Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
Gegevensstromen in kaart brengen in Azure Data Factory- en Synapse-pijplijnen biedt een codevrije interface voor het op schaal ontwerpen en uitvoeren van gegevenstransformaties. Als u niet bekend bent met Mapping Data Flows, raadpleegt u de Mapping Data Flow Overview. In dit artikel worden verschillende manieren beschreven om uw gegevensstromen af te stemmen en te optimaliseren, zodat ze voldoen aan uw prestatiebenchmarks.
Bekijk de volgende video om enkele voorbeeldtijdsinstellingen weer te geven voor het transformeren van gegevens met gegevensstromen.
Prestaties van gegevensstromen bewaken
Zodra u uw transformatielogica hebt geverifieerd met behulp van de foutopsporingsmodus, voert u uw gegevensstroom end-to-end uit als een activiteit in een pijplijn. Gegevensstromen worden in een pijplijn geoperationaliseerd met behulp van de gegevensstroomactiviteit uitvoeren. De gegevensstroomactiviteit heeft een unieke bewakingservaring in vergelijking met andere activiteiten die een gedetailleerd uitvoeringsplan en prestatieprofiel van de transformatielogica weergeven. Als u gedetailleerde bewakingsgegevens van een gegevensstroom wilt bekijken, selecteert u het brilpictogram in de uitvoer van een pijplijnactiviteit. Voor meer informatie, zie Toewijzingsgegevensstromen bewaken.

Wanneer u de prestaties van de gegevensstroom bewaakt, zijn er vier mogelijke knelpunten om te kijken naar:
- Opstarttijd van cluster
- Lezen vanuit een bron
- Transformatietijd
- Schrijven naar een sink
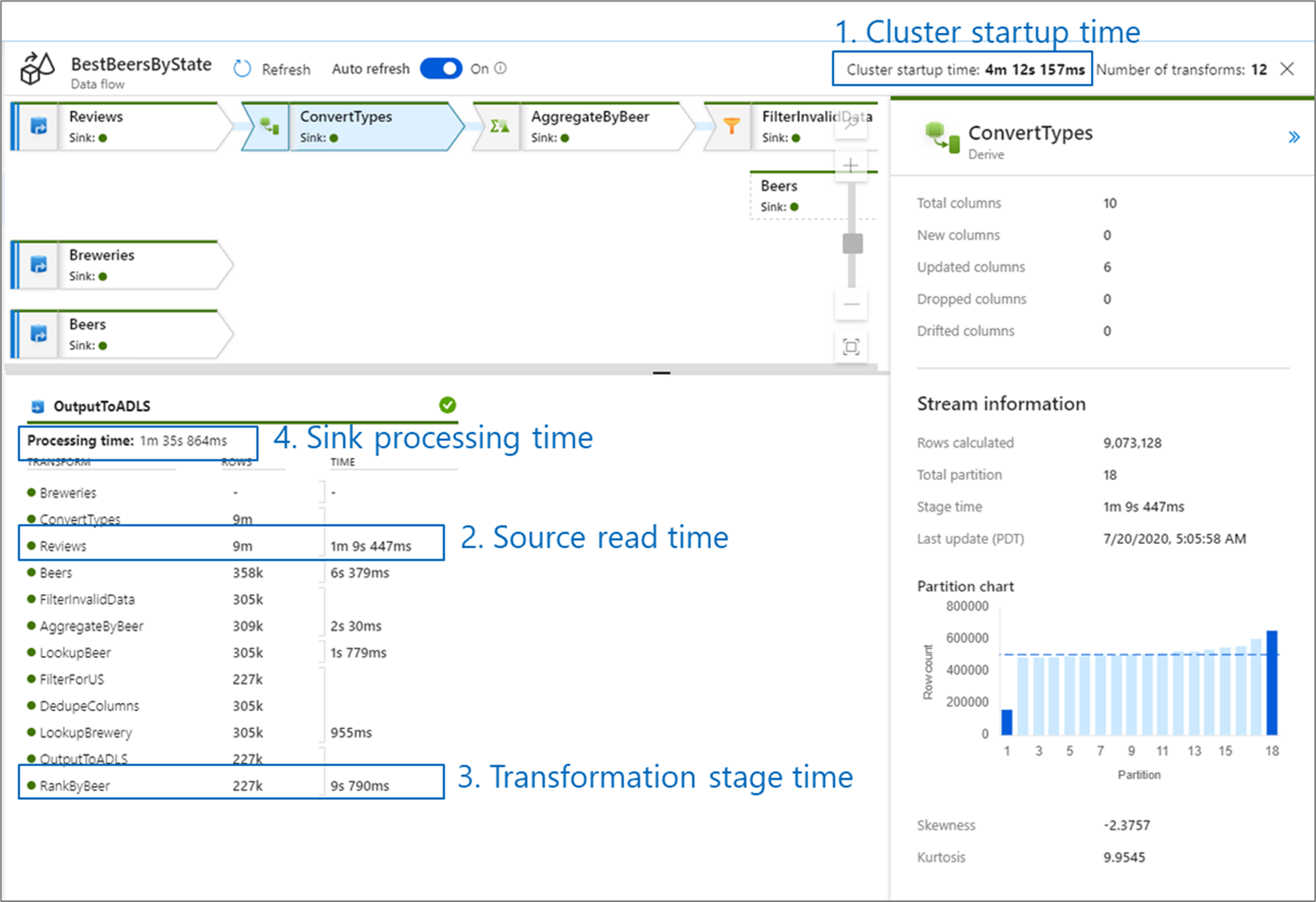
De opstarttijd van het cluster is de tijd die nodig is om een Apache Spark-cluster in te stellen. Deze waarde bevindt zich in de rechterbovenhoek van het bewakingsscherm. Gegevensstromen worden uitgevoerd op een Just-In-Time-model waarbij elke taak gebruikmaakt van een geïsoleerd cluster. Deze opstarttijd duurt doorgaans 3-5 minuten. Voor opeenvolgende taken kan de opstarttijd worden verminderd door een time to live-waarde in te schakelen. Zie de sectie Time to live in Integration Runtime performance voor meer informatie.
Gegevensstromen maken gebruik van een Spark-optimizer die uw bedrijfslogica in 'fasen' herschikt en uitvoert om zo snel mogelijk te presteren. Voor elke sink waarnaar uw gegevensstroom schrijft, geeft de bewakingsuitvoer de duur van elke transformatiefase weer, samen met de tijd die nodig is om gegevens naar de sink te schrijven. De tijd die het grootst is, is waarschijnlijk het knelpunt van uw gegevensstroom. Als de transformatiefase die de meeste tijd in beslag neemt een bron bevat, wilt u mogelijk uw leestijd verder optimaliseren. Als een transformatie lang duurt, moet u mogelijk de integratieruntime opnieuw partitioneren of vergroten. Als de verwerkingstijd van de sink groot is, moet u de database mogelijk omhoog schalen of controleren of u geen uitvoer naar één bestand uitvoert.
Zodra u het knelpunt van uw gegevensstroom hebt geïdentificeerd, gebruikt u de onderstaande optimalisatiestrategieën om de prestaties te verbeteren.
Gegevensstroomlogica testen
Wanneer u gegevensstromen ontwerpt en test vanuit de gebruikersinterface, kunt u met de foutopsporingsmodus interactief testen op een live Spark-cluster, zodat u een voorbeeld van gegevens kunt bekijken en uw gegevensstromen kunt uitvoeren zonder te wachten tot een cluster is opgewarmd. Zie De foutopsporingsmodus voor meer informatie.
Tabblad optimaliseren
Het tabblad Optimaliseren bevat instellingen voor het configureren van het partitioneringsschema van het Spark-cluster. Dit tabblad bestaat in elke transformatie van de gegevensstroom en geeft aan of u de gegevens opnieuw wilt partitioneren nadat de transformatie is voltooid. Het aanpassen van de partitionering biedt controle over de verdeling van uw gegevens over rekenknooppunten en optimalisaties voor gegevenslokaliteit die zowel positieve als negatieve gevolgen kunnen hebben voor de algehele prestaties van de gegevensstroom.
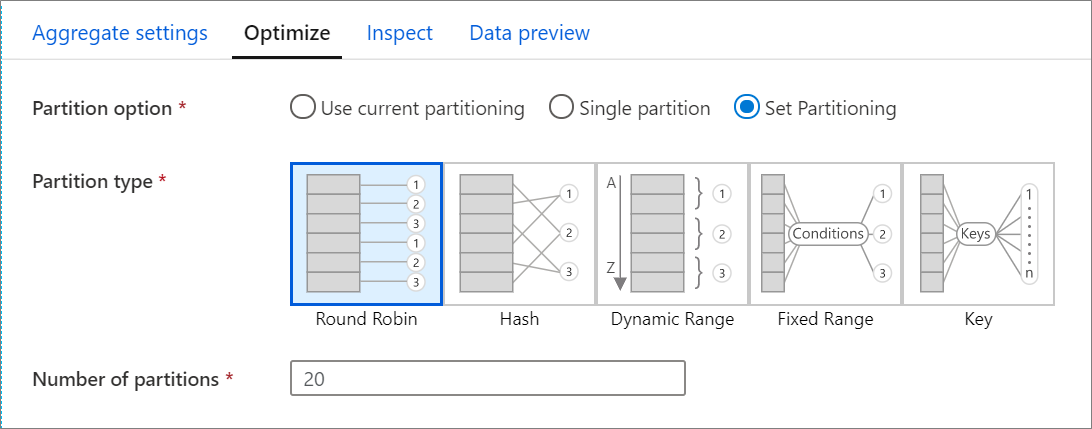
Standaard wordt huidige partitionering gebruiken geselecteerd waarmee de service de huidige uitvoerpartitionering van de transformatie behoudt. Omdat het opnieuw partitioneren van gegevens tijd kost, wordt het gebruik van huidige partitionering aanbevolen in de meeste scenario's. Scenario's waarin u uw gegevens mogelijk opnieuw wilt partitioneren, zijn onder andere na aggregaties en joins die uw gegevens aanzienlijk scheeftrekken of bij het gebruik van bronpartitionering in een SQL-database.
Als u de partitionering voor een transformatie wilt wijzigen, selecteert u het tabblad Optimaliseren en selecteert u het keuzerondje Partitioneren instellen. U krijgt een reeks opties voor partitionering te zien. De beste partitioneringsmethode verschilt op basis van uw gegevensvolumes, kandidaatsleutels, null-waarden en kardinaliteit.
Belangrijk
Eén partitie combineert alle gedistribueerde gegevens in één partitie. Dit is een zeer trage bewerking die ook van invloed is op alle downstreamtransformaties en schrijfbewerkingen. Deze optie wordt sterk afgeraden, tenzij er een expliciete zakelijke reden is om deze te gebruiken.
De volgende partitioneringsopties zijn beschikbaar in elke transformatie:
Ronde-robin
Round robin distribueert gegevens gelijkmatig over partities. Gebruik round robin wanneer u geen goede kandidaten hebt om een solide, slimme partitioneringsstrategie te implementeren. U kunt het aantal fysieke partities instellen.
Hashwaarde
De service produceert een hash van kolommen om uniforme partities te produceren, zodat rijen met vergelijkbare waarden in dezelfde partitie vallen. Wanneer u de hash-optie gebruikt, test u op mogelijke scheeftrekken van partities. U kunt het aantal fysieke partities instellen.
Dynamisch bereik
Het dynamische bereik maakt gebruik van dynamische Spark-bereiken op basis van de kolommen of expressies die u opgeeft. U kunt het aantal fysieke partities instellen.
Vast bereik
Bouw een expressie die een vast bereik biedt voor waarden binnen uw gepartitioneerde gegevenskolommen. Om scheefheid van partities te voorkomen, moet u goed inzicht hebben in uw gegevens voordat u deze optie gebruikt. De waarden die u voor de expressie invoert, worden gebruikt als onderdeel van een partitiefunctie. U kunt het aantal fysieke partities instellen.
Sleutel
Als u goed inzicht hebt in de kardinaliteit van uw gegevens, is sleutelpartitionering mogelijk een goede strategie. Met sleutelpartitionering worden partities gemaakt voor elke unieke waarde in uw kolom. U kunt het aantal partities niet instellen omdat het getal is gebaseerd op unieke waarden in de gegevens.
Tip
Handmatig instellen van het partitioneringsschema herschikt de gegevens en kan de voordelen van de Spark-optimalisatie compenseren. Een best practice is om de partitionering niet handmatig in te stellen, tenzij u dat nodig hebt.
Niveau van logboekregistratie
Als u niet elke pijplijnuitvoering van uw gegevensstroomactiviteiten nodig hebt om alle uitgebreide telemetrielogboeken volledig te registreren, kunt u eventueel het logboekregistratieniveau instellen op Basis of Geen. Wanneer u uw gegevensstromen uitvoert in de modus Uitgebreid (standaard), vraagt u de service om activiteiten op elk afzonderlijk partitieniveau volledig te registreren tijdens uw gegevenstransformatie. Dit kan een dure bewerking zijn, dus alleen gedetailleerde logging inschakelen bij het oplossen van problemen kan de algehele prestaties van uw gegevensstroom en pijplijnen verbeteren. De modus Basic registreert alleen de transformatieduur terwijl 'Geen' alleen een samenvatting van de duur biedt.

Gerelateerde inhoud
- Bronnen optimaliseren
- Sinks optimaliseren
- Transformaties optimaliseren
- Gegevensstromen gebruiken in pijplijnen
Zie andere Data Flow artikelen met betrekking tot prestaties: