events
Power BI サービスのセマンティック モデル モード
この記事では Power BI セマンティック モデル モードの技術面について説明します。 外部ホストの Analysis Services モデルへのライブ接続を表すセマンティック モデルと、Power BI Desktop で開発されたモデルに適用されます。 この記事では、各モードの原理と、Power BI 容量リソースに対する影響について説明します。
3 つのセマンティック モデル モードは次のとおりです。
"インポート" モードは、セマンティック モデルの開発に使用される最も一般的なモードです。 このモードは、インメモリ クエリのおかげでパフォーマンスが非常に高速です。 また、モデラーにとって柔軟な設計が提供され、特定の Power BI サービス機能 (Q&A、クイック分析情報など) がサポートされます。 このような長所があるため、これは新しい Power BI Desktop ソリューションを作成するときの既定モードです。
インポートされたデータは常にディスクに格納されることを理解しておくことが重要です。 クエリまたは更新を行う場合、データを Power BI 容量のメモリに完全に読み込む必要があります。 メモリに格納されると、インポート モデルではクエリ結果が非常に高速に得られます。 また、インポート モデルには、メモリに部分的に読み込まれるという概念がない点を理解することも重要です。
更新されると、データは圧縮および最適化され、VertiPaq ストレージ エンジンによってディスクに格納されます。 ディスクからメモリに読み込まれると、圧縮率は 10 倍になる可能性があります。 そのため、10 GB のソース データは約 1 GB のサイズに圧縮されると見込むことができます。 ディスク上のストレージ サイズは、圧縮サイズから 20% の削減率を達成する可能性があります サイズの違いは、Power BI Desktop ファイルのサイズとファイルのタスク マネージャーのメモリ使用量を比較することで判断できます。
設計の柔軟性は、3 つの方法で実現できます。
- データ ソースの種類や形式に関係なく、データ フローからのデータと外部データ ソースをキャッシュしてデータを統合する。
- データ準備クエリを作成するときに、一連の Power Query M 式言語 (M と呼ばれます) をすべて使用する。
- ビジネス ロジックを使ってモデルを拡張するときに、一連の Data Analysis Expressions (DAX) 関数をすべて適用する。 計算列、計算テーブル、およびメジャーがサポートされています。
次の図に示すように、インポート モデルは、サポートされている任意の数のデータ ソースの種類のデータを統合できます。
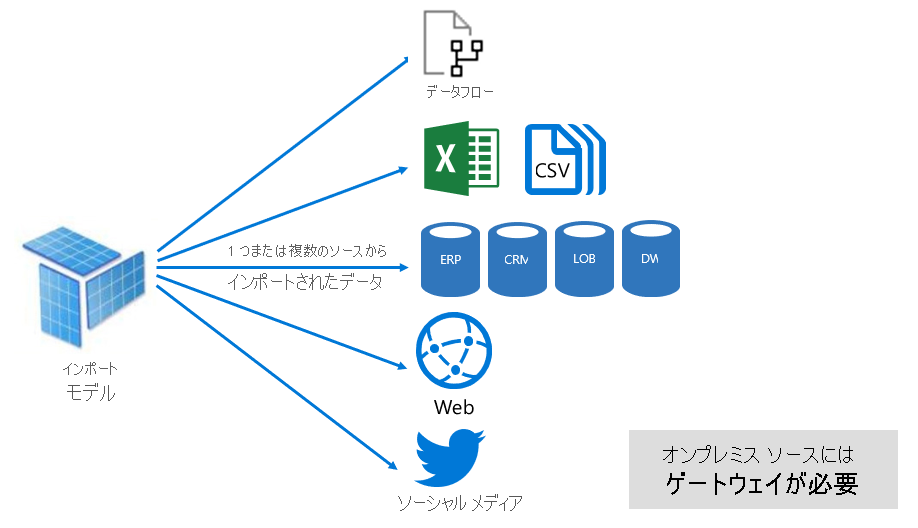
ただし、インポート モデルには優れた長所がありますが、短所もあります。
- Power BI でモデルのクエリを実行するには、モデル全体をメモリに読み込む必要があります。そのため、特にインポート モデルの数とサイズが増大すると、使用可能な容量リソースに負荷がかかる可能性があります。
- モデル データの新しさは最終更新時のものなので、通常、インポート モデルは定期的に更新する必要があります
- 完全な更新では、すべてのテーブルからすべてのデータが削除され、データ ソースから再度読み込まれます。 この操作は、Power BI サービスの時間とリソース、データ ソースという点でコストが高くなる可能性があります。
注意
Power BI では、テーブル全体の切り捨てと再読み込みを回避するために増分更新を行うことができます。 サポートされているプランとライセンスを含む詳細については、「セマンティック モデルの増分更新とリアルタイム データ」を参照してください。
Power BI サービス リソースの観点から見ると、インポート モデルに必要なものは次のとおりです。
- クエリまたは更新時にモデルを読み込むことができる十分なメモリ。
- データを更新するためのリソースと追加メモリ リソースの処理。
DirectQuery モードは、インポート モードの代わりになります。 DirectQuery モードで開発されたモデルでは、データがインポートされません。 代わりに、モデル構造を定義するメタデータのみで構成されます。 モデルに対してクエリを実行すると、基のデータ ソースからのデータの取得にネイティブ クエリが使用されます。
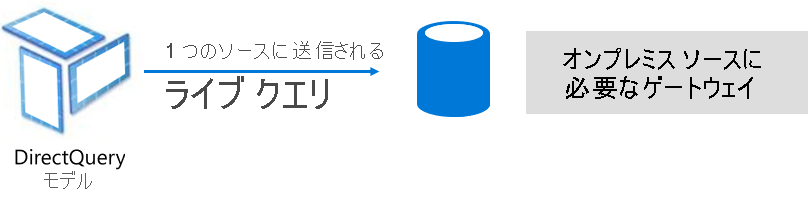
DirectQuery モデルの開発を検討する主な理由は 2 つあります。
- データの削減方法を適用してもデータ量が多すぎて、モデルに読み込むことができない場合、または事実上、更新できない場合。
- レポートとダッシュボードで、スケジュールされた更新の制限内で達成できる範囲を超えて、"準リアルタイム" のデータを配信する必要がある場合。 スケジュールされた更新の制限は、共有容量の場合は 1 日 8 回、Premium 容量の場合は 1 日 48 回です。
