이 문서에서는 GPU 하드웨어 예약 2단계에서 진정한 GPU-GPU 동기화에 사용할 수 있는 GPU 펜스 동기화 개체에 대해 설명합니다. 이 기능은 Windows 11 버전 24H2(WDDM 3.2)부터 지원됩니다. 그래픽 드라이버 개발자는 WDDM 2.0 및 GPU 하드웨어 예약 1단계를 잘 알고 있어야 합니다.
WDDM 2.x의 모니터링된 펜스 동기화 개체
WDDM 2.x의 모니터링되는 펜스 동기화 개체 는 다음 작업을 지원합니다.
- CPU는 다음 중 하나를 통해 모니터링되는 펜스 값에서 대기합니다.
- CPU VA(가상 주소)를 사용하여 폴링합니다.
- CPU가 모니터링되는 새 펜스 값을 관찰할 때 신호를 받는 Dxgkrnl 내에서 차단 대기 대기를 큐에 대기합니다.
- 모니터링되는 값의 CPU 신호입니다.
- 모니터링되는 펜스 GPU VA에 쓰고 모니터링된 펜스 신호를 발생시켜 CPU에 값 업데이트를 알리는 인터럽트를 발생시켜 모니터링되는 값의 GPU 신호입니다.
지원되지 않는 것은 모니터링되는 펜스 값에 대한 네이티브 온-더-GPU 대기였습니다. 대신 OS는 CPU에서 대기한 값에 따라 달라지는 GPU 작업을 보유했습니다. 값이 신호를 받은 경우에만 이 작업을 GPU에 릴리스했습니다.
GPU 네이티브 펜스 동기화 개체 추가됨
WDDM 3.2부터 모니터링되는 펜스 개체는 다음과 같은 추가 기능을 지원하도록 확장되었습니다.
- GPU는 CPU 왕복 없이 고성능 엔진-엔진 동기화를 허용하는 모니터링된 펜스 값을 대기합니다.
- CPU 웨이터가 있는 GPU 펜스 신호에 대해서만 조건부 인터럽트 알림입니다. 이 기능을 사용하면 모든 GPU 작업이 대기 중일 때 CPU가 저전력 상태로 진입할 수 있으므로 상당한 전력 절약이 가능합니다.
- GPU 로컬 메모리의 펜스 값 스토리지(시스템 메모리와 반대).
GPU 네이티브 펜스 동기화 개체 디자인
다음 다이어그램에서는 CPU와 GPU 간에 공유되는 동기화 개체 상태에 초점을 맞춘 GPU 네이티브 펜스 개체의 기본 아키텍처를 보여 줍니다.
: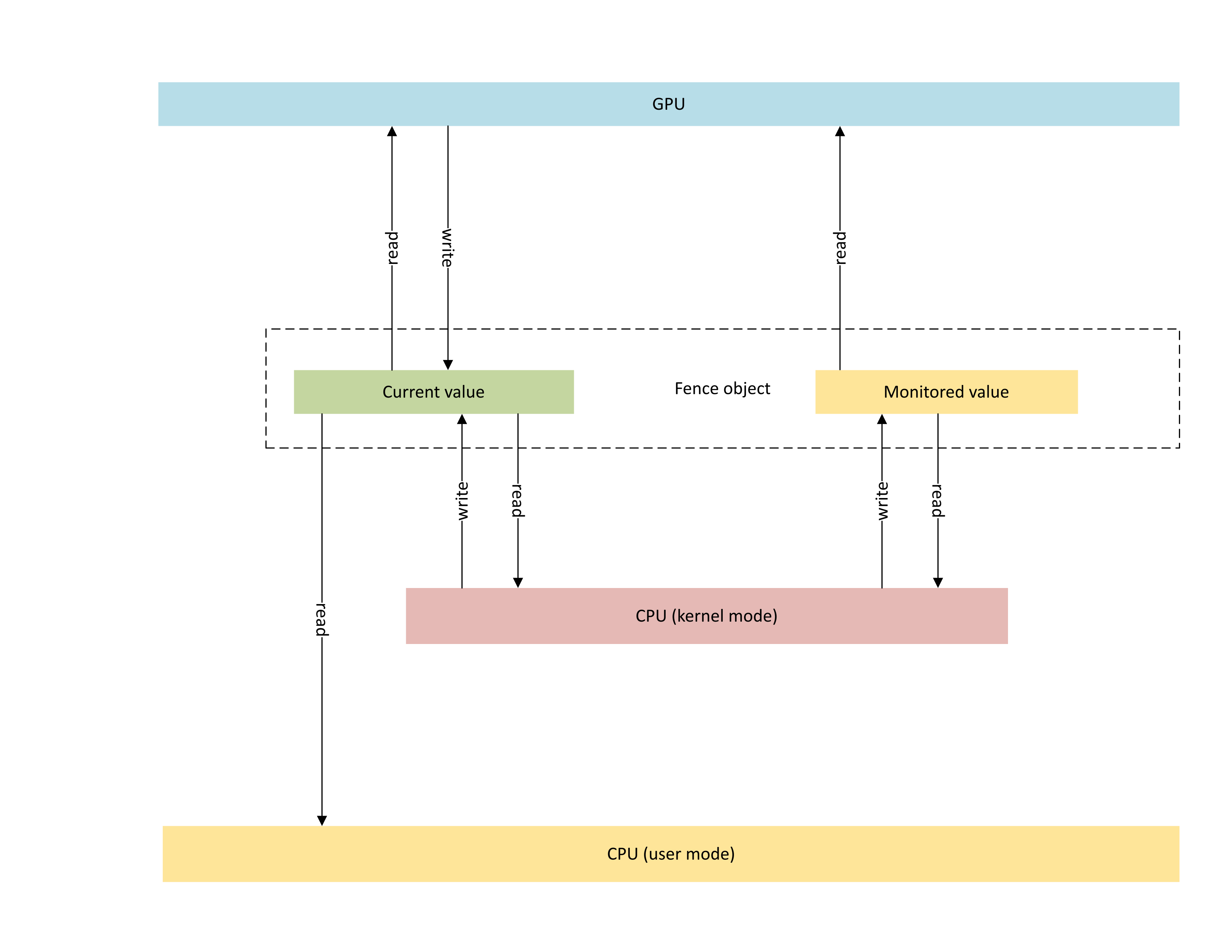
다이어그램에는 다음 두 가지 주요 구성 요소가 포함되어 있습니다.
현재 값(이 문서에서 CurrentValue라고 함). 이 메모리 위치에는 현재 신호를 받은 64비트 펜스 값이 포함됩니다. CurrentValue 는 CPU(커널 모드에서 쓰기 가능, 사용자 및 커널 모드 모두에서 읽을 수 있음) 및 GPU(GPU 가상 주소를 사용하여 읽기 가능하고 쓰기 가능) 둘 다에 매핑되고 액세스할 수 있습니다. CurrentValue 를 사용하려면 CPU 및 GPU 관점에서 64비트 쓰기가 원자성이어야 합니다. 즉, 높고 낮은 32비트의 업데이트는 찢어질 수 없으며 동시에 표시되어야 합니다. 이 개념은 이미 모니터링되는 기존 펜스 개체에 있습니다.
모니터링된 값(이 문서에서 MonitoredValue라고 함). 이 메모리 위치에는 CPU가 1을 뺀 값에서 현재 대기한 값이 가장 적습니다. MonitoredValue 는 CPU(커널 모드에서 읽기 가능 및 쓰기 가능, 사용자 모드 액세스 없음) 및 GPU(GPU VA를 사용하여 읽을 수 있음, 쓰기 권한 없음) 둘 다에 매핑되고 액세스할 수 있습니다. OS는 지정된 펜스 개체에 대한 미해결 CPU 웨이터 목록을 유지 관리하며, 웨이터가 추가 및 제거됨에 따라 MonitoredValue를 업데이트합니다. 미해결 웨이터가 없으면 값이 UINT64_MAX 설정됩니다. 이 개념은 GPU 네이티브 펜스 동기화 개체의 새로운 개념입니다.
