適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
- Fabric無料試用版を開始します。
Microsoft Fabric
JSON ファイルを解析する場合や、JSON 形式にデータを書き込む場合は、この記事に従ってください。
JSON 形式は、以下のコネクタでサポートされています。
- アマゾンS3
- Amazon S3 互換ストレージ、
- Azure BLOB
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- ファイル システム
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。 このセクションでは、JSON データセットでサポートされるプロパティの一覧を示します。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 型 | データセットの type プロパティは、Json に設定する必要があります。 | はい |
| 位置 | ファイルの場所の設定。 ファイル ベースの各コネクタには、固有の場所の種類と location でサポートされるプロパティがあります。
>。 |
はい |
| encodingName | テスト ファイルの読み取り/書き込みに使用するエンコードの種類です。 許可される値は次のとおりです。"UTF-8"、"UTF-8 without BOM"、"UTF-16"、"UTF-16BE"、"UTF-32"、"UTF-32BE"、"US-ASCII"、"UTF-7"、"BIG5"、"EUC-JP"、"EUC-KR"、"GB2312"、"GB18030"、"JOHAB"、"SHIFT-JIS"、"CP875"、"CP866"、"IBM00858"、"IBM037"、"IBM273"、"IBM437"、"IBM500"、"IBM737"、"IBM775"、"IBM850"、"IBM852"、"IBM855"、"IBM857"、"IBM860"、"IBM861"、"IBM863"、"IBM864"、"IBM865"、"IBM869"、"IBM870"、"IBM01140"、"IBM01141"、"IBM01142"、"IBM01143"、"IBM01144"、"IBM01145"、"IBM01146"、"IBM01147"、"IBM01148"、"IBM01149"、"ISO-2022-JP"、"ISO-2022-KR"、"ISO-8859-1"、"ISO-8859-2"、"ISO-8859-3"、"ISO-8859-4"、"ISO-8859-5"、"ISO-8859-6"、"ISO-8859-7"、"ISO-8859-8"、"ISO-8859-9"、"ISO-8859-13"、"ISO-8859-15"、"WINDOWS-874"、"WINDOWS-1250"、"WINDOWS-1251"、"WINDOWS-1252"、"WINDOWS-1253"、"WINDOWS-1254"、"WINDOWS-1255"、"WINDOWS-1256"、"WINDOWS-1257"、"WINDOWS-1258"。 |
いいえ |
| 圧縮 | ファイル圧縮を構成するためのプロパティのグループ。 アクティビティの実行中に圧縮/圧縮解除を行う場合は、このセクションを構成します。 | いいえ |
| 型 ( compression の下にあります) |
JSON ファイルの読み取り/書き込みに使用される圧縮コーデックです。 使用できる値は、bzip2、gzip、deflate、ZipDeflate、TarGzip、Tar、snappy、または lz4 です。 既定では圧縮されません。 Note 現在、Copy アクティビティでは "snappy" と "lz4" はサポートされていません。マッピング データ フローでは "ZipDeflate"、"TarGzip"、"Tar" はサポートされていません。 コピー アクティビティを使用して ZipDeflate// ファイルを圧縮解除し、ファイルベースのシンク データ ストアに書き込む場合、ファイルは既定で フォルダーに解凍されることに <path specified in dataset>/<folder named as source compressed file>/してください。圧縮ファイル名をフォルダー構造として保持するかどうかを制御するには、preserveZipFileNameAsFolderに対して /preserveCompressionFileNameAsFolder を使用します。 |
いいえ。 |
| レベル ( compression の下にあります) |
圧縮率です。 使用できる値は、Optimal または Fastest です。 - Fastest: 圧縮操作は可能な限り短時間で完了しますが、圧縮後のファイルが最適に圧縮されていない場合があります。 - Optimal:圧縮操作で最適に圧縮されますが、操作が完了するまでに時間がかかる場合があります。 詳細については、 圧縮レベル に関するトピックをご覧ください。 |
いいえ |
Azure Blob Storage上の JSON データセットの例を次に示します。
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
プロパティのCopy アクティビティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、JSON のソースとシンクでサポートされるプロパティの一覧を示します。
JSON ファイルからデータを抽出してシンク データ ストアおよび形式にマップする方法、またはスキーマ マッピングからの逆の方法について説明します。
ソースとしての JSON
Copy アクティビティの *source* セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 型 | コピー アクティビティのソースの type プロパティは、JSONSource に設定する必要があります。 | はい |
| formatSettings | プロパティのグループ。 後の JSON の読み取り設定に関する表を参照してください。 | いいえ |
| storeSettings | データ ストアからデータを読み取る方法を指定するプロパティのグループ。 ファイル ベースの各コネクタには、storeSettings に、固有のサポートされる読み取り設定があります。
コネクタの記事の詳細については、「-> Copy アクティビティ プロパティ」セクションを参照してください。 |
いいえ |
でサポートされている formatSettings:
| プロパティ | 内容 | 必須 |
|---|---|---|
| 型 | formatSettings の type は、JsonReadSettings に設定する必要があります。 | はい |
| compressionProperties | 特定の圧縮コーデックのデータを圧縮解除する方法のプロパティ グループ。 | いいえ |
| preserveZipFileNameAsFolder (" compressionProperties>type の下に ZipDeflateReadSettings として") |
ZipDeflate で入力データセットが圧縮構成されている場合に適用されます。 コピー時にソースの ZIP ファイル名をフォルダー構造として保持するかどうかを指定します。 - true (既定) に設定した場合、サービスにより解凍されたファイルが <path specified in dataset>/<folder named as source zip file>/ に書き込まれます。- false に設定した場合、サービスにより解凍されたファイルが <path specified in dataset> に直接書き込まれます。 競合または予期しない動作を避けるために、異なるソース ZIP ファイルに重複したファイル名がないことを確認します。 |
いいえ |
| preserveCompressionFileNameAsFolder (" compressionProperties>type の下に TarGZipReadSettings または TarReadSettings として") |
TarGzip/Tar で入力データセットが圧縮構成されている場合に適用されます。 コピー時にソースの圧縮ファイル名をフォルダー構造として保持するかどうかを指定します。 - true (既定) に設定した場合、サービスにより圧縮解除されたファイルが <path specified in dataset>/<folder named as source compressed file>/ に書き込みます。 - false に設定した場合、サービスにより圧縮解除されたファイルが <path specified in dataset> に直接書き込まれます。 競合または予期しない動作を避けるために、異なるソース ファイルに重複したファイル名がないことを確認します。 |
いいえ |
シンクとしての JSON
Copy アクティビティの *sink* セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 型 | コピー アクティビティのソースの type プロパティは、JSONSink に設定する必要があります。 | はい |
| formatSettings | プロパティのグループ。 後の JSON の書き込み設定に関する表を参照してください。 | いいえ |
| storeSettings | データ ストアにデータを書き込む方法を指定するプロパティのグループ。 ファイル ベースの各コネクタには、storeSettings に、固有のサポートされる書き込み設定があります。
コネクタの記事の詳細については、「-> Copy アクティビティ プロパティ」セクションを参照してください。 |
いいえ |
でサポートされている formatSettings:
| プロパティ | 内容 | 必須 |
|---|---|---|
| 型 | formatSettings の type は、JsonWriteSettings に設定する必要があります。 | はい |
| filePattern | 各 JSON ファイルに格納されたデータのパターンを示します。 使用できる値は、setOfObjects (JSON 行) と arrayOfObjects です。 既定値は setOfObjects です。 これらのパターンの詳細については、「JSON ファイルのパターン」セクションを参照してください。 | いいえ |
JSON ファイルのパターン
JSON ファイルからデータをコピーする場合、コピー アクティビティでは、JSON ファイルの以下のパターンを自動的に検出および解析することができます。 データを JSON ファイルに書き込む場合は、コピー アクティビティのシンクでファイル パターンを構成できます。
タイプ I: setOfObjects
各ファイルには、単一のオブジェクト、JSON 行、または連結されたオブジェクトが含まれます。
単一オブジェクトの JSON の例
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }JSON 行 (シンクの既定値)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}連結 JSON の例
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
タイプ II: arrayOfObjects
各ファイルにはオブジェクトの配列が含まれます。
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Mapping Data Flow のプロパティ
ソース プロパティ
次の表に、JSON ソースでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [ソース オプション] タブで編集できます。
| 名前 | 内容 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| ワイルド カードのパス | ワイルドカードのパスに一致するすべてのファイルが処理されます。 データセットで設定されているフォルダーとファイル パスはオーバーライドされます。 | no | String[] | wildcardPaths |
| パーティションのルート パス | パーティション分割されたファイル データについては、パーティション フォルダーを列として読み取るためにパーティションのルート パスを入力できます | no | String | partitionRootPath |
| ファイルの一覧 | 処理するファイルを一覧表示しているテキスト ファイルをソースが指しているかどうか | no |
true または false |
fileList |
| ファイル名を格納する列 | ソース ファイル名とパスを使用して新しい列を作成します | no | String | rowUrlColumn |
| 完了後 | 処理後にファイルを削除または移動します。 ファイル パスはコンテナー ルートから始まります | no | 削除: true または false 移動: ['<from>', '<to>'] |
purgeFiles moveFiles |
| 最終更新日時でフィルター処理 | 最後に変更された日時に基づいてファイルをフィルター処理する場合に選択 | no | Timestamp | modifiedAfter modifiedBefore |
| 1 つのドキュメント | マッピング データ フローでは、各ファイルから 1 つの JSON ドキュメントが読み取られます | no |
true または false |
singleDocument |
| 引用符で囲まれていない列名 | [Unquoted column names](引用符で囲まれていない列名) を選択した場合、マッピング データ フローでは、引用符で囲まれていない JSON 列が読み取られます。 | no |
true または false |
unquotedColumnNames |
| コメントあり | JSON データに C または C++ スタイルのコメントが含まれている場合は、 [コメントあり] を選択します | no |
true または false |
asComments |
| 一重引用符付き | 引用符で囲まれていない JSON 列が読み取られます | no |
true または false |
singleQuoted |
| 円記号によるエスケープ | JSON データ内の文字をエスケープするためにバックスラッシュを使用している場合は、 [円記号によるエスケープ] を選択します | no |
true または false |
backslashEscape |
| [Allow no files found](ファイルの未検出を許可) | true の場合、ファイルが見つからない場合でもエラーはスローされない | no |
true または false |
ignoreNoFilesFound |
インライン データセット
マッピング データ フローでは、ソースとシンクを定義するためのオプションとして "インライン データセット" がサポートされます。 インライン JSON データセットは、ソース変換やシンク変換の内部で直接定義され、定義されたデータフローの外部では共有されません。 これは、データセットのプロパティをデータ フロー内で直接パラメーター化するのに役立ち、共有された ADF データセットに比べてパフォーマンスが向上するという利点があります。
多数のソース フォルダーとファイルを読み取っている場合は、[プロジェクション | スキーマ オプション] ダイアログ内で [ユーザー プロジェクション スキーマ] オプションを設定することによって、データ フロー ファイル検出のパフォーマンスを向上させることができます。 このオプションにより、ADF の既定のスキーマ自動検出が無効になり、ファイル検出のパフォーマンスが大幅に向上します。 このオプションを設定する前に、ADF にプロジェクションのための既存のスキーマが割り当てられるように、必ず JSON プロジェクションをインポートしてください。 このオプションは、スキーマ ドリフトでは機能しません。
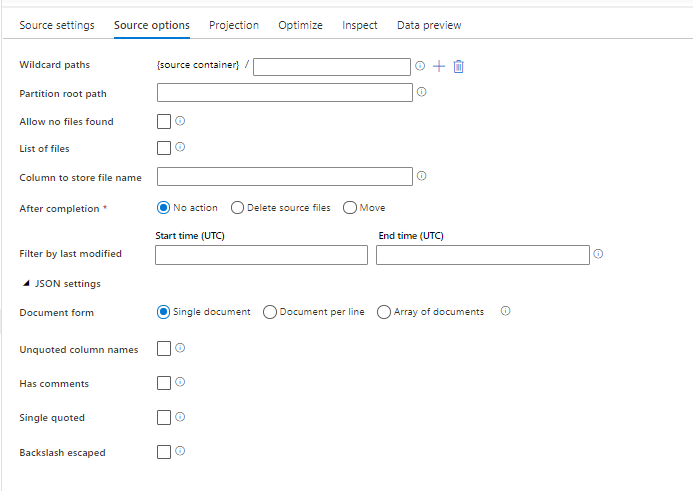
ソース形式のオプション
データ フローでソースとして JSON データセットを使用すると、5 つの追加設定を行うことができます。 これらの設定は、[ソース オプション] タブの [JSON 設定] アコーディオンにあります。[ドキュメント フォーム] 設定では、[Single document] (1 つのドキュメント)、[Document per line] (行ごとのドキュメント)、および [Array of documents] (ドキュメントの配列) を選択できます。
Default
既定では、JSON データは次の形式で読み取られます。
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
1 つのドキュメント
[Single document](1 つのドキュメント) を選択した場合、マッピング データ フローでは、各ファイルから 1 つの JSON ドキュメントが読み取られます。
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
[Document per line](行ごとのドキュメント) を選択した場合、マッピング データ フローでは、ファイルの各行から 1 つの JSON ドキュメントが読み取られます。
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
[Array of documents](ドキュメントの配列) を選択した場合、マッピング データ フローでは、ファイルから 1 つのドキュメントが読み取られます。
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
Note
JSON データをプレビューしているときにデータ フローが "corrupt_record" というエラーをスローした場合は、ユーザーのデータに JSON ファイル内の 1 つのドキュメントが含まれている可能性があります。 "1 つのドキュメント" を設定すると、そのエラーがクリアされます。
引用符で囲まれていない列名
[Unquoted column names](引用符で囲まれていない列名) を選択した場合、マッピング データ フローでは、引用符で囲まれていない JSON 列が読み取られます。
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
コメントあり
JSON データに C または C++ スタイルのコメントが含まれている場合は、 [コメントあり] を選択します。
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
一重引用符付き
JSON フィールドと値に二重引用符ではなく単一引用符を使用している場合は、 [Single quoted](単一引用符付き) を選択します。
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
円記号によるエスケープ
JSON データ内の文字をエスケープするためにバックスラッシュを使用している場合は、 [円記号によるエスケープ] を選択します。
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
シンクのプロパティ
次の表に、JSON シンクでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [設定] タブで編集できます。
| 名前 | 内容 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| フォルダーのクリア | 書き込みの前に宛先フォルダーがクリアされるかどうか | no |
true または false |
切り詰める |
| ファイル名のオプション | 書き込まれたデータの名前付け形式です。 既定では、part-#####-tid-<guid> という形式で、パーティションごとに 1 ファイルです |
no | パターン: String パーティションあたり: String[] 列内のデータとして: String 1 つのファイルに出力する: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
派生列での JSON 構造の作成
派生列式エディターを使用して複合列をデータ フローに追加できます。 派生列変換に新しい列を追加し、青いボックスをクリックして式ビルダーを開きます。 列を複合にするには、手動で JSON 構造を入力するか、UX を使用してサブ列を対話的に追加します。
式ビルダー UX の使用
出力スキーマのサイド ウィンドウで、列の上にマウス ポインターを移動し、プラス記号のアイコンをクリックします。 列を複合型にするために、 [Add subcolumn](サブ列の追加) を選択します。
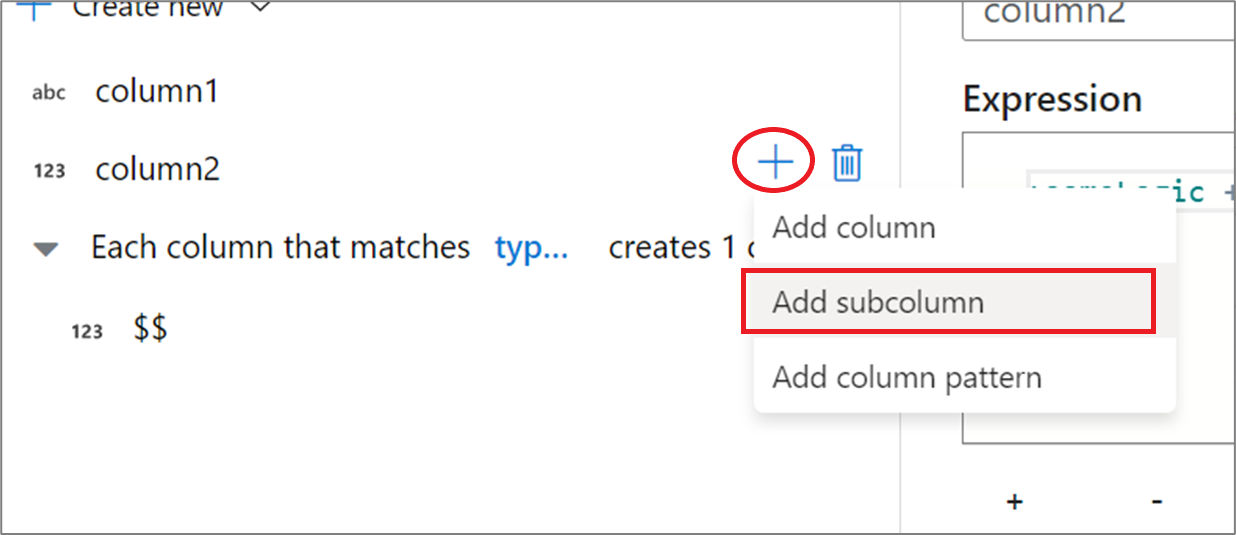
同じ方法で、さらに列とサブ列を追加できます。 複合でない各フィールドについては、式エディターで右側に式を追加できます。
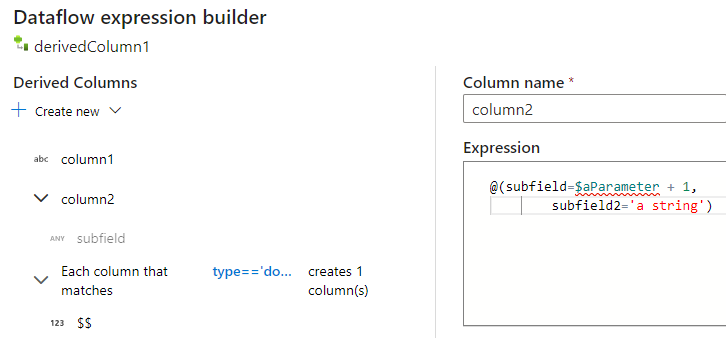
手動による JSON 構造の入力
JSON 構造を手動で追加するには、新しい列を追加し、エディターで式を入力します。 式は、次の一般的な形式に従います。
@(
field1=0,
field2=@(
field1=0
)
)
"complexColumn" という名前の列に対してこの式が入力された場合、次の JSON としてシンクに書き込まれます。
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
完全な階層定義のサンプル手動スクリプト
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
関連するコネクタと形式
JSON 形式に関連する一般的なコネクタと形式を次に示します。