DirectQuery モデルにはいくつかの長所があります。
- インポート モデルのサイズの制限が適用されません。
- モデルに、データ更新のスケジュール化は必要ありません。
- レポート フィルターとスライサーを操作するときに、レポート ユーザーに最新のデータが表示されます。 レポート ユーザーは、レポート全体を更新して現在のデータを取得することもできます。
- ページの自動更新機能を使用して、リアルタイムのレポートを作成できます。
- DirectQuery モデルに基づくダッシュボード タイルを 15 分ごとの頻度で自動的に更新できます。
ただし、DirectQuery モデルに関連したいくつかの制限があります。
- Power Query および Mashup 式で使用できるのは、データ ソースによって認識されるネイティブ クエリに置き換え可能な関数のみです。
- DAX の数式は、データ ソースが理解できるネイティブ クエリに置き換え可能な関数のみを使用するように制限されています。 計算テーブルはサポートされません。
- クイック分析情報機能はサポートされません。
Power BI サービス リソースの観点から見ると、DirectQuery モデルに必要なものは次のとおりです。
- クエリ時にモデル (メタデータのみ) を読み込むための最小メモリ。
- 場合によっては、データ ソースに送信されるクエリを生成および処理するために、Power BI サービスに大量のプロセッサ リソースを使用する必要があります。 このような状況になると、特に同時実行ユーザーがモデルに対してクエリを実行すると、スループットに影響が及ぶ可能性があります。
詳細情報については、「Power BI Desktop で DirectQuery を使用する」を参照してください。
複合モードでは、インポート モードと DirectQuery モードを混在させることや、複数の DirectQuery データ ソースを統合することができます。 複合モードで開発されたモデルでは、各モデル テーブルのストレージ モードの構成がサポートされます。 このモードでは、DAX を使って定義された計算テーブルもサポートされます。
テーブル ストレージ モードは、インポート、DirectQuery、またはデュアルとして構成できます。 デュアル ストレージ モードとして構成されたテーブルはインポートでもあり、DirectQuery でもあります。この設定により、Power BI サービスでは、クエリごとに最も効率的なモードの使用を決定できます。
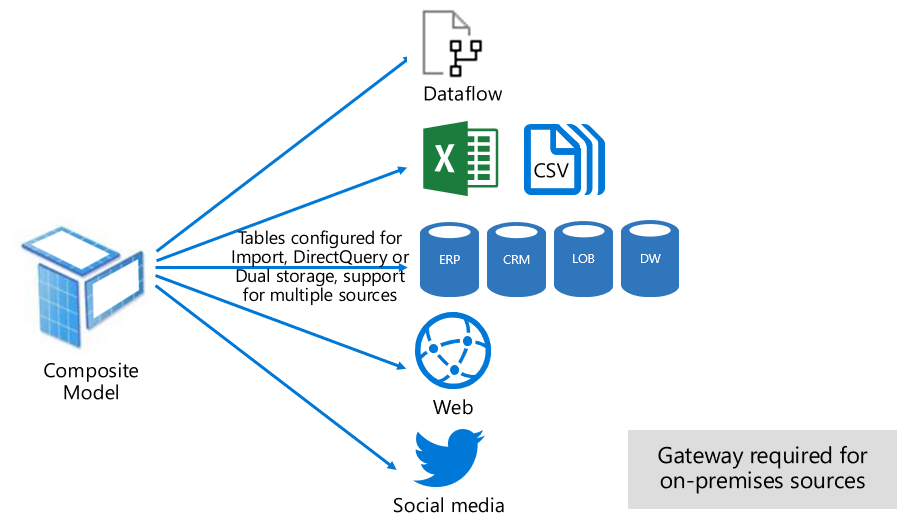
複合モデルは、インポート モードと DirectQuery モードを最大限に活用することを目指しています。 適切に構成した場合、インメモリ モデルのクエリのハイ パフォーマンスと、データ ソースからほぼリアルタイムのデータを取得する機能を組み合わせることができます。
詳細については、「Power BI Desktop で複合モデルを使用する」を参照してください。
複合モデルを開発するデータ モデラーは、インポート モードまたはデュアル ストレージ モードのディメンション型テーブルと、DirectQuery モードでのファクト型テーブルを構成する可能性があります。 モデル テーブル ロールの詳細については、「スター スキーマと Power BI での重要性を理解する」を参照してください。
たとえば、デュアル モードの Product ディメンション型テーブルと、DirectQuery モードの Sales ファクト型テーブルがあるモデルを考えます。 Product テーブルに対しては、メモリ内から効率的かつ迅速にクエリを実行し、レポート スライサーを表示できます。 Sales テーブルに対しては、関連する Product テーブルを使用して DirectQuery モードでクエリを実行することもできます。 後者のクエリでは、Product テーブルと Sales テーブルを結合し、スライサー値でフィルター処理する 1 つの効率的なネイティブ SQL クエリを生成できます。
複合モデルを開発するデータ モデラーは、ファクト テーブルをハイブリッド テーブルとして構成することもできます。 ハイブリッド テーブルとは、1 つまたは複数のインポート パーティションと 1 つの DirectQuery パーティションが含まれているテーブルです。 ハイブリッド テーブルの利点は、次の視覚エフェクトで示すように、それに対してメモリ内から効率的かつ迅速にクエリを実行できると同時に、最後のインポート サイクル後に発生したデータ ソースからの最新のデータ変更を含めることができることです。
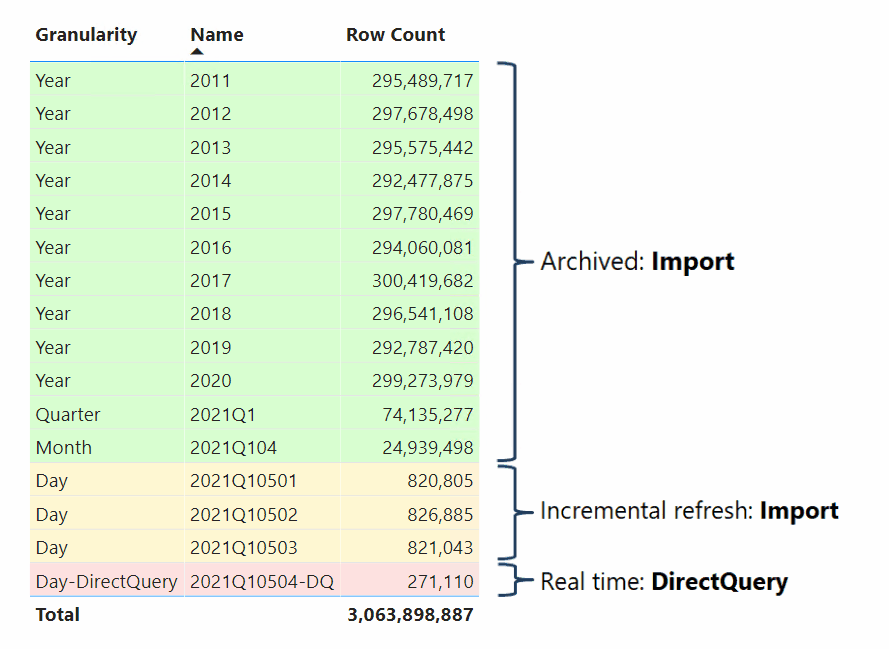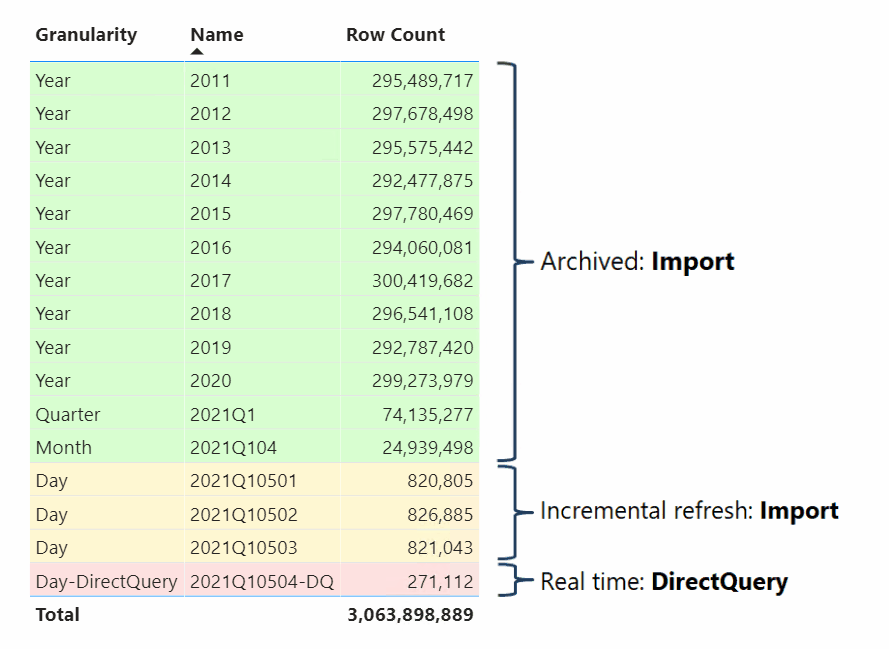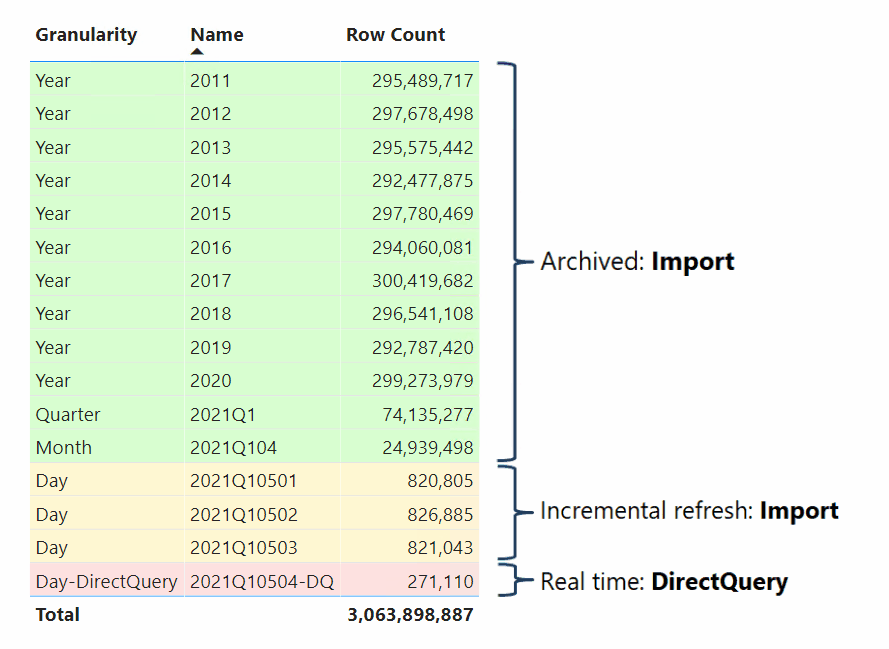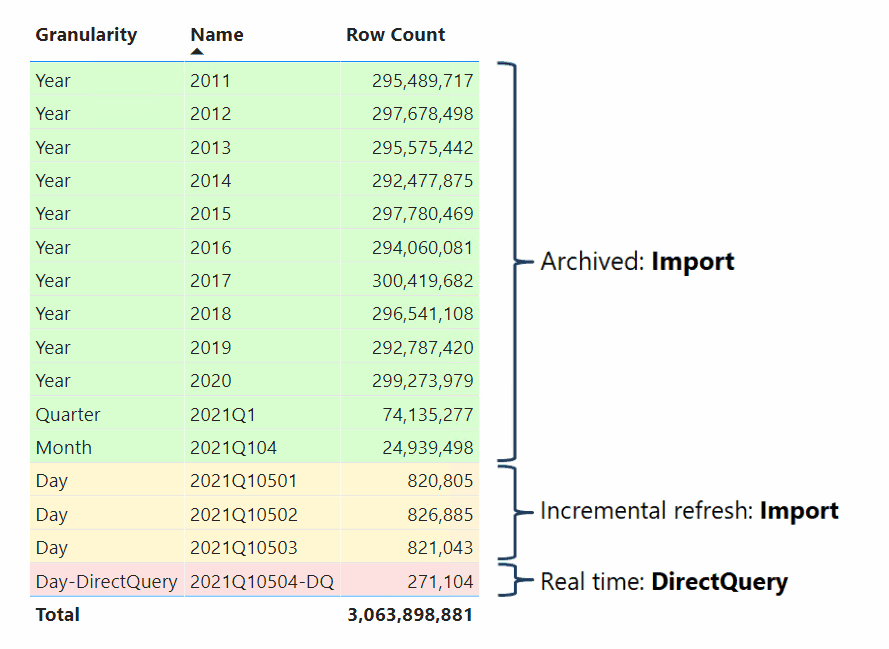
ハイブリッド テーブルを作成するには、Power BI Desktop で増分更新ポリシーを構成し、[DirectQuery で最新データをリアルタイムで取得します (Premium のみ)] オプションを有効にする方法が最も簡単です。 Power BI でこのオプションが有効になっている増分更新ポリシーが適用されると、先ほどの図で示されているパーティション構成のようなテーブルはパーティション分割されます。 パフォーマンスを確実に向上させるには、ディメンションの種類のテーブルをデュアル ストレージ モードで構成することで、Power BI で DirectQuery パーティションに対してクエリを実行する際に効率的なネイティブ SQL クエリが生成されるようにします。
注意
Power BI では、セマンティック モデルが Premium 容量のワークスペースでホストされている場合にのみ、ハイブリッド テーブルをサポートします。 したがって、DirectQuery で最新のデータをリアルタイムで取得するオプションを使用して増分更新ポリシーを構成する場合は、セマンティック モデルを Premium ワークスペースにアップロードする必要があります。 詳細については、「データ セットの増分更新とリアルタイム データ」を参照してください。
また、インポート テーブルをハイブリッド テーブルに変換することもできます。それには、表形式モデルのスクリプト言語 (TMSL) または表形式オブジェクト モデル (TOM) を使用して DirectQuery パーティションを追加するか、あるいはサードパーティ製のツールを使用します。 たとえば、データの大部分はデータ ウェアハウスに残され、最新のデータの一部だけがインポートされるようにファクト テーブルをパーティション分割することができます。 この方法を使用すると、このデータの大部分がアクセス頻度の低い履歴データである場合に、パフォーマンスを容易に最適化することができます。 ハイブリッド テーブルでは、インポート パーティションを複数使用できますが、DirectQuery パーティションについては 1 だけです。
その他のリソース
トレーニング
認定資格
Microsoft Certified: Power BI Data Analyst Associate - Certifications
Microsoft Power BI でデータをモデル化、視覚化、分析するためのビジネス要件と技術要件に沿った方法とベスト プラクティスを示します。