適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
この記事では、ファイル システムをコピー先またはコピー元としてデータをコピーする方法について説明します。 詳細については、Azure Data Factory または Azure Synapse Analytics の入門記事を参照してください。
サポートされる機能
このファイル システム コネクタでは、次の機能がサポートされます。
| サポートされる機能 | IR |
|---|---|
| Copy アクティビティ (ソース/シンク) | (1) (2) |
| ルックアップ アクティビティ | (1) (2) |
| GetMetadata アクティビティ | (1) (2) |
| Delete アクティビティ | (1) (2) |
(1) Azure統合ランタイム (2) セルフホステッド統合ランタイム
具体的には、このファイル システム コネクタは以下をサポートします。
- ネットワーク ファイル共有をコピー元またはコピー先とするファイルのコピー。 Linux ファイル共有を使用するには、Linux サーバーに Samba をインストールします。
- 基本認証を使用したファイルのコピー。
- ファイルをそのままコピーするか、サポートされているファイル形式と圧縮コーデックを使用したファイルの解析/生成。
前提条件
データ ストアがオンプレミス ネットワーク、Azure仮想ネットワーク、または Amazon Virtual Private Cloud 内にある場合は、自身がホストする統合ランタイム を構成して接続する必要があります。
データ ストアがマネージド クラウド データ サービスの場合は、Azure Integration Runtimeを使用できます。 アクセスがファイアウォール規則で承認されている IP に制限されている場合は、許可リストに Azure Integration Runtime IP を追加できます。
Azure Data Factoryの 管理された仮想ネットワーク統合ランタイム機能を使用して、セルフホステッド統合ランタイムをインストールして構成することなく、オンプレミス ネットワークにアクセスすることもできます。
Data Factory によってサポートされるネットワーク セキュリティ メカニズムやオプションの詳細については、「データ アクセス戦略」を参照してください。
概要
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用できます。
- データのコピー ツール
- Azure Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- Azure Resource Manager テンプレート
UI を使用してファイル システムのリンク サービスを作成する
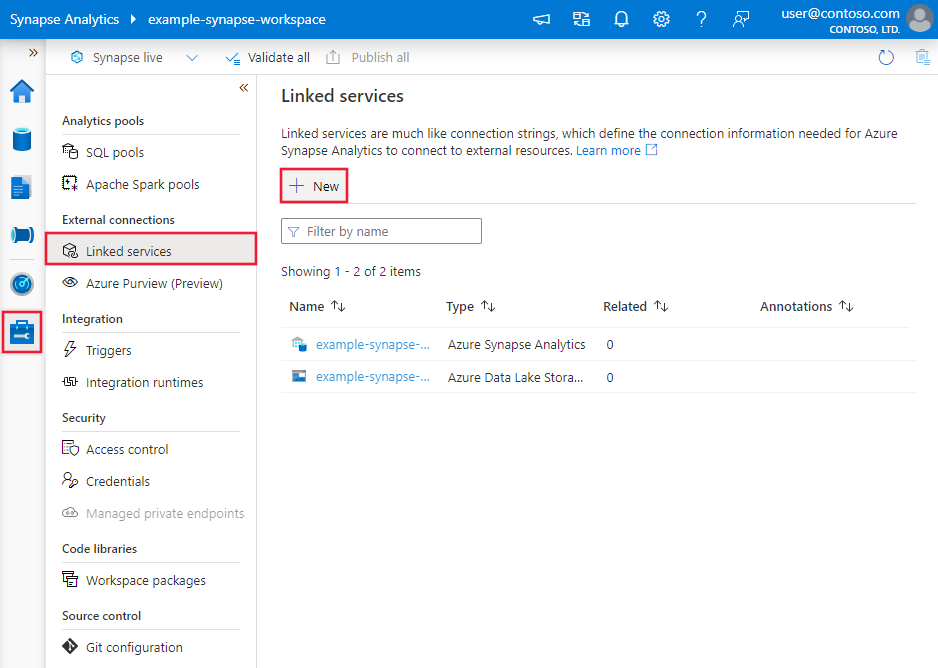
Azure ポータル UI でファイル システムのリンクされたサービスを作成するには、次の手順に従います。
Azure Data Factoryまたは Synapse ワークスペースの [管理] タブを参照し、[リンクされたサービス] を選択し、[新規] を選択します。
- Azureデータファクトリー
- Azure Synapse
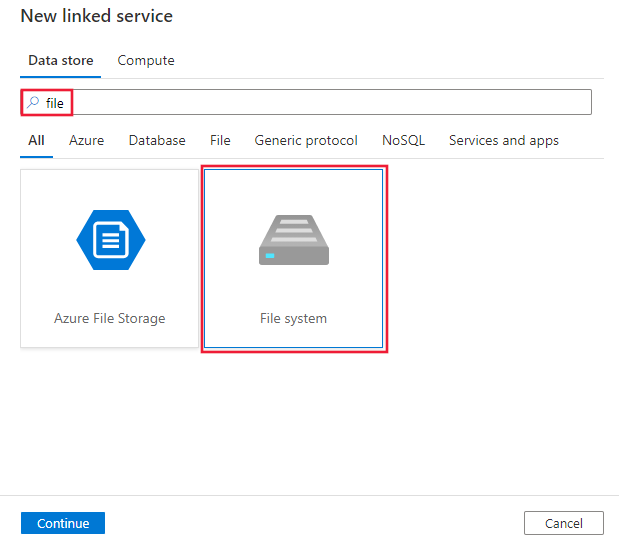
Azure Data Factory UI を使用した新しいリンク サービスの作成のスクリーンショット ファイルを検索し、ファイル システム コネクタを選択します。
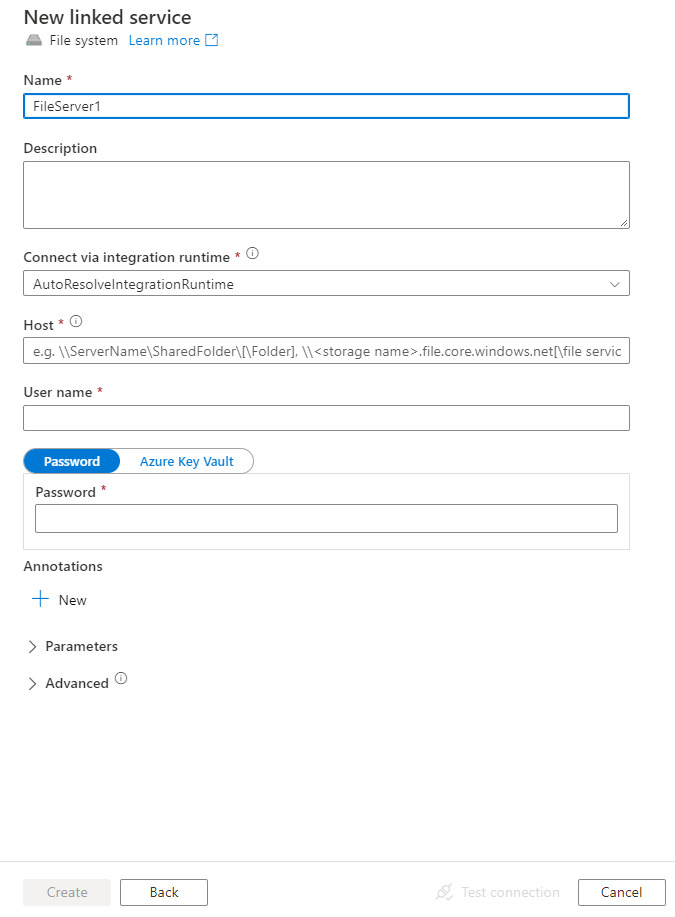
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
コネクタの構成の詳細
以下のセクションでは、ファイル システムに固有の Data Factory および Synapse パイプライン エンティティの定義に使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
ファイル システムの のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | type プロパティは、次のように設定する必要があります:FileServer. | はい |
| ホスティング | コピーするフォルダーのルート パスを指定します。 文字列内の特殊文字にはエスケープ文字 "" を使用します。 例については、「 サンプルのリンクされたサービスとデータセットの定義 」ご覧ください。 | はい |
| userId | サーバーにアクセスするユーザーの ID を指定します。 | はい |
| パスワード | ユーザー (userId) のパスワードを指定します。 このフィールドを SecureString としてマークして安全に格納するか、 |
はい |
| connectVia | データ ストアへの接続に使用するIntegration Runtime。 詳細については、「前提条件」セクションを参照してください。 指定しない場合は、既定のAzure Integration Runtimeが使用されます。 | いいえ |
サンプルのリンクされたサービスとデータセットの定義
| シナリオ | リンクされたサービス定義の "host" | データセット定義の "folderPath" |
|---|---|---|
| リモート共有フォルダー: 例: \\myserver\share\* または \\myserver\share\folder\subfolder\* |
JSON の場合: \\\\myserver\\shareUI の場合: \\myserver\share |
JSON の場合: .\\ または folder\\subfolderUI の場合: .\ または folder\subfolder |
Note
UI を使用して作成する場合、JSON のように、エスケープするために二重バックスラッシュ (\\) を入力する必要はなく、単一のバックスラッシュを指定します。
Note
Azure Integration Runtimeでは、ローカル コンピューターからのファイルのコピーはサポートされていません。
セルフホステッド統合ランタイムでローカル コンピューターへのアクセスを有効にするには、こちらからコマンド ラインを参照してください。 これは既定で無効になっています。
例:
{
"name": "FileLinkedService",
"properties": {
"type": "FileServer",
"typeProperties": {
"host": "<host>",
"userId": "<domain>\\<user>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。
Azure Data Factoryでは、次のファイル形式がサポートされています。 形式ベースの設定については、各記事を参照してください。
ファイル システムでは、形式ベースのデータセットの location 設定において、次のプロパティがサポートされています。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | データセットの location の type プロパティは、FileServerLocation に設定する必要があります。 |
はい |
| folderPath | フォルダーのパス。 フォルダーをフィルター処理するためにワイルドカードを使用する場合は、この設定をスキップし、アクティビティのソースの設定で指定します。 共有用のフォルダーを公開するには、Windowsまたは Linux 環境でファイル共有の場所を設定する必要があります。 | いいえ |
| fileName | 特定の folderPath の下のファイル名。 ファイルをフィルター処理するためにワイルドカードを使用する場合は、この設定をスキップし、アクティビティのソースの設定で指定します。 | いいえ |
例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<File system linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "FileServerLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Copy activity のプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、ファイル システムのソースとシンクでサポートされるプロパティの一覧を示します。
ソースとしてのファイル システム
Azure Data Factoryでは、次のファイル形式がサポートされています。 形式ベースの設定については、各記事を参照してください。
ファイル システムでは、形式ベースのコピー ソースの storeSettings 設定において、次のプロパティがサポートされています。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 |
storeSettings の type プロパティは FileServerReadSettings に設定する必要があります。 |
はい |
| コピーするファイルを特定する: | ||
| オプション 1: 静的パス |
データセットに指定されている所定のフォルダーまたはファイル パスからコピーします。 フォルダーからすべてのファイルをコピーする場合は、さらに wildcardFileName として * を指定します。 |
|
| オプション 2: サーバー側のフィルター -Filefilter |
オプション 3 のワイルドカード フィルターより優れたパフォーマンスを提供する、ファイル サーバー側のネイティブ フィルター。 0 個以上の文字に一致させるには * を使用し、0 または 1 文字に一致させるには ? を使用します。 詳細および注については、このセクションの下部の「解説」を参照してください。 |
いいえ |
| オプション 3: クライアント側のフィルター - ワイルドカードフォルダパス |
ソース フォルダーをフィルター処理するための、ワイルドカード文字を含むフォルダー パス。 このようなフィルター処理はサービス内で実行されます。指定されたパスにあるフォルダーまたはファイルが列挙され、その後、ワイルドカード フィルターが適用されます。 使用できるワイルドカーは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。実際のフォルダー名にワイルドカードまたはこのエスケープ文字が含まれている場合は、^ を使用してエスケープします。 「フォルダーとファイル フィルターの例」の他の例をご覧ください。 |
いいえ |
| オプション 3: クライアント側のフィルター - ワイルドカードファイル名 |
ソース ファイルをフィルター処理するための、特定の folderPath/wildcardFolderPath の下のワイルドカード文字を含むファイル名。 このようなフィルター処理はサービス内で行われます。指定されたパスにあるファイルが列挙され、ワイルドカード フィルターが適用されます。 使用できるワイルドカーは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。実際のファイル名にワイルドカードまたはこのエスケープ文字が含まれている場合は、^ を使用してエスケープします。「フォルダーとファイル フィルターの例」の他の例をご覧ください。 |
はい |
| オプション 3: ファイルの一覧 - fileListPath(ファイルリストのパス) |
指定されたファイル セットをコピーすることを示します。 コピーするファイルの一覧を含むテキスト ファイルをポイントします。データセットで構成されているパスへの相対パスであるファイルを 1 行につき 1 つずつ指定します。 このオプションを使用する場合は、データ セット内でファイル名を指定しないでください。 その他の例については、ファイル リストの例を参照してください。 |
いいえ |
| 追加の設定: | ||
| recursive | データをサブフォルダーから再帰的に読み取るか、指定したフォルダーからのみ読み取るかを指定します。 recursive が true に設定されていて、シンクがファイル ベースのストアである場合、空のフォルダーまたはサブフォルダーはシンクでコピーも作成もされません。 使用可能な値: true (既定値) および false。 fileListPath を構成する場合、このプロパティは適用されません。 |
いいえ |
| deleteFilesAfterCompletion | バイナリ ファイルを宛先ストアに正常に移動した後、それらのバイナリ ファイルをソース ストアから削除するかどうかを示します。 ファイルの削除はファイルごとに行われます。 つまり、アクティビティが失敗した場合、一部のファイルは既にコピー先にコピーされて、ソースから削除されています。一方で、他のファイルはまだソース ストアに残されています。 このプロパティは、バイナリ ファイルのコピー シナリオでのみ有効です。 既定値: false。 |
いいえ |
| modifiedDatetimeStart | 最終変更日時属性に基づくファイル フィルター。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選ばれます。 時刻は、YYYY-MM-DDTHH:mm:ssZ の形式で UTC タイム ゾーンに適用されます。 各プロパティには NULL を指定できます。これは、ファイル属性フィルターをデータセットに適用しないことを意味します。 modifiedDatetimeStart で datetime 値を設定し、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値と同じまたはそれより後であるファイルが選択されます。
modifiedDatetimeEnd で datetime 値を設定し、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値より前であるファイルが選択されます。fileListPath を構成する場合、このプロパティは適用されません。 |
いいえ |
| modifiedDatetimeEnd | modifiedDateTimeStart と同じです。 | いいえ |
| enablePartitionDiscovery | パーティション分割されているファイルの場合、ファイル パスのパーティションを解析し、それを追加のソース列として追加するかどうかを指定します。 指定できる値は false (既定値) と true です。 |
