System.IO.Pipelines は、.NET での高パフォーマンス I/O を容易にするように設計されたライブラリです。 このパッケージは、広範な互換性、.NET Framework、および最新の .NET のために .NET Standard を対象としています。 最新の .NET バージョンでは、 System.IO.Pipelines は共有フレームワークに含まれており、別の NuGet パッケージは必要ありません。
ライブラリは 、System.IO.Pipelines NuGet パッケージとしても使用できます。
System.IO.Pipelines はどのような問題を解決しますか?
ストリーミング データを解析するアプリは、多くの特殊な通常とは異なるコード フローを持つ定型コードで構成されます。 定型および特殊なケースのコードは複雑で、保守が困難です。
System.IO.Pipelines は、以下のようになるように設計されています。
- ハイ パフォーマンスのストリーミング データ解析を実現する。
- コードの複雑さを軽減する。
このコードは、クライアントから行区切りメッセージ ( '\n' で区切られた) を受信する TCP サーバーの場合に一般的です。
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}
上記のコードには、以下のようないくつかの問題があります。
- メッセージ全体 (行の終わり) が、
ReadAsyncへの 1 回の呼び出しで受信されない場合がある。 -
stream.ReadAsyncの結果が無視される。stream.ReadAsyncで、読み取られたデータの量が返される。 - 複数の行が 1 回の
ReadAsync呼び出しで読み取られるケースが処理されない。 - 読み取りごとに
byte配列が割り当てられる。
上記の問題を解決するには、次の変更を行います。
改行が検出されるまで、受信データをバッファーに格納します。
バッファーで返されたすべての行を解析します。
行が 1 KB (1024 バイト) を超える可能性があります。 このコードでは、バッファー内の完全な行に収まるように区切り記号が見つかるまで、入力バッファーのサイズを変更する必要があります。
- バッファーのサイズが変更されると、入力に長い行が増えるにつれて、さらに多くのバッファーがコピーされます。
- 無駄な領域を減らすには、行の読み取りに使用されるバッファーを小さくします。
メモリが繰り返し割り当てられないようにするために、バッファー プーリングの使用を検討します。
このコードは、次の問題の一部に対処します。
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffer.
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffer.
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool.
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes.
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data.
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed,
bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset.
var lineLength = linePosition - bytesConsumed;
// Process the line.
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line consumed (including \n).
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
上記のコードは複雑で、特定されたすべての問題には対処していません。 ハイ パフォーマンス ネットワークは、通常、パフォーマンスを最大化するために複雑なコードを記述することを意味します。
System.IO.Pipelines は、この種のコードをより簡単に記述できるように設計されています。
パイプ
Pipe クラスを使用して、PipeWriter/PipeReader ペアを作成します。
PipeWriter に書き込まれたすべてのデータは、PipeReader で利用できます。
var pipe = new Pipe();
PipeReader reader = pipe.Reader;
PipeWriter writer = pipe.Writer;
パイプの基本的な使用方法
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket.
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader.
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// By completing PipeWriter, tell the PipeReader that there's no more data coming.
await writer.CompleteAsync();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
while (TryReadLine(ref buffer, out ReadOnlySequence<byte> line))
{
// Process the line.
ProcessLine(line);
}
// Tell the PipeReader how much of the buffer has been consumed.
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data coming.
if (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete.
await reader.CompleteAsync();
}
bool TryReadLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
// Look for a EOL in the buffer.
SequencePosition? position = buffer.PositionOf((byte)'\n');
if (position == null)
{
line = default;
return false;
}
// Skip the line + the \n.
