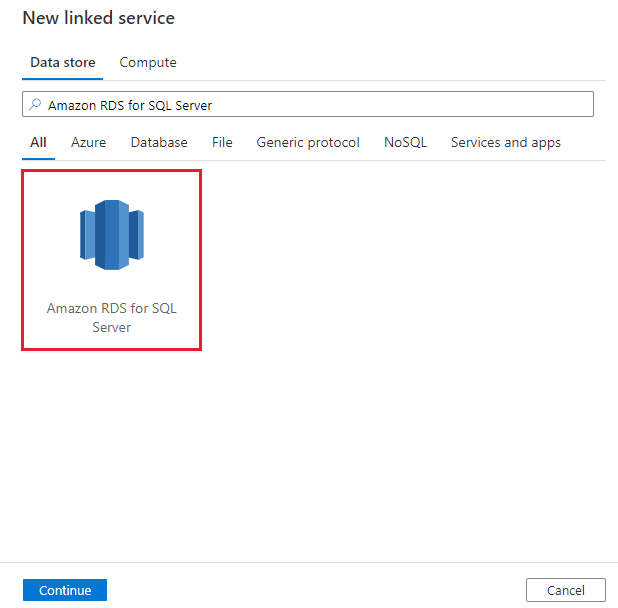
Amazon RDS for SQL Server を検索し、Amazon RDS for SQL Server コネクタを選択します。
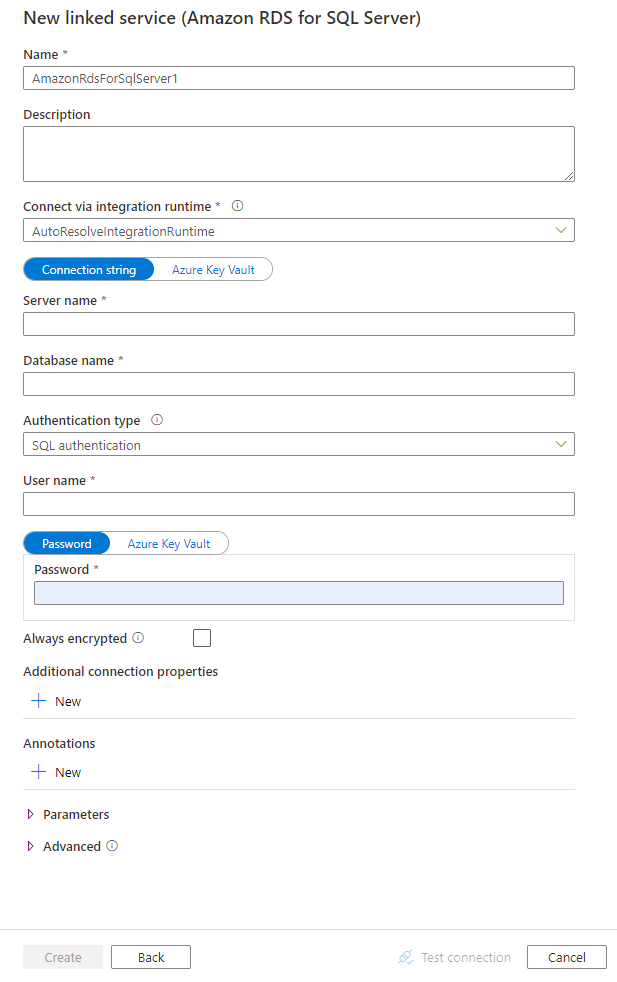
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
コネクタの構成の詳細
以下のセクションでは、Amazon RDS for SQL Server データベース コネクタに固有の Data Factory および Synapse パイプライン エンティティの定義に使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
Amazon RDS for SQL Server コネクタの推奨バージョンは、TLS 1.3 をサポートしています。 Amazon RDS for SQL Server コネクタのバージョンをレガシ バージョンからアップグレードするには、このセクションを参照してください。 プロパティの詳細については、対応するセクションを参照してください。
Note
Amazon RDS for SQL Server の Always Encrypted は、データ フローではサポートされていません。
ヒント
エラー コード "UserErrorFailedToConnectToSqlServer" および "The session limit for the database is XXX and has been reached" (データベースのセッション制限 XXX に達しました) のようなメッセージのエラーが発生する場合は、Pooling=false を接続文字列に追加して、もう一度試してください。
推奨されるバージョン
推奨バージョンを適用すると、Amazon RDS for SQL Server のリンク サービスで以下の汎用プロパティがサポートされます:
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | type プロパティは、AmazonRdsForSqlServer に設定する必要があります。 | はい |
| サーバー | 接続先の SQL Server インスタンスの名前またはネットワーク アドレス。 | はい |
| データベース | データベースの名前。 | はい |
| authenticationType | 認証に使用される型。 使用できる値は、SQL (既定値)、Windows です。 特定のプロパティと前提条件については、関連する認証セクションに移動します。 | はい |
| alwaysEncryptedSettings | マネージド ID またはサービス プリンシパルを使用して、Amazon RDS for SQL Server に格納されている機密データを保護する Always Encrypted を有効にするために必要な alwaysencryptedsettings 情報を指定します。 詳細については、この表の後にある JSON の例および「Always Encrypted の使用」を参照してください。 指定されていない場合、既定の always encrypted 設定は無効になります。 | いいえ |
| 暗号化する | クライアントとサーバーの間で送信されるすべてのデータに TLS 暗号化が必要かどうかを示します。 オプション: 必須 (true の場合、既定値)/省略可能 (false の場合)/strict。 | いいえ |
| trustServerCertificate | 信頼を検証するための証明書チェーンをバイパスする間、チャネルを暗号化するかどうかを示します。 | いいえ |
| hostNameInCertificate | 接続に対応するサーバー証明書を検証するときに使用するホスト名。 指定しない場合、サーバー名が証明書の検証に使用されます。 | いいえ |
| connectVia | この統合ランタイムは、データ ストアに接続するために使用されます。 詳細については、「前提条件」セクションを参照してください。 指定されていない場合は、既定の Azure Integration Runtime が使用されます。 | いいえ |
その他の接続プロパティについては、次の表を参照してください。
| プロパティ | 説明 | 必須 |
|---|---|---|
| applicationIntent | サーバーに接続するときのアプリケーション ワークロードのタイプ。 使用できる値は ReadOnly と ReadWrite です。 |
いいえ |
| connectTimeout | サーバーへの接続が確立されるまでに待機する時間 (秒) です。この時間が経過すると接続要求を終了し、エラーを生成します。 | いいえ |
| connectRetryCount | アイドル状態の接続エラーを特定した後に試行された再接続の数。 値は、0 から 255 の整数にする必要があります。 | いいえ |