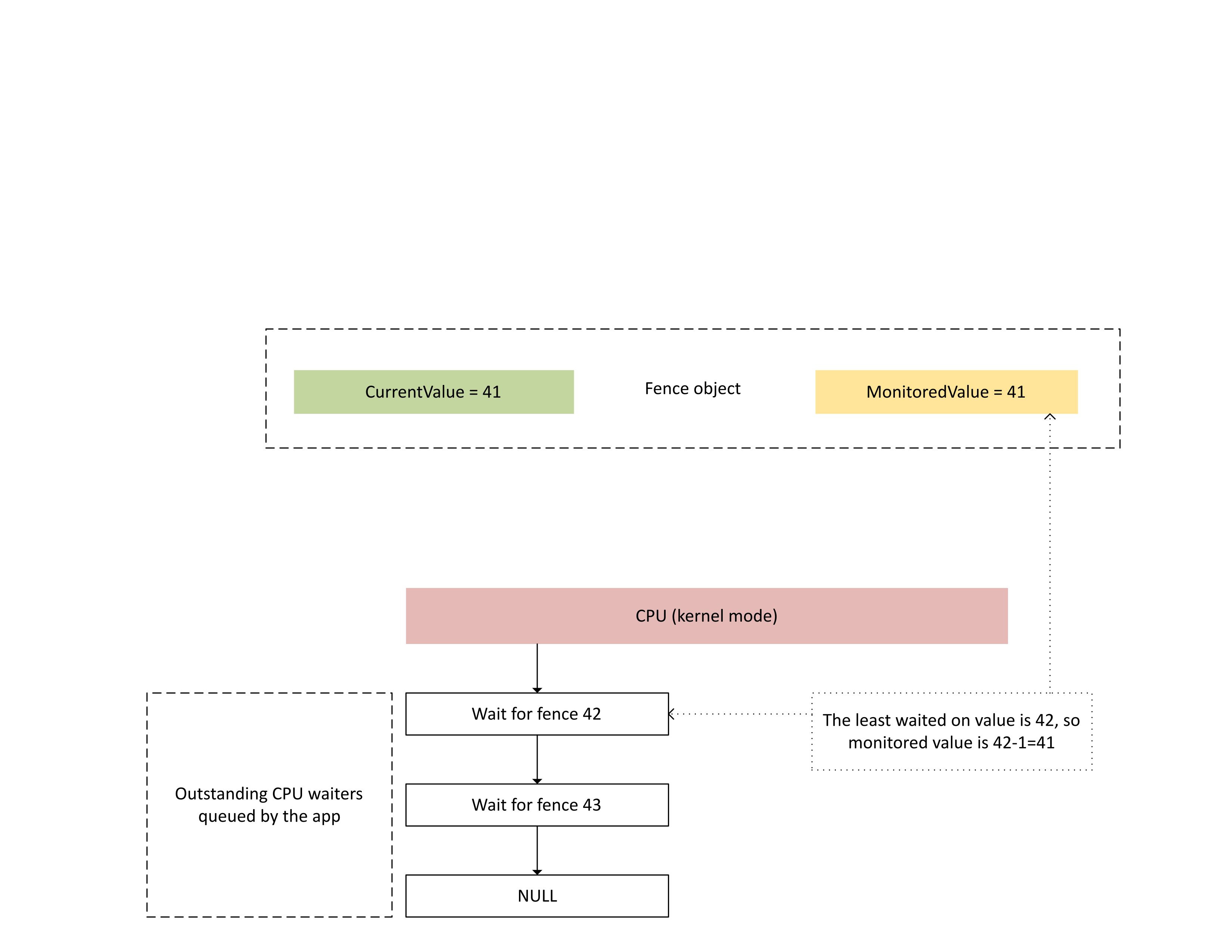
다음 다이어그램은 Dxgkrnl이 모니터링되는 특정 펜스 값에서 미해결 CPU 웨이터를 추적하는 방법을 보여 줍니다. 또한 지정된 시점에서 모니터링된 펜스 값 집합을 보여 주었습니다. CurrentValue 와 MonitoredValue 는 모두 41입니다. 즉, 다음을 의미합니다.
- GPU는 펜스 값 41까지 모든 작업을 완료했습니다.
- CPU는 41보다 작거나 같은 펜스 값에서 대기하지 않습니다.
:
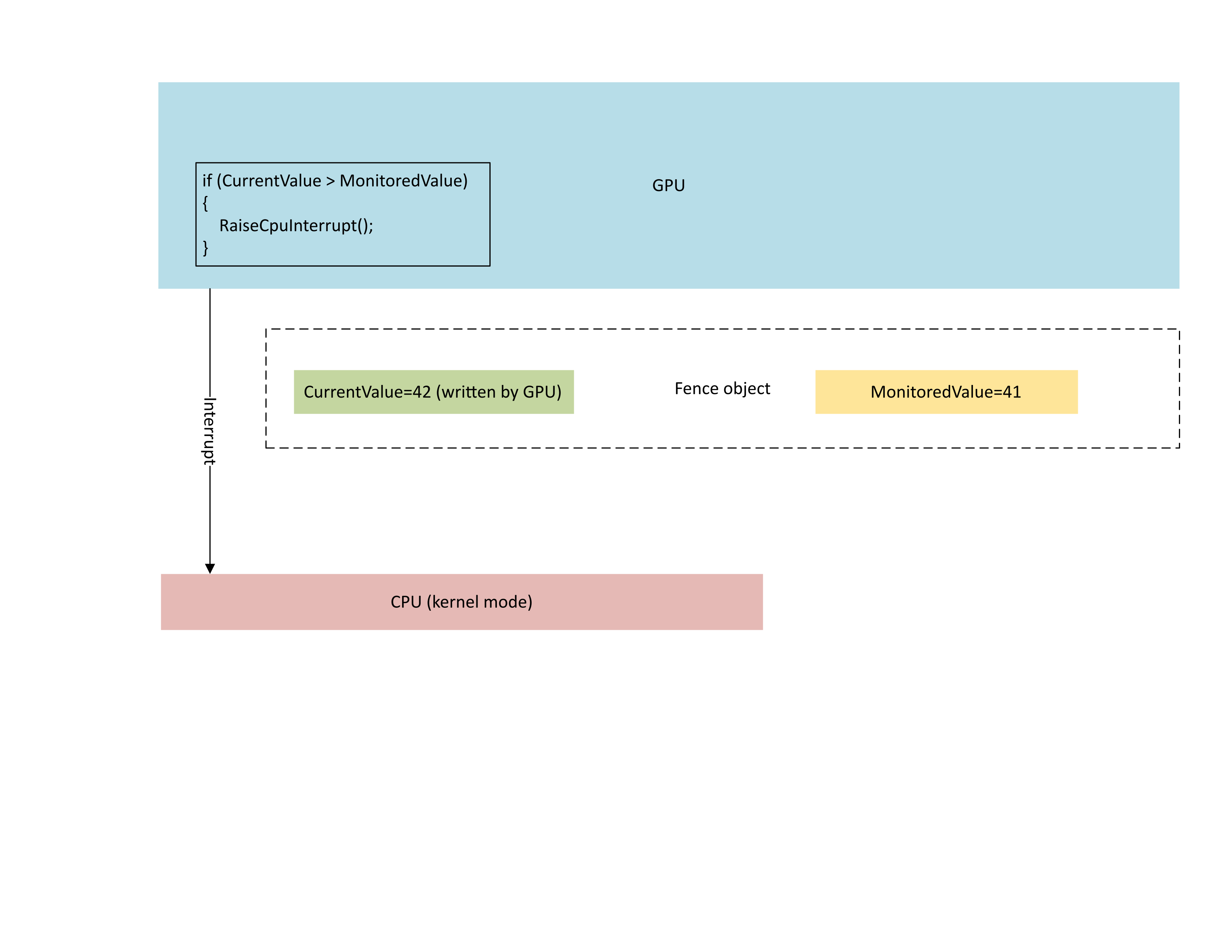
다음 다이어그램은 GPU의 CMP(컨텍스트 관리 프로세서)가 새 펜스 값이 모니터링된 값보다 큰 경우에만 조건부로 CPU 인터럽트를 발생시키는 것을 보여 줍니다. 이러한 인터럽트는 새로 작성된 값에 만족할 수 있는 미해결 CPU 웨이터가 있음을 의미합니다.
:
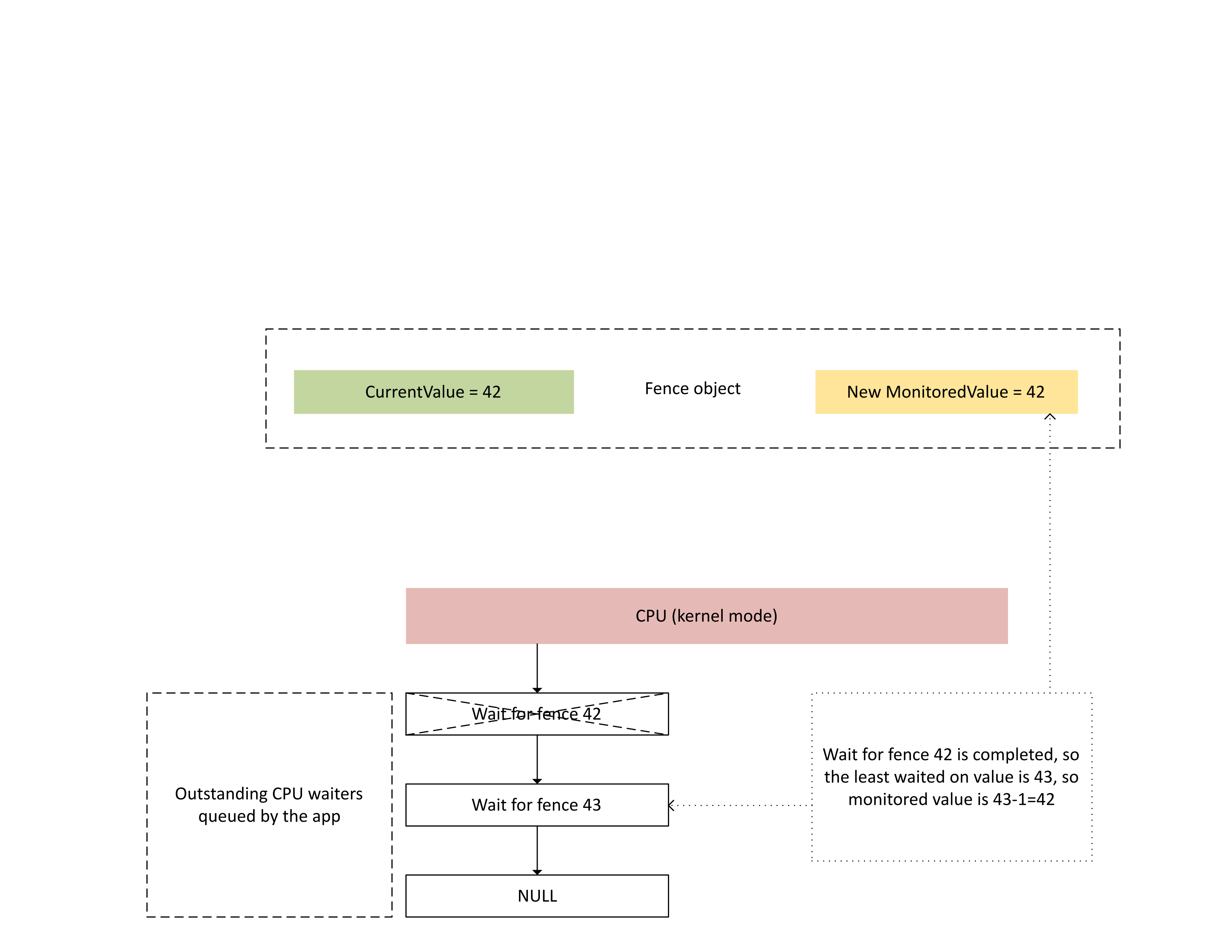
CPU가 이 인터럽트 처리 시 Dxgkrnl 은 다음 다이어그램에 설명된 대로 다음 작업을 수행합니다.