line = buffer.Slice(0, position.Value);
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
return true;
}
2 つのループが読み取りと書き込みを処理します。
-
FillPipeAsyncではSocketから読み取り、PipeWriterに書き込みます。 -
ReadPipeAsyncではPipeReaderから読み取り、受信行を解析します。
明示的なバッファーは割り当てされません。 すべてのバッファー管理は、PipeReader と PipeWriter の実装に委任されます。 バッファー管理を委任することで、ビジネス ロジックのみに焦点を当てるコードがより簡単に消費されるようになります。
最初のループでは、次のようになります。
- PipeWriter.GetMemory(Int32) は、基になるライターからメモリを取得するために呼び出されます。
-
PipeWriter.Advance(Int32) は、バッファーに書き込まれたデータの量を
PipeWriterに示すために呼び出されます。 -
PipeWriter.FlushAsync は、データを
PipeReaderで使用できるようにするために呼び出されます。
2 番目のループでは、PipeReader によって書き込まれたバッファーが PipeWriter で消費されます。 バッファーはソケットから来ます。
PipeReader.ReadAsync の呼び出しでは、次のようになります。
次の 2 つの重要な情報を含む、ReadResult を返します。
- ReadOnlySequence<T> の形式で読み取られたデータ。
- データの終わり (EOF) に到達したかどうかを示すブール値
IsCompleted。
行の終わり (EOL) の区切り記号が検出され、行が解析された後は、次のようになります。
- ロジックでバッファーが処理され、既に処理されているものがスキップされます。
-
PipeReader.AdvanceTo は、どのくらいの量のデータが使用され、検査されたかを
PipeReaderに示すために呼び出されます。
リーダーとライターのループは、 PipeReader.Complete と PipeWriter.Completeを呼び出すことによって終了します。
Completeを呼び出すと、基になるPipeが割り当てられたメモリが解放されます。
バックプレッシャとフロー制御
読み取りと解析を連動させるのが理想的です。
- 読み取りスレッドでは、ネットワークからのデータを消費し、それをバッファーに格納します。
- 解析スレッドでは、適切なデータ構造の構築を担当します。
通常、解析には、ネットワークからデータのブロックをコピーするだけの場合より、時間がかかります。
- 読み取りスレッドは解析スレッドより前になります。
- 読み取りスレッドの速度を落とすか、解析スレッド用のデータを格納するためにより多くのメモリを割り当てる必要があります。
最適なパフォーマンスが得られるように、頻繁な一時停止間のバランスが保たれ、より多くのメモリが割り当てられます。
この問題を解決するために、Pipe には、データのフローを制御するための次の 2 つの設定があります。
- PauseWriterThreshold:FlushAsync の呼び出しが一時停止する前に、バッファーに格納する必要があるデータ量を判別します。
- ResumeWriterThreshold:PipeWriter.FlushAsync の呼び出しが再開される前に、リーダーが監視する必要があるデータの量を判別します。
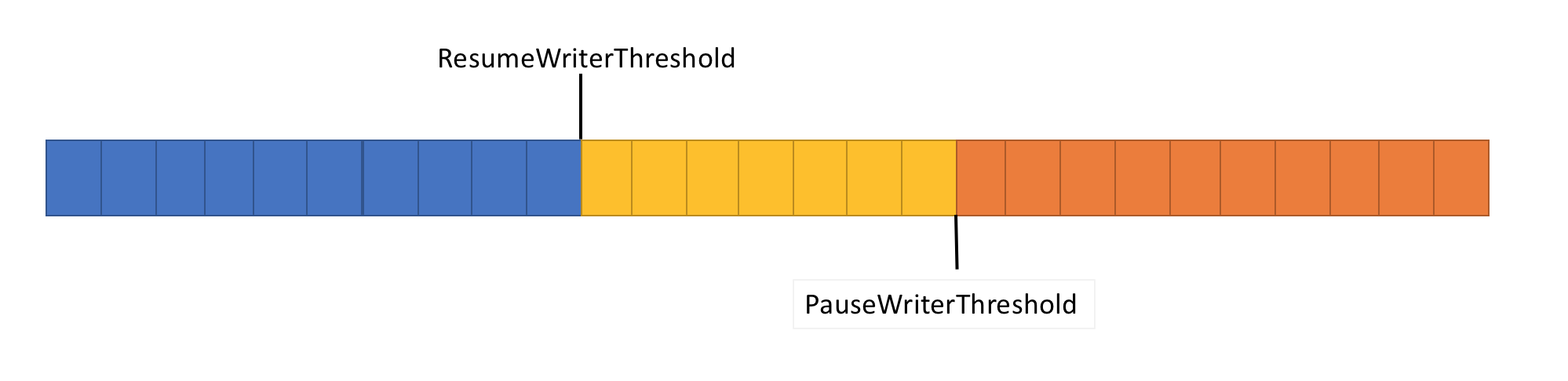
-
ValueTask<FlushResult>のデータ量がPipeを超えたときに、不完全なPauseWriterThresholdを返します。 -
ValueTask<FlushResult>より低くなったときに、ResumeWriterThresholdを完了します。
2 つの値は、1 つの値が使用された場合に発生する可能性がある、急速な循環を防ぐために使用されます。
使用例
// The Pipe will start returning incomplete tasks from FlushAsync until
// the reader examines at least 5 bytes.