いいえ |
| partitionRootPath | パーティション検出が有効になっている場合は、パーティション分割されたフォルダーをデータ列として読み取るための絶対ルート パスを指定します。 これを指定していない場合は、既定で次のようになります。 - ソース上のデータセットまたはファイルの一覧内のファイル パスを使用する場合、パーティションのルート パスはそのデータセットで構成されているパスです。 - ワイルドカード フォルダー フィルターを使用する場合、最初のワイルドカードより前のサブパスが、パーティションのルート パスになります。 たとえば、データセット内のパスを "root/folder/year=2020/month=08/day=27" として構成するとします。 - パーティションのルート パスを "root/folder/year=2020" として指定した場合は、Copy アクティビティによって、ファイル内の列に加え、それぞれ "08" や "27" という値を持つ、 month や day という 2 つの追加の列が生成されます。- パーティションのルート パスを指定していない場合、追加の列は生成されません。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されるコンカレント接続数の上限。 コンカレント接続数を制限する場合にのみ、値を指定します。 | いいえ |
例:
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "FileServerReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
シンクとしてのファイル システム
Azure Data Factoryでは、次のファイル形式がサポートされています。 形式ベースの設定については、各記事を参照してください。
Note
MergeFilescopyBehavior オプションは、Synapse Analytics パイプラインではなく、Azure Data Factory パイプラインでのみ使用できます。
ファイル システムでは、形式ベースのコピー シンクの storeSettings 設定において、次のプロパティがサポートされています。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 |
storeSettings の type プロパティは FileServerWriteSettings に設定する必要があります。 |
はい |
| copyBehavior | ソースがファイル ベースのデータ ストアのファイルの場合は、コピー動作を定義します。 使用できる値は、以下のとおりです。 - PreserveHierarchy (既定値): ファイル階層をターゲット フォルダー内で保持します。 ソース フォルダーに対するソース ファイルの相対パスと、ターゲット フォルダーに対するターゲット ファイルの相対パスが一致します。 - FlattenHierarchy: ソース フォルダー内に存在しているすべてのファイルが、ターゲット フォルダーの第一レベルに配置されます。 ターゲット ファイルは、自動生成された名前になります。 - MergeFiles: ソース フォルダーのすべてのファイルを 1 つのファイルにマージします。 ファイル名を指定した場合、マージされたファイル名は指定した名前になります。 それ以外は自動生成されたファイル名になります。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されるコンカレント接続数の上限。 コンカレント接続数を制限する場合にのみ、値を指定します。 | いいえ |
例:
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "FileServerWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
フォルダーとファイル フィルターの例
このセクションでは、ワイルドカード フィルターを使用した結果のフォルダーのパスとファイル名の動作について説明します。
| folderPath | fileName | recursive | ソースのフォルダー構造とフィルターの結果 (太字のファイルが取得されます) |
|---|---|---|---|
Folder* |
(空、既定値を使用) | false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(空、既定値を使用) | true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
ファイル リストの例
このセクションでは、コピー アクティビティのソースでファイル リスト パスを使用した結果の動作について説明します。
次のソース フォルダー構造があり、太字のファイルをコピーするとします。
| サンプルのソース構造 | FileListToCopy.txt のコンテンツ | パイプラインの構成 |
|---|---|---|
| ルート FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv Metadata FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
データセット内: - フォルダー パス: root/FolderACopy アクティビティのソース内: - ファイル リストのパス: root/Metadata/FileListToCopy.txt ファイル リストのパスは、同じデータ ストア内にある 1 個のテキスト ファイルを指します。 このファイルに、コピーしようとするファイルのリストを含めます。 各行には、データセット内で構成したルート パスを基準として、各ファイルへの相対パスを含めます。 |
recursive と copyBehavior の例
このセクションでは、recursive 値と copyBhavior 値の組み合わせごとに、Copy 操作で行われる動作について説明します。
| recursive | copyBehavior | ソースのフォルダー構造 | ターゲットの結果 |
|---|---|---|---|
| true | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲット フォルダー Folder1 は、ソースと同じ構造で作成されます。 Folder1 File1 File2 Subfolder1 File3 File4 File5. |
| true | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲットの Folder1 は、次の構造で作成されます。 Folder1 File1 の自動生成された名前 File2 の自動生成された名前 File3 の自動生成された名前 File4 の自動生成された名前 File5 の自動生成された名前 |
| true | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲットの Folder1 は、次の構造で作成されます。 Folder1 File1、File2、File3、File4、File5 の内容は、自動生成されたファイル名を持つ 1 つのファイルにマージされます |
| false | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲット フォルダー Folder1 は、次の構造で作成されます。 Folder1 File1 File2 Subfolder1 と File3、File4、File5 は取得されません。 |
| false | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲット フォルダー Folder1 は、次の構造で作成されます。 Folder1 File1 の自動生成された名前 File2 の自動生成された名前 Subfolder1 と File3、File4、File5 は取得されません。 |
| false | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
ターゲット フォルダー Folder1 は、次の構造で作成されます。 Folder1 File1、File2 の内容は 1 つのファイルにマージされ、自動生成されたファイル名が付けられます。 File1 の自動生成された名前 Subfolder1 と File3、File4、File5 は取得されません。 |
Lookup アクティビティのプロパティ
プロパティの詳細については、Lookup アクティビティに関するページを参照してください。
GetMetadata アクティビティのプロパティ
プロパティの詳細については、「GetMetadata アクティビティ」を参照してください。
Delete アクティビティのプロパティ
プロパティの詳細については、「Delete アクティビティ」を参照してください。
レガシ モデル
Note
次のモデルは、下位互換性のために引き続きそのままサポートされます。 今後は、上記のセクションで説明した新しいモデルを使用することをお勧めします。作成 UI は、新しいモデルを生成するように切り替えられています。
レガシ データセット モデル
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | データセットの type プロパティは、次のように設定する必要があります:FileShare | はい |
| folderPath | フォルダーへのパス。 ワイルドカード フィルターがサポートされています。 使用できるワイルドカーは、* (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。実際のフォルダー名にワイルドカードまたはこのエスケープ文字が含まれている場合は、^ を使用してエスケープします。 例: ルートフォルダー/サブフォルダー。「サンプルのリンクされたサービスとデータセットの定義」および「フォルダーとファイル フィルターの例」の例も参照してください。 |
いいえ |
| fileName | 指定した "folderPath" の下にあるファイルを対象にする、名前またはワイルドカード フィルター。 このプロパティの値を指定しない場合、データセットはフォルダー内のすべてのファイルをポイントします。 フィルターに使用できるワイルドカードは、 * (ゼロ文字以上の文字に一致) と ? (ゼロ文字または 1 文字に一致) です。- 例 1: "fileName": "*.csv"- 例 2: "fileName": "???20180427.txt"実際のファイル名にワイルドカードまたはこのエスケープ文字が含まれている場合は、 ^ を使用してエスケープします。出力データセットに fileName の指定がなく、アクティビティ シンクに preserveHierarchy の指定がない場合、コピー アクティビティは、"Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz" のように "Data.[アクティビティ実行 ID GUID].[FlattenHierarchy の場合は GUID].[構成されている場合は形式].[構成されている場合は圧縮] " のパターンでファイル名を自動生成します。クエリの代わりにテーブル名を使用して表形式のソースからコピーする場合、名前のパターンは "MyTable.csv" のように " [テーブル名].[形式].[構成されている場合は圧縮] " になります。 |
いいえ |
| modifiedDatetimeStart | 最終変更日時属性に基づくファイル フィルター。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選ばれます。 時刻は、YYYY-MM-DDTHH:mm:ssZ の形式で UTC タイム ゾーンに適用されます。 多数のファイルに対してファイル フィルター処理を実行する場合は、この設定を有効にすると、データ移動の全体的なパフォーマンスが影響を受けることに注意してください。 各プロパティには NULL を指定できます。これは、ファイル属性フィルターをデータセットに適用しないことを意味します。 modifiedDatetimeStart で datetime 値を設定し、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値と同じまたはそれより後であるファイルが選択されます。
modifiedDatetimeEnd で datetime 値を設定し、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値より前であるファイルが選択されます。 |
いいえ |
| modifiedDatetimeEnd | 最終変更日時属性に基づくファイル フィルター。 ファイルは、最終変更日時が modifiedDatetimeStart と同じかそれよりも後であり、modifiedDatetimeEnd よりも前である場合に選ばれます。 時刻は "2018-12-01T05:00:00Z" の形式で UTC タイム ゾーンに適用されます。 多数のファイルに対してファイル フィルター処理を実行する場合は、この設定を有効にすると、データ移動の全体的なパフォーマンスが影響を受けることに注意してください。 各プロパティには NULL を指定できます。これは、ファイル属性フィルターをデータセットに適用しないことを意味します。 modifiedDatetimeStart で datetime 値を設定し、modifiedDatetimeEnd が NULL の場合は、最終変更日時属性が datetime 値と同じまたはそれより後であるファイルが選択されます。
modifiedDatetimeEnd で datetime 値を設定し、modifiedDatetimeStart が NULL の場合は、最終変更日時属性が datetime 値より前であるファイルが選択されます。 |
いいえ |
| format | ファイルベースのストア間でファイルをそのままコピー (バイナリ コピー) する場合は、入力と出力の両方のデータセット定義で format セクションをスキップします。 特定の形式のファイルを解析または生成する場合、サポートされるファイル形式の種類は、TextFormat、JsonFormat、AvroFormat、OrcFormat、ParquetFormat です。 形式の type プロパティをいずれかの値に設定します。 詳細については、「 テキスト形式、 JSON 形式、 Avro 形式、 Orc 形式、 Parquet 形式 」セクションを参照してください。 |