| connectRetryInterval | アイドル状態の接続エラーが特定された後で、再接続を試行する時間間隔 (秒単位)。 値は、1 から 60 の整数にする必要があります。 | いいえ |
| loadBalanceTimeout | 接続プール内に維持されている接続が破棄されるまでの最短時間 (秒単位)。 | いいえ |
| commandTimeout | コマンド実行の試行を終了してエラーを生成するまでの既定の待機時間 (秒単位)。 | いいえ |
| integratedSecurity | 使用できる値は true または false です。
false を指定する場合は、接続の中で userName とパスワードが指定されているかどうかを示します。
true を指定する場合は、現在の Windows アカウントの資格情報が認証に使用されているかどうかを示します。 |
いいえ |
| failoverPartner | プライマリ サーバーがダウンした場合に接続先となるパートナー サーバーの名前またはアドレス。 | いいえ |
| maxPoolSize | 特定の接続文字列について、接続プール内で許可される最大接続数。 | いいえ |
| minPoolSize | 特定の接続文字列について、接続プール内で許可される最小接続数。 | いいえ |
| multipleActiveResultSets | 使用できる値は true または false です。
true を指定する場合、アプリケーションは複数のアクティブな結果セット (MARS) を保持できます。
false を指定する場合、その接続で他のバッチを実行するには、その前にアプリケーションは 1 つのバッチからのすべての結果セットを処理するか、取り消す必要があります。 |
いいえ |
| multiSubnetFailover | 使用できる値は true または false です。 アプリケーションが異なるサブネット上の AlwaysOn 可用性グループ (AG) に接続している場合、このプロパティを true に設定すると、現在アクティブなサーバーの検出と接続が速くなります。 |
いいえ |
| packetSize | サーバーのインスタンスと通信するために使用するネットワーク パケットのサイズ (バイト単位)。 | いいえ |
| pooling | 使用できる値は true または false です。
true を指定すると、接続がプールされます。
false を指定すると、接続が要求されるたびに接続が明示的に開かれます。 |
いいえ |
SQL 認証
前のセクションで説明した汎用的なプロパティに加えて、SQL 認証を使用するには、以下のプロパティを指定します:
| プロパティ | 説明 | 必須 |
|---|---|---|
| userName | サーバーへの接続に使用されるユーザー名。 | はい |
| パスワード | 該当するユーザー名のパスワード。 安全に保存するには、このフィールドを SecureString としてマークします。 また、Azure Key Vault に格納されているシークレットを参照することもできます。 | はい |
例: SQL 認証を使用する
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
例: Azure Key Vault 内のパスワードで SQL 認証を使用する
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
例: Always Encrypted の使用
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Windows 認証
前のセクションで説明した汎用的なプロパティに加えて、Windows 認証を使用するには、次のプロパティを指定します。
| プロパティ | 説明 | 必須 |
|---|---|---|
| userName | ユーザー名を指定します。 例: domainname\username。 | はい |
| パスワード | ユーザー名に指定したユーザー アカウントのパスワードを指定します。 安全に保存するには、このフィールドを SecureString としてマークします。 また、Azure Key Vault に格納されているシークレットを参照することもできます。 | はい |
例: Windows 認証を使用する
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
レガシ バージョン
レガシ バージョンを適用すると、Amazon RDS for SQL Server のリンク サービスで以下の汎用プロパティがサポートされます:
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | type プロパティは、AmazonRdsForSqlServer に設定する必要があります。 | はい |
| alwaysEncryptedSettings | マネージド ID またはサービス プリンシパルを使用して、Amazon RDS for SQL Server に格納されている機密データを保護する Always Encrypted を有効にするために必要な alwaysencryptedsettings 情報を指定します。 詳しくは、「Always Encrypted の使用」セクションをご覧ください。 指定されていない場合、既定の always encrypted 設定は無効になります。 | いいえ |
| connectVia | この統合ランタイムは、データ ストアに接続するために使用されます。 詳細については、「前提条件」セクションを参照してください。 指定されていない場合は、既定の Azure Integration Runtime が使用されます。 | いいえ |
この Amazon RDS for SQL Server コネクタでは、以下の認証の種類がサポートされています。 詳細については、対応するセクションをご覧ください。
レガシ バージョンの SQL 認証
前のセクションで説明した汎用的なプロパティに加えて、SQL 認証を使用するには、以下のプロパティを指定します:
| プロパティ | 説明 | 必須 |
|---|---|---|
| connectionString | Amazon RDS for SQL Server データベースに接続するために必要な connectionString 情報を指定します。 ユーザー名としてログイン名を指定し、接続するデータベースがこのログインにマップされていることを確認します。 | はい |
| パスワード | パスワードを Azure Key Vault に格納する場合、接続文字列から password 構成をプルします。 詳細については、「Azure Key Vault への資格情報の格納」を参照してください。 |
いいえ |
レガシ バージョンの Windows 認証
前のセクションで説明した汎用的なプロパティに加えて、Windows 認証を使用するには、次のプロパティを指定します。
| プロパティ | 説明 | 必須 |
|---|---|---|
| connectionString | Amazon RDS for SQL Server データベースに接続するために必要な connectionString 情報を指定します。 | はい |
| userName | ユーザー名を指定します。 例: domainname\username。 | はい |
| パスワード | ユーザー名に指定したユーザー アカウントのパスワードを指定します。 安全に保存するには、このフィールドを SecureString としてマークします。 また、Azure Key Vault に格納されているシークレットを参照することもできます。 | はい |
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。 このセクションでは、Amazon RDS for SQL Server データセットでサポートされるプロパティの一覧を示します。
Amazon RDS for SQL Server データベースからデータをコピーするために、次のプロパティがサポートされています。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | データセットの type プロパティは、AmazonRdsForSqlServerTable に設定する必要があります。 | はい |
| スキーマ | スキーマの名前。 | いいえ |
| テーブル | テーブル/ビューの名前。 | いいえ |
| tableName | スキーマがあるテーブル/ビューの名前。 このプロパティは下位互換性のためにサポートされています。 新しいワークロードでは、schema と table を使用します。 |
いいえ |
例
{
"name": "AmazonRdsForSQLServerDataset",
"properties":
{
"type": "AmazonRdsForSqlServerTable",
"linkedServiceName": {
"referenceName": "<Amazon RDS for SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
コピー アクティビティのプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、Amazon RDS for SQL Server ソースでサポートされるプロパティの一覧を示します。
ソースとしての Amazon RDS for SQL Server
ヒント
データ パーティション分割を使用して、Amazon RDS for SQL Server からデータを効率的に読み込む方法の詳細については、「SQL データベースからの並列コピー」を参照してください。
Amazon RDS for SQL Server からデータをコピーするには、コピー アクティビティのソースの種類を AmazonRdsForSqlServerSource に設定します。 コピー アクティビティの source セクションでは、次のプロパティがサポートされます。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | コピー アクティビティのソースの type プロパティは、AmazonRdsForSqlServerSource に設定する必要があります。 | はい |
| sqlReaderQuery | カスタム SQL クエリを使用してデータを読み取ります。 たとえば select * from MyTable です。 |
いいえ |
| sqlReaderStoredProcedureName | このプロパティは、ソース テーブルからデータを読み取るストアド プロシージャの名前です。 最後の SQL ステートメントはストアド プロシージャの SELECT ステートメントにする必要があります。 | いいえ |
| storedProcedureParameters | これらのパラメーターは、ストアド プロシージャ用です。 使用可能な値は、名前または値のペアです。 パラメーターの名前とその大文字と小文字は、ストアド プロシージャのパラメーターの名前とその大文字小文字と一致する必要があります。 |
いいえ |
| isolationLevel | SQL ソースのトランザクション ロック動作を指定します。 使用できる値は、ReadCommitted、ReadUncommitted、RepeatableRead、Serializable、Snapshot です。 指定しない場合、データベースの既定の分離レベルが使用されます。 詳細についてはこちらのドキュメントをご覧ください。 | いいえ |
| partitionOptions | Amazon RDS for SQL Server からのデータの読み込みに使用されるデータ パーティション分割オプションを指定します。 使用できる値は、None (既定値)、PhysicalPartitionsOfTable、DynamicRange です。 パーティション オプションが有効になっている場合 (つまり、 None ではない場合)、Amazon RDS for SQL Server から同時にデータを読み込む並列処理の次数は、コピー アクティビティの parallelCopies 設定によって制御されます。 |
いいえ |
| partitionSettings | データ パーティション分割の設定のグループを指定します。 パーティション オプションが None でない場合に適用されます。 |
いいえ |
partitionSettings の下: |
||
| partitionColumnName | 並列コピーの範囲パーティション分割で使用される整数型または日付/日時型 (int、smallint、bigint、date、smalldatetime、datetime、datetime2、または datetimeoffset) のソース列の名前を指定します。 指定されない場合は、テーブルのインデックスまたは主キーが自動検出され、パーティション列として使用されます。パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?DfDynamicRangePartitionCondition をフックします。 例については、「SQL データベースからの並列コピー」セクションを参照してください。 |
いいえ |
| partitionUpperBound | パーティション範囲の分割のための、パーティション列の最大値。 この値は、テーブル内の行のフィルター処理用ではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果に含まれるすべての行がパーティション分割され、コピーされます。 指定されていない場合は、コピー アクティビティによって値が自動検出されます。 パーティション オプションが DynamicRange である場合に適用されます。 例については、「SQL データベースからの並列コピー」セクションを参照してください。 |
いいえ |
| partitionLowerBound | パーティション範囲の分割のための、パーティション列の最小値。 この値は、テーブル内の行のフィルター処理用ではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果に含まれるすべての行がパーティション分割され、コピーされます。 指定されていない場合は、コピー アクティビティによって値が自動検出されます。 パーティション オプションが DynamicRange である場合に適用されます。 例については、「SQL データベースからの並列コピー」セクションを参照してください。 |
いいえ |
以下の点に注意してください:
- AmazonRdsForSqlServerSource に sqlReaderQuery が指定されている場合、コピー アクティビティでは、データを取得するために Amazon RDS for SQL Server ソースに対してこのクエリを実行します。 sqlReaderStoredProcedureName と storedProcedureParameters を指定して、ストアド プロシージャを指定することもできます (ストアド プロシージャでパラメーターを使用する場合)。
- ソースのストアド プロシージャを使用してデータを取得する場合、異なるパラメーター値が渡されたときに別のスキーマを返すようにストアド プロシージャが設計されていると、UI からスキーマをインポートするときや、テーブルの自動作成を使用して SQL データベースにデータをコピーするときに、エラーが発生したり、予期しない結果になったりする可能性があります。
例: SQL クエリを使用する
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
例: ストアド プロシージャを使用する
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
ストアド プロシージャの定義
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
SQL データベースからの並列コピー
Amazon RDS for SQL Server コネクタでは、コピー アクティビティの際に、データを並列でコピーするための組み込みのデータ パーティション分割が提供されます。 データ パーティション分割オプションは、コピー アクティビティの [ソース] タブにあります。
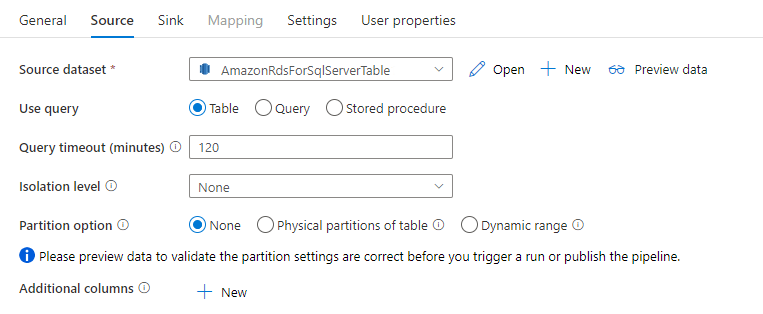
パーティション分割されたコピーを有効にすると、コピー アクティビティによって Amazon RDS for SQL Server ソースに対する並列クエリが実行され、パーティションごとにデータが読み込まれます。 並列度は、コピー アクティビティの parallelCopies 設定によって制御されます。 たとえば、parallelCopies を 4 に設定した場合、指定したパーティション オプションと設定に基づいて 4 つのクエリが同時に生成され、実行されます。各クエリでは、Amazon RDS for SQL Server からデータの一部を取得します。
特に、Amazon RDS for SQL Server から大量のデータを読み込む場合は、データ パーティション分割を使用した並列コピーを有効にすることをお勧めします。 さまざまなシナリオの推奨構成を以下に示します。 ファイルベースのデータ ストアにデータをコピーする場合は、複数のファイルとしてフォルダーに書き込む (フォルダー名のみを指定する) ことをお勧めします。この場合、1 つのファイルに書き込むよりもパフォーマンスが優れています。
| シナリオ | 推奨設定 |
|---|---|
| 物理パーティションに分割された大きなテーブル全体から読み込む。 |
パーティション オプション: テーブルの物理パーティション。 実行中に、サービスによって物理パーティションが自動的に検出され、パーティションごとにデータがコピーされます。 テーブルに物理パーティションがあるかどうかを確認するには、こちらのクエリを参照してください。 |
| 物理パーティションがなく、データ パーティション分割用の整数または日時の列がある大きなテーブル全体から読み込む。 |
パーティション オプション: ダイナミック レンジ パーティション。 パーティション列 (省略可能): データのパーティション分割に使用する列を指定します。 指定されていない場合は、主キー列が使用されます。 パーティションの上限とパーティションの下限 (省略可能): パーティション ストライドを決定する場合に指定します。 これは、テーブル内の行のフィルター処理用ではなく、テーブル内のすべての行がパーティション分割されてコピーされます。 指定されていない場合は、Copy アクティビティによって値が自動検出されます。最小値と最大値によっては時間がかかることがあります。 上限と下限を指定することをお勧めします。 たとえば、パーティション列「ID」の値の範囲が 1 ~ 100 で、下限を 20 に、上限を 80 に設定し、並列コピーを 4 にした場合、サービスによって 4 つのパーティションでデータが取得されます。ID の範囲は、それぞれ、20 以下、21 ~ 50、51 ~ 80、81 以上となります。 (Please delete < and > tags). |
| 物理パーティションがなく、データ パーティション分割用の整数列または日付/日時列がある大量のデータを、カスタム クエリを使用して読み込む。 |
パーティション オプション: ダイナミック レンジ パーティション。 クエリ: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>。パーティション列: データのパーティション分割に使用される列を指定します。 パーティションの上限とパーティションの下限 (省略可能): パーティション ストライドを決定する場合に指定します。 これは、テーブル内の行のフィルター処理用ではなく、クエリ結果のすべての行がパーティション分割されてコピーされます。 指定されていない場合は、コピー アクティビティによって値が自動検出されます。 たとえば、パーティション列「ID」の値の範囲が 1 ~ 100 で、下限を 20 に、上限を 80 に設定し、並列コピーを 4 にした場合、サービスによって 4 つのパーティションでデータが取得されます。ID の範囲は、それぞれ、20 以下、21 ~ 50、51 ~ 80、81 以上となります。 (Please delete < and > tags). さまざまなシナリオのサンプル クエリを次に示します。 1.テーブル全体に対してクエリを実行する: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2.列の選択と追加の where 句フィルターが含まれるテーブルからのクエリ: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3.サブクエリを使用したクエリ: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4.サブクエリにパーティションがあるクエリ: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
パーティション オプションを使用してデータを読み込む場合のベスト プラクティス:
- データ スキューを回避するため、パーティション列 (主キーや一意キーなど) には特徴のある列を選択します。
- テーブルに組み込みパーティションがある場合は、パフォーマンスを向上させるためにパーティション オプションとして "テーブルの物理パーティション" を使用します。
- Azure Integration Runtime を使用してデータをコピーする場合は、より大きな (4 より大きい) "データ統合単位 (DIU)" (>4) を設定すると、より多くのコンピューティング リソースを利用できます。 そこで、該当するシナリオを確認してください。
- パーティション数は、"コピーの並列処理の次数" によって制御されます。この数値を大きくしすぎるとパフォーマンスが低下するため、この数値は、(DIU またはセルフホステッド IR ノードの数) x (2 から 4) に設定することをお勧めします。
例: 複数の物理パーティションがある大きなテーブル全体から読み込む
"source": {
"type": "AmazonRdsForSqlServerSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
例: 動的範囲パーティションを使用してクエリを実行する
"source": {
"type": "AmazonRdsForSqlServerSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
物理パーティションを確認するためのサンプル クエリ
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
テーブルに物理パーティションがある場合、次のように、"HasPartition" は "yes" と表示されます。

Amazon RDS for SQL Server のデータ型マッピング
Amazon RDS for SQL Server からデータをコピーする場合、Amazon RDS for SQL Server のデータ型から、サービスによって内部的に使用される中間データ型へのマッピングが使用されます。 コピー アクティビティでソースのスキーマとデータ型がシンクにマッピングされるしくみについては、スキーマとデータ型のマッピングに関する記事を参照してください。
| Amazon RDS for SQL Server のデータ型 | 中間サービス データ型 |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | ブール値 |
| char | String、Char[] |
| date | DateTime |
| 日時 | DateTime |
| datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM 属性(varbinary(max)) | Byte[] |
| Float | Double |
| イメージ | Byte[] |
| 整数 (int) | Int32 |
| money | Decimal |
| nchar | String、Char[] |
| ntext | String、Char[] |
| numeric | Decimal |
| nvarchar(エヌヴァーチャー) | String、Char[] |
| real | シングル |
| rowversion | Byte[] |
| smalldatetime | DateTime |
| smallint(スモールイント) | Int16 |
| 少額のお金 | Decimal |
| sql_variant | Object |
| SMS 送信 | String、Char[] |
| time | TimeSpan |
| timestamp | Byte[] |
| tinyint | Int16 |
| uniqueidentifier | Guid |
| varbinary | Byte[] |
| varchar | String、Char[] |
| XML | 糸 |
Note