var options = new PipeOptions(pauseWriterThreshold: 10, resumeWriterThreshold: 5);
var pipe = new Pipe(options);
パイプスケジューラー
通常、async および await を使用する場合、非同期コードは TaskScheduler または現在の SynchronizationContext で再開されます。
I/O を行う場合は、I/O が実行される場所をきめ細かく制御することが重要です。 この制御により、CPU キャッシュを効果的に利用できます。 効率的なキャッシュは、Web サーバーなどのハイ パフォーマンス アプリに不可欠です。 PipeScheduler では、非同期コールバックが実行される場所を制御できます。 既定では:
- 現在の SynchronizationContext が使用されます。
-
SynchronizationContextがない場合は、スレッド プールを使用してコールバックを実行します。
public static void Main(string[] args)
{
var writeScheduler = new SingleThreadPipeScheduler();
var readScheduler = new SingleThreadPipeScheduler();
// Tell the Pipe what schedulers to use and disable the SynchronizationContext.
var options = new PipeOptions(readerScheduler: readScheduler,
writerScheduler: writeScheduler,
useSynchronizationContext: false);
var pipe = new Pipe(options);
}
// This is a sample scheduler that async callbacks on a single dedicated thread.
public class SingleThreadPipeScheduler : PipeScheduler
{
private readonly BlockingCollection<(Action<object> Action, object State)> _queue =
new BlockingCollection<(Action<object> Action, object State)>();
private readonly Thread _thread;
public SingleThreadPipeScheduler()
{
_thread = new Thread(DoWork);
_thread.Start();
}
private void DoWork()
{
foreach (var item in _queue.GetConsumingEnumerable())
{
item.Action(item.State);
}
}
public override void Schedule(Action<object?> action, object? state)
{
if (state is not null)
{
_queue.Add((action, state));
}
// else log the fact that _queue.Add was not called.
}
}
PipeScheduler.ThreadPool は、スレッド プールへのコールバックをキューに登録する PipeScheduler の実装です。
PipeScheduler.ThreadPool は既定値であり、一般的に最適な選択肢です。
PipeScheduler.Inline を使用すると、デッドロックなどの意図しない結果となる可能性があります。
パイプのリセット
多くの場合、 Pipe オブジェクトの再利用は効率的です。 パイプをリセットするには、PipeReader と Reset の両方が完了したときに PipeReaderPipeWriter を呼び出します。
PipeReader
PipeReader では、呼び出し元の代わりにメモリを管理します。
を呼び出した後に、PipeReader.AdvanceTo を常に呼び出してください。 これにより、PipeReader では、呼び出し元がメモリを使用して実行されるタイミングを把握し、追跡できるようになります。
ReadOnlySequence<T>から返されるPipeReader.ReadAsyncは、PipeReader.AdvanceToの呼び出しまで有効です。
ReadOnlySequence<T> を呼び出した後、PipeReader.AdvanceTo を使用することはできません。
PipeReader.AdvanceTo では、次の 2 つの SequencePosition 引数を受け取ります。
- 最初の引数では、消費されたメモリの量を判別します。
- 2 番目の引数では、監視されたバッファーの量を判別します。
データを消費済みとしてマークすることは、パイプでメモリを基になるバッファープ ールに返すことができることを意味します。 データを監視済みとしてマークすると、PipeReader.ReadAsync の次回の呼び出しがどのように動作するかを制御します。 すべてを監視済みとしてマークすることは、パイプにデータがさらに書き込まれるまで、PipeReader.ReadAsync の次の呼び出しでは何も返されないことを意味します。 その他の値を指定すると、次の呼び出し PipeReader.ReadAsync は観測されたデータ および未観測データとともに直ちに返されますが、すでに消費されたデータは含まれません。
ストリーミング データの読み取りシナリオ
ストリーミング データを読み取るときに、いくつかの一般的なパターンが出現します。
- 指定したデータのストリームで、1 つのメッセージを解析する。
- 指定したデータのストリームで、使用可能なメッセージをすべて解析する。
これらの例では、TryParseLinesからのメッセージを解析するために ReadOnlySequence<T> メソッドを使用します。