いいえ (バイナリ コピー シナリオのみ) |
| 圧縮 | データの圧縮の種類とレベルを指定します。 詳細については、サポートされるファイル形式と圧縮コーデックに関する記事を参照してください。 サポートされる種類は、GZip、Deflate、BZip2、ZipDeflate です。 サポートされるレベルは、Optimal と Fastest です。 |
いいえ |
ヒント
フォルダーの下のすべてのファイルをコピーするには、folderPath のみを指定します。
特定の名前の単一のファイルをコピーするには、フォルダー部分で folderPath、ファイル名で fileName を指定します。
フォルダーの下のファイルのサブセットをコピーするには、フォルダー部分で folderPath、ワイルドカード フィルターで fileName を指定します。
Note
ファイル フィルターで "fileFilter" プロパティを使用していた場合は、そのまま引き続きサポートされますが、今後は "fileName" に追加された新しいフィルター機能を使用することをお勧めします。
例:
{
"name": "FileSystemDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<file system linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
レガシ コピー アクティビティ ソース モデル
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | コピー アクティビティのソースの type プロパティは、次のように設定する必要があります:FileSystemSource | はい |
| recursive | データをサブフォルダーから再帰的に読み取るか、指定したフォルダーからのみ読み取るかを指定します。 recursive を true に設定し、シンクがファイル ベースのストアである場合、空のフォルダー/サブフォルダーはシンク側でコピーも作成もされないことに注意してください。 使用可能な値: true (既定値)、false |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されるコンカレント接続数の上限。 コンカレント接続数を制限する場合にのみ、値を指定します。 | いいえ |
例:
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<file system input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
レガシ コピー アクティビティ シンク モデル
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | コピー アクティビティのシンクの type プロパティは、次のように設定する必要があります: FileSystemSink | はい |
| copyBehavior | ソースがファイル ベースのデータ ストアのファイルの場合は、コピー動作を定義します。 使用できる値は、以下のとおりです。 - PreserveHierarchy (既定値): ファイル階層をターゲット フォルダー内で保持します。 ソース フォルダーに対するソース ファイルの相対パスと、ターゲット フォルダーに対するターゲット ファイルの相対パスが一致します。 - FlattenHierarchy: ソース フォルダー内に存在しているすべてのファイルが、ターゲット フォルダーの第一レベルに配置されます。 ターゲット ファイルの名前は、自動生成されます。 - MergeFiles: ソース フォルダーのすべてのファイルを 1 つのファイルにマージします。 レコードの重複除去は、マージ中には実行されません。 ファイル名を指定した場合、マージされたファイル名は指定した名前になります。それ以外の場合は、自動生成されたファイル名になります。 |
いいえ |
| maxConcurrentConnections | アクティビティの実行中にデータ ストアに対して確立されるコンカレント接続数の上限。 コンカレント接続数を制限する場合にのみ、値を指定します。 | いいえ |
例:
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<file system output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "FileSystemSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
関連コンテンツ
Copy アクティビティでソースおよびシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するセクションを参照してください。