10 進の中間型にマップされるデータ型の場合、コピー アクティビティでは、現在、最大 28 の有効桁数がサポートされています。 28 よりも大きな有効桁数を必要とするデータがある場合は、SQL クエリで文字列に変換することを検討してください。
Azure Data Factory を使用して Amazon RDS for SQL Server からデータをコピーする場合、ビット データ型はブール中間データ型にマップされます。 bit データ型として保持する必要があるデータがある場合は、T-SQL CAST または CONVERT を使用したクエリを使用します。
Lookup アクティビティのプロパティ
プロパティの詳細については、Lookup アクティビティに関するページを参照してください。
GetMetadata アクティビティのプロパティ
プロパティの詳細については、GetMetadata アクティビティに関するページを参照してください。
Always Encrypted の使用
Always Encrypted を使用して Amazon RDS for SQL Server との間でデータをコピーする場合は、次の手順に従います。
列マスター キー (CMK) を Azure Key Vault に保存します。 詳細については、Azure Key Vault を使用して Always Encrypted を構成する方法に関する記事を参照してください
列マスター キー (CMK) が格納されているキー コンテナーへのアクセス権を付与します。 必要なアクセス許可については、こちらの記事を参照してください。
リンク サービスを作成して SQL データベースに接続し、マネージド ID またはサービス プリンシパルを使用して "Always Encrypted" 機能を有効にします。
接続の問題のトラブルシューティング
リモート接続を受け入れるように、Amazon RDS for SQL Server インスタンスを構成します。 Amazon RDS for SQL Server Management Studio を起動し、サーバーを右クリックして、 [プロパティ] を選択します。 一覧から [接続] を選択し、[このサーバーへのリモート接続を許可する] チェック ボックスをオンにします。
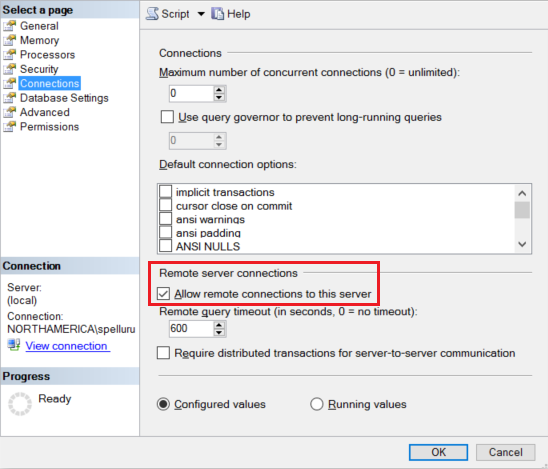
詳細な手順については、「remote access サーバー構成オプションの構成」をご覧ください。
Amazon RDS for SQL Server 構成マネージャー を起動します。 目的のインスタンスの [Amazon RDS for SQL Server ネットワークの構成] を展開し、 [MSSQLSERVER のプロトコル] を選択します。 右側のウィンドウにプロトコルが表示されます。 [TCP/IP] を右クリックして [有効化] を選択し、TCP/IP を有効にします。
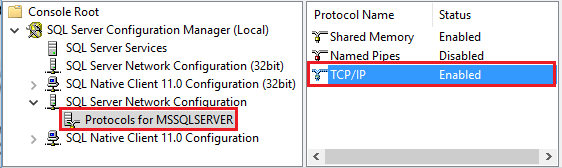
TCP/IP プロトコルの有効化の詳細および別の方法については、「サーバー ネットワーク プロトコルの有効化または無効化」をご覧ください。
同じウィンドウで、[TCP/IP] をダブルクリックして、[TCP/IP のプロパティ] ウィンドウを起動します。
[IP アドレス] タブに切り替えます。下にスクロールして、[IPAll] セクションを表示します。 [TCP ポート] を書き留めます。 既定値は 1433 です。
コンピューターに Windows Firewall のルール を作成し、このポート経由の受信トラフィックを許可します。
接続の確認: 完全修飾名を使用して Amazon RDS for SQL Server に接続するには、別のマシンから Amazon RDS for SQL Server Management Studio を使用します。 たとえば
"<machine>.<domain>.corp.<company>.com,1433"です。
Amazon RDS for SQL Server のバージョンをアップグレードする
Amazon RDS for SQL Server のバージョンをアップグレードするには、[Edit linked service (リンク サービスの編集)] ページで [Version (バージョン)] の [Recommended (推奨)] を選択し、[Linked service properties for the recommended version (推奨バージョンのリンク サービス プロパティ)]を参照してリンク サービスを構成します。
推奨バージョンとレガシ バージョンの違い
次の表は、推奨バージョンを使用した場合と、レガシ バージョンを使用した場合の Amazon RDS for SQL Server の違いを示しています。
| 推奨されるバージョン | レガシ バージョン |
|---|---|
encrypt を strict と指定すると TLS 1.3 をサポートします。 |
TLS 1.3 には対応していません。 |
関連コンテンツ
コピー アクティビティによってソースおよびシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するセクションを参照してください。