Azure Toolkit for IntelliJ를 사용하여 VPN을 통해 HDInsight에서 원격으로 Apache Spark 애플리케이션 디버그
SSH를 통해 원격으로 Apache Spark 애플리케이션을 디버그하는 것이 좋습니다. 자세한 내용은 Azure Toolkit for IntelliJ를 사용하여 SSH를 통해 HDInsight 클러스터에서 원격으로 Apache Spark 애플리케이션 디버그를 참조하세요.
이 문서에서는 IntelliJ용 Azure 도구 키트의 HDInsight 도구를 사용하여 HDInsight Spark 클러스터에서 Spark 작업을 제출한 다음 데스크톱 컴퓨터에서 원격으로 디버그하는 방법에 대한 단계별 지침을 제공합니다. 이러한 작업을 완료하려면 다음과 같은 개략적인 단계를 수행해야 합니다.
- 사이트 간 또는 지점 및 사이트 간 Azure Virtual Network를 만듭니다. 이 문서의 단계에서는 사이트 간 네트워크를 사용하는 것으로 가정합니다.
- 사이트 간 가상 네트워크의 일부인 HDInsight에서 Spark 클러스터를 만듭니다.
- 클러스터 헤드 노드 및 데스크톱 간의 연결을 확인합니다.
- IntelliJ IDEA에서 Scala 애플리케이션을 만든 다음, 원격 디버깅을 위해 구성합니다.
- 애플리케이션을 실행하고 디버그합니다.
필수 구성 요소
- Azure 구독. 자세한 내용은 Azure 평가판 얻기를 참조하세요.
- HDInsight의 Apache Spark 클러스터. 자세한 내용은 Azure HDInsight에서 Apache Spark 클러스터 만들기를 참조하세요.
- Oracle Java Development 키트. Oracle 웹 사이트에서 설치할 수 있습니다.
- IntelliJ IDEA. 이 문서에서는 버전 2017.1을 사용합니다. JetBrains 웹 사이트에서 설치할 수 있습니다.
- IntelliJ용 Azure 도구 키트의 HDInsight 도구 IntelliJ용 HDInsight 도구는 IntelliJ용 Azure 도구 키트에 포함되어 제공됩니다. Azure 도구 키트를 설치하는 방법에 대한 지침은 IntelliJ용 Azure 도구 키트 설치를 참조하세요.
- IntelliJ IDEA에서 Azure 구독에 로그인. Azure Toolkit for IntelliJ를 사용하여 HDInsight 클러스터용 Apache Spark 애플리케이션 만들기의 지침을 따릅니다.
- 예외 해결 방법. Windows 컴퓨터에서 원격 디버깅을 위해 로컬 Spark Scala 애플리케이션을 실행하는 동안 예외가 발생할 수 있습니다. 이 예외는 SPARK-2356에 설명되어 있으며 Windows에서 누락된 WinUtils.exe 파일 때문에 발생합니다. 이 오류를 해결하려면 Winutils.exe를 다운로드하여 C:\WinUtils\bin 등의 위치에 저장해야 합니다. HADOOP_HOME 환경 변수를 추가하고 이 변수 값을 C\WinUtils로 설정합니다.
1단계: Azure Virtual Network 만들기
아래 링크의 지침을 따라 Azure Virtual Network를 만든 다음 데스크톱 컴퓨터와 가상 네트워크 간의 연결을 확인합니다.
- Azure Portal을 사용하여 사이트 간 VPN 연결로 VNet 만들기
- PowerShell을 사용하여 사이트 간 VPN 연결로 VNet 만들기
- PowerShell을 사용하여 가상 네트워크에 지점 및 사이트 간 연결 구성
2단계: HDInsight Spark 클러스터 만들기
또한 만든 Azure Virtual Network의 일부인 Azure HDInsight에서 Apache Spark 클러스터도 만드는 것이 좋습니다. HDInsight에서 Linux 기반 클러스터 만들기에서 제공되는 정보를 사용합니다. 선택적 구성의 일부로 이전 단계에서 만든 Azure Virtual Network를 선택합니다.
