Apache Kafka-migratie naar Azure
Apache Kafka is een zeer schaalbaar en fouttolerant gedistribueerd berichtensysteem waarmee een architectuur voor publiceren-abonneren wordt geïmplementeerd. Het wordt gebruikt als een opnamelaag in realtime streamingscenario's, zoals Internet of Things en realtime bewakingssystemen voor logboeken. Het wordt ook steeds vaker gebruikt als het onveranderbare gegevensarchief dat alleen toevoegt in Kappa-architecturen.
Apache, Apache® Spark®, Apache Hadoop®, Apache HBase, Apache Storm®, Apache Sqoop®, Apache Kafka® en het vlamlogo zijn geregistreerde handelsmerken of handelsmerken van de Apache Software Foundation in de Verenigde Staten en/of andere landen. Er wordt geen goedkeuring door De Apache Software Foundation geïmpliceerd door het gebruik van deze markeringen.
Migratiebenadering
Dit artikel bevat verschillende strategieën voor het migreren van Kafka naar Azure:
- Kafka migreren naar Azure Infrastructure as a Service (IaaS)
- Kafka migreren naar Azure Event Hubs voor Kafka
- Kafka migreren in Azure HDInsight
- Azure Kubernetes Service (AKS) gebruiken met Kafka in HDInsight
- Kafka op AKS gebruiken met de Strimzi-operator
Hier volgt een beslissingsstroomdiagram om te bepalen welke strategie u wilt gebruiken.
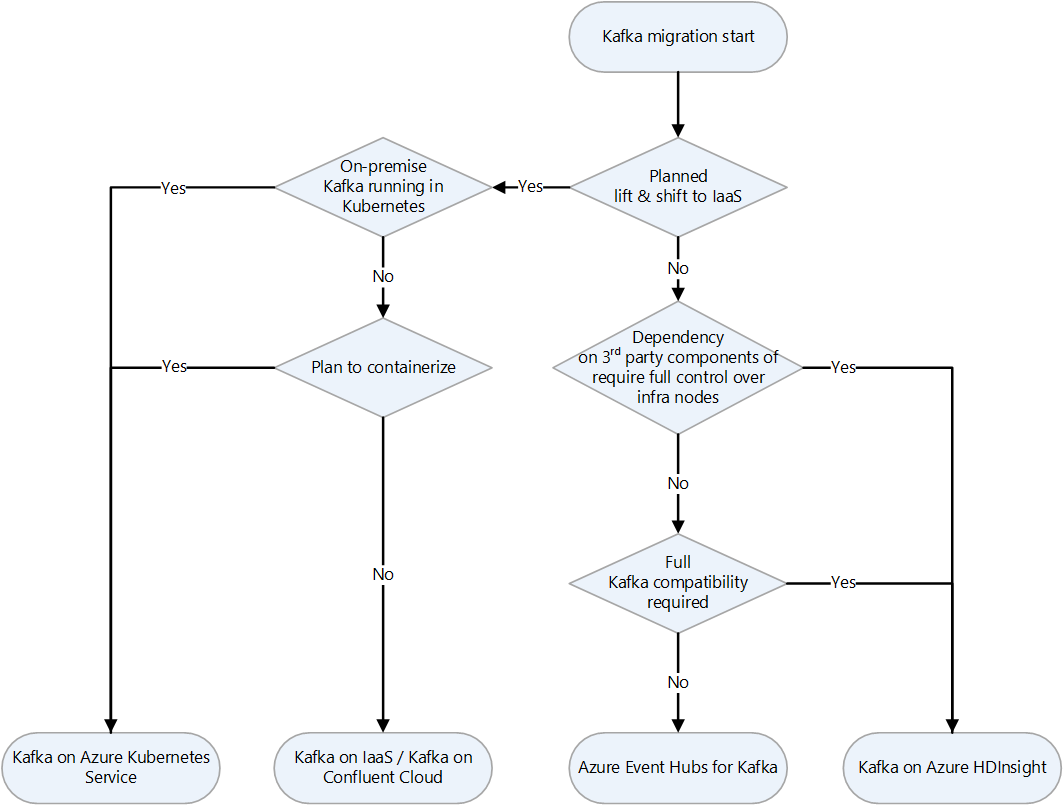
Kafka migreren naar Azure IaaS
Zie Kafka op virtuele Ubuntu-machines voor één manier om Kafka te migreren naar Azure IaaS.
Kafka migreren naar Event Hubs voor Kafka
Event Hubs biedt een eindpunt dat compatibel is met de Producer- en Consumer-API's van Apache Kafka. De meeste Apache Kafka-clienttoepassingen kunnen dit eindpunt gebruiken, zodat u het kunt gebruiken als alternatief voor het uitvoeren van een Kafka-cluster in Azure. Het eindpunt ondersteunt clients die API-versies 1.0 en hoger gebruiken. Zie het overzicht van Event Hubs voor Apache Kafka voor meer informatie over deze functie.
Zie Migreren naar Event Hubs voor Apache Kafka-ecosystemen voor meer informatie over het migreren van uw Apache Kafka-toepassingen voor het gebruik van Event Hubs.
Functies van Kafka en Event Hubs
| Overeenkomsten tussen Kafka en Event Hubs | Verschillen in Kafka en Event Hubs |
|---|---|
| Partities gebruiken | Platform as a service versus software |
| Partities zijn onafhankelijk | Partitie |
| Een cursorconcept aan de clientzijde gebruiken | Apis |
| Kan worden geschaald naar zeer hoge workloads | Looptijd |
| Bijna identiek conceptueel | Protocollen |
| Geen van beide maakt gebruik van het HTTP-protocol voor ontvangst | Duurzaamheid |
| Veiligheid | |
| Snelheidsbeperking |
Verschillen tussen partitionering
| Kafka | Evenement Hubs |
|---|---|
| Het aantal partities beheert de schaal. | Doorvoereenheden beheren schaal. |
| U moet partities verdelen over computers. | Taakverdeling is automatisch. |
| U moet handmatig opnieuwharden met behulp van splitsen en samenvoegen. | Opnieuw partitioneren is niet vereist. |
Verschillen in duurzaamheid
| Kafka | Evenement Hubs |
|---|---|
| Vluchtig standaard | Altijd duurzaam |
| Gerepliceerd nadat een bevestiging (ACK) is ontvangen | Gerepliceerd voordat een ACK wordt verzonden |
| Afhankelijk van schijf en quorum | Geleverd door opslag |
Beveiligingsverschillen
| Kafka | Evenement Hubs |
|---|---|
| Secure Sockets Layer (SSL) en Simple Authentication and Security Layer (SASL) | Shared Access Signature (SAS) en SASL of PLAIN RFC 4618 |
| Bestandsachtige toegangsbeheerlijsten | Beleid |
| Optionele transportversleuteling | Verplichte Transport Layer Security (TLS) |
| Op basis van gebruiker | Op token gebaseerd (onbeperkt) |
Andere verschillen
| Kafka | Evenement Hubs |
|---|---|
| Wordt niet beperkt | Ondersteunt beperking |
| Maakt gebruik van een eigen protocol | Maakt gebruik van het AMQP 1.0-protocol |
| Maakt geen gebruik van HTTP voor verzenden | Maakt gebruik van HTTP-verzenden en batch-verzenden |
Kafka migreren in HDInsight
U kunt Kafka migreren naar Kafka in HDInsight. Zie Wat is Apache Kafka in HDInsight? voor meer informatie.
AKS gebruiken met Kafka in HDInsight
Zie AKS gebruiken met Apache Kafka in HDInsight voor meer informatie.
Kafka op AKS gebruiken met de Strimzi-operator
Zie Een Kafka-cluster implementeren op AKS met behulp van Strimzi voor meer informatie.
Kafka-gegevensmigratie
U kunt het hulpprogramma MirrorMaker van Kafka gebruiken om onderwerpen van het ene cluster naar het andere te repliceren. Met deze techniek kunt u gegevens migreren nadat een Kafka-cluster is ingericht. Zie MirrorMaker gebruiken om Apache Kafka-onderwerpen te repliceren met Kafka in HDInsight voor meer informatie.
De volgende migratiebenadering maakt gebruik van spiegeling:
Verplaats eerst producenten. Wanneer u de producenten migreert, voorkomt u productie van nieuwe berichten in de bron-Kafka.
Nadat de bron-Kafka alle resterende berichten heeft verbruikt, kunt u de consumenten migreren.
De implementatie omvat de volgende stappen:
Wijzig het Kafka-verbindingsadres van de producerclient zodat deze verwijst naar het nieuwe Kafka-exemplaar.
Start de producer business services opnieuw en verzend nieuwe berichten naar het nieuwe Kafka-exemplaar.
Wacht tot de gegevens in de bron-Kafka zijn verbruikt.
Wijzig het Kafka-verbindingsadres van de consumentenclient zodat deze verwijst naar het nieuwe Kafka-exemplaar.
Start de zakelijke services voor consumenten opnieuw op om berichten van het nieuwe Kafka-exemplaar te gebruiken.
Controleer of consumenten gegevens kunnen ophalen uit het nieuwe Kafka-exemplaar.
Het Kafka-cluster bewaken
U kunt Azure Monitor-logboeken gebruiken om logboeken te analyseren die door Apache Kafka in HDInsight worden gegenereerd. Zie Logboeken voor Apache Kafka in HDInsight analyseren voor meer informatie.
Apache Kafka Streams-API
De Kafka Streams-API maakt het mogelijk om gegevens in bijna realtime te verwerken en gegevens samen te voegen en samen te voegen. Zie Introductie van Kafka Streams: Stream Processing Made Simple - Confluent voor meer informatie.
Het partnerschap van Microsoft en Confluent
Confluent biedt een cloudeigen service voor Apache Kafka. Microsoft en Confluent hebben een strategische alliantie. Zie de volgende bronnen voor meer informatie:
- Confluent en Microsoft kondigt strategische alliantie aan
- Inleiding tot naadloze integratie tussen Microsoft Azure en Confluent Cloud
Bijdragers
Microsoft onderhoudt dit artikel. De volgende inzenders hebben dit artikel geschreven.
Hoofdauteurs:
- Namrata Maheshwary | Senior Cloud Solution Architect
- Radja N | Directeur, Klant succes
- Hideo Takagi | Cloud Solution Architect
- Ram Yerrabotu | Senior Cloud Solution Architect
Andere Inzenders:
- Ram Baskaran | Senior Cloud Solution Architect
- Jason Bouska | Senior Software Engineer
- Eugene Chung | Senior Cloud Solution Architect
- Pawan Hosatti | Senior Cloud Solution Architect - Engineering
- Daman Kaur | Cloud Solution Architect
- Danny Liu | Senior Cloud Solution Architect - Engineering
- Jose Mendez Senior Cloud Solution Architect
- Ben Sadeghi | Senior Specialist
- Sunil Sattiraju | Senior Cloud Solution Architect
- Amanjeet Singh | Principal Program Manager
- Cateaj Seeplapudur Venkatesan | Senior Cloud Solution Architect - Engineering
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Volgende stappen
Introducties van Azure-producten
- Inleiding tot Azure Data Lake Storage
- Wat is Apache Spark in HDInsight?
- Wat is Apache Hadoop in HDInsight?
- Wat is Apache HBase in HDInsight?
- Wat is Apache Kafka in HDInsight?
- Overzicht van bedrijfsbeveiliging in HDInsight
Azure-productreferentie
- Microsoft Entra-documentatie
- Documentatie voor Azure Cosmos DB
- Documentatie voor Azure Data Factory
- Documentatie voor Azure Databricks
- Documentatie voor Event Hubs
- Documentatie van Azure Functions
- Documentatie voor HDInsight
- Documentatie voor Microsoft Purview-gegevensbeheer
- Documentatie voor Azure Stream Analytics