- 새로 작성된 펜스에 만족된 CPU 웨이터의 차단을 해제합니다.
- 모니터링된 값이 1을 뺀 값에서 대기한 최소 미해결 값에 해당하도록 진행합니다.
:
현재 및 모니터링되는 펜스 값에 대한 실제 메모리 스토리지
지정된 펜스 개체 의 경우 CurrentValue 및 MonitoredValue 는 별도의 위치에 저장됩니다.
공유할 수 없는 Fence 개체에는 동일한 메모리 페이지에 압축된 동일한 프로세스 내의 여러 펜스 개체에 대한 펜스 값 스토리지가 있습니다. 값은 이 문서의 뒷부분에 설명된 네이티브 펜스 KMD 캡에 지정된 보폭 값에 따라 압축됩니다.
공유할 수 있는 Fence 개체는 다른 펜스 개체와 공유되지 않는 메모리 페이지에 현재 및 모니터링된 값을 배치합니다.
현재 값
현재 값은 D3DDDI_NATIVEFENCE_TYPE 지정된 펜스 유형에 따라 시스템 메모리 또는 GPU 로컬 메모리에 상주할 수 있습니다.
크로스 어댑터 펜스의 현재 값은 항상 시스템 메모리에 있습니다.
현재 값이 시스템 메모리에 저장되면 스토리지는 내부 시스템 메모리 풀에서 할당됩니다.
현재 값이 로컬 메모리에 저장되면 드라이버가 D3DKMDT_FENCESTORAGESURFACEDATA 지정한 메모리 세그먼트에서 스토리지가 할당됩니다.
모니터링되는 값
모니터링되는 값은 D3DDDI_NATIVEFENCE_TYPE 따라 시스템 또는 GPU 로컬 메모리에 상주할 수도 있습니다.
모니터링된 값이 시스템 메모리에 저장되면 OS는 내부 시스템 메모리 풀에서 스토리지를 할당합니다.
모니터링된 값이 로컬 메모리에 저장되면 OS는 드라이버가 D3DKMDT_FENCESTORAGESURFACEDATA 지정한 메모리 세그먼트에서 스토리지를 할당합니다.
OS의 CPU 대기 조건이 변경되면 KMD의 DxgkDdiUpdateMonitoredValues 콜백을 호출하여 KMD에 모니터링된 값을 지정된 값으로 업데이트하도록 지시합니다.
동기화 문제
앞에서 설명한 메커니즘은 현재 값과 모니터링된 값의 CPU 및 GPU 읽기 및 쓰기 사이에 내재된 경합 조건이 있습니다. 특별한 주의가 이루어지지 않으면 다음과 같은 문제가 발생할 수 있습니다.
- GPU는 부실 MonitoredValue 를 읽고 CPU에서 예상한 대로 인터럽트를 발생시키지 않을 수 있습니다.
- CMP가 인터럽트 조건을 결정하는 동안 GPU 엔진이 최신 CurrentValue 를 작성할 수 있습니다. 이 최신 CurrentValue 는 예상대로 인터럽트 발생을 발생시키지 않거나 현재 값을 가져올 때 CPU에 표시되지 않을 수 있습니다.
엔진과 CMP 간의 GPU 내 동기화
효율성을 위해 많은 개별 GPU는 다음 사이에 GPU의 로컬 메모리에 있는 섀도 상태를 사용하여 모니터링되는 펜스 신호 의미 체계를 구현합니다.
명령 버퍼 스트림을 실행하고 조건부로 하드웨어 신호를 CMP에 발생시키는 GPU 엔진입니다.
CPU 인터럽트를 발생시켜야 하는지 여부를 결정하는 GPU CMP입니다.
이 경우 CMP는 메모리 쓰기를 펜스 값으로 수행하는 GPU 엔진과 메모리 액세스를 동기화해야 합니다. 특히 섀도 MonitoredValue 를 업데이트하는 작업은 CMP 관점에서 순서를 지정해야 합니다.
- 새 MonitoredValue (섀도 GPU 스토리지)를 작성합니다.
- 메모리 장벽을 실행하여 GPU 엔진과 메모리 액세스를 동기화합니다.
- CurrentValue를 읽습니다.
- CurrentValue>인 경우 CPU 인터럽트를 발생합니다.
- CurrentValue= <인 경우 CPU 인터럽트는 발생하지 않습니다.
이 경합 상태를 제대로 해결하려면 2단계의 메모리 장벽이 제대로 작동해야 합니다. 1단계에서 MonitoredValue 업데이트를 못한 명령에서 시작된 3단계의 CurrentValue에 대한 보류 중인 메모리 쓰기 작업이 없어야 합니다. 이 상황은 3단계에서 작성된 펜스가 1단계에서 업데이트된 값보다 큰 경우 인터럽트를 생성합니다.
GPU와 CPU 간의 동기화
CPU는 진행 중인 신호에 대한 인터럽트 알림을 잃지 않는 방식으로 MonitoredValue의 업데이트 및 CurrentValue 읽기를 수행해야 합니다.
- 시스템에 새 CPU 웨이터가 추가되거나 기존 CPU 웨이터가 사용 중지된 경우 OS는 MonitoredValue를 수정해야 합니다.
- OS는 DxgkDdiUpdateMonitoredValues를 호출하여 GPU에 모니터링되는 새 값을 알립니다.
- DxgkDdiUpdateMonitoredValue 는 디바이스 인터럽트 수준에서 실행되므로 모니터링되는 펜스 신호 인터럽트 서비스 루틴(ISR)과 동기화됩니다.
- DxgkDdiUpdateMonitoredValue는 반환된 후 모든 프로세서 코어에서 읽은 CurrentValue가 새 MonitoredValue를 관찰한 후 GPU CMP에 의해 작성되었음을 보장해야 합니다.
- DxgkDdiUpdateMonitoredValue에서 돌아오면 OS는 CurrentValue를 다시 샘플링하고 새 CurrentValue에 의해 차단 해제된 모든 웨이터를 충족합니다.
CPU가 중단을 발생시킬지 여부를 결정하기 위해 GPU에서 사용하는 것보다 최신 CurrentValue 를 관찰하는 것은 완벽하게 허용됩니다. 이 경우 경우에 따라 대기자의 차단을 해제하지 않는 인터럽트 알림이 발생합니다. 허용되지 않는 것은 CPU가 모니터링된 최신 CurrentValue 업데이트(즉, >)에 대한 인터럽트 알림을 수신하지 않는 것입니다.
OS에서 네이티브 펜스 기능 사용 쿼리
드라이버는 드라이버 초기화 중에 OS에서 네이티브 펜스 기능을 사용할 수 있는지 여부를 쿼리해야 합니다. WDDM 3.2부터 OS는 추가 된 IsFeatureEnabled 인터페이스를 사용하여 기본 펜스 기능을 포함하여 특정 기능을 사용할 수 있는지 여부를 제어합니다.
따라서 KMD는 IsFeatureEnabled 인터페이스를 구현해야 합니다. KMD의 구현은 DXGK_VIDSCHCAPS 네이티브 펜스 지원을 보급하기 전에 OS가 DXGK_FEATURE_NATIVE_FENCE 기능을 사용하도록 설정했는지 여부를 쿼리해야 합니다. OS에서 이 기능을 사용하도록 설정하지 않은 경우 KMD가 네이티브 펜스 지원을 보급하는 경우 OS가 어댑터 초기화에 실패합니다.
기능 사용 인터페이스에 대한 자세한 내용은 WDDM 기능 지원 및 사용 쿼리를 참조 하세요.
네이티브 펜스 기능 사용 기능을 쿼리하는 DPI
다음 인터페이스는 OS가 네이티브 펜스 기능을 사용하도록 설정했는지 여부를 쿼리하기 위해 KMD에 도입되었습니다.
- DXGKCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKCBINT_FEATURE_NATIVEFENCE_1
OS는 DXGK_FEATURE_NATIVE_FENCE 버전 1 전용으로 추가된 DXGKCB_FEATURE_NATIVEFENCE_CAPS_1 인터페이스 테이블을 구현합니다. KMD는 OS의 기능을 확인하려면 이 기능 인터페이스 테이블을 쿼리해야 합니다. 향후 OS 릴리스에서 OS는 새로운 기능에 대한 지원을 자세히 설명하는 이 인터페이스 테이블의 향후 버전을 도입할 수 있습니다.
지원 쿼리를 위한 샘플 드라이버 코드
다음 샘플 코드에서는 드라이버가 DXGK_FEATURE_INTERFACE 인터페이스의 DXGK_FEATURE_NATIVE_FENCE 기능을 사용하여 지원을 쿼리하는 방법을 보여 드립니다.
DXGK_FEATURE_INTERFACE FeatureInterface;
struct FEATURE_RESULT
{
bool Enabled;
DXGK_FEATURE_VERSION Version;
};
// Driver internal cache for state & version of queried features
struct FEATURE_STATE
{
struct
{
UINT NativeFenceEnabled : 1;
};
DXGK_FEATURE_VERSION NativeFenceVersion = 0;
// Interfaces
DXGKCBINT_FEATURE_NATIVEFENCE_1 NativeFenceInterface = {};
// Interface queried values
DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1 NativeFenceOSCaps1 = {};
};
// Helper function to query OS's feature enabled interface
FEATURE_RESULT IsFeatureEnabled(
DXGK_FEATURE_ID FeatureId
)
{
FEATURE_RESULT Result = {};
//
// If the feature interface functionality is available (e.g. supported by the OS)
//
DXGKARGCB_ISFEATUREENABLED2 Args = {};
Args.FeatureId = FeatureId;
if(NT_SUCCESS(FeatureInterface.IsFeatureEnabled(DxgkInterface.DeviceHandle, &Args)))
{
Result.Enabled = Args.Result.Enabled;
Result.Version = Args.Result.Version;
}
return Result;
}
// Actual code to query whether OS has enabled Native Fence support and corresponding OS caps
FEATURE_RESULT FeatureResult = IsFeatureEnabled(DXGK_FEATURE_NATIVE_FENCE);
FEATURE_STATE FeatureState = {};
FeatureState.NativeFenceEnabled = !!FeatureResult.Enabled;
if (FeatureResult.Enabled)
{
// Query OS caps for native fence feature, using the feature interface
DXGKARGCB_QUERYFEATUREINTERFACE QFIArgs = {};
QFIArgs.FeatureId = DXGK_FEATURE_NATIVE_FENCE;
QFIArgs.Interface = &FeatureState.NativeFenceInterface;
QFIArgs.InterfaceSize = sizeof(FeatureState.NativeFenceInterface);
QFIArgs.Version = FeatureResult.Version;
Status = FeatureInterface.QueryFeatureInterface(DxgkInterface.DeviceHandle, &QFIArgs);
if(NT_SUCCESS(Status))
{
FeatureState.NativeFenceVersion = FeatureResult.Version;
Status = FeatureState.NativeFenceInterface.GetOSCaps(&FeatureState.NativeFenceOSCaps1);
NT_ASSERT(NT_SUCCESS(Status));
}
else
{
// We should always succeed getting an interface from a successfully
// negotiated feature + version.
NT_ASSERT(FALSE);
}
}
네이티브 펜스 기능
다음 인터페이스는 네이티브 펜스 캡을 쿼리하기 위해 업데이트되거나 도입되었습니다.
NativeGpuFence 필드가 DXGK_VIDSCHCAPS 추가됩니다. OS에서 DXGK_FEATURE_NATIVE_FENCE 기능을 사용하도록 설정한 경우 드라이버는 DXGK_VIDSCHCAPS::NativeGpuFence 비트를 1로 설정하여 어댑터 초기화 중에 네이티브 GPU 펜스 기능에 대한 지원을 선언할 수 있습니다.
DXGKQAITYPE_NATIVE_FENCE_CAPS DXGK_QUERYADAPTERINFOTYPE 추가됩니다.
Dxgkrnl 은 추가된 해당 D3DKMT_WDDM_3_1_CAPS::NativeGpuFenceSupported structure/bit를 통해 이 기능을 사용자 모드에 노출합니다.
KMTQAITYPE_WDDM_3_1_CAPS KMTQUERYADAPTERINFOTYPE에 추가됩니다.
네이티브 GPU 펜스 기능에 대한 지원 기능을 나타내기 위해 KMD에 대해 다음 엔터티가 추가됩니다.
DXGK_NATIVE_FENCE_CAPS 구조는 GPU의 네이티브 펜스 기능을 설명합니다. KMD가 이 구조의 MapToGpuSystemProcess 비트를 설정하는 경우 OS에 CMP 사용을 위해 시스템 프로세스 GPU 가상 주소 공간을 예약하고 네이티브 펜스 CurrentValue 및 MonitoredValue에 대한 해당 주소 공간에 GPU VA 매핑을 만들도록 지시합니다. 이러한 GPU VA는 나중에 DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa 및 MonitoredValueSystemProcessGpuVa로 KMD의 펜스 생성 콜백에 전달됩니다.
KMD는 추가된 DXGKQAITYPE_NATIVE_FENCE_CAPS 쿼리 어댑터 정보 형식으로 DxgkDdiQueryAdapterInfo 함수를 호출할 때 채워진 DXGK_NATIVE_FENCE_CAPS 구조를 반환합니다.
네이티브 펜스 개체를 만들고, 열고, 닫고, 파괴하는 KMD DPI
다음 KMD 구현 DD는 네이티브 펜스 개체를 만들고, 열고, 닫고, 삭제하기 위해 도입되었습니다. Dxgkrnl은 사용자 모드 구성 요소를 대신하여 이러한 DDIS를 호출합니다. Dxgkrnl은 OS에서 DXGK_FEATURE_NATIVE_FENCE 기능을 사용하도록 설정한 경우에만 호출합니다.
- DxgkDdiCreateNativeFence/DXGKARG_CREATENATIVEFENCE
- DxgkDdiOpenNativeFence/DXGKARG_OPENNATIVEFENCE
- DxgkDdiCloseNativeFence/DXGKARG_CLOSENATIVEFENCE
- DxgkDdiDestroyNativeFence/DXGKARG_DESTROYNATIVEFENCE
다음 DDI는 네이티브 펜스 개체를 지원하도록 업데이트되었습니다.
다음 멤버가 DRIVER_INITIALIZATION_DATA 추가되었습니다. 네이티브 GPU 펜스 개체를 지원하는 드라이버는 함수를 구현하고 이 구조를 통해 Dxgkrnl에 포인터를 제공해야 합니다.
- PDXGKDDI_CREATENATIVEFENCE DxgkDdiCreateNativeFence (WDDM 3.1에 추가됨)
- PDXGKDDI_DESTROYNATIVEFENCE DxgkDdiDestroyNativeFence (WDDM 3.1에 추가됨)
- PDXGKDDI_OPENNATIVEFENCE DxgkDdiCreateNativeFence (WDDM 3.2에 추가됨)
- PDXGKDDI_CLOSENATIVEFENCE DxgkDdiCloseNativeFence (WDDM 3.2에 추가됨)
- PDXGKDDI_SETNATIVEFENCELOGBUFFER DxgkDdiSetNativeFenceLogBuffer (WDDM 3.2에 추가됨)
- PDXGKDDI_UPDATENATIVEFENCELOGS DxgkDdiUpdateNativeFenceLogs (WDDM 3.2에 추가됨)
공유 펜스에 대한 전역 및 로컬 핸들
프로세스 A가 공유 네이티브 울타리를 만들고 프로세스 B가 나중에 이 울타리를 여는 것을 상상해 보십시오.
프로세스 A가 공유 네이티브 펜스를 만들 때 Dxgkrnl은 이 펜스가 만들어지는 어댑터 드라이버 핸들을 사용하여 DxgkDdiCreateNativeFence를 호출합니다. hGlobalNativeFence에서 만들어지고 반환되는 펜스 핸들은 전역 펜스 핸들입니다.
이후 Dxgkrnl은 DxgkDdiOpenNativeFence를 호출하여 프로세스 A의 특정 로컬 핸들(hLocalNativeFenceA)을 엽니다.
프로세스 B가 동일한 공유 네이티브 펜스를 열면 Dxgkrnl은 DxgkDdiOpenNativeFence를 호출하여 프로세스 B별 로컬 핸들(hLocalNativeFenceB)을 엽니다.
프로세스 A가 공유 네이티브 펜스 인스턴스를 삭제하는 경우 Dxgkrnl은 이 전역 펜스에 대한 보류 중인 참조가 여전히 있음을 확인하므로 드라이버가 프로세스 A 관련 구조를 정리하기 위해 DxgkDdiCloseNativeFence(hLocalNativeFenceA)만 호출합니다. hGlobalNativeFence 핸들이 여전히 존재합니다.
프로세스 B가 펜스 인스턴스를 삭제하면 Dxgkrnl은 DxgkDdiCloseNativeFence(hLocalNativeFenceB)를 호출한 다음 DxgkDdiDestroyNativeFence(hGlobalNativeFence)를 호출하여 KMD가 글로벌 펜스 데이터를 삭제할 수 있도록 합니다.
CMP 사용을 위한 페이징 프로세스 주소 공간의 GPU VA 매핑
KMD는 네이티브 펜스 GPU VA가 GPU 페이징 프로세스 주소 공간에도 매핑되어야 하는 하드웨어의 DXGK_NATIVE_FENCE_CAPS::MapToGpuSystemProcess 캡을 설정합니다. Set MapToGpuSystemProcess 비트는 CMP에서 사용할 네이티브 펜스의 CurrentValue 및 MonitoredValue에 대한 페이징 프로세스 주소 공간에 GPU VA 매핑을 만들도록 OS에 지시합니다. 이러한 GPU VA는 나중에 DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa 및 MonitoredValueSystemProcessGpuVa로 DxgkDdiCreateNativeFence에 전달됩니다.
네이티브 펜스를 만들고, 열고, 파괴하는 D3DKMT 커널 API
다음 D3DKMT 커널 모드 API는 네이티브 펜스 개체를 만들고 열기 위해 도입되었습니다.
- D3DKMTCreateNativeFence / D3DKMT_CREATENATIVEFENCE
- D3DKMTOpenNativeFenceFromNTHandle / D3DKMT_OPENNATIVEFENCEFROMNTHANDLE
Dxgkrnl 은 기존 D3DKMTDestroySynchronizationObject 함수를 호출하여 기존 네이티브 펜스 개체를 닫고 제거(자유)합니다.
도입되거나 업데이트되는 지원 구조 및 열거형은 다음과 같습니다.
- D3DDDI_NATIVEFENCEINFO
- D3DDDI_NATIVEFENCE_TYPE
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
- D3DDDI_NATIVEFENCE_MAPPING
로컬 메모리에 네이티브 펜스 값 배치를 지원하는 DDI
로컬 메모리에 네이티브 펜스 값의 배치를 지원하도록 다음 DPI가 추가되거나 변경되었습니다.
D3DKMDT_FENCESTORAGESURFACEDATA 구조체가 추가됩니다.
D3DDDI_NATIVEFENCE_TYPE_INTRA_GPU 네이티브 펜스 유형의네이티브 펜스 MonitoredValue 및 CurrentValue는 로컬 디바이스 메모리에 배치할 수 있습니다. 이를 위해 OS는 펜스 스토리지를 배치해야 하는 메모리 세그먼트를 지정하도록 드라이버에 요청합니다. DxgkDdiGetStandardAllocation 은 이러한 정보를 제공하도록 확장됩니다.
D3DKMDT_STANDARDALLOCATION_FENCESTORAGE DXGKARG_GETSTANDARDALLOCATIONDRIVERDATA 추가됩니다.
하드웨어 큐에 대한 네이티브 진행률 펜스 표시
다음 업데이트는 네이티브 하드웨어 큐 진행률 펜스 개체를 나타내기 위해 도입되었습니다.
DxgkDdiCreateHwQueue 호출에 대해 NativeProgressFence 플래그가 추가됩니다.
- 지원되는 시스템에서 OS는 하드웨어 큐 진행률 펜스를 네이티브 펜스로 업데이트합니다. OS가 NativeProgressFence를 설정하는 경우 DXGKARG_CREATEHWQUEUE::hHwQueueProgressFence 핸들이 DxgkDdiCreateNativeFence를 사용하여 이전에 만든 네이티브 GPU 펜스 개체의 드라이버 핸들을 가리킨다는 것을 KMD에 나타냅니다.
네이티브 펜스 신호 인터럽트
네이티브 펜스 신호 인터럽트를 지원하기 위해 인터럽트 메커니즘을 다음과 같이 변경합니다.
DXGK_INTERRUPT_TYPE 열거형은 DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED 인터럽트 형식으로 업데이트됩니다.
DXGKARGCB_NOTIFY_INTERRUPT_DATA 구조체는 네이티브 펜스 신호 인터럽트를 나타내는 NativeFenceSignaled 구조를 포함하도록 업데이트됩니다.
NativeFenceSignaled 는 CPU에서 모니터링하는 네이티브 펜스 GPU 개체 집합이 GPU 엔진에서 신호를 받았다고 OS에 알리는 데 사용됩니다. GPU가 활성 CPU 웨이터를 사용하여 개체의 정확한 하위 집합을 확인할 수 있는 경우 pSignaledNativeFenceArray를 통해 이 하위 집합을 전달합니다. 이 배열의 핸들은 DxgkDdiCreateNativeFence에서 Dxgkrnl이 KMD에 전달한 유효한 hGlobalNativeFence 핸들이어야 합니다. 소멸된 네이티브 펜스 개체에 핸들을 전달하면 버그 검사가 발생합니다.
DXGKCB_NOTIFY_INTERRUPT_DATA_FLAGS 구조체는 EvaluateLegacyMonitoredFences 멤버를 포함하도록 업데이트됩니다.
GPU는 다음 조건에서 NULL pSignaledNativeFenceArray 를 전달할 수 있습니다.
- GPU는 활성 CPU 웨이터가 있는 개체의 정확한 하위 집합을 확인할 수 없습니다.
- 여러 신호 인터럽트는 함께 축소되므로 활성 웨이터가 있는 신호 집합을 확인하기가 어렵습니다.
NULL 값은 모든 미해결 네이티브 GPU 펜스 개체 웨이터를 검사하도록 OS에 지시합니다.
OS와 드라이버 간의 계약은 다음과 같습니다. OS에 활성 CPU 웨이터(MonitoredValue로 표현됨)가 있고 GPU 엔진이 개체에 CPU 인터럽트를 요구하는 값으로 신호를 보낸 경우 GPU는 다음 작업 중 하나를 수행해야 합니다.
- pSignaledNativeFenceArray에 이 네이티브 펜스 핸들을 포함합니다.
- NULL pSignaledNativeFenceArray를 사용하여 NativeFenceSignaled 인터럽트를 발생합니다.
기본적으로 KMD가 NULL pSignaledNativeFenceArray를 사용하여 이 인터럽트를 발생시키는 경우 Dxgkrnl은 보류 중인 모든 네이티브 펜스 웨이터만 검사하고 레거시 모니터링 펜스 웨이터를 검사하지 않습니다. 레거시 DXGK_INTERRUPT_MONITORED_FENCE_SIGNALED DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED구분할 수 없는 하드웨어에서 KMD는 항상 pSignaledNativeFenceArray = NULL 및 EvaluateLegacyMonitoredFences = 1을 사용하여 도입된 DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED 인터럽트만 발생시키는데, 이는 OS에 모든 웨이터(레거시 모니터링 펜스 웨이터 및 네이티브 펜스 웨이터)를 검사하도록 나타냅니다.
KMD에 값 일괄 처리를 업데이트하도록 지시
다음 인터페이스는 KMD에 현재 또는 모니터링되는 값의 일괄 처리를 업데이트하도록 지시하기 위해 도입되었습니다.
DxgkDdiUpdateCurrentValuesFromCpu / DXGKARG_UPDATECURRENTVALUESFROMCPU
DxgkDdiUpdateMonitoredValues / DXGKARG_UPDATEMONITOREDVALUES
어댑터 간 네이티브 펜스
기존 DX12 앱이 교차 어댑터 모니터링 펜스를 만들고 사용하기 때문에 OS는 크로스 어댑터 네이티브 펜스 만들기를 지원해야 합니다. 이러한 앱에 대한 기본 큐 및 예약이 사용자 모드 제출로 전환되는 경우 모니터링되는 펜스도 네이티브 펜스로 전환해야 합니다(사용자 모드 큐는 모니터링된 펜스를 지원할 수 없음).
D3DDDI_NATIVEFENCE_TYPE_DEFAULT 형식으로 어댑터 간 펜스를 만들어야 합니다. 그렇지 않으면 D3DKMTCreateNativeFence 가 실패합니다.
모든 GPU는 항상 시스템 메모리에 할당되는 CurrentValue 스토리지의 동일한 복사본을 공유합니다. 런타임이 GPU1에 크로스 어댑터 네이티브 펜스를 만들고 GPU2에서 열면 두 GPU의 GPU VA 매핑은 동일한 CurrentValue 물리적 스토리지를 가리킵니다.
각 GPU는 MonitoredValue의 자체 복사본을 가져옵니다. 따라서 MonitoredValue 스토리지는 시스템 메모리 또는 로컬 메모리에 할당할 수 있습니다.
어댑터 간 네이티브 펜스는 GPU1이 GPU2가 신호를 받은 네이티브 펜스에서 대기하는 조건을 해결해야 합니다. 현재 GPU-GPU 신호의 개념은 없습니다. 따라서 OS는 CPU에서 GPU1 신호를 전송하여 이 조건을 명시적으로 해결합니다. 이 신호는 교차 어댑터 펜스의 MonitoredValue를 수명 동안 0으로 설정하여 수행됩니다. 그런 다음 GPU2가 네이티브 펜스에 신호를 보내면 CPU 인터럽트도 발생하므로 Dxgkrnl이 GPU1에서 CurrentValue를 업데이트하고(NotificationOnly 플래그가 TRUE로 설정된 DxgkDdiUpdateCurrentValuesFromCpu 사용) 해당 GPU의 보류 중인 CPU/GPU 웨이터의 차단을 해제할 수 있습니다.
MonitoredValue는 어댑터 간 네이티브 펜스의 경우 항상 0이지만 동일한 GPU에서 제출된 대기 및 신호는 GPU 동기화 시 더 빠른 혜택을 누릴 수 있습니다. 그러나 다른 GPU에 CPU 웨이터 또는 웨이터가 없더라도 CPU 인터럽트는 무조건 발생하므로 CPU 인터럽트 감소의 전원 혜택이 손실됩니다. 이 절상은 어댑터 간 네이티브 펜스의 설계 및 구현 비용을 단순하게 유지하기 위해 만들어집니다.
OS는 GPU1에서 네이티브 펜스 개체가 만들어지고 GPU2에서 열리는 시나리오를 지원합니다. 여기서 GPU1은 기능을 지원하고 GPU2는 지원하지 않습니다. 펜스 개체는 GPU2에서 일반 MonitoredFence 로 열립니다.
OS는 GPU1에서 일반 모니터링 펜스 개체가 만들어지고 이 기능을 지원하는 GPU2의 네이티브 펜스로 열리는 시나리오를 지원합니다. 펜스 개체는 GPU2에서 네이티브 펜스로 열립니다.
어댑터 간 대기/신호 조합
다음 하위 섹션의 테이블은 iGPU 및 dGPU 시스템의 예를 사용하고 CPU/GPU의 네이티브 펜스 대기/신호에 사용할 수 있는 다양한 구성을 나열합니다. 다음 두 가지 경우를 고려합니다.
- 두 GPU 모두 네이티브 펜스를 지원합니다.
- iGPU는 네이티브 펜스를 지원하지 않지만 dGPU는 네이티브 펜스를 지원합니다.
두 번째 시나리오는 두 GPU가 네이티브 펜스를 지원하지만 네이티브 펜스 대기/신호가 iGPU의 커널 모드 큐에 제출되는 경우와 비슷합니다.
테이블은 열에서 대기 및 신호 쌍을 선택하여 읽어야 합니다(예: WaitFromGPU - SignalFromGPU 또는 WaitFromGPU - SignalFromCPU, et cetera).
시나리오 1
시나리오 1에서 dGPU와 iGPU는 모두 네이티브 펜스를 지원합니다.
| iGPU WaitFromGPU(hFence, 10) | iGPU WaitFromCPU(hFence, 10) | dGPU SignalFromGpu(hFence, 10) | dGPU의 CPU 신호 처리(hFence, 10) |
|---|---|---|---|
| UMD는 명령 버퍼에 hfence CurrentValue == 10 명령에 대한 대기를 삽입합니다. | 런타임에서 D3DKMTWaitForSynchronizationObjectFromCpu를 호출 합니다. | ||
| VidSch 는 네이티브 펜스 CPU 웨이터 목록에서 이 동기화 개체를 추적합니다. | |||
| UMD는 명령 버퍼에 쓰기 hFence CurrentValue = 10 신호 명령을 삽입합니다. | 런타임에서 D3DKMTSignalSynchronizationObjectFromCpu를 호출 합니다. | ||
| CurrentValue가 기록될 때 VidSch는 기본 펜스 신호 ISR을 받습니다(MonitoredValue == 0이 항상 있기 때문). | VidSch는 DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10)를 호출합니다. | ||
| VidSch 는 신호(hFence, 10)를 iGPU로 전파합니다. | VidSch 는 신호(hFence, 10)를 iGPU로 전파합니다. | ||
| VidSch는 전파된 신호를 수신하고 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE)를 호출합니다. | VidSch는 전파된 신호를 수신하고 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE)를 호출합니다. | ||
| KMD는 실행 목록을 다시 검사하여 hFence에서 대기 중인 HW 채널 차단을 해제합니다. | VidSch 는 KEVENT에 신호를 전송하여 CPU 대기 조건의 차단을 해제합니다. |
시나리오 2a
시나리오 2a에서 iGPU는 네이티브 펜스를 지원하지 않지만 dGPU는 지원합니다. iGPU에서 대기가 제출되고 dGPU에 신호가 제출됩니다.
| iGPU WaitFromGPU(hFence, 10) | iGPU WaitFromCPU(hFence, 10) | dGPU SignalFromGpu(hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| 런타임에서 D3DKMTWaitForSynchronizationObjectFromGpu를 호출 합니다. | 런타임에서 D3DKMTWaitForSynchronizationObjectFromCpu를 호출 합니다. | ||
| VidSch 는 모니터링되는 펜스 대기자 목록에서 이 동기화 개체를 추적합니다. | VidSch 는 모니터링되는 펜스 CPU 웨이터 목록 헤드에서 이 동기화 개체를 추적합니다. | ||
| UMD는 명령 버퍼에 쓰기 hFence CurrentValue = 10 신호 명령을 삽입합니다. | 런타임에서 D3DKMTSignalSynchronizationObjectFromCpu를 호출 합니다. | ||
| CurrentValue가 작성될 때 VidSch는 NativeFenceSignaledISR을 받습니다(MV == 0이 항상 사용되기 때문). | VidSch는 DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10)를 호출합니다. | ||
| VidSch 는 신호(hFence, 10)를 iGPU로 전파합니다. | VidSch 는 신호(hFence, 10)를 iGPU로 전파합니다. | ||
| VidSch 는 전파된 신호를 수신하고 새 펜스 값을 관찰합니다. | VidSch 는 전파된 신호를 수신하고 새 펜스 값을 관찰합니다. | ||
| VidSch 는 모니터링되는 펜스 대기자 목록을 검사하고 소프트웨어 컨텍스트 차단을 해제합니다. | VidSch 는 모니터링되는 펜스 CPU 웨이터 목록 헤드를 검사하고 KEVENT를 신호로 표시하여 CPU 대기 차단을 해제합니다. |
시나리오 2b
시나리오 2b에서 네이티브 펜스 지원은 동일하게 유지됩니다(iGPU는 지원하지 않습니다. dGPU는 지원되지 않음). 이번에는 iGPU에 신호가 제출되고 dGPU에서 대기가 제출됩니다.
| iGPU SignalFromGPU(hFence, 10) | iGPU SignalFromCPU(hFence, 10) | dGPU WaitFromGpu(hFence, 10) | dGPU WaitFromCpu(hFence, 10) |
|---|---|---|---|
| UMD는 명령 버퍼에 hfence CurrentValue == 10 명령에 대한 대기를 삽입합니다. | 런타임에서 D3DKMTWaitForSynchronizationObjectFromCpu를 호출 합니다. | ||
| VidSch 는 네이티브 펜스 CPU 웨이터 목록에서 이 동기화 개체를 추적합니다. | |||
| UMD 호출 D3DKMTSignalSynchronizationObjectFromGpu | UMD는 D3DKMTSignalSynchronizationObjectFromCpu를 호출 합니다. | ||
| 패킷이 소프트웨어 컨텍스트 의 맨 앞에 있는 경우 VidSch 는 CPU에서 직접 펜스 값을 업데이트합니다. | VidSch 는 CPU에서 직접 펜스 값을 업데이트합니다. | ||
| VidSch 는 신호(hFence, 10)를 dGPU로 전파합니다. | VidSch 는 신호(hFence, 10)를 dGPU로 전파합니다. | ||
| VidSch는 전파된 신호를 수신하고 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE)를 호출합니다. | VidSch는 전파된 신호를 수신하고 DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE)를 호출합니다. | ||
| KMD는 실행 목록을 다시 검사하여 hFence에서 대기 중인 HW 채널 차단을 해제합니다. | VidSch 는 KEVENT에 신호를 전송하여 CPU 대기 조건의 차단을 해제합니다. |
향후 GPU-GPU 간 어댑터 신호
동기화 문제에 설명된 대로 어댑터 간 네이티브 펜스의 경우 CPU 인터럽트를 무조건 발생하므로 전원이 절약됩니다.
향후 릴리스에서 OS는 한 GPU의 GPU 신호가 공통 초인종 메모리에 기록하여 다른 GPU를 중단하도록 허용하는 인프라를 개발하여 다른 GPU가 절전 모드 해제, 실행 목록 처리 및 준비된 HW 큐 차단 해제를 허용합니다.
이 작업의 과제는 다음을 설계하는 것입니다.
- 일반적인 초인종 메모리입니다.
- GPU가 초인종에 쓸 수 있는 지능형 페이로드 또는 핸들로, 다른 GPU가 HWQueues의 하위 집합만 검색할 수 있도록 신호를 받은 펜스를 확인할 수 있습니다.
이러한 어댑터 간 신호를 사용하면 GPU가 모든 GPU가 읽고 쓰는 동일한 네이티브 펜스 스토리지 복사본(어댑터 간 검색 할당과 유사한 선형 형식 크로스 어댑터 할당)을 공유할 수도 있습니다.
네이티브 펜스 로그 버퍼 디자인
네이티브 펜스 및 사용자 모드 제출 을 사용하면 Dxgkrnl 은 UMD에서 큐에 포함된 네이티브 GPU 대기 및 신호가 특정 HWQueue에 대해 GPU에서 차단 해제되는 시기를 볼 수 없습니다. 네이티브 울타리를 사용하면 지정된 울타리에 대해 모니터링된 울타리 신호 인터럽트를 억제할 수 있습니다.
:
이 GPUView 이미지에 표시된 대로 펜스 작업을 다시 만드는 방법이 필요합니다. 진한 분홍색 상자는 신호이며 연한 분홍색 상자는 대기합니다. 각 상자는 CPU에서 Dxgkrnl로 작업이 제출될 때 시작되고 Dxgkrnl이 CPU에서 작업을 완료하면 종료됩니다. 이렇게 하면 명령의 전체 수명을 연구할 수 있습니다.
따라서 높은 수준에서 기록해야 하는 HWQueue별 조건은 다음과 같습니다.
| 조건 | 의미 |
|---|---|
| FENCE_WAIT_QUEUED | UMD가 명령 큐에 GPU 대기 명령을 삽입하는 경우의 CPU 타임스탬프 |
| FENCE_SIGNAL_QUEUED | UMD가 명령 큐에 GPU 신호 명령을 삽입하는 경우의 CPU 타임스탬프 |
| FENCE_SIGNAL_EXECUTED | HWQueue에 대한 GPU에서 신호 명령이 실행되는 경우의 GPU 타임스탬프 |
| FENCE_WAIT_UNBLOCKED | GPU에서 대기 조건이 충족되고 HWQueue가 차단 해제된 경우의 GPU 타임스탬프 |
네이티브 펜스 로그 버퍼 DDI
다음 DDI, 구조체 및 열거형은 네이티브 펜스 로그 버퍼를 지원하기 위해 도입되었습니다.
- DxgkDdiSetNativeFenceLogBuffer / DXGKARG_SETNATIVEFENCELOGBUFFER
- DxgkDdiUpdateNativeFenceLogs / DXGKARG_UPDATENATIVEFENCELOGS
- 로그 항목의 헤더 및 배열을 포함하는 로그 버퍼입니다. 헤더는 항목이 대기 또는 신호인지 여부를 식별하고 각 항목은 작업 유형(실행됨 또는 차단 해제)을 식별합니다.
로그 버퍼 디자인은 Dxgkrnl 또는 KMD의 개입 없이 GPU 엔진/CMP에서 로그 버퍼 페이로드를 작성하는 네이티브 펜스 및 사용자 모드 제출 큐를 위한 것입니다. 따라서 UMD는 대기/신호 명령 버퍼를 생성하는 동안 명령을 삽입하고 GPU를 프로그래밍하여 로그 버퍼 페이로드를 실행 시 로그 버퍼 항목에 기록합니다. 사용자 모드가 아닌 제출(즉, 커널 모드 큐)의 경우 대기 및 신호는 Dxgkrnl 내의 소프트웨어 명령이므로 이러한 작업의 타임스탬프 및 기타 세부 정보를 이미 알고 있으며 로그 버퍼를 업데이트하기 위해 하드웨어/KMD가 필요하지 않습니다. 이러한 커널 모드 큐의 경우 Dxgkrnl 은 로그 버퍼를 만들지 않습니다.
로그 버퍼 메커니즘
Dxgkrnl 은 HWQueue당 두 개의 전용 4KB 로그 버퍼를 할당합니다.
- 로깅 대기를 위한 것입니다.
- 신호 로깅을 위한 것입니다.
이러한 로그 버퍼에는 커널 모드 CPU VA(LogBufferCpuVa), 프로세스 주소 공간의 GPU VA(LogBufferGpuVa) 및 CMP VA(LogBufferSystemProcessGpuVa)에 대한 매핑이 있으므로 KMD, GPU 엔진 및 CMP에 읽기/쓰기가 가능합니다. Dxgkrnl은 DxgkDdiSetNativeFenceLogBuffer를 두 번 호출합니다. 한 번은 로깅 대기에 대한 로그 버퍼를 설정하고 한 번은 로깅 신호에 대한 로그 버퍼를 설정합니다.
UMD가 명령 목록에 네이티브 펜스 대기 또는 신호 명령을 삽입한 직후 GPU가 로그 버퍼에 특정 항목에 페이로드를 쓰도록 지시하는 명령도 삽입합니다.
GPU 엔진이 펜스 작업을 실행한 후에는 지정된 항목에 페이로드를 로그 버퍼에 쓰는 UMD 명령이 표시됩니다. 또한 GPU는 현재 FenceEndGpuTimestamp 를 이 로그 버퍼 항목에 씁니다.
UMD는 GPU 액세스 가능 로그 버퍼에 액세스할 수 없지만 로그 버퍼의 진행을 제어합니다. 즉, UMD는 쓸 다음 무료 항목(있는 경우)을 결정하고 이 정보를 사용하여 GPU를 프로그래밍합니다. GPU가 로그 버퍼에 쓰면 로그 헤더의 FirstFreeEntryIndex 값이 증가합니다. UMD는 로그 항목에 대한 쓰기가 단조적으로 증가하는지 확인해야 합니다.
다음 시나리오를 살펴 보십시오.
- HWQueueA 및 HWQueueB에는 FenceLogA 및 FenceLogB의 GPU VA가 있는 해당 펜스 로그 버퍼가 있는 두 개의 HWQueues가 있습니다. HWQueueA 는 로깅 대기를 위한 로그 버퍼와 연결되고 HWQueueB 는 로깅 신호에 대한 로그 버퍼와 연결됩니다.
- FenceF의 사용자 모드 D3DKMT_HANDLE 있는 네이티브 펜스 개체가 있습니다.
- 값 V1에 대한 FenceF의 GPU 대기는 CPUT1 시 HWQueueA에 큐에 대기합니다. UMD는 명령 버퍼를 빌드할 때 GPU에 페이로드 를 기록하도록 지시하는 명령을 삽입합니다( LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED).
- 값 V1이 있는 FenceF에 대한 GPU 신호는 CPUT2 시 HWQueueB에 큐에 대기합니다. UMD는 명령 버퍼를 빌드할 때 GPU에 LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED) 페이로드를 기록하도록 지시하는 명령을 삽입합니다.
GPU 스케줄러는 GPU 시간 GPUT1에서 HWQueueB에서 GPU 신호를 실행한 후 UMD 페이로드를 읽고 HWQueueB에 대한 OS 제공 펜스 로그에 이벤트를 기록합니다.
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED;
LogEntry.FenceEndGpuTimestamp = GPUT1; // Time when UMD submits a command to the GPU
GPU 스케줄러는 GPU 시간 GPUT2에서 HWQueueA가 차단 해제된 것을 관찰한 후 UMD 페이로드를 읽고 HWQueueA에 대한 OS 제공 펜스 로그에 이벤트를 기록합니다.
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED;
LogEntry.FenceObservedGpuTimestamp = GPUTo; // Time that GPU acknowledged UMD's submitted command and queued the fence wait on HW
LogEntry.FenceEndGpuTimestamp = GPUT2;
Dxgkrnl은 로그 버퍼를 삭제하고 다시 만들 수 있습니다. 이 작업을 할 때마다 DxgkDdiSetNativeFenceLogBuffer를 호출하여 KMD에 새 위치를 알릴 수 있습니다.
펜스 대기 작업의 CPU 타임스탬프
다음과 같은 경우 이러한 CPU 타임스탬프를 UMD 로그로 만드는 데는 약간의 이점이 있습니다.
- 명령 목록을 포함하는 명령 버퍼의 GPU 실행 몇 분 전에 명령 목록을 기록할 수 있습니다.
- 이러한 몇 분은 동일한 명령 버퍼에 있는 다른 동기화 개체와 순서가 다를 수 있습니다.
GPU에서 작성한 로그 버퍼에 대한 UMD 지침에 CPU 타임스탬프를 포함하는 데 드는 비용이 있으므로 CPU 타임스탬프는 로그 항목 페이로드에 포함되지 않습니다.
대신, 런타임 또는 UMD는 명령 목록이 기록될 때 CPU 타임스탬프를 사용하여 네이티브 펜스 큐 ETW 이벤트를 내보낼 수 있습니다. 따라서 도구는 이 새 이벤트의 CPU 타임스탬프와 로그 버퍼 항목의 GPU 타임스탬프를 결합하여 펜스 대기 및 완료된 이벤트의 타임라인을 작성할 수 있습니다.
펜스 신호 또는 차단 해제 시 GPU에 대한 작업 순서
UMD는 GPU에 펜스를 신호/차단 해제하도록 지시하는 명령 목록을 빌드할 때 다음 순서를 유지해야 합니다.
- 펜스 GPU VA/CMP VA에 새 펜스 값을 씁니다.
- 로그 페이로드를 해당 로그 버퍼 GPU VA/CMP VA에 씁니다.
- 필요한 경우 네이티브 펜스 신호 인터럽트를 발생합니다.
이 작업 순서를 통해 인터럽트는 OS로 발생할 때 Dxgkrnl 에서 가장 최근의 로그 항목을 볼 수 있습니다.
로그 버퍼 오버런이 허용됨
GPU는 OS에서 아직 볼 수 없는 항목으로 덮어쓰여 로그 버퍼를 오버런할 수 있습니다. WraparoundCount를 증가시켜 이 작업을 수행합니다.
OS가 결국 로그를 읽는 경우 로그 헤더의 새 WraparoundCount 값을 캐시된 값과 비교하여 오버런이 발생했음을 감지할 수 있습니다. 오버런이 발생한 경우 OS에는 다음과 같은 대체 옵션이 있습니다.
- 오버런이 발생할 때 울타리를 차단 해제하기 위해 OS는 모든 울타리를 검사하고 차단 해제된 웨이터를 결정합니다.
- 추적을 사용하도록 설정한 경우 OS는 추적에 플래그를 내보내서 사용자에게 이벤트가 손실되었음을 알릴 수 있습니다. 또한 추적을 사용하도록 설정하면 OS는 먼저 로그 버퍼의 크기를 늘려 처음에 오버런을 방지합니다.
로그 버퍼 항목을 진행하는 동안 UMD에서 백 압력 지원을 구현할 필요는 없습니다.
비어 있거나 반복되는 로그 버퍼 타임스탬프
일반적으로 Dxgkrnl 은 로그 항목의 타임스탬프가 단조적으로 증가할 것으로 예상합니다. 그러나 후속 로그 항목의 타임스탬프가 0이거나 이전 로그 항목과 동일한 시나리오가 있습니다.
예를 들어 연결된 디스플레이 어댑터가 있는 시나리오에서는 LDA의 연결된 어댑터 중 하나가 펜스 쓰기 작업을 건너뛸 수 있습니다. 이 경우 로그 버퍼 항목에는 타임스탬프가 0개 있습니다. Dxgkrnl 은 이러한 사례를 처리합니다. 즉, Dxgkrnl 은 지정된 로그 항목의 타임스탬프가 이전 로그 항목보다 작을 것으로 기대하지 않습니다. 즉, 타임스탬프는 뒤로 갈 수 없습니다.
네이티브 펜스 로그를 동기적으로 업데이트
GPU 쓰기는 펜스 값을 업데이트하고 해당 로그 버퍼는 CPU 읽기 전에 쓰기가 완전히 전파되도록 해야 합니다. 이 요구 사항은 메모리 장벽을 사용해야 합니다. 예시:
- Signal Fence(N): N을 새 현재 값으로 작성
- GPU 타임스탬프를 포함한 로그 항목 작성
- MemoryBarrier
- FirstFreeEntryIndex 증가시키기
- MemoryBarrier
- 모니터링된 펜스 인터럽트(N): 주소 "M"을 읽고 값을 N과 비교하여 CPU 인터럽트 제공을 결정합니다.
특히 조건부 인터럽트 검사가 충족되지 않고 CPU 인터럽트를 사용할 필요가 없는 경우 모든 GPU 신호에 두 개의 장벽을 삽입하는 데 비용이 너무 많이 듭니다. 결과적으로, 디자인은 GPU(생산자)에서 CPU(소비자)로 메모리 장벽 중 하나를 삽입하는 비용을 이동합니다. Dxgkrnl은 도입된 DxgkDdiUpdateNativeFenceLogs 함수를 호출하여 KMD가 요청 시 보류 중인 네이티브 펜스 로그 쓰기를 동기적으로 플러시하도록 합니다(HW 대칭 이동 큐 로그 플러시에 DxgkddiUpdateflipqueuelog가 도입된 것과 유사함).
GPU 작업의 경우:
- Signal Fence(N): N을 새 현재 값으로 작성
- GPU 타임스탬프를 포함한 로그 항목 작성
- FirstFreeEntryIndex 증가시키기
- MemoryBarrier => FirstFreeEntryIndex가 완전히 전파되었는지 확인합니다.
- 모니터링된 펜스 인터럽트(N): 주소 "M"을 읽고 N과 값을 비교하여 인터럽트 전달을 결정합니다.
CPU 작업의 경우:
Dxgkrnl의 네이티브 펜스 신호 인터럽트 처리기(DISPATCH_IRQL):
- 각 HWQueue 로그: FirstFreeEntryIndex를 읽고 새 항목이 작성되었는지 확인합니다.
- 새 항목이 있는 모든 HWQueue 로그에 대해 DxgkDdiUpdateNativeFenceLogs를 호출하고 해당 HWQueues에 대한 커널 핸들을 제공합니다. 이 DDI에서 KMD는 지정된 각 HWQueue에 메모리 장벽을 삽입하여 모든 로그 항목 쓰기가 커밋되도록 합니다.
- Dxgkrnl은 로그 항목을 읽어 타임스탬프 페이로드를 추출합니다.
따라서 하드웨어가 FirstFreeEntryIndex에 쓴 후 메모리 장벽을 삽입하는 한 Dxgkrnl 은 항상 KMD의 DDI를 호출하므로 Dxgkrnl이 로그 항목을 읽기 전에 KMD가 메모리 장벽을 삽입할 수 있습니다.
향후 하드웨어 요구 사항
대부분의 현재 세대 하드웨어는 네이티브 펜스 신호 인터럽트에서 신호를 받은 펜스 개체의 커널 핸들 작성만 지원할 수 있습니다. 이 디자인은 앞에서 네이티브 펜스 신호 인터럽트에서 설명합니다. 이 경우 Dxgkrnl 은 다음과 같이 인터럽트 페이로드를 처리합니다.
- OS는 펜스 값의 읽기(잠재적으로 PCI 전체)를 수행합니다.
- 신호를 받은 펜스와 펜스 값을 알고 있는 OS는 해당 펜스/값에서 대기 중인 CPU 웨이터를 깨우고 있습니다.
- 이와 별도로 이 펜스의 부모 디바이스에 대해 OS는 모든 HWQueues의 로그 버퍼를 검색합니다. 그런 다음 OS는 마지막으로 쓴 로그 버퍼 항목을 읽어 신호를 한 HWQueue를 확인하고 해당 타임스탬프 페이로드를 추출합니다. 이 방법은 PCI에서 일부 펜스 값을 중복으로 읽을 수 있습니다.
향후 플랫폼에서 Dxgkrnl 은 네이티브 펜스 신호 인터럽트에서 커널 HwQueue 핸들 배열을 가져오는 것을 선호합니다. 이 방법을 사용하면 OS에서 다음을 수행할 수 있습니다.
- 해당 HwQueue에 대한 최신 로그 버퍼 항목을 읽습니다. 사용자 디바이스는 인터럽트 처리기에 알려지지 않습니다. 따라서 이 HwQueue 핸들은 커널 핸들이어야 합니다.
- 로그 버퍼에서 신호를 받은 펜스 및 값을 나타내는 로그 항목을 검색합니다. 로그 버퍼만 읽으면 펜스 값과 로그 버퍼를 중복으로 읽지 않고도 PCI를 통해 단일 읽기가 가능합니다. 이 최적화는 로그 버퍼가 오버런되지 않은 한 성공합니다(Dxgkrnl에서 읽지 않은 항목 삭제).
- OS에서 로그 버퍼가 오버런되었음을 감지하면 동일한 디바이스가 소유한 모든 펜스의 라이브 값을 읽는 최적이 아닌 경로로 돌아갑니다. 성능은 디바이스가 소유한 펜스 수에 비례합니다. 펜스 값이 비디오 메모리에 있는 경우 이러한 읽기는 PCI 전체에서 캐시 일관성이 있습니다.
- 신호를 받은 펜스와 펜스 값을 알고 있는 OS는 해당 펜스/값을 기다리는 CPU 웨이터를 깨우고 있습니다.
최적화된 네이티브 펜스 신호 인터럽트
네이티브 펜스 신호 인터럽트에서 설명된 변경 내용 외에도 최적화된 접근 방식을 지원하기 위해 다음과 같은 변경이 수행됩니다.
- OptimizedNativeFenceSignaledInterrupt 캡이 DXGK_VIDSCHCAPS 추가됩니다.
하드웨어에서 지원되는 경우 신호를 받은 펜스 핸들 배열을 채우는 대신 GPU는 인터럽트를 발생시켰을 때 실행 중인 HWQueue의 KMD 핸들만 언급해야 합니다. Dxgkrnl 은 이 HWQueue에 대한 펜스 로그 버퍼를 검사하고 마지막 업데이트 이후 GPU에서 완료한 모든 펜스 작업을 읽고 해당 CPU 웨이터의 차단을 해제합니다. GPU에서 신호를 받은 펜스의 하위 집합을 확인할 수 없는 경우 NULL HWQueue 핸들을 지정해야 합니다. Dxgkrnl에서 NULL HWQueue 핸들이 표시되면 이 엔진에서 모든 HWQueues의 로그 버퍼를 다시 검사하여 신호를 받은 펜스를 확인합니다.
이 최적화에 대한 지원은 선택 사항입니다. KMD는 하드웨어에서 지원하는 경우 DXGK_VIDSCHCAPS:OptimizedNativeFenceSignaledInterrupt 캡을 설정해야 합니다. OptimizedNativeFenceSignaledInterrupt 상한이 설정되지 않은 경우 GPU/KMD는 네이티브 펜스 신호 인터럽트에 설명된 동작을 따라야 합니다.
최적화된 네이티브 펜스 신호 인터럽트 예
HWQueueA: 펜스 F1에 GPU 신호, 값 V1 -> 로그 버퍼 항목 E1 에 쓰기 -> 인터럽트 필요 없음
HWQueueA: 펜스 F1에 GPU 신호, 값 V2 -> 로그 버퍼 항목 E2 에 쓰기 -> 인터럽트 필요 없음
HWQueueA: 펜스 F2에 GPU 신호, 값 V3 -> 로그 버퍼 항목 E3 에 쓰기 -> 인터럽트 필요 없음
HWQueueA: 펜스 F2에 GPU 신호, 값 V3 -> 로그 버퍼 항목 E4 에 쓰기 -> 인터럽트 발생
DXGKARGCB_NOTIFY_INTERRUPT_DATA FenceSignalISR = {}; FenceSignalISR.NodeOrdinal = 0; FenceSignalISR.EngineOrdinal = 0; FenceSignalISR.hHWQueue = A;Dxgkrnl은 HWQueueA에 대한 로그 버퍼를 읽습니다. 로그 버퍼 항목 E1, E2, E3 및 E4를 읽고 신호 펜스 F1 @ 값 V1, F1 @ 값 V2, F2 @ 값 V3 및 F2 @ 값 V3을 관찰하고 해당 펜스 및 값에서 기다리는 모든 웨이터의 차단을 해제합니다.
선택적 및 필수 로깅
DXGK_NATIVE_FENCE_LOG_TYPE_WAITS 및 DXGK_NATIVE_FENCE_LOG_TYPE_SIGNALS 대한 네이티브 펜스 로깅에 대한 지원은 필수입니다.
나중에 GPUView와 같은 도구가 OS에서 자세한 ETW 로깅을 사용하도록 설정하는 경우에만 다른 로깅 형식이 추가될 수 있습니다. OS는 자세한 정보 로깅을 사용하도록 설정하고 사용하지 않도록 설정한 경우 해당 자세한 이벤트 로깅을 선택적으로 사용하도록 설정하도록 UMD와 KMD 모두에 알려야 합니다.