3단계: 클러스터 헤드 노드 및 데스크톱 간의 연결 확인
헤드 노드의 IP 주소를 가져옵니다. 클러스터에 대한 Ambari UI를 엽니다. 클러스터 블레이드에서 대시보드를 선택합니다.
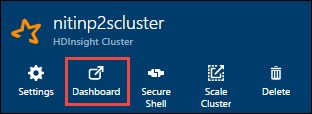
Ambari UI에서 호스트를 선택합니다.

헤드 노드, 작업자 노드 및 zookeeper 노드 목록이 표시됩니다. 헤드 노드에는 hn* 접두사가 붙습니다. 첫 번째 헤드 노드를 선택합니다.
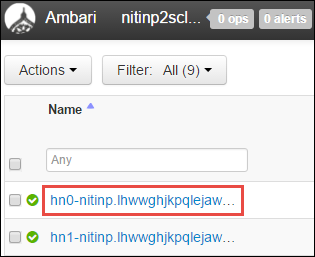
열리는 페이지 아래쪽의 요약 창에서 헤드 노드의 IP 주소 및 호스트 이름을 복사합니다.
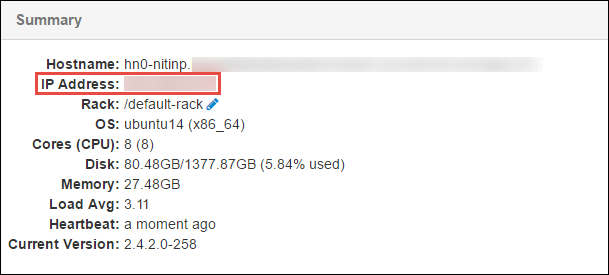
헤드 노드의 IP 주소 및 호스트 이름을 Spark 작업을 실행하고 원격으로 디버그하려는 컴퓨터의 호스트 파일에 추가합니다. 이렇게 하면 IP 주소뿐만 아니라 호스트 이름을 사용하여 헤드 노드와 통신할 수 있습니다.
a. 관리자 권한으로 메모장 파일을 엽니다. 파일 메뉴에서 열기를 선택한 다음 hosts 파일의 위치를 찾습니다. Windows 컴퓨터에서 이 위치는 C:\Windows\System32\Drivers\etc\hosts입니다.
b. hosts 파일에 다음 정보를 추가합니다.
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netHDInsight 클러스터에서 사용되는 Azure Virtual Network에 연결된 컴퓨터에서 IP 주소뿐만 아니라 호스트 이름을 사용하여 두 헤드 노드에 ping을 실행할 수 있는지 확인합니다.
SSH를 사용하여 HDInsight 클러스터에 연결의 지침을 사용하여 SSH를 통해 클러스터 헤드 노드에 연결합니다. 클러스터 헤드 노드에서 데스크톱 컴퓨터의 IP 주소에 ping을 실행합니다. 컴퓨터에 할당된 다음 두 IP 주소에 대한 연결을 테스트합니다.
- 네트워크 연결용
- Azure Virtual Network용
다른 헤드 노드에서 해당 단계를 반복합니다.
4단계: Azure Toolkit for IntelliJ의 HDInsight 도구를 사용하여 Apache Spark Scala 애플리케이션 만들기 및 원격 디버깅이 가능하도록 구성
IntelliJ IDEA를 열고 새 프로젝트를 만듭니다. 새 프로젝트 대화 상자에서 다음을 수행합니다.
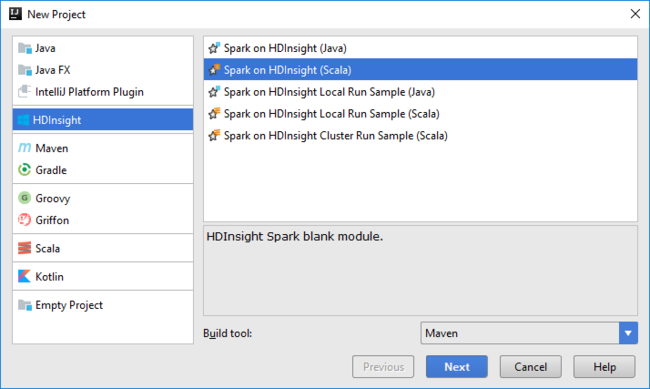
a. HDInsight>HDInsight의 Spark(Scala)를 선택합니다.
b. 다음을 선택합니다.
다음 새 프로젝트 대화 상자에서 다음을 수행한 후 마침을 선택합니다.
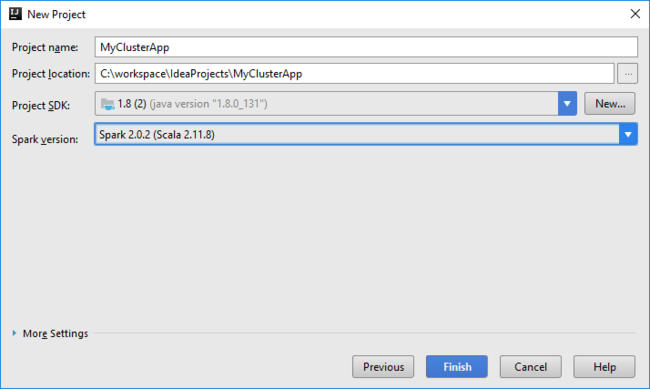
프로젝트 이름 및 위치를 입력합니다.
프로젝트 SDK 드롭다운 목록에서 Spark 2.x 클러스터에 대해 Java 1.8을 선택하거나 Spark 1.x 클러스터에 대해 Java 1.7을 선택합니다.
Spark 버전 드롭다운 목록에서 Scala 프로젝트 생성 마법사는 Spark SDK 및 Scala SDK에 대한 적절한 버전을 통합합니다. Spark 클러스터 버전이 2.0 이전인 경우 Spark 1.x를 선택합니다. 그렇지 않으면 Spark2.x를 선택합니다. 이 예제에서는 Spark 2.0.2(Scala 2.11.8)를 사용합니다.
Spark 프로젝트가 자동으로 아티팩트를 만듭니다. 이 아티팩트를 보려면 다음을 수행합니다.
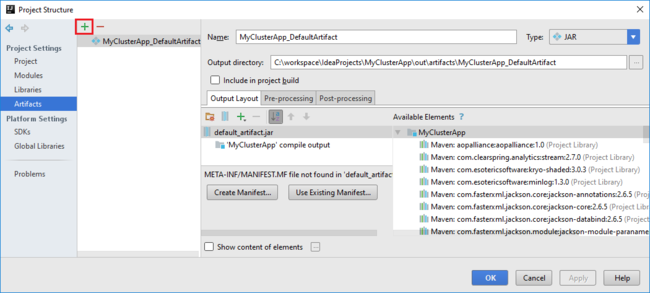
a. 파일 메뉴에서 프로젝트 구조를 선택합니다.
b. 프로젝트 구조 대화 상자에서 아티팩트를 선택하여 만든 기본 아티팩트를 봅니다. 더하기 기호(+)를 선택하여 사용자 고유의 아티팩트를 만들 수도 있습니다.
프로젝트에 라이브러리를 추가합니다. 라이브러리를 추가하려면 다음을 수행합니다.
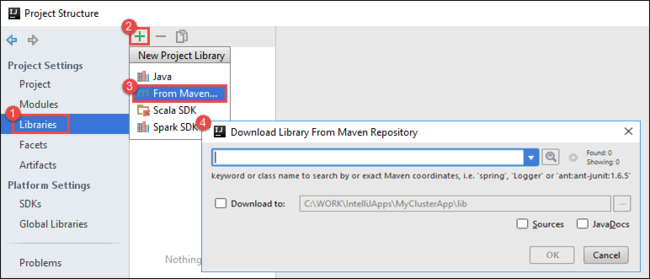
a. 프로젝트 트리에서 프로젝트 이름을 마우스 오른쪽 단추로 클릭한 다음 모듈 설정 열기를 선택합니다.
b. 프로젝트 구조 대화 상자에서 라이브러리를 선택하고 (+) 기호를 선택한 다음, Maven에서를 선택합니다.
c. Maven 리포지토리에서 라이브러리 다운로드 대화 상자에서 다음 라이브러리를 검색하고 추가합니다.
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
클러스터 헤드 노드에서
yarn-site.xml및core-site.xml을 복사하고 프로젝트에 추가합니다. 다음 명령을 사용하여 파일을 복사합니다. Cygwin을 사용하여 클러스터 헤드 노드에서 파일을 복사하도록 다음scp명령을 실행할 수 있습니다.scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .데스크톱의 호스트 파일에 대한 클러스터 헤드 노드 IP 주소 및 호스트 이름을 이미 추가했으므로 다음과 같이
scp명령을 사용할 수 있습니다.scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .이러한 파일을 프로젝트에 추가하려면 프로젝트 트리의 /src 폴더 아래에 복사합니다(예:
<your project directory>\src).core-site.xml파일을 업데이트하여 다음과 같이 변경합니다.a. 암호화된 키를 바꿉니다.
core-site.xml파일은 클러스터와 연결된 스토리지 계정에 암호화된 키를 포함합니다. 프로젝트에 추가한core-site.xml파일에서 암호화된 키를 기본 스토리지 계정과 연결된 실제 스토리지 키로 대체합니다. 자세한 내용은 스토리지 계정 액세스 키 관리를 참조하세요.<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b.
core-site.xml에서 다음 항목을 제거합니다.<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>c. 파일을 저장합니다.
애플리케이션에 대한 기본 클래스를 추가합니다. 프로젝트 탐색기에서 src를 마우스 오른쪽 단추로 클릭하고 새로 만들기를 가리킨 다음 Scala 클래스를 선택합니다.
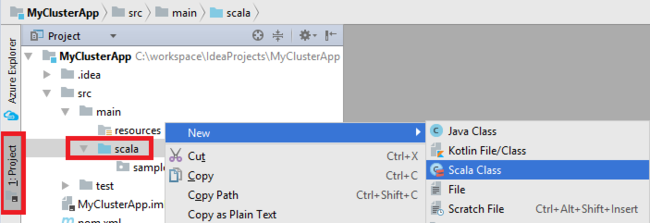
새 Scala 클래스 만들기 대화 상자에서 이름을 제공하고 종류 상자에 개체를 선택한 다음 확인을 선택합니다.
MyClusterAppMain.scala파일에서 다음 코드를 붙여 넣습니다. 이 코드는 Spark 컨텍스트를 만들고SparkSample개체에서executeJob메서드를 엽니다.import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }8 및 9단계를 반복하여
*SparkSample이라는 새 Scala 개체를 추가합니다. 이 클래스에 다음 코드를 추가합니다. 이 코드는 HVAC.csv(모든 HDInsight Spark 클러스터에서 사용 가능)에서 데이터를 읽습니다. 또한 CSV 파일의 일곱 번째 열에 한 자리 수만 있는 행을 검색하고, 출력을 클러스터의 기본 스토리지 컨테이너 아래의 /HVACOut에 씁니다.import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }8 및 9단계를 반복하여
RemoteClusterDebugging이라는 새 클래스를 추가합니다. 이 클래스는 애플리케이션 디버깅에 사용되는 Spark 테스트 프레임워크를 구현합니다. 다음 코드를RemoteClusterDebugging클래스에 추가합니다.import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }유의해야 할 몇 가지 중요한 사항은 다음과 같습니다.
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar")의 경우 Spark 어셈블리 JAR를 지정된 경로의 클러스터 스토리지에서 사용할 수 있는지 확인합니다.setJars에서 아티팩트 JAR을 만들 위치를 지정합니다. 일반적으로<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jar입니다.
*RemoteClusterDebugging클래스에서 마우스 오른쪽 단추로test키워드를 클릭하고 RemoteClusterDebugging 구성 만들기를 선택합니다.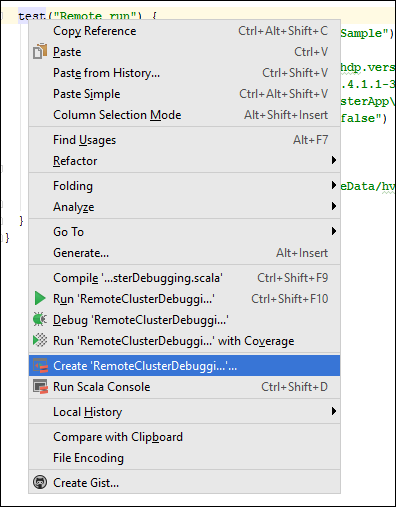
RemoteClusterDebugging 구성 만들기 대화 상자에서 구성에 대한 이름을 입력한 다음 Test kind를 테스트 이름으로 선택합니다. 다른 모든 값은 기본 설정으로 둡니다. 적용을 선택한 다음 확인을 선택합니다.
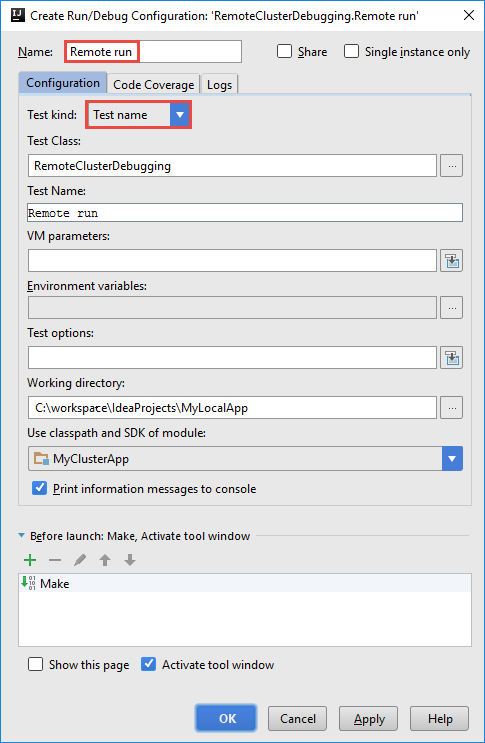
이제 메뉴 모음에 원격 실행 구성 드롭다운 목록이 표시됩니다.

5단계: 디버그 모드에서 애플리케이션 실행
IntelliJ IDEA 프로젝트에서
SparkSample.scala를 열고val rdd1옆에 중단점을 만듭니다. 중단점 만들기 팝업 메뉴에서 함수 executeJob의 줄을 선택합니다.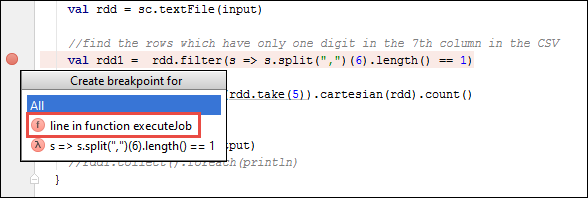
애플리케이션을 실행하려면 원격 실행 구성 드롭다운 목록 옆에 있는 디버그 실행 단추를 선택합니다.

프로그램 실행이 중단점에 도달하면 아래 창에 디버거 탭이 표시됩니다.
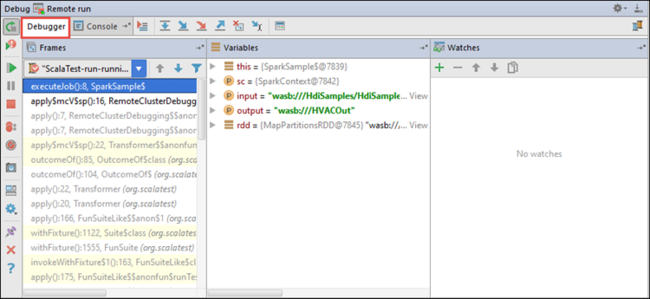
조사식을 추가하려면 (+) 아이콘을 선택합니다.
이 예제에서는 변수
rdd1이 만들어지기 전에 애플리케이션이 중단되었습니다. 이 조사식을 사용하여 변수rdd의 처음 5개 행을 볼 수 있습니다. Enter를 선택합니다.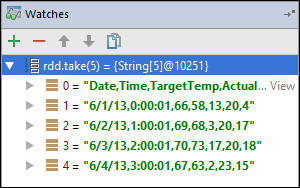
이전 이미지에서 보는 것은 런타임 시이며 테라바이트의 데이터를 쿼리하고 애플리케이션이 진행되는 방법을 디버그할 수 있습니다. 예를 들어 이전 이미지에 표시된 출력에서 출력의 첫 번째 행이 헤더임을 볼 수 있습니다. 이 출력을 기반으로 필요한 경우 애플리케이션 코드를 헤더 행을 건너뛰도록 수정할 수 있습니다.
이제 프로그램 다시 시작 아이콘을 선택하여 애플리케이션 실행을 진행할 수 있습니다.
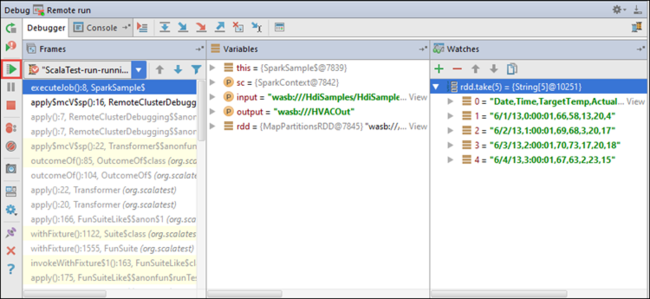
애플리케이션이 성공적으로 완료되면 다음과 유사한 출력이 표시됩니다.
다음 단계
시나리오
- BI와 Apache Spark: BI 도구와 함께 HDInsight의 Spark를 사용하여 대화형 데이터 분석 수행
- Machine Learning과 Apache Spark: HVAC 데이터를 사용하여 건물 온도를 분석하는 데 HDInsight의 Spark 사용
- Machine Learning과 Apache Spark: HDInsight의 Spark를 사용하여 식품 검사 결과 예측
- HDInsight의 Apache Spark를 사용한 웹 사이트 로그 분석
애플리케이션 만들기 및 실행
도구 및 확장
- Azure Toolkit for IntelliJ를 사용하여 HDInsight 클러스터용 Apache Spark 애플리케이션 만들기
- Azure Toolkit for IntelliJ를 사용하여 SSH를 통해 원격으로 Apache Spark 애플리케이션 디버그
- Azure Toolkit for Eclipse의 HDInsight 도구를 사용하여 Apache Spark 애플리케이션 만들기
- HDInsight에서 Apache Spark 클러스터와 함께 Apache Zeppelin Notebook 사용
- HDInsight의 Apache Spark 클러스터에서 Jupyter Notebook에 사용할 수 있는 커널
- Jupyter Notebook에서 외부 패키지 사용
- 컴퓨터에 Jupyter를 설치하고 HDInsight Spark 클러스터에 연결