TryParseLines では 1 つのメッセージを解析し、入力バッファーを更新して、解析されたメッセージをバッファーからトリミングします。
TryParseLines は .NET の一部ではありません。これは、次のセクションで使用されるユーザー記述メソッドです。
bool TryParseLines(ref ReadOnlySequence<byte> buffer, out Message message);
1 つのメッセージを読み取る
このコードは、 PipeReader から 1 つのメッセージを読み取り、呼び出し元に返します。
async ValueTask<Message?> ReadSingleMessageAsync(PipeReader reader,
CancellationToken cancellationToken = default)
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
// In the event that no message is parsed successfully, mark consumed
// as nothing and examined as the entire buffer.
SequencePosition consumed = buffer.Start;
SequencePosition examined = buffer.End;
try
{
if (TryParseLines(ref buffer, out Message message))
{
// A single message was successfully parsed so mark the start of the
// parsed buffer as consumed. TryParseLines trims the buffer to
// point to the data after the message was parsed.
consumed = buffer.Start;
// Examined is marked the same as consumed here, so the next call
// to ReadSingleMessageAsync will process the next message if there's
// one.
examined = consumed;
return message;
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(consumed, examined);
}
}
return null;
}
先行するコード:
- 1 つのメッセージを解析します。
- 消費された
SequencePositionと検査されたSequencePositionを更新し、トリミングされた入力バッファーの先頭を指すようにします。
2 つの SequencePosition 引数が更新されます。これは、TryParseLines で解析されたメッセージが入力バッファーから削除されるためです。 一般に、バッファーからの 1 つのメッセージを解析する場合、検査位置は次のいずれかである必要があります。
- メッセージの終わり。
- メッセージが検出されなかった場合は、受信されたバッファーの終わり。
1 つのメッセージ ケースでは、エラーが発生する可能性が最も高くなります。 間違った値を 検査 に渡すと、メモリ不足の例外や無限ループが発生する可能性があります。 詳細については、この記事の「PipeReader の一般的な問題」セクションを参照してください。
重要
ReadSingleMessageAsync は PipeReader.CompleteAsyncを呼び出しません。 呼び出し元は、 PipeReaderの完了を担当します。
PipeReader.CompleteAsync内でReadSingleMessageAsyncを呼び出すと、それ以上データを読み取ることができなくなり、後続のメッセージの読み取りが妨げられます。
複数のメッセージを読み取る
このコードは、 PipeReader からすべてのメッセージを読み取り、それぞれに ProcessMessageAsync を呼び出します。
async Task ProcessMessagesAsync(PipeReader reader, CancellationToken cancellationToken = default)
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
ProcessMessagesAsyncは完全なメッセージ読み取りループを所有しているため、完了するとPipeReader.CompleteAsyncを呼び出します。 単一メッセージの場合とは異なり、呼び出し元はリーダーを完了する必要はありません。
ProcessMessagesAsync は、 PipeReader 有効期間の完全な所有権を取得します。
キャンセル
- CancellationToken を渡すことをサポートします。
- 読み取りが保留中のときに OperationCanceledException が取り消された場合は、
CancellationTokenをスローします。 -
PipeReader.CancelPendingRead を使用して現在の読み取り操作を取り消す方法をサポートします。これにより、例外の発生を回避できます。
PipeReader.CancelPendingReadを呼び出すと、PipeReader.ReadAsync の現在の呼び出しまたは次の呼び出しで、ReadResult がIsCanceledに設定されたtrueが返されます。 これは、非破壊的および非例外的な方法で既存の読み取りループを停止する場合に便利です。
private PipeReader reader;
public MyConnection(PipeReader reader)
{
this.reader = reader;
}
public void Abort()
{
// Cancel the pending read so the process loop ends without an exception.
reader.CancelPendingRead();
}
public async Task ProcessMessagesAsync()
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
if (result.IsCanceled)
{
// The read was canceled. You can quit without reading the existing data.
break;
}
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
PipeReader の一般的な問題
間違った値を
consumedまたはexaminedに渡すと、既に読み取られたデータが読み取られます。buffer.Endを検証済みとして渡すと、次の結果が得られます。- データが停止する
- データが消費されない場合、最終的にメモリ不足 (OOM) の例外が発生します。 たとえば、バッファーから一度に 1 つのメッセージを処理する場合は、
PipeReader.AdvanceTo(position, buffer.End)です。
間違った値を
consumedまたはexaminedに渡すと、無限ループが発生する可能性があります。 たとえば、PipeReader.AdvanceTo(buffer.Start)が変更されていない場合にbuffer.Startすると、新しいデータが到着する直前に次の呼び出しPipeReader.ReadAsyncが返されます。間違った値を
consumedまたはexaminedに渡すと、無限バッファリング (最終的な OOM) が発生する可能性があります。ReadOnlySequence<T>を呼び出した後にPipeReader.AdvanceToを使用すると、メモリが破損する可能性があります (空き時間後に使用します)。
Complete / CompleteAsyncの呼び出しに失敗すると、メモリ リークが発生する可能性があります。
バッファーを処理する前に ReadResult.IsCompleted を確認し、読み取りロジックを終了すると、データが失われます。 ループの終了条件は、
ReadResult.Buffer.IsEmptyおよびReadResult.IsCompletedに基づいている必要があります。 これを誤って実行すると、無限ループになる可能性があります。
問題のあるコード
❌ データ損失
ReadResult が IsCompleted に設定されている場合、true でデータの最終セグメントを返すことができます。 読み取りループを終了する前にそのデータを読み取らないと、データが失われます。
警告
次のコードは使用しないでください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 次のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> dataLossBuffer = result.Buffer;
if (result.IsCompleted)
break;
Process(ref dataLossBuffer, out Message message);
reader.AdvanceTo(dataLossBuffer.Start, dataLossBuffer.End);
}
警告
上記のコードは使用しない でください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 前のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
❌ 無限ループ
次のロジックは、Result.IsCompleted が true 状態の場合でも、バッファーに完全なメッセージがないと無限ループになる可能性があります。
警告
次のコードは使用しないでください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 次のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (result.IsCompleted && infiniteLoopBuffer.IsEmpty)
break;
Process(ref infiniteLoopBuffer, out Message message);
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
警告
上記のコードは使用しない でください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 前のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
同じ問題があるもう 1 つのコードを次に示します。
ReadResult.IsCompleted を確認する前に、空でないバッファーがあるかどうかが確認されます。
else if内にあるため、バッファー内に完全なメッセージがない場合は、永久にループします。
警告
次のコードは使用しないでください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 次のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (!infiniteLoopBuffer.IsEmpty)
Process(ref infiniteLoopBuffer, out Message message);
else if (result.IsCompleted)
break;
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
警告
上記のコードは使用しない でください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 前のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
❌ 応答しないアプリケーション
PipeReader.AdvanceTo位置でbuffer.Endを使用して無条件にexaminedを呼び出すと、1 つのメッセージを解析するときにアプリケーションが応答しなくなる可能性があります。
PipeReader.AdvanceTo の次の呼び出しでは、以下のようになるまで何も返されません。
- パイプにさらにデータが書き込まれている。
- また、新しいデータが以前に検査されていない。
警告
次のコードは使用しないでください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 次のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> hangBuffer = result.Buffer;
Process(ref hangBuffer, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(hangBuffer.Start, hangBuffer.End);
if (message != null)
return message;
}
警告
上記のコードは使用しない でください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 前のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
❌ メモリ不足 (OOM)
次の条件では、このコードは OutOfMemoryException が発生するまでバッファリングを続けます。
- 最大メッセージ サイズがない。
-
PipeReaderから返されたデータで、完全なメッセージが作成されない。 たとえば、もう一方の側は大きなメッセージ (たとえば、4 GB のメッセージ) を書き込みます。
警告
次のコードは使用しないでください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 次のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> thisCouldOutOfMemory = result.Buffer;
Process(ref thisCouldOutOfMemory, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(thisCouldOutOfMemory.Start, thisCouldOutOfMemory.End);
if (message != null)
return message;
}
警告
上記のコードは使用しない でください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 前のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
❌ メモリの破損
バッファーを読み取るヘルパーを記述するときは、 Advanceを呼び出す前に、返されたペイロードをコピーします。 次の例では、 Pipe が破棄したメモリを返し、次の操作 (読み取り/書き込み) に再利用できます。
警告
次のコードは使用しないでください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 次のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
public class Message
{
public ReadOnlySequence<byte> CorruptedPayload { get; set; }
}
Environment.FailFast("This code is terrible, don't use it!");
Message message = null;
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
ReadHeader(ref buffer, out int length);
if (length <= buffer.Length)
{
message = new Message
{
// Slice the payload from the existing buffer
CorruptedPayload = buffer.Slice(0, length)
};
buffer = buffer.Slice(length);
}
if (result.IsCompleted)
break;
reader.AdvanceTo(buffer.Start, buffer.End);
if (message != null)
{
// This code is broken since reader.AdvanceTo() was called with a position *after* the buffer
// was captured.
break;
}
}
return message;
}
警告
上記のコードは使用しない でください。 このサンプルを使用すると、データの損失、ハング、セキュリティの問題が発生するため、コピーしないでください。 前のサンプルは、 PipeReader の一般的な問題を説明するために提供されています。
PipeWriter
PipeWriter では、呼び出し元の代わりに書き込むバッファーを管理します。
PipeWriter は、IBufferWriter<byte> を実装します。
IBufferWriter<byte> は、追加のバッファー コピーなしで書き込みを実行するためのバッファーへのアクセスを提供します。
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
// Request at least 5 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(5);
// Write directly into the buffer.
int written = Encoding.ASCII.GetBytes("Hello".AsSpan(), memory.Span);
// Tell the writer how many bytes were written.
writer.Advance(written);
await writer.FlushAsync(cancellationToken);
}
上記のコードでは、次のようになります。
-
PipeWriterを使用して、GetMemory から少なくとも 5 バイトのバッファーを要求します。 - ASCII 文字列である
"Hello"のバイトを、返されたMemory<byte>に書き込みます。 - Advance を呼び出して、バッファーに書き込まれたバイト数を示します。
-
PipeWriterをフラッシュし、基になるデバイスにバイトを送信します。
上記の書き込みメソッドでは、PipeWriter によって提供されるバッファーが使用されています。 また、次の PipeWriter.WriteAsyncを使用することもできます。
- 既存のバッファーを
PipeWriterにコピーします。 - GetSpanを呼び出し、必要に応じてAdvanceし、FlushAsyncを呼び出します。
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer, there's no need to call Advance here
// (Write does that).
await writer.WriteAsync(helloBytes, cancellationToken);
}
キャンセル
FlushAsync では、CancellationToken を渡すことがサポートされます。
CancellationToken を渡すとき、フラッシュが保留中にトークンが取り消された場合、結果としてOperationCanceledException となります。
PipeWriter.FlushAsync では、例外を発生させることなく、PipeWriter.CancelPendingFlush を使用して、現在のフラッシュ操作を取り消す方法がサポートされます。
PipeWriter.CancelPendingFlush を呼び出すと、PipeWriter.FlushAsync または PipeWriter.WriteAsync の現在の呼び出しあるいは次の呼び出しで、FlushResult が IsCanceled に設定された true が返されます。 これは、非破壊的および非例外的な方法でフラッシュの生成を停止する場合に便利です。
PipeWriter の一般的な問題
- GetSpan および GetMemory では、少なくとも要求された量のメモリを持つバッファーを返します。 正確なバッファー サイズを想定しないでください。
- 連続する呼び出しは、同じバッファーまたは同じサイズのバッファーを返す保証はありません。
- さらにデータの書き込みを続行するには、Advance を呼び出した後に新しいバッファーを要求する必要があります。 以前に取得したバッファーに書き込むことはできません。
- GetMemory の呼び出しが不完全な場合に GetSpan または FlushAsync を呼び出すのは安全ではありません。
- フラッシュされていないデータがある間に Complete または CompleteAsync を呼び出すと、メモリが破損する可能性があります。
PipeReader と PipeWriter のヒント
System.IO.Pipelines クラスを正常に使用するには、次のヒントを使用します。
- PipeReader と PipeWriter は、該当する場合は例外を含めて、常に完了させてください。
- PipeReader.AdvanceTo を呼び出した後に、常にPipeReader.ReadAsync を呼び出します。
- 定期的に
awaitPipeWriter.FlushAsyncし、常にFlushResult.IsCompletedを確認します。IsCompletedがtrueの場合は、リーダーが完了し、書き込まれた内容がどうでもよいことを示すので、書き込みを中止します。 -
PipeWriter.FlushAsyncがアクセスできる内容を書き込んだ後、
PipeReaderを呼び出します。 -
FlushAsyncが終了するまでリーダーが起動できない場合は、FlushAsyncを呼び出さないでください。これによりデッドロックが発生する可能性があります。 -
PipeReaderやPipeWriterには、1 つのコンテキストのみがそれらを "所有" またはアクセスするようにします。 これらの型はスレッドセーフではありません。 -
ReadResult.Buffer を呼び出したり、PipeReader.AdvanceTo が完了した後に
PipeReaderにアクセスしないでください。
IDuplexPipe
IDuplexPipe は、読み取りと書き込みの両方をサポートする型のコントラクトです。 たとえば、ネットワーク接続は IDuplexPipeによって表されます。
Pipe と PipeReader を含む PipeWriter とは異なり、IDuplexPipe は全二重接続の片側を表します。
PipeWriterに書き込んだ内容は、PipeReaderから読み取られません。
ストリーム
ストリーム データの読み取りまたは書き込みを行う場合、通常は、デシリアライザーを使用してデータを読み取り、シリアライザーを使用してデータを書き込みます。 これらの読み取りおよび書き込みストリーム API のほとんどに、Stream パラメーターがあります。 これらの既存の API との統合をより容易にするために、PipeReader および PipeWriter で AsStream メソッドが公開されます。
AsStream では、Stream または PipeReader に関する PipeWriter 実装を返します。
ストリームの例
PipeReader オブジェクトとオプションの対応する作成オプションを指定して、静的PipeWriter メソッドを使用して、CreateインスタンスとStream インスタンスを作成します。
StreamPipeReaderOptions では、次のパラメーターを使用して PipeReader インスタンスの作成を制御できます。
-
StreamPipeReaderOptions.BufferSize はプールからメモリを借りるときに使用される最小バッファー サイズ (バイト単位) であり、既定値は
4096です。 -
StreamPipeReaderOptions.LeaveOpen フラグによって、
PipeReaderの完了後、基礎となるストリームを開いたままにするかどうかが決定されます。既定値はfalseです。 -
StreamPipeReaderOptions.MinimumReadSize は、新しいバッファーが割り当てられる前のバッファー内に残るバイト数のしきい値を表します。既定値は
1024です。 -
StreamPipeReaderOptions.Pool はメモリを割り当てるときに使用される
MemoryPool<byte>であり、既定値はnullです。
StreamPipeWriterOptions では、次のパラメーターを使用して PipeWriter インスタンスの作成を制御できます。
-
StreamPipeWriterOptions.LeaveOpen フラグによって、
PipeWriterの完了後、基礎となるストリームを開いたままにするかどうかが決定されます。既定値はfalseです。 -
StreamPipeWriterOptions.MinimumBufferSize は、Pool からメモリをレンタルしているときに使用する最小バッファー サイズを表します。既定値は
4096です。 -
StreamPipeWriterOptions.Pool はメモリを割り当てるときに使用される
MemoryPool<byte>であり、既定値はnullです。
重要
PipeReader メソッドを使用してPipeWriterインスタンスとCreate インスタンスを作成する場合は、Stream オブジェクトの有効期間を考慮してください。 リーダーまたはライターの使用後にストリームにアクセスする必要がある場合は、作成オプションにおいてLeaveOpenをtrueフラグに設定してください。 それ以外の場合、ストリームは閉じられます。
このコードでは、ストリームからPipeReaderメソッドを使用してPipeWriterインスタンスとCreateインスタンスを作成する方法を示します。
using System.Buffers;
using System.IO.Pipelines;
using System.Text;
class Program
{
static async Task Main()
{
using var stream = File.OpenRead("lorem-ipsum.txt");
var reader = PipeReader.Create(stream);
var writer = PipeWriter.Create(
Console.OpenStandardOutput(),
new StreamPipeWriterOptions(leaveOpen: true));
WriteUserCancellationPrompt();
var processMessagesTask = ProcessMessagesAsync(reader, writer);
var userCanceled = false;
var cancelProcessingTask = Task.Run(() =>
{
while (char.ToUpperInvariant(Console.ReadKey().KeyChar) != 'C')
{
WriteUserCancellationPrompt();
}
userCanceled = true;
// No exceptions thrown
reader.CancelPendingRead();
writer.CancelPendingFlush();
});
await Task.WhenAny(cancelProcessingTask, processMessagesTask);
Console.WriteLine(
$"\n\nProcessing {(userCanceled ? "cancelled" : "completed")}.\n");
}
static void WriteUserCancellationPrompt() =>
Console.WriteLine("Press 'C' to cancel processing...\n");
static async Task ProcessMessagesAsync(
PipeReader reader,
PipeWriter writer)
{
try
{
while (true)
{
ReadResult readResult = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = readResult.Buffer;
try
{
if (readResult.IsCanceled)
{
break;
}
if (TryParseLines(ref buffer, out string message))
{
FlushResult flushResult =
await WriteMessagesAsync(writer, message);
if (flushResult.IsCanceled || flushResult.IsCompleted)
{
break;
}
}
if (readResult.IsCompleted)
{
if (!buffer.IsEmpty)
{
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
catch (Exception ex)
{
Console.Error.WriteLine(ex);
}
finally
{
await reader.CompleteAsync();
await writer.CompleteAsync();
}
}
static bool TryParseLines(
ref ReadOnlySequence<byte> buffer,
out string message)
{
SequencePosition? position;
StringBuilder outputMessage = new();
while(true)
{
position = buffer.PositionOf((byte)'\n');
if (!position.HasValue)
break;
outputMessage.Append(Encoding.ASCII.GetString(buffer.Slice(buffer.Start, position.Value)))
.AppendLine();
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
};
message = outputMessage.ToString();
return message.Length != 0;
}
static ValueTask<FlushResult> WriteMessagesAsync(
PipeWriter writer,
string message) =>
writer.WriteAsync(Encoding.ASCII.GetBytes(message));
}
このアプリケーションによって StreamReader が使用され、ストリームとして lorem-ipsum.txt ファイルが読み取られます。これは空白行で終了する必要があります。
FileStream は、PipeReader.Create オブジェクトをインスタンス化する PipeReader に渡されます。 次に、コンソール アプリケーションから PipeWriter.Create を使用して Console.OpenStandardOutput() にその標準出力ストリームが渡されます。 この例ではキャンセルがサポートされます。
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET