Sinks optimaliseren
Wanneer gegevensstromen naar sinks schrijven, vindt elke aangepaste partitionering direct voor de schrijfbewerking plaats. Net als bij de bron is het raadzaam om huidige partitionering te blijven gebruiken als de geselecteerde partitieoptie. Gepartitioneerde gegevens schrijven veel sneller dan niet-gepartitioneerde gegevens, zelfs uw bestemming is niet gepartitioneerd. Hieronder volgen de afzonderlijke overwegingen voor verschillende sinktypen.
Azure SQL Database-sinks
Met Azure SQL Database moet de standaardpartitionering in de meeste gevallen werken. Er is een kans dat uw sink te veel partities heeft om uw SQL-database te verwerken. Als u hiermee bezig bent, vermindert u het aantal partities dat wordt uitgevoerd door uw SQL Database-sink.
Aanbevolen procedure voor het verwijderen van rijen in sink op basis van ontbrekende rijen in de bron
Hier volgt een video-overzicht van het gebruik van gegevensstromen met bestaande gegevensstromen, het wijzigen van rij- en sinktransformaties om dit algemene patroon te bereiken:
Invloed van de verwerking van foutrijen op prestaties
Wanneer u foutrijafhandeling inschakelt ('doorgaan op fout') in de sinktransformatie, neemt de service een extra stap voordat de compatibele rijen naar de doeltabel worden geschreven. Deze extra stap heeft een kleine prestatiestraf die in het bereik van 5% kan worden toegevoegd voor deze stap, waarbij ook een extra kleine prestatietreffer wordt toegevoegd als u de optie instelt om ook de niet-compatibele rijen naar een logboekbestand te schrijven.
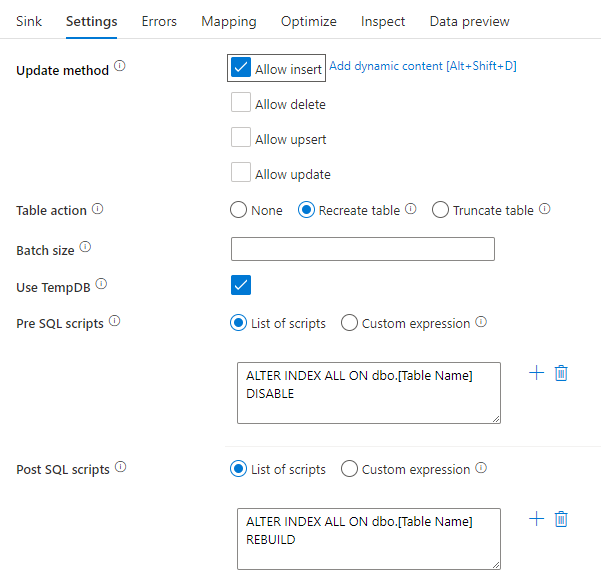
Indexen uitschakelen met behulp van een SQL-script
Als u indexen uitschakelt voordat een belasting in een SQL-database wordt geladen, kunt u de prestaties van het schrijven naar de tabel aanzienlijk verbeteren. Voer de onderstaande opdracht uit voordat u naar uw SQL-sink schrijft.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
Nadat de schrijfbewerking is voltooid, bouwt u de indexen opnieuw op met behulp van de volgende opdracht:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Deze kunnen beide systeemeigen worden uitgevoerd met behulp van Pre- en Post-SQL-scripts in een Azure SQL Database- of Synapse-sink in toewijzingsgegevensstromen.
Waarschuwing
Wanneer u indexen uitschakelt, wordt de gegevensstroom effectief beheerd door een database en zullen query's op dit moment waarschijnlijk niet slagen. Als gevolg hiervan worden veel ETL-taken midden in de nacht geactiveerd om dit conflict te voorkomen. Meer informatie over de beperkingen voor het uitschakelen van SQL-indexen
Uw database omhoog schalen
Plan een grootte van uw bron en sink Azure SQL DB en DW voordat de pijplijn wordt uitgevoerd om de doorvoer te verhogen en azure-beperking te minimaliseren zodra u DTU-limieten hebt bereikt. Nadat de uitvoering van de pijplijn is voltooid, wijzigt u het formaat van uw databases terug naar de normale uitvoeringssnelheid.
Azure Synapse Analytics-sinks
Wanneer u naar Azure Synapse Analytics schrijft, moet u ervoor zorgen dat fasering inschakelen is ingesteld op waar. Hierdoor kan de service schrijven met behulp van de SQL COPY-opdracht, waardoor de gegevens bulksgewijs worden geladen. U moet verwijzen naar een Azure Data Lake Storage Gen2- of Azure Blob Storage-account voor het faseren van de gegevens bij het gebruik van fasering.
Behalve fasering zijn dezelfde best practices van toepassing op Azure Synapse Analytics als Azure SQL Database.
Sinks op basis van bestanden
Hoewel gegevensstromen verschillende bestandstypen ondersteunen, wordt de systeemeigen Parquet-indeling van Spark aanbevolen voor optimale lees- en schrijftijden.
Als de gegevens gelijkmatig zijn verdeeld, is huidige partitionering de snelste partitioneringsoptie voor het schrijven van bestanden.
Opties voor bestandsnaam
Bij het schrijven van bestanden hebt u een keuze uit naamgevingsopties die elk invloed hebben op de prestaties.
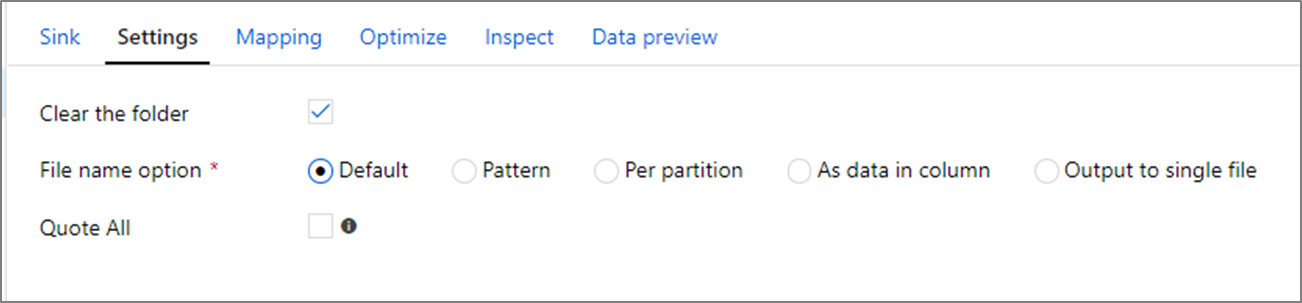
Als u de standaardoptie selecteert, wordt het snelst geschreven. Elke partitie is gelijk aan een bestand met de standaardnaam van Spark. Dit is handig als u alleen leest uit de map met gegevens.
Als u een naamgevingspatroon instelt, wordt de naam van elk partitiebestand gewijzigd in een meer gebruiksvriendelijke naam. Deze bewerking vindt plaats na schrijven en is iets langzamer dan het kiezen van de standaardinstelling.
Met elke partitie kunt u elke afzonderlijke partitie handmatig een naam geven.
Als een kolom overeenkomt met hoe u de gegevens wilt uitvoeren, kunt u het naambestand selecteren als kolomgegevens. Hierdoor worden de gegevens opnieuw ingedeeld en kunnen deze van invloed zijn op de prestaties als de kolommen niet gelijkmatig zijn verdeeld.
Als een kolom overeenkomt met de wijze waarop u mapnamen wilt genereren, selecteert u De map Naam als kolomgegevens.
Uitvoer naar één bestand combineert alle gegevens in één partitie. Dit leidt tot lange schrijftijden, met name voor grote gegevenssets. Deze optie wordt afgeraden, tenzij er een expliciete zakelijke reden is om deze te gebruiken.
Azure Cosmos DB-sinks
Wanneer u naar Azure Cosmos DB schrijft, kunt u de prestaties verbeteren door de doorvoer en batchgrootte te wijzigen tijdens de uitvoering van de gegevensstroom. Deze wijzigingen worden pas van kracht tijdens de uitvoering van de gegevensstroomactiviteit en worden na afloop terug naar de oorspronkelijke verzamelingsinstellingen.
Batchgrootte: Meestal is het voldoende om te beginnen met de standaard batchgrootte. Als u deze waarde verder wilt afstemmen, berekent u de ruwe objectgrootte van uw gegevens en zorgt u ervoor dat de objectgrootte * batchgrootte kleiner is dan 2 MB. Als dat het geval is, kunt u de batchgrootte vergroten om een betere doorvoer te krijgen.
Doorvoer: Stel hier een hogere doorvoerinstelling in om documenten sneller naar Azure Cosmos DB te laten schrijven. Houd rekening met de hogere RU-kosten op basis van een instelling voor hoge doorvoer.
Budget voor schrijfdoorvoer: gebruik een waarde die kleiner is dan het totale aantal RU's per minuut. Als u een gegevensstroom hebt met een groot aantal Spark-partities, zorgt het instellen van een budgetdoorvoer voor meer balans tussen deze partities.
Gerelateerde inhoud
- Overzicht van prestaties van gegevensstromen
- Bronnen optimaliseren
- Transformaties optimaliseren
- Gegevensstromen gebruiken in pijplijnen
Zie andere Gegevensstroom artikelen met betrekking tot prestaties: